 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying the Privacy of Counterfactuals by Leveraging Membership Inference Attacks Against Synthetic Data
Jun 04, 2026Counterfactuals are typically used in high-stakes decision areas to explain a machine learning model by showing how changes to the user profiles result in the desired outcome. However, explaining the model's decisions through counterfactuals can also be exploited by an adversary to conduct privacy attacks against the model or its training data. Drawing on the analogy that counterfactuals provide realistic substitutes for real training data, similar to synthetic data, we demonstrate in this paper how it is possible to successfully perform privacy attacks on counterfactuals by drawing on the attacks developed against synthetic data. More precisely, we investigate the effectiveness of the membership inference attacks designed for synthetic data on various types of counterfactuals. Additionally, while existing membership inference attacks against counterfactuals usually require to be able to query the model, we show how it is possible to perform successful membership inference attacks using only a set of counterfactuals, with no access to the model from which they are generated. Our results demonstrate that model developers should be more cautious when releasing counterfactuals to various users, as it can lead to a privacy breach.
Smooth Sensitivity for Learning Differentially-Private yet Accurate Rule Lists
Mar 18, 2024



Differentially-private (DP) mechanisms can be embedded into the design of a machine learningalgorithm to protect the resulting model against privacy leakage, although this often comes with asignificant loss of accuracy. In this paper, we aim at improving this trade-off for rule lists modelsby establishing the smooth sensitivity of the Gini impurity and leveraging it to propose a DP greedyrule list algorithm. In particular, our theoretical analysis and experimental results demonstrate thatthe DP rule lists models integrating smooth sensitivity have higher accuracy that those using otherDP frameworks based on global sensitivity.
Fairness via Explanation Quality: Evaluating Disparities in the Quality of Post hoc Explanations
May 15, 2022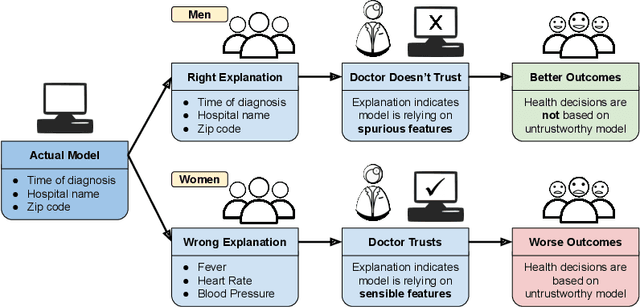
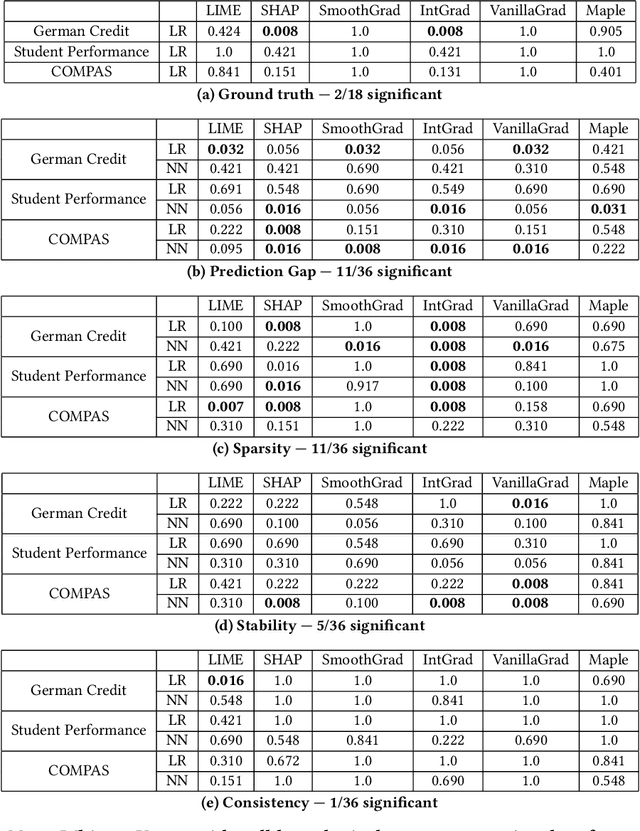
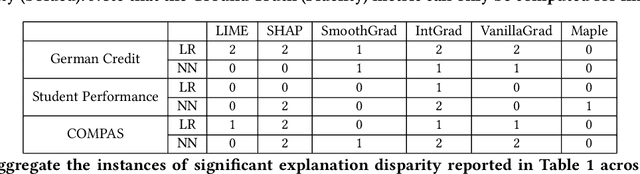
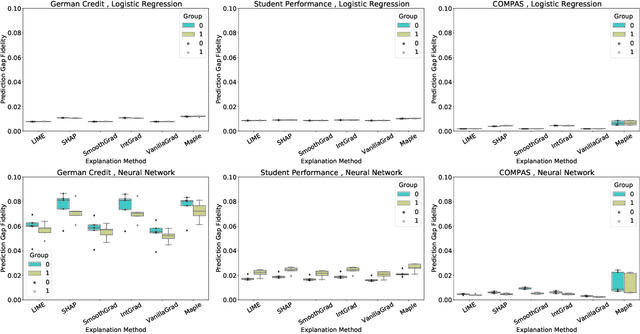
As post hoc explanation methods are increasingly being leveraged to explain complex models in high-stakes settings, it becomes critical to ensure that the quality of the resulting explanations is consistently high across various population subgroups including the minority groups. For instance, it should not be the case that explanations associated with instances belonging to a particular gender subgroup (e.g., female) are less accurate than those associated with other genders. However, there is little to no research that assesses if there exist such group-based disparities in the quality of the explanations output by state-of-the-art explanation methods. In this work, we address the aforementioned gaps by initiating the study of identifying group-based disparities in explanation quality. To this end, we first outline the key properties which constitute explanation quality and where disparities can be particularly problematic. We then leverage these properties to propose a novel evaluation framework which can quantitatively measure disparities in the quality of explanations output by state-of-the-art methods. Using this framework, we carry out a rigorous empirical analysis to understand if and when group-based disparities in explanation quality arise. Our results indicate that such disparities are more likely to occur when the models being explained are complex and highly non-linear. In addition, we also observe that certain post hoc explanation methods (e.g., Integrated Gradients, SHAP) are more likely to exhibit the aforementioned disparities. To the best of our knowledge, this work is the first to highlight and study the problem of group-based disparities in explanation quality. In doing so, our work sheds light on previously unexplored ways in which explanation methods may introduce unfairness in real world decision making.