 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDebiased Learning for Remote Sensing Data
Dec 24, 2023Deep learning has had remarkable success at analyzing handheld imagery such as consumer photos due to the availability of large-scale human annotations (e.g., ImageNet). However, remote sensing data lacks such extensive annotation and thus potential for supervised learning. To address this, we propose a highly effective semi-supervised approach tailored specifically to remote sensing data. Our approach encompasses two key contributions. First, we adapt the FixMatch framework to remote sensing data by designing robust strong and weak augmentations suitable for this domain. Second, we develop an effective semi-supervised learning method by removing bias in imbalanced training data resulting from both actual labels and pseudo-labels predicted by the model. Our simple semi-supervised framework was validated by extensive experimentation. Using 30\% of labeled annotations, it delivers a 7.1\% accuracy gain over the supervised learning baseline and a 2.1\% gain over the supervised state-of-the-art CDS method on the remote sensing xView dataset.
Zero-shot Building Attribute Extraction from Large-Scale Vision and Language Models
Dec 19, 2023



Existing building recognition methods, exemplified by BRAILS, utilize supervised learning to extract information from satellite and street-view images for classification and segmentation. However, each task module requires human-annotated data, hindering the scalability and robustness to regional variations and annotation imbalances. In response, we propose a new zero-shot workflow for building attribute extraction that utilizes large-scale vision and language models to mitigate reliance on external annotations. The proposed workflow contains two key components: image-level captioning and segment-level captioning for the building images based on the vocabularies pertinent to structural and civil engineering. These two components generate descriptive captions by computing feature representations of the image and the vocabularies, and facilitating a semantic match between the visual and textual representations. Consequently, our framework offers a promising avenue to enhance AI-driven captioning for building attribute extraction in the structural and civil engineering domains, ultimately reducing reliance on human annotations while bolstering performance and adaptability.
How to guess a gradient
Dec 07, 2023How much can you say about the gradient of a neural network without computing a loss or knowing the label? This may sound like a strange question: surely the answer is "very little." However, in this paper, we show that gradients are more structured than previously thought. Gradients lie in a predictable low-dimensional subspace which depends on the network architecture and incoming features. Exploiting this structure can significantly improve gradient-free optimization schemes based on directional derivatives, which have struggled to scale beyond small networks trained on toy datasets. We study how to narrow the gap in optimization performance between methods that calculate exact gradients and those that use directional derivatives. Furthermore, we highlight new challenges in overcoming the large gap between optimizing with exact gradients and guessing the gradients.
Learning to Transform for Generalizable Instance-wise Invariance
Sep 28, 2023Computer vision research has long aimed to build systems that are robust to spatial transformations found in natural data. Traditionally, this is done using data augmentation or hard-coding invariances into the architecture. However, too much or too little invariance can hurt, and the correct amount is unknown a priori and dependent on the instance. Ideally, the appropriate invariance would be learned from data and inferred at test-time. We treat invariance as a prediction problem. Given any image, we use a normalizing flow to predict a distribution over transformations and average the predictions over them. Since this distribution only depends on the instance, we can align instances before classifying them and generalize invariance across classes. The same distribution can also be used to adapt to out-of-distribution poses. This normalizing flow is trained end-to-end and can learn a much larger range of transformations than Augerino and InstaAug. When used as data augmentation, our method shows accuracy and robustness gains on CIFAR 10, CIFAR10-LT, and TinyImageNet.
VEATIC: Video-based Emotion and Affect Tracking in Context Dataset
Sep 15, 2023



Human affect recognition has been a significant topic in psychophysics and computer vision. However, the currently published datasets have many limitations. For example, most datasets contain frames that contain only information about facial expressions. Due to the limitations of previous datasets, it is very hard to either understand the mechanisms for affect recognition of humans or generalize well on common cases for computer vision models trained on those datasets. In this work, we introduce a brand new large dataset, the Video-based Emotion and Affect Tracking in Context Dataset (VEATIC), that can conquer the limitations of the previous datasets. VEATIC has 124 video clips from Hollywood movies, documentaries, and home videos with continuous valence and arousal ratings of each frame via real-time annotation. Along with the dataset, we propose a new computer vision task to infer the affect of the selected character via both context and character information in each video frame. Additionally, we propose a simple model to benchmark this new computer vision task. We also compare the performance of the pretrained model using our dataset with other similar datasets. Experiments show the competing results of our pretrained model via VEATIC, indicating the generalizability of VEATIC. Our dataset is available at https://veatic.github.io.
Coordinate-based neural representations for computational adaptive optics in widefield microscopy
Jul 07, 2023Widefield microscopy is widely used for non-invasive imaging of biological structures at subcellular resolution. When applied to complex specimen, its image quality is degraded by sample-induced optical aberration. Adaptive optics can correct wavefront distortion and restore diffraction-limited resolution but require wavefront sensing and corrective devices, increasing system complexity and cost. Here, we describe a self-supervised machine learning algorithm, CoCoA, that performs joint wavefront estimation and three-dimensional structural information extraction from a single input 3D image stack without the need for external training dataset. We implemented CoCoA for widefield imaging of mouse brain tissues and validated its performance with direct-wavefront-sensing-based adaptive optics. Importantly, we systematically explored and quantitatively characterized the limiting factors of CoCoA's performance. Using CoCoA, we demonstrated the first in vivo widefield mouse brain imaging using machine-learning-based adaptive optics. Incorporating coordinate-based neural representations and a forward physics model, the self-supervised scheme of CoCoA should be applicable to microscopy modalities in general.
Unsupervised Feature Learning with Emergent Data-Driven Prototypicality
Jul 04, 2023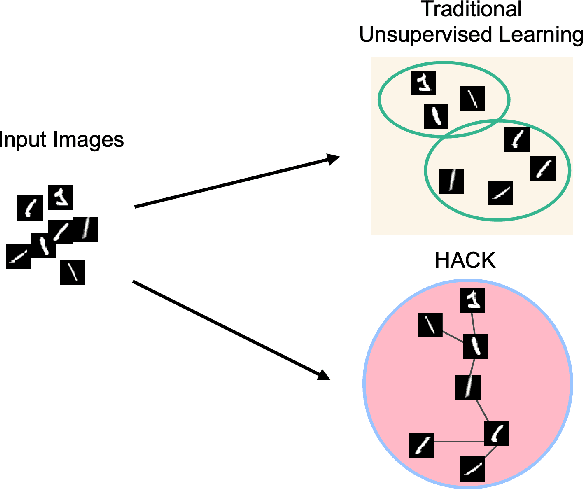


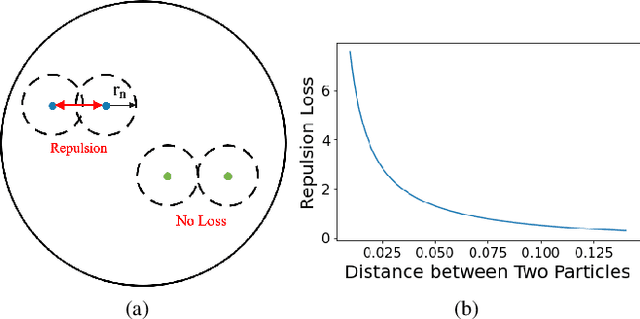
Given an image set without any labels, our goal is to train a model that maps each image to a point in a feature space such that, not only proximity indicates visual similarity, but where it is located directly encodes how prototypical the image is according to the dataset. Our key insight is to perform unsupervised feature learning in hyperbolic instead of Euclidean space, where the distance between points still reflect image similarity, and yet we gain additional capacity for representing prototypicality with the location of the point: The closer it is to the origin, the more prototypical it is. The latter property is simply emergent from optimizing the usual metric learning objective: The image similar to many training instances is best placed at the center of corresponding points in Euclidean space, but closer to the origin in hyperbolic space. We propose an unsupervised feature learning algorithm in Hyperbolic space with sphere pACKing. HACK first generates uniformly packed particles in the Poincar\'e ball of hyperbolic space and then assigns each image uniquely to each particle. Images after congealing are regarded more typical of the dataset it belongs to. With our feature mapper simply trained to spread out training instances in hyperbolic space, we observe that images move closer to the origin with congealing, validating our idea of unsupervised prototypicality discovery. We demonstrate that our data-driven prototypicality provides an easy and superior unsupervised instance selection to reduce sample complexity, increase model generalization with atypical instances and robustness with typical ones.
Bootstrapping Objectness from Videos by Relaxed Common Fate and Visual Grouping
Apr 17, 2023



We study learning object segmentation from unlabeled videos. Humans can easily segment moving objects without knowing what they are. The Gestalt law of common fate, i.e., what move at the same speed belong together, has inspired unsupervised object discovery based on motion segmentation. However, common fate is not a reliable indicator of objectness: Parts of an articulated / deformable object may not move at the same speed, whereas shadows / reflections of an object always move with it but are not part of it. Our insight is to bootstrap objectness by first learning image features from relaxed common fate and then refining them based on visual appearance grouping within the image itself and across images statistically. Specifically, we learn an image segmenter first in the loop of approximating optical flow with constant segment flow plus small within-segment residual flow, and then by refining it for more coherent appearance and statistical figure-ground relevance. On unsupervised video object segmentation, using only ResNet and convolutional heads, our model surpasses the state-of-the-art by absolute gains of 7/9/5% on DAVIS16 / STv2 / FBMS59 respectively, demonstrating the effectiveness of our ideas. Our code is publicly available.
The Audio-Visual BatVision Dataset for Research on Sight and Sound
Mar 14, 2023



Vision research showed remarkable success in understanding our world, propelled by datasets of images and videos. Sensor data from radar, LiDAR and cameras supports research in robotics and autonomous driving for at least a decade. However, while visual sensors may fail in some conditions, sound has recently shown potential to complement sensor data. Simulated room impulse responses (RIR) in 3D apartment-models became a benchmark dataset for the community, fostering a range of audiovisual research. In simulation, depth is predictable from sound, by learning bat-like perception with a neural network. Concurrently, the same was achieved in reality by using RGB-D images and echoes of chirping sounds. Biomimicking bat perception is an exciting new direction but needs dedicated datasets to explore the potential. Therefore, we collected the BatVision dataset to provide large-scale echoes in complex real-world scenes to the community. We equipped a robot with a speaker to emit chirps and a binaural microphone to record their echoes. Synchronized RGB-D images from the same perspective provide visual labels of traversed spaces. We sampled modern US office spaces to historic French university grounds, indoor and outdoor with large architectural variety. This dataset will allow research on robot echolocation, general audio-visual tasks and sound phaenomena unavailable in simulated data. We show promising results for audio-only depth prediction and show how state-of-the-art work developed for simulated data can also succeed on our dataset. The data can be downloaded at https://forms.gle/W6xtshMgoXGZDwsE7
Cut and Learn for Unsupervised Object Detection and Instance Segmentation
Jan 26, 2023We propose Cut-and-LEaRn (CutLER), a simple approach for training unsupervised object detection and segmentation models. We leverage the property of self-supervised models to 'discover' objects without supervision and amplify it to train a state-of-the-art localization model without any human labels. CutLER first uses our proposed MaskCut approach to generate coarse masks for multiple objects in an image and then learns a detector on these masks using our robust loss function. We further improve the performance by self-training the model on its predictions. Compared to prior work, CutLER is simpler, compatible with different detection architectures, and detects multiple objects. CutLER is also a zero-shot unsupervised detector and improves detection performance AP50 by over 2.7 times on 11 benchmarks across domains like video frames, paintings, sketches, etc. With finetuning, CutLER serves as a low-shot detector surpassing MoCo-v2 by 7.3% APbox and 6.6% APmask on COCO when training with 5% labels.