 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Emergence of Objectness: Learning Zero-Shot Segmentation from Videos
Nov 11, 2021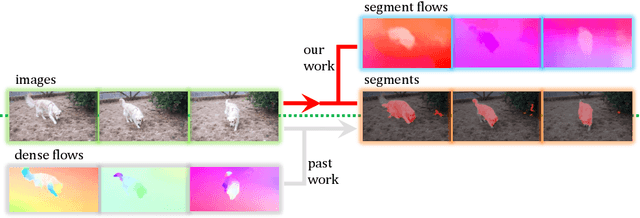

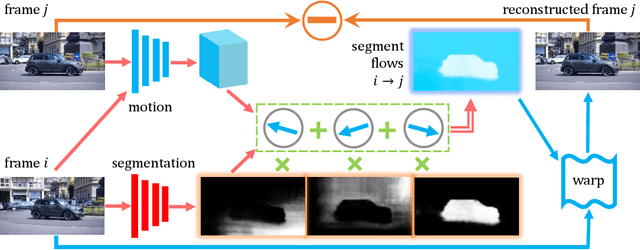

Humans can easily segment moving objects without knowing what they are. That objectness could emerge from continuous visual observations motivates us to model grouping and movement concurrently from unlabeled videos. Our premise is that a video has different views of the same scene related by moving components, and the right region segmentation and region flow would allow mutual view synthesis which can be checked from the data itself without any external supervision. Our model starts with two separate pathways: an appearance pathway that outputs feature-based region segmentation for a single image, and a motion pathway that outputs motion features for a pair of images. It then binds them in a conjoint representation called segment flow that pools flow offsets over each region and provides a gross characterization of moving regions for the entire scene. By training the model to minimize view synthesis errors based on segment flow, our appearance and motion pathways learn region segmentation and flow estimation automatically without building them up from low-level edges or optical flows respectively. Our model demonstrates the surprising emergence of objectness in the appearance pathway, surpassing prior works on zero-shot object segmentation from an image, moving object segmentation from a video with unsupervised test-time adaptation, and semantic image segmentation by supervised fine-tuning. Our work is the first truly end-to-end zero-shot object segmentation from videos. It not only develops generic objectness for segmentation and tracking, but also outperforms prevalent image-based contrastive learning methods without augmentation engineering.
Data-Centric Semi-Supervised Learning
Oct 06, 2021

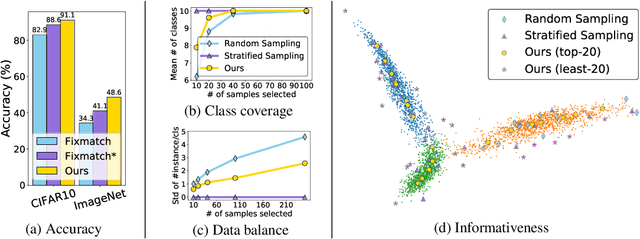

We study unsupervised data selection for semi-supervised learning (SSL), where a large-scale unlabeled data is available and a small subset of data is budgeted for label acquisition. Existing SSL methods focus on learning a model that effectively integrates information from given small labeled data and large unlabeled data, whereas we focus on selecting the right data for SSL without any label or task information, in an also stark contrast to supervised data selection for active learning. Intuitively, instances to be labeled shall collectively have maximum diversity and coverage for downstream tasks, and individually have maximum information propagation utility for SSL. We formalize these concepts in a three-step data-centric SSL method that improves FixMatch in stability and accuracy by 8% on CIFAR-10 (0.08% labeled) and 14% on ImageNet-1K (0.2% labeled). Our work demonstrates that a small compute spent on careful labeled data selection brings big annotation efficiency and model performance gain without changing the learning pipeline. Our completely unsupervised data selection can be easily extended to other weakly supervised learning settings.
Free Hyperbolic Neural Networks with Limited Radii
Jul 23, 2021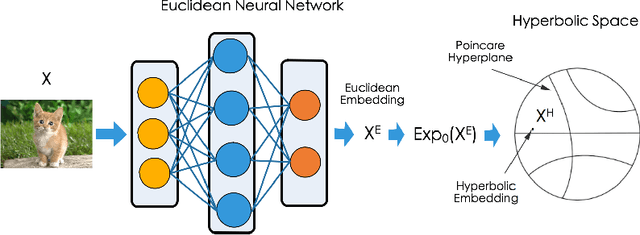

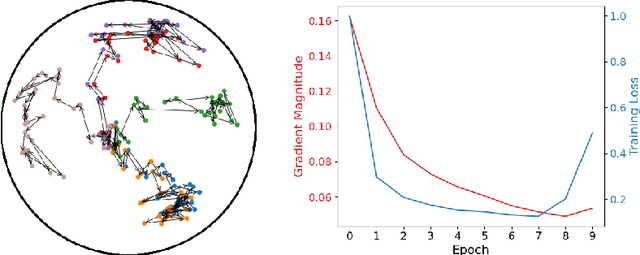

Non-Euclidean geometry with constant negative curvature, i.e., hyperbolic space, has attracted sustained attention in the community of machine learning. Hyperbolic space, owing to its ability to embed hierarchical structures continuously with low distortion, has been applied for learning data with tree-like structures. Hyperbolic Neural Networks (HNNs) that operate directly in hyperbolic space have also been proposed recently to further exploit the potential of hyperbolic representations. While HNNs have achieved better performance than Euclidean neural networks (ENNs) on datasets with implicit hierarchical structure, they still perform poorly on standard classification benchmarks such as CIFAR and ImageNet. The traditional wisdom is that it is critical for the data to respect the hyperbolic geometry when applying HNNs. In this paper, we first conduct an empirical study showing that the inferior performance of HNNs on standard recognition datasets can be attributed to the notorious vanishing gradient problem. We further discovered that this problem stems from the hybrid architecture of HNNs. Our analysis leads to a simple yet effective solution called Feature Clipping, which regularizes the hyperbolic embedding whenever its norm exceeding a given threshold. Our thorough experiments show that the proposed method can successfully avoid the vanishing gradient problem when training HNNs with backpropagation. The improved HNNs are able to achieve comparable performance with ENNs on standard image recognition datasets including MNIST, CIFAR10, CIFAR100 and ImageNet, while demonstrating more adversarial robustness and stronger out-of-distribution detection capability.
Recurrent Parameter Generators
Jul 15, 2021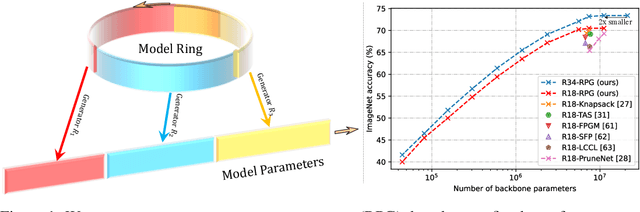
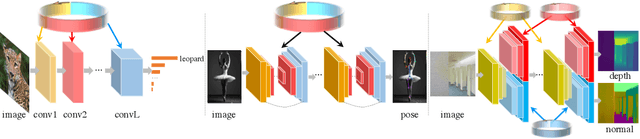
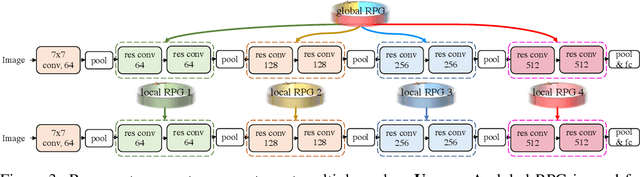

We present a generic method for recurrently using the same parameters for many different convolution layers to build a deep network. Specifically, for a network, we create a recurrent parameter generator (RPG), from which the parameters of each convolution layer are generated. Though using recurrent models to build a deep convolutional neural network (CNN) is not entirely new, our method achieves significant performance gain compared to the existing works. We demonstrate how to build a one-layer neural network to achieve similar performance compared to other traditional CNN models on various applications and datasets. Such a method allows us to build an arbitrarily complex neural network with any amount of parameters. For example, we build a ResNet34 with model parameters reduced by more than $400$ times, which still achieves $41.6\%$ ImageNet top-1 accuracy. Furthermore, we demonstrate the RPG can be applied at different scales, such as layers, blocks, or even sub-networks. Specifically, we use the RPG to build a ResNet18 network with the number of weights equivalent to one convolutional layer of a conventional ResNet and show this model can achieve $67.2\%$ ImageNet top-1 accuracy. The proposed method can be viewed as an inverse approach to model compression. Rather than removing the unused parameters from a large model, it aims to squeeze more information into a small number of parameters. Extensive experiment results are provided to demonstrate the power of the proposed recurrent parameter generator.
Unsupervised Discriminative Learning of Sounds for Audio Event Classification
May 20, 2021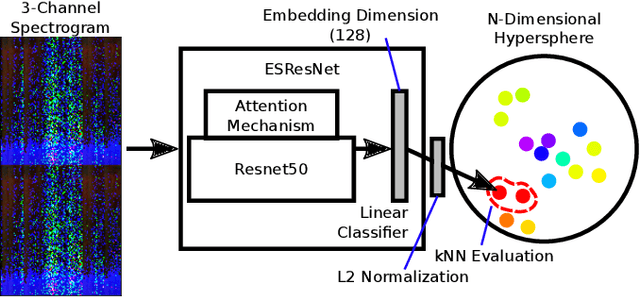
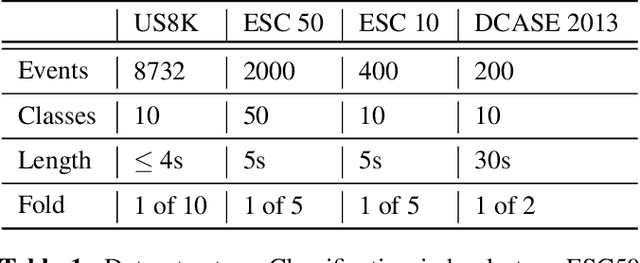
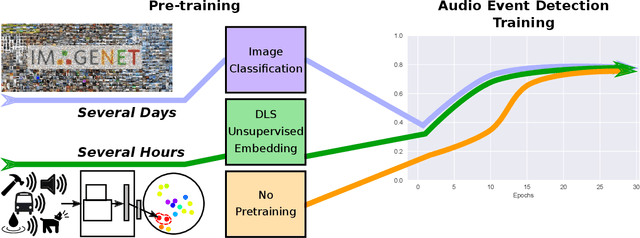

Recent progress in network-based audio event classification has shown the benefit of pre-training models on visual data such as ImageNet. While this process allows knowledge transfer across different domains, training a model on large-scale visual datasets is time consuming. On several audio event classification benchmarks, we show a fast and effective alternative that pre-trains the model unsupervised, only on audio data and yet delivers on-par performance with ImageNet pre-training. Furthermore, we show that our discriminative audio learning can be used to transfer knowledge across audio datasets and optionally include ImageNet pre-training.
Universal Weakly Supervised Segmentation by Pixel-to-Segment Contrastive Learning
May 11, 2021
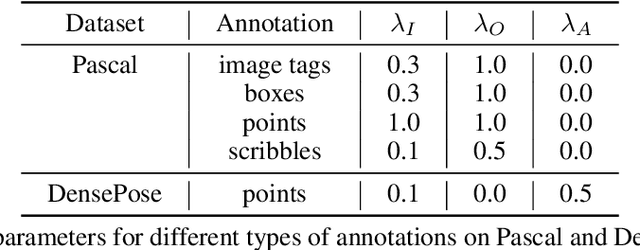
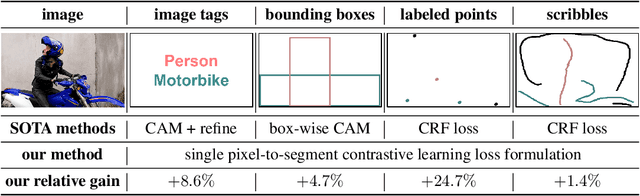
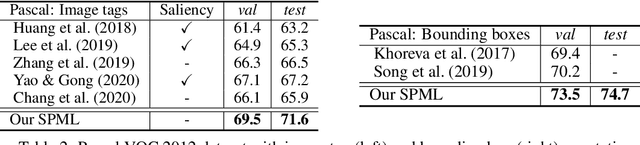
Weakly supervised segmentation requires assigning a label to every pixel based on training instances with partial annotations such as image-level tags, object bounding boxes, labeled points and scribbles. This task is challenging, as coarse annotations (tags, boxes) lack precise pixel localization whereas sparse annotations (points, scribbles) lack broad region coverage. Existing methods tackle these two types of weak supervision differently: Class activation maps are used to localize coarse labels and iteratively refine the segmentation model, whereas conditional random fields are used to propagate sparse labels to the entire image. We formulate weakly supervised segmentation as a semi-supervised metric learning problem, where pixels of the same (different) semantics need to be mapped to the same (distinctive) features. We propose 4 types of contrastive relationships between pixels and segments in the feature space, capturing low-level image similarity, semantic annotation, co-occurrence, and feature affinity They act as priors; the pixel-wise feature can be learned from training images with any partial annotations in a data-driven fashion. In particular, unlabeled pixels in training images participate not only in data-driven grouping within each image, but also in discriminative feature learning within and across images. We deliver a universal weakly supervised segmenter with significant gains on Pascal VOC and DensePose. Our code is publicly available at https://github.com/twke18/SPML.
Iterative Human and Automated Identification of Wildlife Images
May 05, 2021
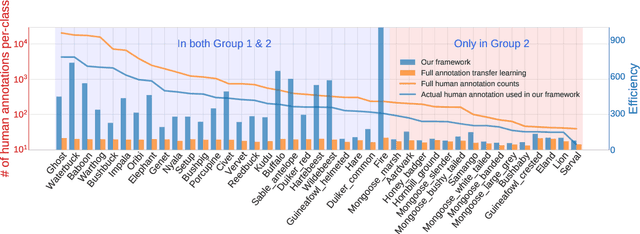
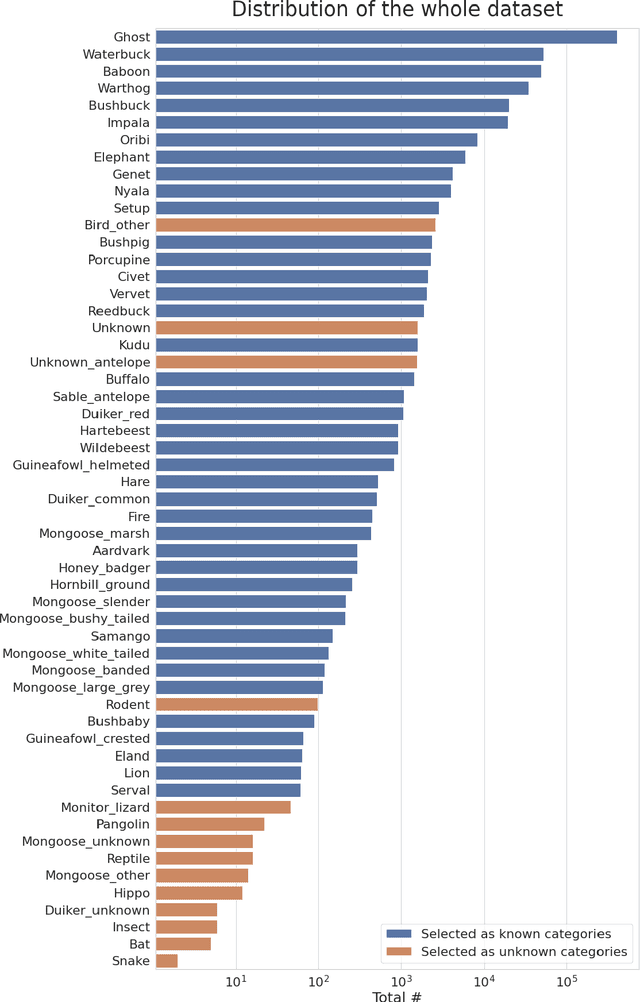
Camera trapping is increasingly used to monitor wildlife, but this technology typically requires extensive data annotation. Recently, deep learning has significantly advanced automatic wildlife recognition. However, current methods are hampered by a dependence on large static data sets when wildlife data is intrinsically dynamic and involves long-tailed distributions. These two drawbacks can be overcome through a hybrid combination of machine learning and humans in the loop. Our proposed iterative human and automated identification approach is capable of learning from wildlife imagery data with a long-tailed distribution. Additionally, it includes self-updating learning that facilitates capturing the community dynamics of rapidly changing natural systems. Extensive experiments show that our approach can achieve a ~90% accuracy employing only ~20% of the human annotations of existing approaches. Our synergistic collaboration of humans and machines transforms deep learning from a relatively inefficient post-annotation tool to a collaborative on-going annotation tool that vastly relieves the burden of human annotation and enables efficient and constant model updates.
Unsupervised Visual Attention and Invariance for Reinforcement Learning
Apr 16, 2021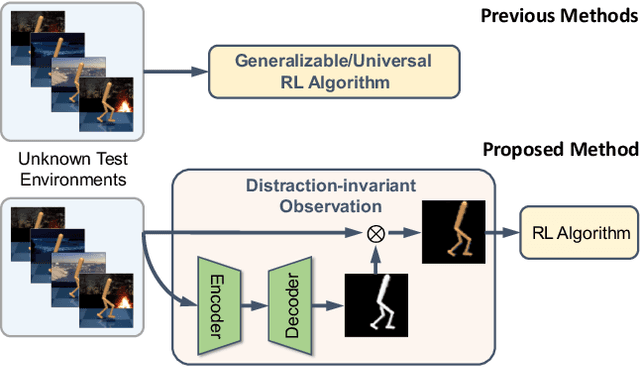
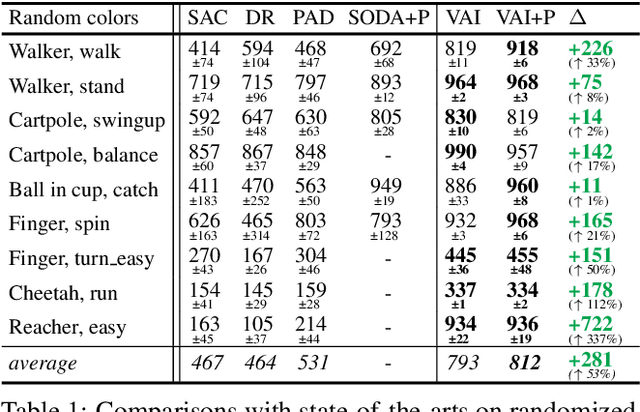
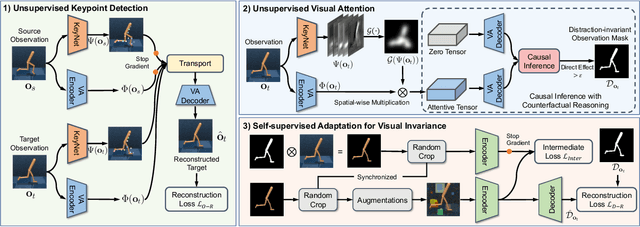
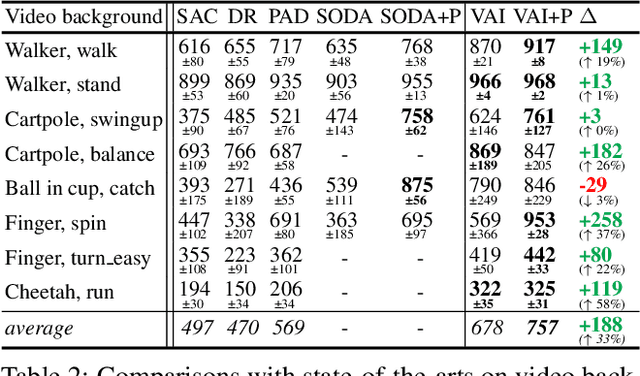
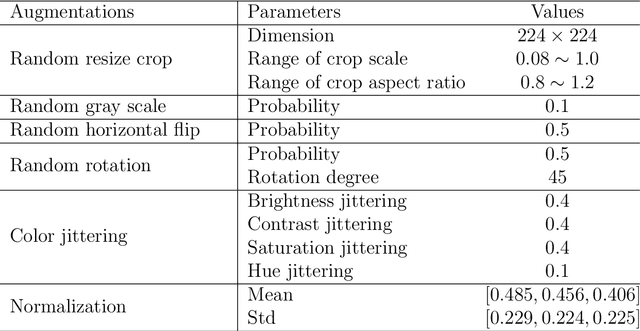
Vision-based reinforcement learning (RL) is successful, but how to generalize it to unknown test environments remains challenging. Existing methods focus on training an RL policy that is universal to changing visual domains, whereas we focus on extracting visual foreground that is universal, feeding clean invariant vision to the RL policy learner. Our method is completely unsupervised, without manual annotations or access to environment internals. Given videos of actions in a training environment, we learn how to extract foregrounds with unsupervised keypoint detection, followed by unsupervised visual attention to automatically generate a foreground mask per video frame. We can then introduce artificial distractors and train a model to reconstruct the clean foreground mask from noisy observations. Only this learned model is needed during test to provide distraction-free visual input to the RL policy learner. Our Visual Attention and Invariance (VAI) method significantly outperforms the state-of-the-art on visual domain generalization, gaining 15 to 49% (61 to 229%) more cumulative rewards per episode on DeepMind Control (our DrawerWorld Manipulation) benchmarks. Our results demonstrate that it is not only possible to learn domain-invariant vision without any supervision, but freeing RL from visual distractions also makes the policy more focused and thus far better.
Memory-efficient Learning for High-Dimensional MRI Reconstruction
Mar 06, 2021

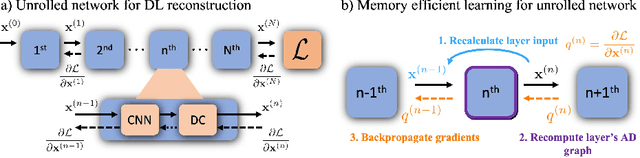
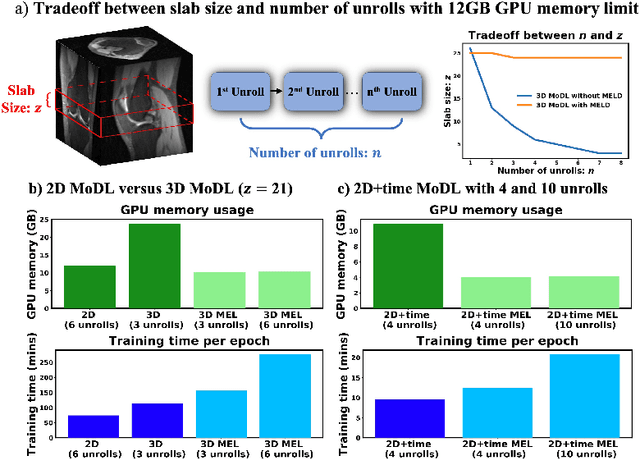
Deep learning (DL) based unrolled reconstructions have shown state-of-the-art performance for under-sampled magnetic resonance imaging (MRI). Similar to compressed sensing, DL can leverage high-dimensional data (e.g. 3D, 2D+time, 3D+time) to further improve performance. However, network size and depth are currently limited by the GPU memory required for backpropagation. Here we use a memory-efficient learning (MEL) framework which favorably trades off storage with a manageable increase in computation during training. Using MEL with multi-dimensional data, we demonstrate improved image reconstruction performance for in-vivo 3D MRI and 2D+time cardiac cine MRI. MEL uses far less GPU memory while marginally increasing the training time, which enables new applications of DL to high-dimensional MRI.
Long-tailed Recognition by Routing Diverse Distribution-Aware Experts
Oct 05, 2020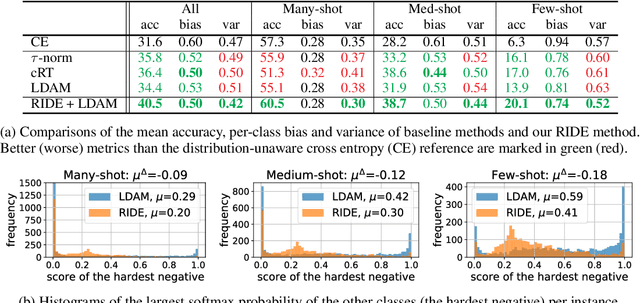
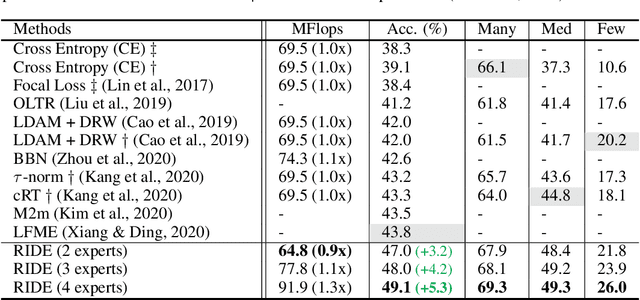
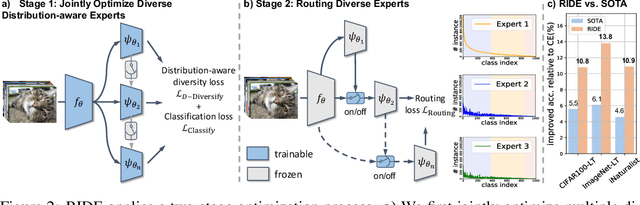
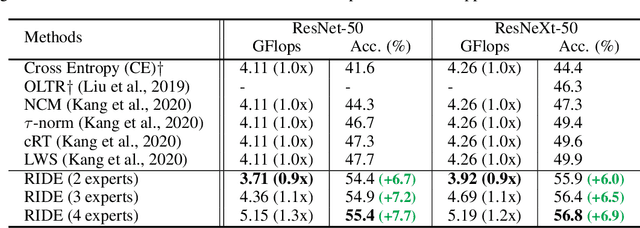
Natural data are often long-tail distributed over semantic classes. Existing recognition methods tend to focus on tail performance gain, often at the expense of head performance loss from increased classifier variance. The low tail performance manifests itself in large inter-class confusion and high classifier variance. We aim to reduce both the bias and the variance of a long-tailed classifier by RoutIng Diverse Experts (RIDE). It has three components: 1) a shared architecture for multiple classifiers (experts); 2) a distribution-aware diversity loss that encourages more diverse decisions for classes with fewer training instances; and 3) an expert routing module that dynamically assigns more ambiguous instances to additional experts. With on-par computational complexity, RIDE significantly outperforms the state-of-the-art methods by 5% to 7% on all the benchmarks including CIFAR100-LT, ImageNet-LT and iNaturalist. RIDE is also a universal framework that can be applied to different backbone networks and integrated into various long-tailed algorithms and training mechanisms for consistent performance gains.