 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Generalization of Representations in Reinforcement Learning
Mar 01, 2022
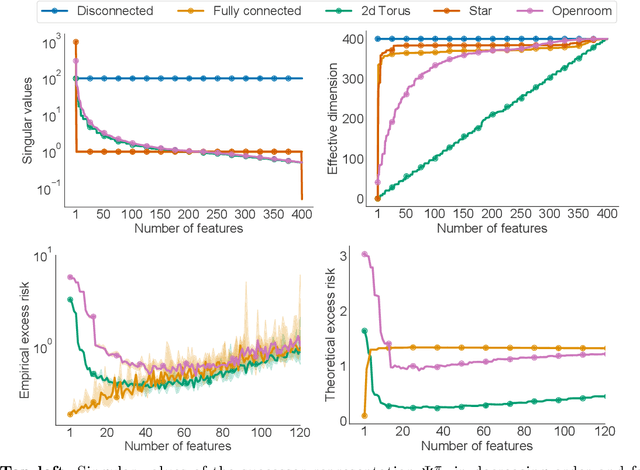
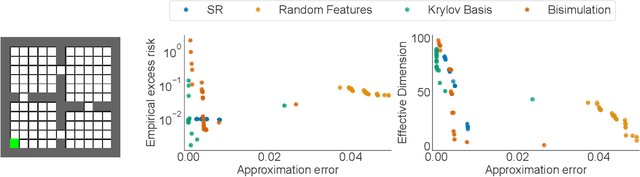
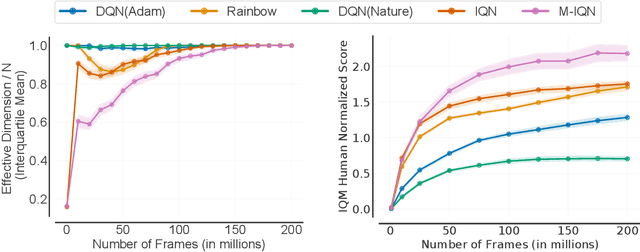
In reinforcement learning, state representations are used to tractably deal with large problem spaces. State representations serve both to approximate the value function with few parameters, but also to generalize to newly encountered states. Their features may be learned implicitly (as part of a neural network) or explicitly (for example, the successor representation of \citet{dayan1993improving}). While the approximation properties of representations are reasonably well-understood, a precise characterization of how and when these representations generalize is lacking. In this work, we address this gap and provide an informative bound on the generalization error arising from a specific state representation. This bound is based on the notion of effective dimension which measures the degree to which knowing the value at one state informs the value at other states. Our bound applies to any state representation and quantifies the natural tension between representations that generalize well and those that approximate well. We complement our theoretical results with an empirical survey of classic representation learning methods from the literature and results on the Arcade Learning Environment, and find that the generalization behaviour of learned representations is well-explained by their effective dimension.
Adversarially Robust Stability Certificates can be Sample-Efficient
Dec 20, 2021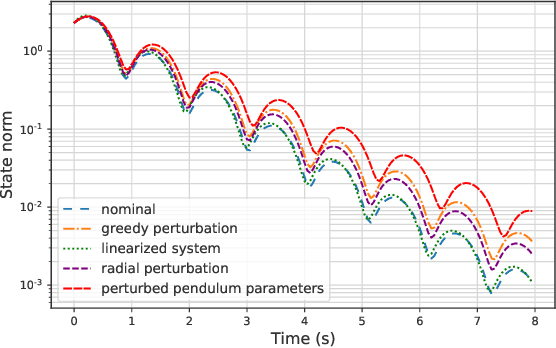
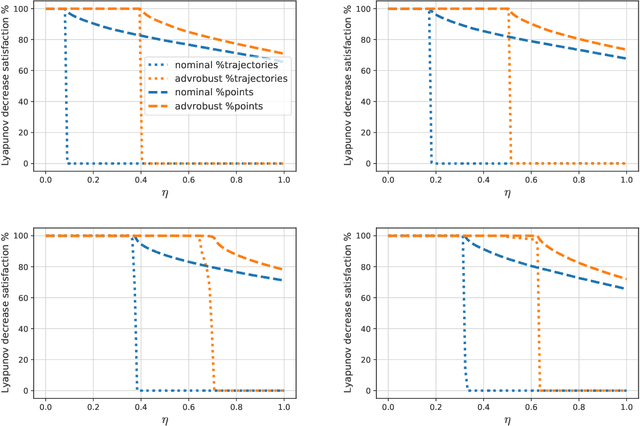
Motivated by bridging the simulation to reality gap in the context of safety-critical systems, we consider learning adversarially robust stability certificates for unknown nonlinear dynamical systems. In line with approaches from robust control, we consider additive and Lipschitz bounded adversaries that perturb the system dynamics. We show that under suitable assumptions of incremental stability on the underlying system, the statistical cost of learning an adversarial stability certificate is equivalent, up to constant factors, to that of learning a nominal stability certificate. Our results hinge on novel bounds for the Rademacher complexity of the resulting adversarial loss class, which may be of independent interest. To the best of our knowledge, this is the first characterization of sample-complexity bounds when performing adversarial learning over data generated by a dynamical system. We further provide a practical algorithm for approximating the adversarial training algorithm, and validate our findings on a damped pendulum example.
Learning Robust Output Control Barrier Functions from Safe Expert Demonstrations
Nov 18, 2021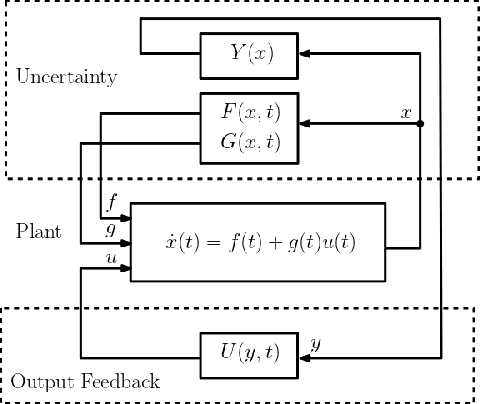
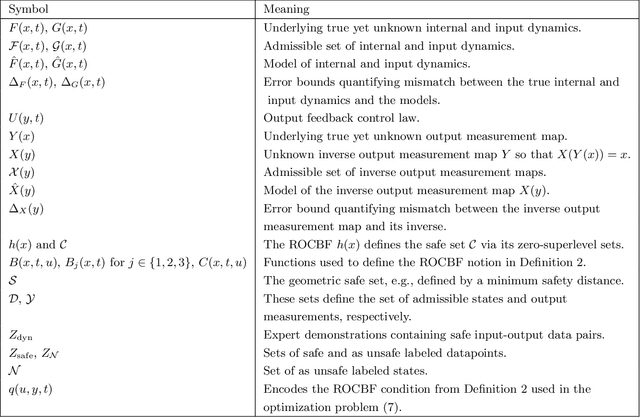
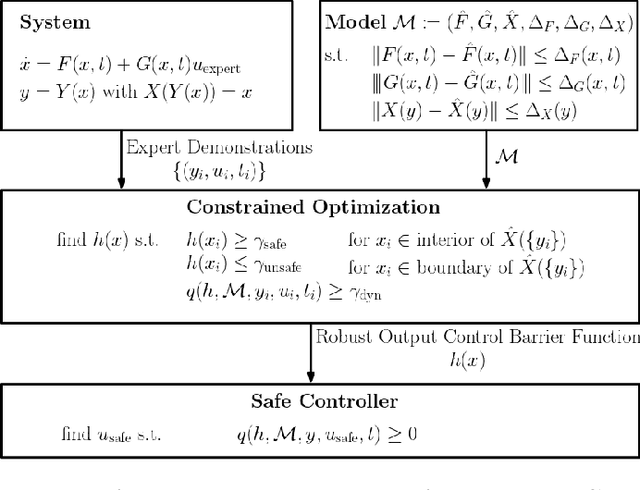

This paper addresses learning safe control laws from expert demonstrations. We assume that appropriate models of the system dynamics and the output measurement map are available, along with corresponding error bounds. We first propose robust output control barrier functions (ROCBFs) as a means to guarantee safety, as defined through controlled forward invariance of a safe set. We then present an optimization problem to learn ROCBFs from expert demonstrations that exhibit safe system behavior, e.g., data collected from a human operator. Along with the optimization problem, we provide verifiable conditions that guarantee validity of the obtained ROCBF. These conditions are stated in terms of the density of the data and on Lipschitz and boundedness constants of the learned function and the models of the system dynamics and the output measurement map. When the parametrization of the ROCBF is linear, then, under mild assumptions, the optimization problem is convex. We validate our findings in the autonomous driving simulator CARLA and show how to learn safe control laws from RGB camera images.
Random features for adaptive nonlinear control and prediction
Jun 07, 2021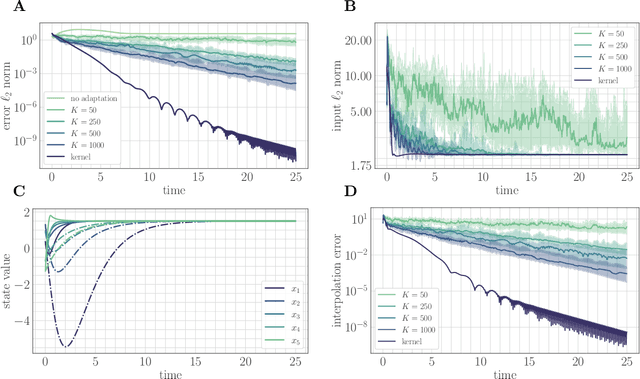
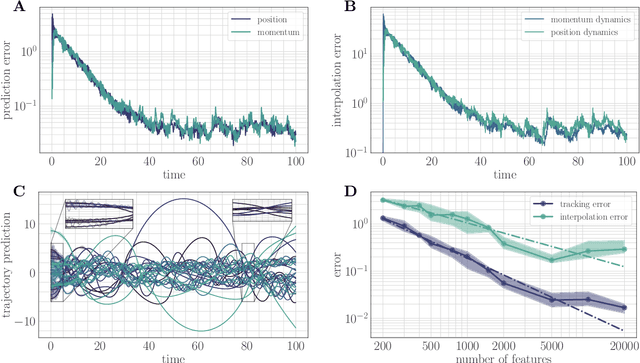
A key assumption in the theory of adaptive control for nonlinear systems is that the uncertainty of the system can be expressed in the linear span of a set of known basis functions. While this assumption leads to efficient algorithms, verifying it in practice can be difficult, particularly for complex systems. Here we leverage connections between reproducing kernel Hilbert spaces, random Fourier features, and universal approximation theory to propose a computationally tractable algorithm for both adaptive control and adaptive prediction that does not rely on a linearly parameterized unknown. Specifically, we approximate the unknown dynamics with a finite expansion in $\textit{random}$ basis functions, and provide an explicit guarantee on the number of random features needed to track a desired trajectory with high probability. Remarkably, our explicit bounds only depend $\textit{polynomially}$ on the underlying parameters of the system, allowing our proposed algorithms to efficiently scale to high-dimensional systems. We study a setting where the unknown dynamics splits into a component that can be modeled through available physical knowledge of the system and a component that lives in a reproducing kernel Hilbert space. Our algorithms simultaneously adapt over parameters for physical basis functions and random features to learn both components of the dynamics online.
Closing the Closed-Loop Distribution Shift in Safe Imitation Learning
Feb 18, 2021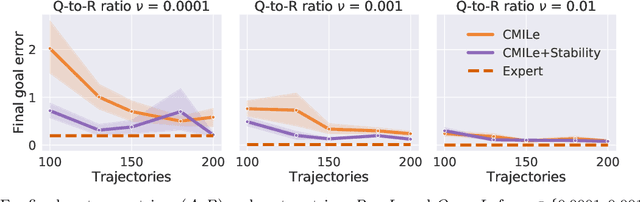
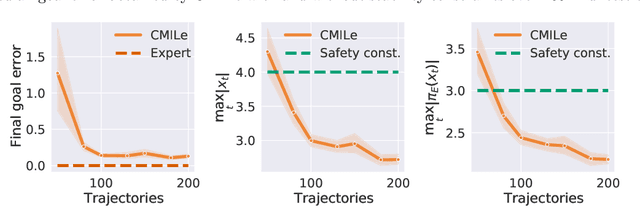
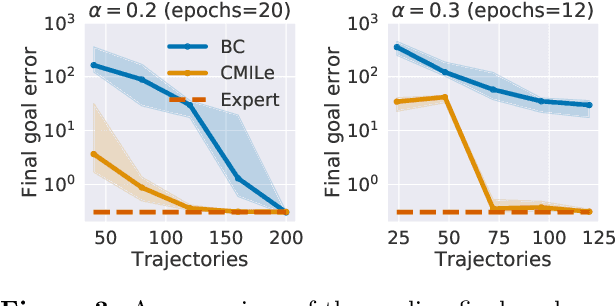
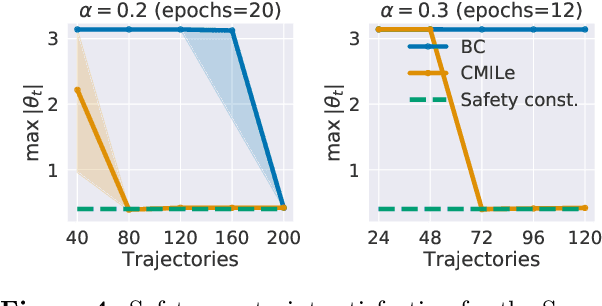
Commonly used optimization-based control strategies such as model-predictive and control Lyapunov/barrier function based controllers often enjoy provable stability, robustness, and safety properties. However, implementing such approaches requires solving optimization problems online at high-frequencies, which may not be possible on resource-constrained commodity hardware. Furthermore, how to extend the safety guarantees of such approaches to systems that use rich perceptual sensing modalities, such as cameras, remains unclear. In this paper, we address this gap by treating safe optimization-based control strategies as experts in an imitation learning problem, and train a learned policy that can be cheaply evaluated at run-time and that provably satisfies the same safety guarantees as the expert. In particular, we propose Constrained Mixing Iterative Learning (CMILe), a novel on-policy robust imitation learning algorithm that integrates ideas from stochastic mixing iterative learning, constrained policy optimization, and nonlinear robust control. Our approach allows us to control errors introduced by both the learning task of imitating an expert and by the distribution shift inherent to deviating from the original expert policy. The value of using tools from nonlinear robust control to impose stability constraints on learned policies is shown through sample-complexity bounds that are independent of the task time-horizon. We demonstrate the usefulness of CMILe through extensive experiments, including training a provably safe perception-based controller using a state-feedback-based expert.
Learning Robust Hybrid Control Barrier Functions for Uncertain Systems
Jan 16, 2021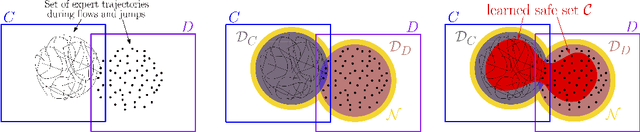
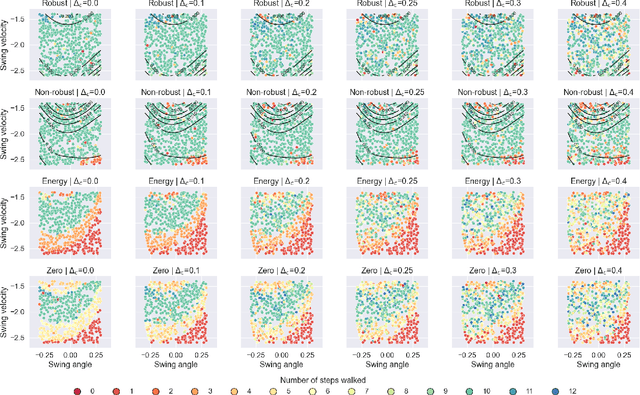
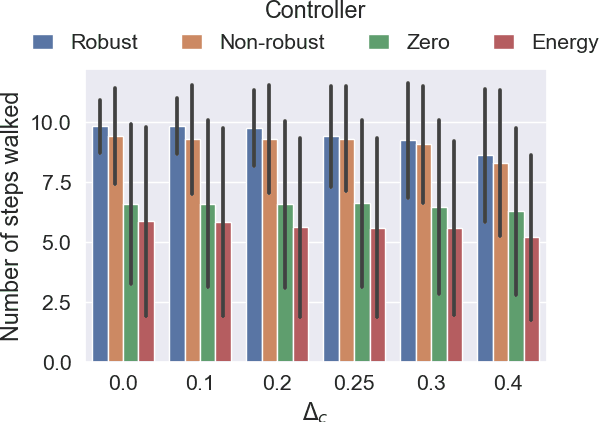
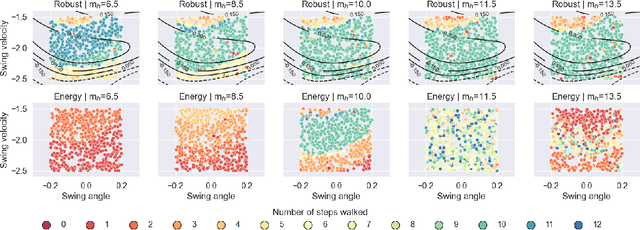
The need for robust control laws is especially important in safety-critical applications. We propose robust hybrid control barrier functions as a means to synthesize control laws that ensure robust safety. Based on this notion, we formulate an optimization problem for learning robust hybrid control barrier functions from data. We identify sufficient conditions on the data such that feasibility of the optimization problem ensures correctness of the learned robust hybrid control barrier functions. Our techniques allow us to safely expand the region of attraction of a compass gait walker that is subject to model uncertainty.
Regret Bounds for Adaptive Nonlinear Control
Nov 26, 2020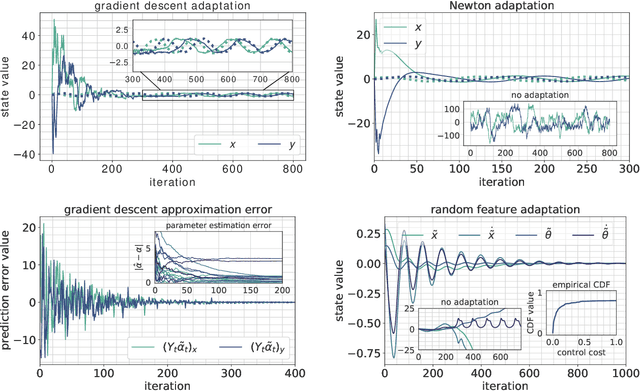
We study the problem of adaptively controlling a known discrete-time nonlinear system subject to unmodeled disturbances. We prove the first finite-time regret bounds for adaptive nonlinear control with matched uncertainty in the stochastic setting, showing that the regret suffered by certainty equivalence adaptive control, compared to an oracle controller with perfect knowledge of the unmodeled disturbances, is upper bounded by $\widetilde{O}(\sqrt{T})$ in expectation. Furthermore, we show that when the input is subject to a $k$ timestep delay, the regret degrades to $\widetilde{O}(k \sqrt{T})$. Our analysis draws connections between classical stability notions in nonlinear control theory (Lyapunov stability and contraction theory) and modern regret analysis from online convex optimization. The use of stability theory allows us to analyze the challenging infinite-horizon single trajectory setting.
Safely Learning Dynamical Systems from Short Trajectories
Nov 24, 2020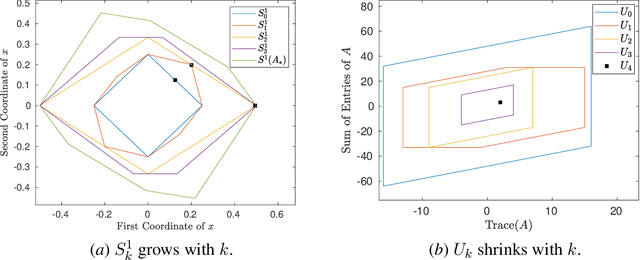
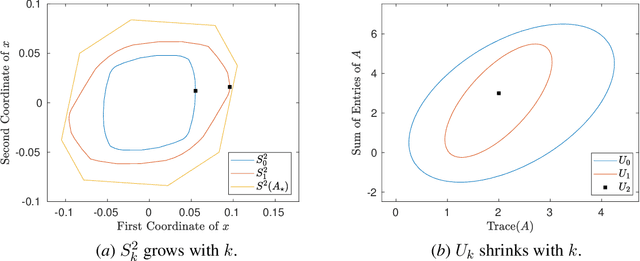
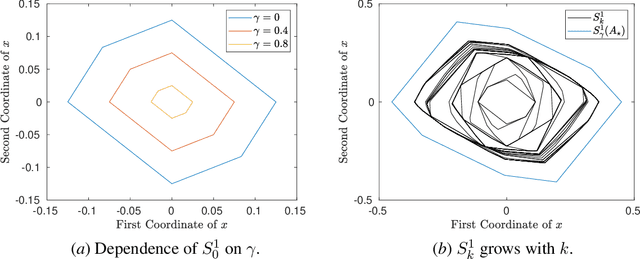
A fundamental challenge in learning to control an unknown dynamical system is to reduce model uncertainty by making measurements while maintaining safety. In this work, we formulate a mathematical definition of what it means to safely learn a dynamical system by sequentially deciding where to initialize the next trajectory. In our framework, the state of the system is required to stay within a given safety region under the (possibly repeated) action of all dynamical systems that are consistent with the information gathered so far. For our first two results, we consider the setting of safely learning linear dynamics. We present a linear programming-based algorithm that either safely recovers the true dynamics from trajectories of length one, or certifies that safe learning is impossible. We also give an efficient semidefinite representation of the set of initial conditions whose resulting trajectories of length two are guaranteed to stay in the safety region. For our final result, we study the problem of safely learning a nonlinear dynamical system. We give a second-order cone programming based representation of the set of initial conditions that are guaranteed to remain in the safety region after one application of the system dynamics.
Learning Hybrid Control Barrier Functions from Data
Nov 08, 2020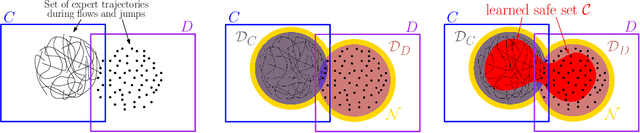
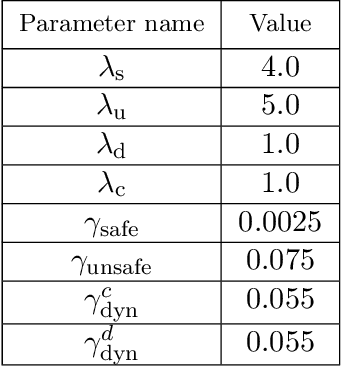
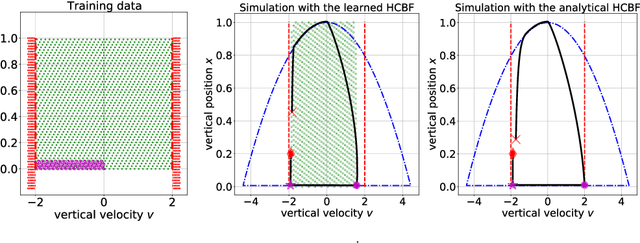
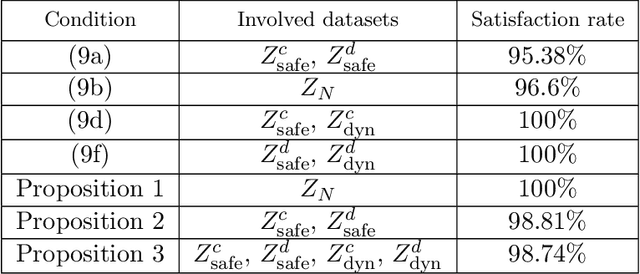
Motivated by the lack of systematic tools to obtain safe control laws for hybrid systems, we propose an optimization-based framework for learning certifiably safe control laws from data. In particular, we assume a setting in which the system dynamics are known and in which data exhibiting safe system behavior is available. We propose hybrid control barrier functions for hybrid systems as a means to synthesize safe control inputs. Based on this notion, we present an optimization-based framework to learn such hybrid control barrier functions from data. Importantly, we identify sufficient conditions on the data such that feasibility of the optimization problem ensures correctness of the learned hybrid control barrier functions, and hence the safety of the system. We illustrate our findings in two simulations studies, including a compass gait walker.
Learning Stability Certificates from Data
Sep 14, 2020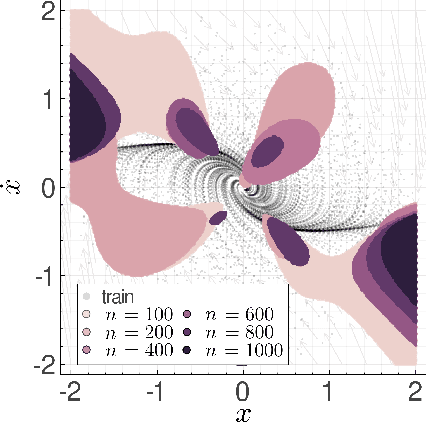
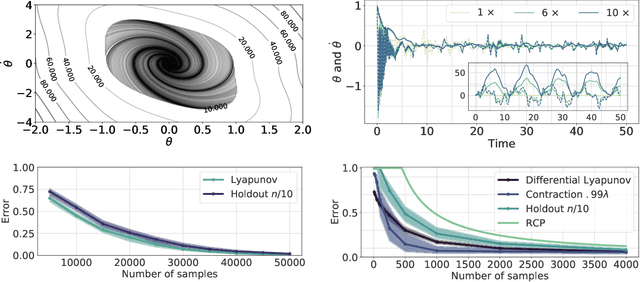
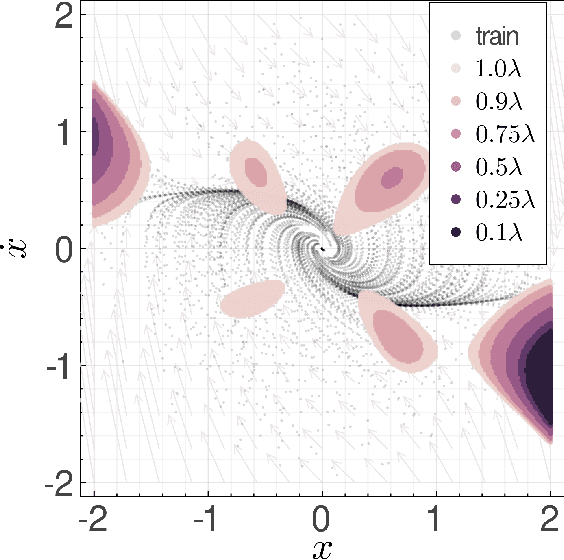
Many existing tools in nonlinear control theory for establishing stability or safety of a dynamical system can be distilled to the construction of a certificate function that guarantees a desired property. However, algorithms for synthesizing certificate functions typically require a closed-form analytical expression of the underlying dynamics, which rules out their use on many modern robotic platforms. To circumvent this issue, we develop algorithms for learning certificate functions only from trajectory data. We establish bounds on the generalization error - the probability that a certificate will not certify a new, unseen trajectory - when learning from trajectories, and we convert such generalization error bounds into global stability guarantees. We demonstrate empirically that certificates for complex dynamics can be efficiently learned, and that the learned certificates can be used for downstream tasks such as adaptive control.