 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Stem to Stern: Contestability Along AI Value Chains
Aug 02, 2024
This workshop will grow and consolidate a community of interdisciplinary CSCW researchers focusing on the topic of contestable AI. As an outcome of the workshop, we will synthesize the most pressing opportunities and challenges for contestability along AI value chains in the form of a research roadmap. This roadmap will help shape and inspire imminent work in this field. Considering the length and depth of AI value chains, it will especially spur discussions around the contestability of AI systems along various sites of such chains. The workshop will serve as a platform for dialogue and demonstrations of concrete, successful, and unsuccessful examples of AI systems that (could or should) have been contested, to identify requirements, obstacles, and opportunities for designing and deploying contestable AI in various contexts. This will be held primarily as an in-person workshop, with some hybrid accommodation. The day will consist of individual presentations and group activities to stimulate ideation and inspire broad reflections on the field of contestable AI. Our aim is to facilitate interdisciplinary dialogue by bringing together researchers, practitioners, and stakeholders to foster the design and deployment of contestable AI.
Metric Elicitation; Moving from Theory to Practice
Dec 07, 2022



Metric Elicitation (ME) is a framework for eliciting classification metrics that better align with implicit user preferences based on the task and context. The existing ME strategy so far is based on the assumption that users can most easily provide preference feedback over classifier statistics such as confusion matrices. This work examines ME, by providing a first ever implementation of the ME strategy. Specifically, we create a web-based ME interface and conduct a user study that elicits users' preferred metrics in a binary classification setting. We discuss the study findings and present guidelines for future research in this direction.
Fairness via Explanation Quality: Evaluating Disparities in the Quality of Post hoc Explanations
May 15, 2022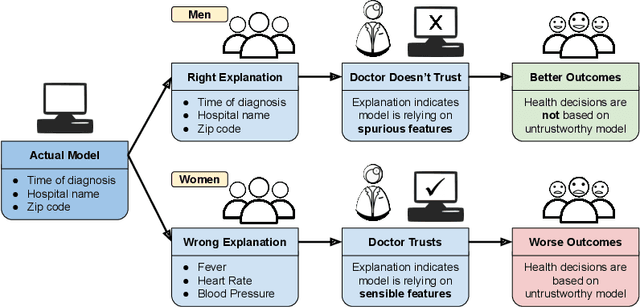
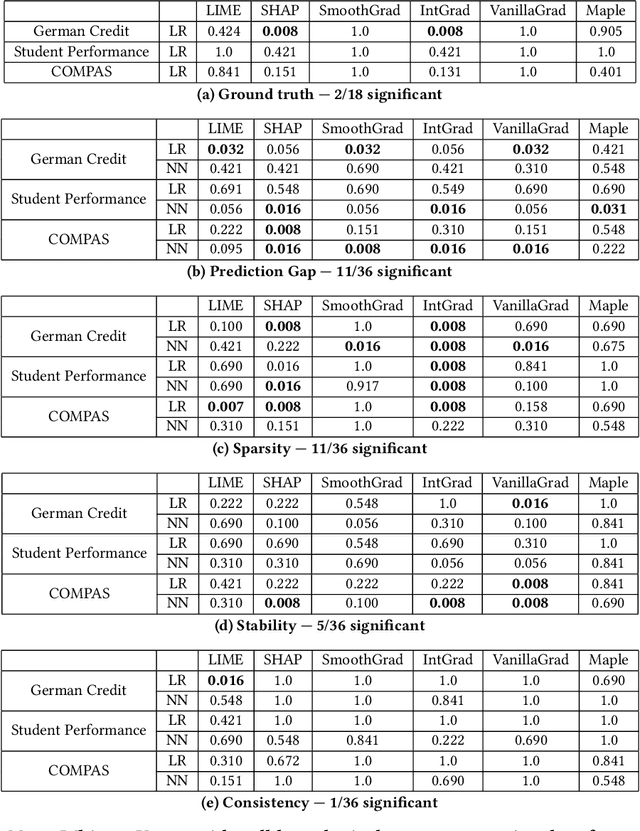
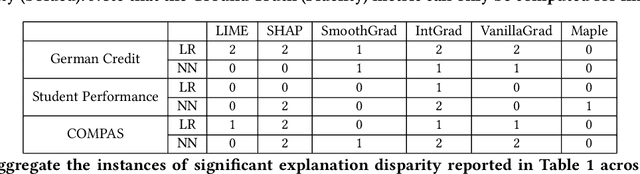
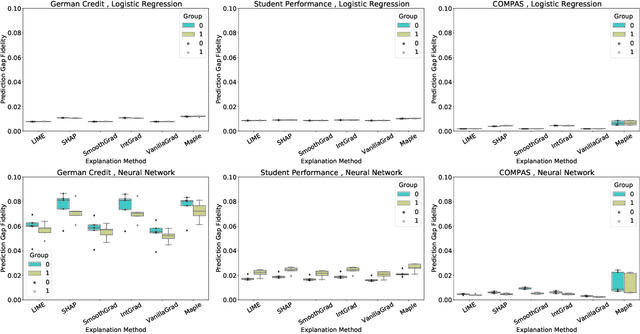
As post hoc explanation methods are increasingly being leveraged to explain complex models in high-stakes settings, it becomes critical to ensure that the quality of the resulting explanations is consistently high across various population subgroups including the minority groups. For instance, it should not be the case that explanations associated with instances belonging to a particular gender subgroup (e.g., female) are less accurate than those associated with other genders. However, there is little to no research that assesses if there exist such group-based disparities in the quality of the explanations output by state-of-the-art explanation methods. In this work, we address the aforementioned gaps by initiating the study of identifying group-based disparities in explanation quality. To this end, we first outline the key properties which constitute explanation quality and where disparities can be particularly problematic. We then leverage these properties to propose a novel evaluation framework which can quantitatively measure disparities in the quality of explanations output by state-of-the-art methods. Using this framework, we carry out a rigorous empirical analysis to understand if and when group-based disparities in explanation quality arise. Our results indicate that such disparities are more likely to occur when the models being explained are complex and highly non-linear. In addition, we also observe that certain post hoc explanation methods (e.g., Integrated Gradients, SHAP) are more likely to exhibit the aforementioned disparities. To the best of our knowledge, this work is the first to highlight and study the problem of group-based disparities in explanation quality. In doing so, our work sheds light on previously unexplored ways in which explanation methods may introduce unfairness in real world decision making.
Extending LIME for Business Process Automation
Aug 09, 2021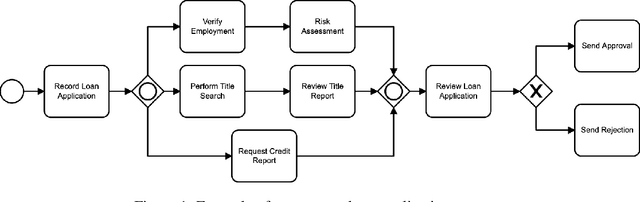

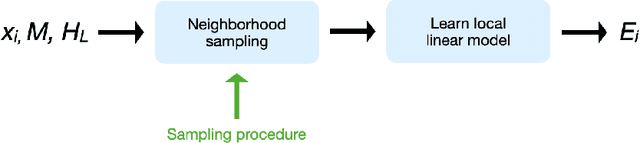
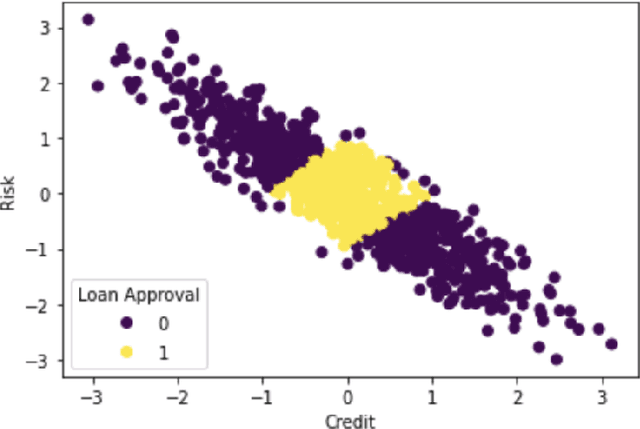
AI business process applications automate high-stakes business decisions where there is an increasing demand to justify or explain the rationale behind algorithmic decisions. Business process applications have ordering or constraints on tasks and feature values that cause lightweight, model-agnostic, existing explanation methods like LIME to fail. In response, we propose a local explanation framework extending LIME for explaining AI business process applications. Empirical evaluation of our extension underscores the advantage of our approach in the business process setting.
What will it take to generate fairness-preserving explanations?
Jun 24, 2021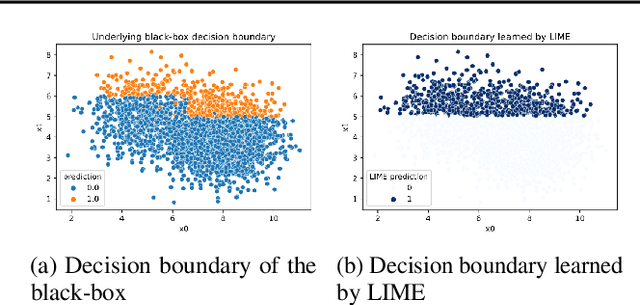
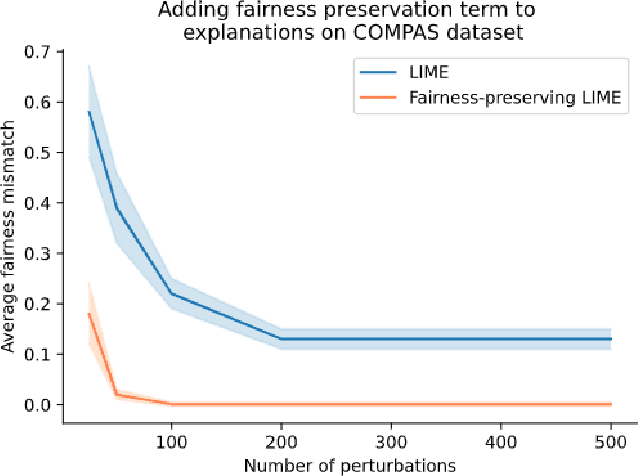
In situations where explanations of black-box models may be useful, the fairness of the black-box is also often a relevant concern. However, the link between the fairness of the black-box model and the behavior of explanations for the black-box is unclear. We focus on explanations applied to tabular datasets, suggesting that explanations do not necessarily preserve the fairness properties of the black-box algorithm. In other words, explanation algorithms can ignore or obscure critical relevant properties, creating incorrect or misleading explanations. More broadly, we propose future research directions for evaluating and generating explanations such that they are informative and relevant from a fairness perspective.
On the Connections between Counterfactual Explanations and Adversarial Examples
Jun 18, 2021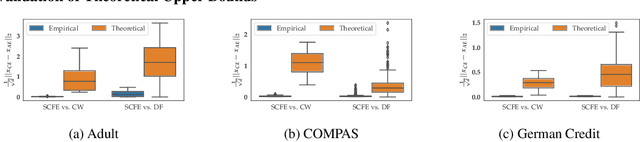
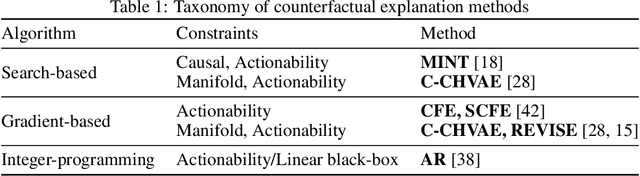
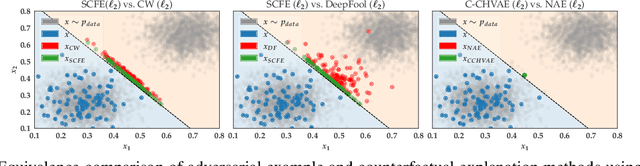

Counterfactual explanations and adversarial examples have emerged as critical research areas for addressing the explainability and robustness goals of machine learning (ML). While counterfactual explanations were developed with the goal of providing recourse to individuals adversely impacted by algorithmic decisions, adversarial examples were designed to expose the vulnerabilities of ML models. While prior research has hinted at the commonalities between these frameworks, there has been little to no work on systematically exploring the connections between the literature on counterfactual explanations and adversarial examples. In this work, we make one of the first attempts at formalizing the connections between counterfactual explanations and adversarial examples. More specifically, we theoretically analyze salient counterfactual explanation and adversarial example generation methods, and highlight the conditions under which they behave similarly. Our analysis demonstrates that several popular counterfactual explanation and adversarial example generation methods such as the ones proposed by Wachter et. al. and Carlini and Wagner (with mean squared error loss), and C-CHVAE and natural adversarial examples by Zhao et. al. are equivalent. We also bound the distance between counterfactual explanations and adversarial examples generated by Wachter et. al. and DeepFool methods for linear models. Finally, we empirically validate our theoretical findings using extensive experimentation with synthetic and real world datasets.
Towards Robust and Reliable Algorithmic Recourse
Feb 26, 2021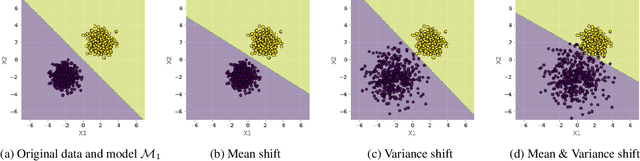
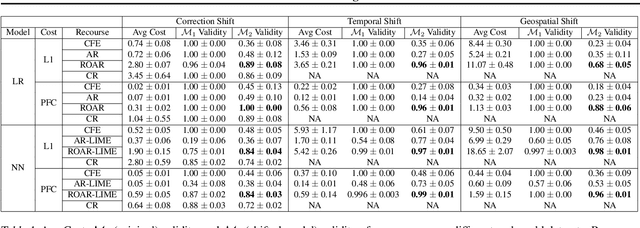
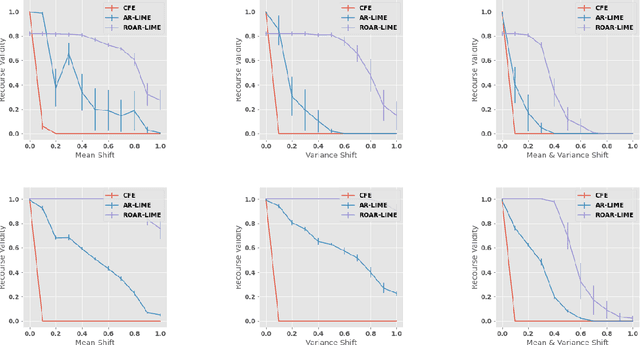
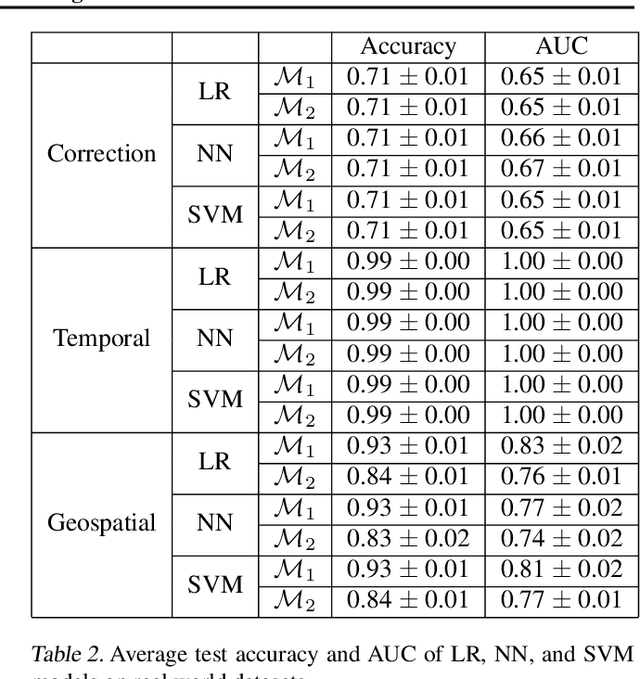
As predictive models are increasingly being deployed in high-stakes decision making (e.g., loan approvals), there has been growing interest in post hoc techniques which provide recourse to affected individuals. These techniques generate recourses under the assumption that the underlying predictive model does not change. However, in practice, models are often regularly updated for a variety of reasons (e.g., dataset shifts), thereby rendering previously prescribed recourses ineffective. To address this problem, we propose a novel framework, RObust Algorithmic Recourse (ROAR), that leverages adversarial training for finding recourses that are robust to model shifts. To the best of our knowledge, this work proposes the first solution to this critical problem. We also carry out detailed theoretical analysis which underscores the importance of constructing recourses that are robust to model shifts: 1) we derive a lower bound on the probability of invalidation of recourses generated by existing approaches which are not robust to model shifts. 2) we prove that the additional cost incurred due to the robust recourses output by our framework is bounded. Experimental evaluation on multiple synthetic and real-world datasets demonstrates the efficacy of the proposed framework and supports our theoretical findings.
Towards the Unification and Robustness of Perturbation and Gradient Based Explanations
Feb 21, 2021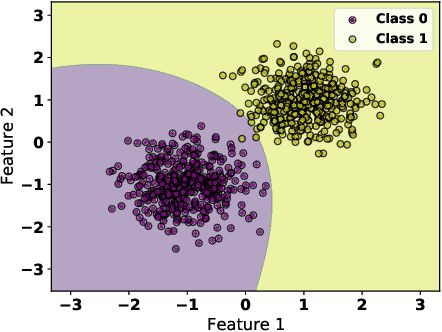
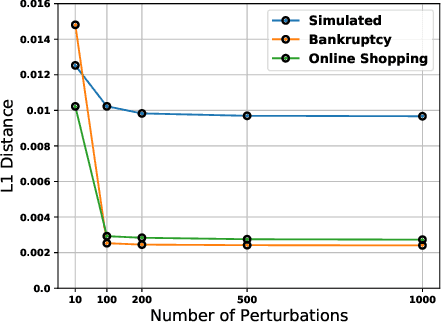
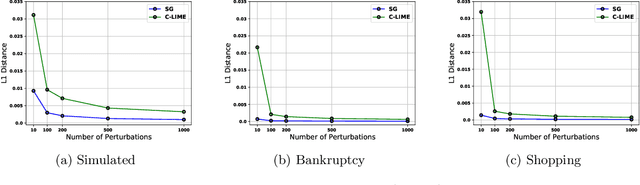
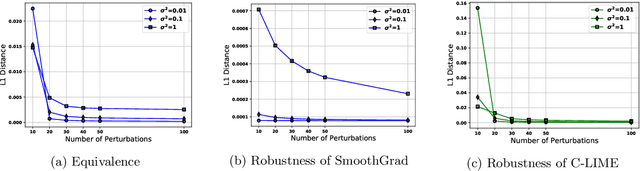
As machine learning black boxes are increasingly being deployed in critical domains such as healthcare and criminal justice, there has been a growing emphasis on developing techniques for explaining these black boxes in a post hoc manner. In this work, we analyze two popular post hoc interpretation techniques: SmoothGrad which is a gradient based method, and a variant of LIME which is a perturbation based method. More specifically, we derive explicit closed form expressions for the explanations output by these two methods and show that they both converge to the same explanation in expectation, i.e., when the number of perturbed samples used by these methods is large. We then leverage this connection to establish other desirable properties, such as robustness, for these techniques. We also derive finite sample complexity bounds for the number of perturbations required for these methods to converge to their expected explanation. Finally, we empirically validate our theory using extensive experimentation on both synthetic and real world datasets.
Online Semi-Supervised Learning with Bandit Feedback
Oct 23, 2020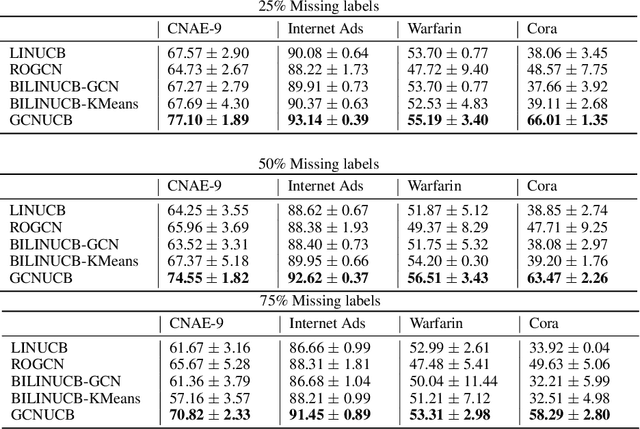
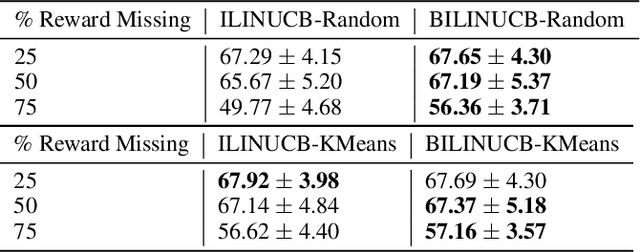
We formulate a new problem at the intersectionof semi-supervised learning and contextual bandits,motivated by several applications including clini-cal trials and ad recommendations. We demonstratehow Graph Convolutional Network (GCN), a semi-supervised learning approach, can be adjusted tothe new problem formulation. We also propose avariant of the linear contextual bandit with semi-supervised missing rewards imputation. We thentake the best of both approaches to develop multi-GCN embedded contextual bandit. Our algorithmsare verified on several real world datasets.
Double-Linear Thompson Sampling for Context-Attentive Bandits
Oct 15, 2020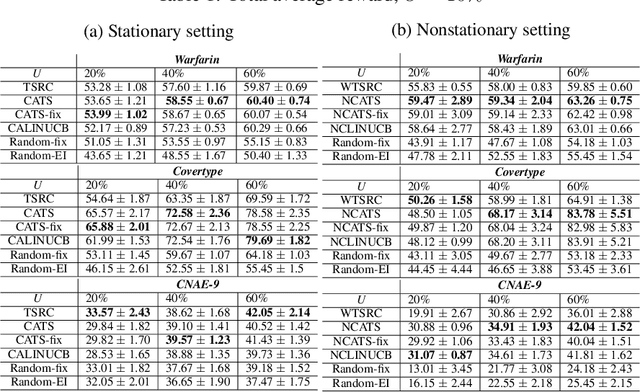
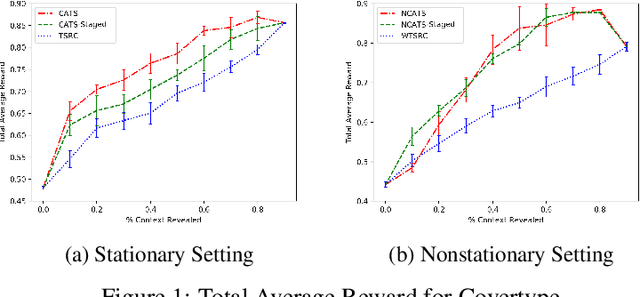
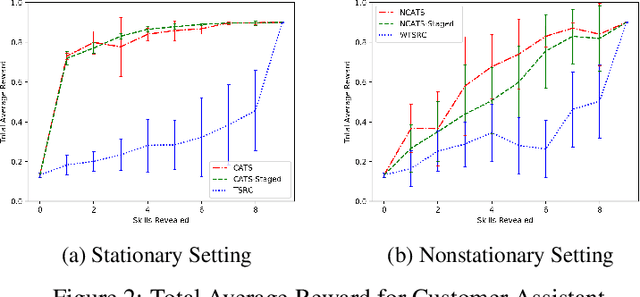
In this paper, we analyze and extend an online learning framework known as Context-Attentive Bandit, motivated by various practical applications, from medical diagnosis to dialog systems, where due to observation costs only a small subset of a potentially large number of context variables can be observed at each iteration;however, the agent has a freedom to choose which variables to observe. We derive a novel algorithm, called Context-Attentive Thompson Sampling (CATS), which builds upon the Linear Thompson Sampling approach, adapting it to Context-Attentive Bandit setting. We provide a theoretical regret analysis and an extensive empirical evaluation demonstrating advantages of the proposed approach over several baseline methods on a variety of real-life datasets