 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Generate Instruction Tuning Datasets for Zero-Shot Task Adaptation
Feb 28, 2024We introduce Bonito, an open-source model for conditional task generation: the task of converting unannotated text into task-specific training datasets for instruction tuning. Our goal is to enable zero-shot task adaptation of large language models on users' specialized, private data. We train Bonito on a new large-scale dataset with 1.65M examples created by remixing existing instruction tuning datasets into meta-templates. The meta-templates for a dataset produce training examples where the input is the unannotated text and the task attribute and the output consists of the instruction and the response. We use Bonito to generate synthetic tasks for seven datasets from specialized domains across three task types -- yes-no question answering, extractive question answering, and natural language inference -- and adapt language models. We show that Bonito significantly improves the average performance of pretrained and instruction tuned models over the de facto self supervised baseline. For example, adapting Mistral-Instruct-v2 and instruction tuned variants of Mistral and Llama2 with Bonito improves the strong zero-shot performance by 22.1 F1 points whereas the next word prediction objective undoes some of the benefits of instruction tuning and reduces the average performance by 0.8 F1 points. We conduct additional experiments with Bonito to understand the effects of the domain, the size of the training set, and the choice of alternative synthetic task generators. Overall, we show that learning with synthetic instruction tuning datasets is an effective way to adapt language models to new domains. The model, dataset, and code are available at https://github.com/BatsResearch/bonito.
LexC-Gen: Generating Data for Extremely Low-Resource Languages with Large Language Models and Bilingual Lexicons
Feb 21, 2024Data scarcity in low-resource languages can be addressed with word-to-word translations from labeled task data in high-resource languages using bilingual lexicons. However, bilingual lexicons often have limited lexical overlap with task data, which results in poor translation coverage and lexicon utilization. We propose lexicon-conditioned data generation (LexC-Gen), a method that generates low-resource-language classification task data at scale. Specifically, LexC-Gen first uses high-resource-language words from bilingual lexicons to generate lexicon-compatible task data, and then it translates them into low-resource languages with bilingual lexicons via word translation. Across 17 extremely low-resource languages, LexC-Gen generated data is competitive with expert-translated gold data, and yields on average 5.6 and 8.9 points improvement over existing lexicon-based word translation methods on sentiment analysis and topic classification tasks respectively. We show that conditioning on bilingual lexicons is the key component of LexC-Gen. LexC-Gen is also practical -- it only needs a single GPU to generate data at scale. It works well with open-access LLMs, and its cost is one-fifth of the cost of GPT4-based multilingual data generation.
Leveraging Large Language Models for Structure Learning in Prompted Weak Supervision
Feb 02, 2024Prompted weak supervision (PromptedWS) applies pre-trained large language models (LLMs) as the basis for labeling functions (LFs) in a weak supervision framework to obtain large labeled datasets. We further extend the use of LLMs in the loop to address one of the key challenges in weak supervision: learning the statistical dependency structure among supervision sources. In this work, we ask the LLM how similar are these prompted LFs. We propose a Structure Refining Module, a simple yet effective first approach based on the similarities of the prompts by taking advantage of the intrinsic structure in the embedding space. At the core of Structure Refining Module are Labeling Function Removal (LaRe) and Correlation Structure Generation (CosGen). Compared to previous methods that learn the dependencies from weak labels, our method finds the dependencies which are intrinsic to the LFs and less dependent on the data. We show that our Structure Refining Module improves the PromptedWS pipeline by up to 12.7 points on the benchmark tasks. We also explore the trade-offs between efficiency and performance with comprehensive ablation experiments and analysis. Code for this project can be found in https://github.com/BatsResearch/su-bigdata23-code.
Follow-Up Differential Descriptions: Language Models Resolve Ambiguities for Image Classification
Nov 10, 2023



A promising approach for improving the performance of vision-language models like CLIP for image classification is to extend the class descriptions (i.e., prompts) with related attributes, e.g., using brown sparrow instead of sparrow. However, current zero-shot methods select a subset of attributes regardless of commonalities between the target classes, potentially providing no useful information that would have helped to distinguish between them. For instance, they may use color instead of bill shape to distinguish between sparrows and wrens, which are both brown. We propose Follow-up Differential Descriptions (FuDD), a zero-shot approach that tailors the class descriptions to each dataset and leads to additional attributes that better differentiate the target classes. FuDD first identifies the ambiguous classes for each image, and then uses a Large Language Model (LLM) to generate new class descriptions that differentiate between them. The new class descriptions resolve the initial ambiguity and help predict the correct label. In our experiments, FuDD consistently outperforms generic description ensembles and naive LLM-generated descriptions on 12 datasets. We show that differential descriptions are an effective tool to resolve class ambiguities, which otherwise significantly degrade the performance. We also show that high quality natural language class descriptions produced by FuDD result in comparable performance to few-shot adaptation methods.
Low-Resource Languages Jailbreak GPT-4
Oct 03, 2023


AI safety training and red-teaming of large language models (LLMs) are measures to mitigate the generation of unsafe content. Our work exposes the inherent cross-lingual vulnerability of these safety mechanisms, resulting from the linguistic inequality of safety training data, by successfully circumventing GPT-4's safeguard through translating unsafe English inputs into low-resource languages. On the AdvBenchmark, GPT-4 engages with the unsafe translated inputs and provides actionable items that can get the users towards their harmful goals 79% of the time, which is on par with or even surpassing state-of-the-art jailbreaking attacks. Other high-/mid-resource languages have significantly lower attack success rate, which suggests that the cross-lingual vulnerability mainly applies to low-resource languages. Previously, limited training on low-resource languages primarily affects speakers of those languages, causing technological disparities. However, our work highlights a crucial shift: this deficiency now poses a risk to all LLMs users. Publicly available translation APIs enable anyone to exploit LLMs' safety vulnerabilities. Therefore, our work calls for a more holistic red-teaming efforts to develop robust multilingual safeguards with wide language coverage.
An Adaptive Method for Weak Supervision with Drifting Data
Jun 02, 2023We introduce an adaptive method with formal quality guarantees for weak supervision in a non-stationary setting. Our goal is to infer the unknown labels of a sequence of data by using weak supervision sources that provide independent noisy signals of the correct classification for each data point. This setting includes crowdsourcing and programmatic weak supervision. We focus on the non-stationary case, where the accuracy of the weak supervision sources can drift over time, e.g., because of changes in the underlying data distribution. Due to the drift, older data could provide misleading information to infer the label of the current data point. Previous work relied on a priori assumptions on the magnitude of the drift to decide how much data to use from the past. Comparatively, our algorithm does not require any assumptions on the drift, and it adapts based on the input. In particular, at each step, our algorithm guarantees an estimation of the current accuracies of the weak supervision sources over a window of past observations that minimizes a trade-off between the error due to the variance of the estimation and the error due to the drift. Experiments on synthetic and real-world labelers show that our approach indeed adapts to the drift. Unlike fixed-window-size strategies, it dynamically chooses a window size that allows it to consistently maintain good performance.
Enhancing CLIP with CLIP: Exploring Pseudolabeling for Limited-Label Prompt Tuning
Jun 02, 2023Fine-tuning vision-language models (VLMs) like CLIP to downstream tasks is often necessary to optimize their performance. However, a major obstacle is the limited availability of labeled data. We study the use of pseudolabels, i.e., heuristic labels for unlabeled data, to enhance CLIP via prompt tuning. Conventional pseudolabeling trains a model on labeled data and then generates labels for unlabeled data. VLMs' zero-shot capabilities enable a ``second generation'' of pseudolabeling approaches that do not require task-specific training on labeled data. By using zero-shot pseudolabels as a source of supervision, we observe that learning paradigms such as semi-supervised, transductive zero-shot, and unsupervised learning can all be seen as optimizing the same loss function. This unified view enables the development of versatile training strategies that are applicable across learning paradigms. We investigate them on image classification tasks where CLIP exhibits limitations, by varying prompt modalities, e.g., textual or visual prompts, and learning paradigms. We find that (1) unexplored prompt tuning strategies that iteratively refine pseudolabels consistently improve CLIP accuracy, by 19.5 points in semi-supervised learning, by 28.4 points in transductive zero-shot learning, and by 15.2 points in unsupervised learning, and (2) unlike conventional semi-supervised pseudolabeling, which exacerbates model biases toward classes with higher-quality pseudolabels, prompt tuning leads to a more equitable distribution of per-class accuracy. The code to reproduce the experiments is at github.com/BatsResearch/menghini-enhanceCLIPwithCLIP-code.
Alfred: A System for Prompted Weak Supervision
May 29, 2023



Alfred is the first system for programmatic weak supervision (PWS) that creates training data for machine learning by prompting. In contrast to typical PWS systems where weak supervision sources are programs coded by experts, Alfred enables users to encode their subject matter expertise via natural language prompts for language and vision-language models. Alfred provides a simple Python interface for the key steps of this emerging paradigm, with a high-throughput backend for large-scale data labeling. Users can quickly create, evaluate, and refine their prompt-based weak supervision sources; map the results to weak labels; and resolve their disagreements with a label model. Alfred enables a seamless local development experience backed by models served from self-managed computing clusters. It automatically optimizes the execution of prompts with optimized batching mechanisms. We find that this optimization improves query throughput by 2.9x versus a naive approach. We present two example use cases demonstrating Alfred on YouTube comment spam detection and pet breeds classification. Alfred is open source, available at https://github.com/BatsResearch/alfred.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
Tight Lower Bounds on Worst-Case Guarantees for Zero-Shot Learning with Attributes
May 25, 2022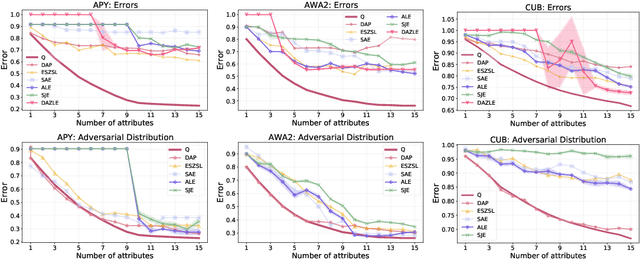
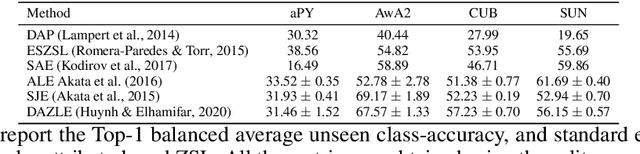
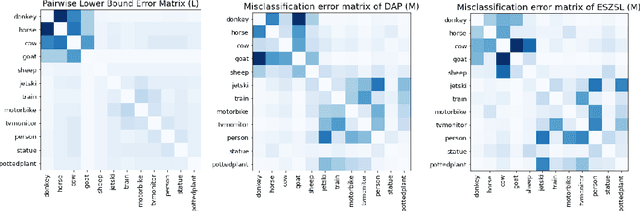
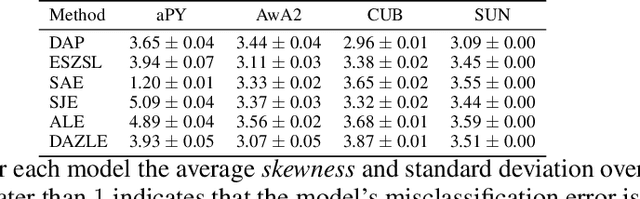
We develop a rigorous mathematical analysis of zero-shot learning with attributes. In this setting, the goal is to label novel classes with no training data, only detectors for attributes and a description of how those attributes are correlated with the target classes, called the class-attribute matrix. We develop the first non-trivial lower bound on the worst-case error of the best map from attributes to classes for this setting, even with perfect attribute detectors. The lower bound characterizes the theoretical intrinsic difficulty of the zero-shot problem based on the available information -- the class-attribute matrix -- and the bound is practically computable from it. Our lower bound is tight, as we show that we can always find a randomized map from attributes to classes whose expected error is upper bounded by the value of the lower bound. We show that our analysis can be predictive of how standard zero-shot methods behave in practice, including which classes will likely be confused with others.