 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximating Gradients for Differentiable Quality Diversity in Reinforcement Learning
Feb 08, 2022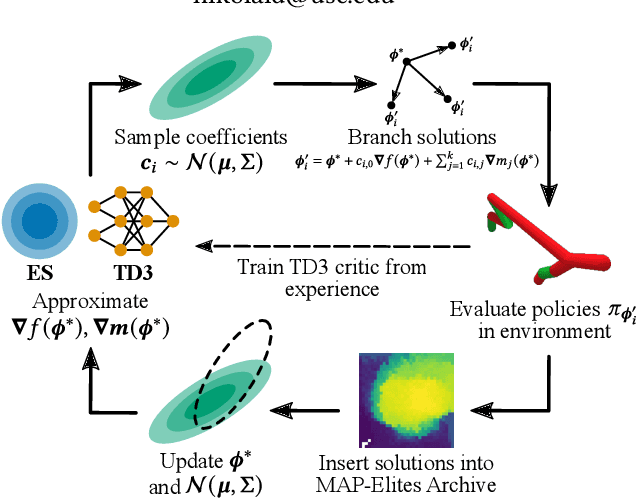

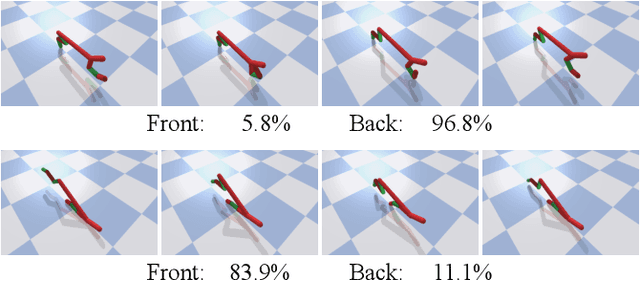
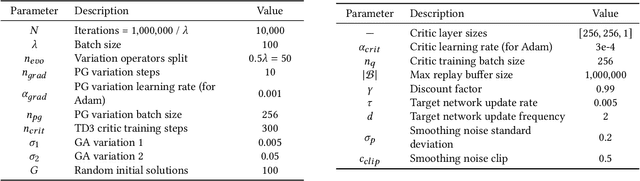
Consider a walking agent that must adapt to damage. To approach this task, we can train a collection of policies and have the agent select a suitable policy when damaged. Training this collection may be viewed as a quality diversity (QD) optimization problem, where we search for solutions (policies) which maximize an objective (walking forward) while spanning a set of measures (measurable characteristics). Recent work shows that differentiable quality diversity (DQD) algorithms greatly accelerate QD optimization when exact gradients are available for the objective and measures. However, such gradients are typically unavailable in RL settings due to non-differentiable environments. To apply DQD in RL settings, we propose to approximate objective and measure gradients with evolution strategies and actor-critic methods. We develop two variants of the DQD algorithm CMA-MEGA, each with different gradient approximations, and evaluate them on four simulated walking tasks. One variant achieves comparable performance (QD score) with the state-of-the-art PGA-MAP-Elites in two tasks. The other variant performs comparably in all tasks but is less efficient than PGA-MAP-Elites in two tasks. These results provide insight into the limitations of CMA-MEGA in domains that require rigorous optimization of the objective and where exact gradients are unavailable.
Using Design Metaphors to Understand User Expectations of Socially Interactive Robot Embodiments
Jan 25, 2022The physical design of a robot suggests expectations of that robot's functionality for human users and collaborators. When those expectations align with the true capabilities of the robot, interaction with the robot is enhanced. However, misalignment of those expectations can result in an unsatisfying interaction. This paper uses Mechanical Turk to evaluate user expectation through the use of design metaphors as applied to a wide range of robot embodiments. The first study (N=382) associates crowd-sourced design metaphors to different robot embodiments. The second study (N=803) assesses initial social expectations of robot embodiments. The final study (N=805) addresses the degree of abstraction of the design metaphors and the functional expectations projected on robot embodiments. Together, these results can guide robot designers toward aligning user expectations with true robot capabilities, facilitating positive human-robot interaction.
Deep Surrogate Assisted MAP-Elites for Automated Hearthstone Deckbuilding
Dec 07, 2021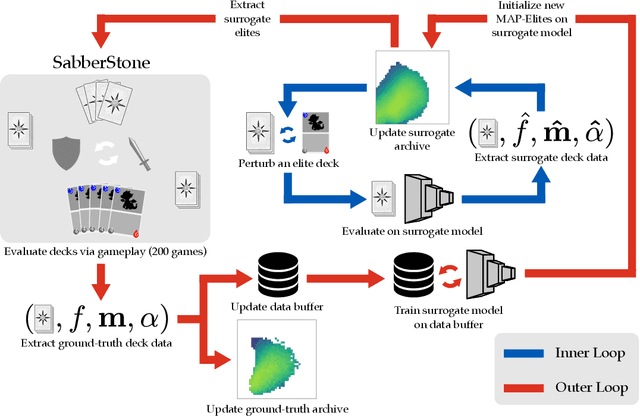
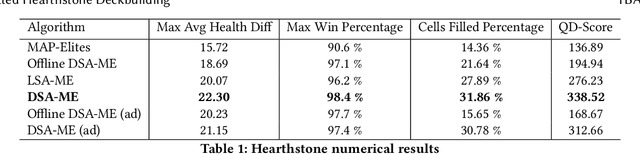
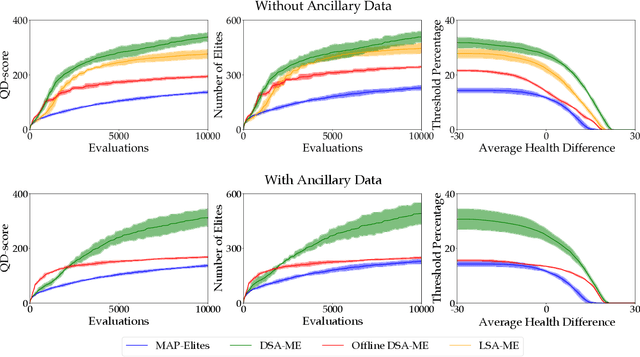
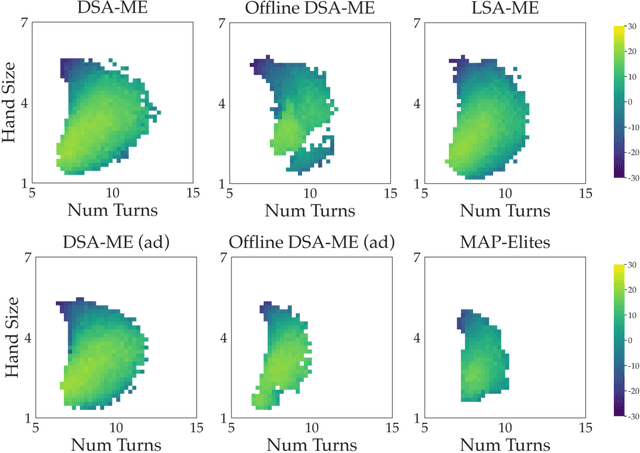
We study the problem of efficiently generating high-quality and diverse content in games. Previous work on automated deckbuilding in Hearthstone shows that the quality diversity algorithm MAP-Elites can generate a collection of high-performing decks with diverse strategic gameplay. However, MAP-Elites requires a large number of expensive evaluations to discover the diverse collection of decks. We propose assisting MAP-Elites with a deep surrogate model trained online to predict game outcomes with respect to candidate decks. MAP-Elites discovers a diverse dataset to improve the surrogate model accuracy, while the surrogate model helps guide MAP-Elites towards promising new content. In a Hearthstone deckbuilding case study, we show that our approach improves the sample efficiency of MAP-Elites and outperforms a model trained offline with random decks, as well as a linear surrogate model baseline, setting a new state-of-the-art for quality diversity approaches in the application domain of automated Hearthstone deckbuilding.
Towards Transferring Human Preferences from Canonical to Actual Assembly Tasks
Nov 11, 2021
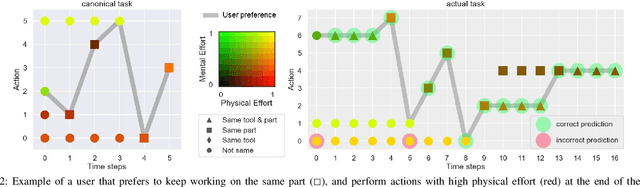
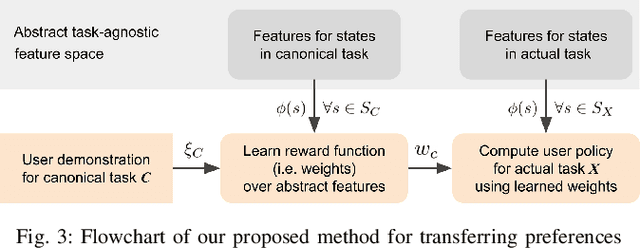
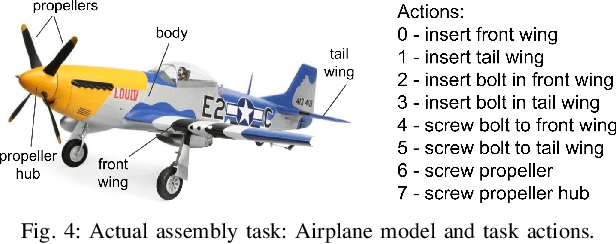
To assist human users according to their individual preference in assembly tasks, robots typically require user demonstrations in the given task. However, providing demonstrations in actual assembly tasks can be tedious and time-consuming. Our thesis is that we can learn user preferences in assembly tasks from demonstrations in a representative canonical task. Inspired by previous work in economy of human movement, we propose to represent user preferences as a linear function of abstract task-agnostic features, such as movement and physical and mental effort required by the user. For each user, we learn their preference from demonstrations in a canonical task and use the learned preference to anticipate their actions in the actual assembly task without any user demonstrations in the actual task. We evaluate our proposed method in a model-airplane assembly study and show that preferences can be effectively transferred from canonical to actual assembly tasks, enabling robots to anticipate user actions.
Illuminating Diverse Neural Cellular Automata for Level Generation
Sep 12, 2021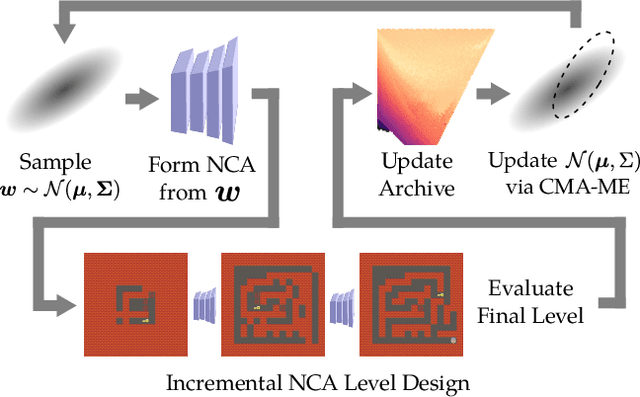
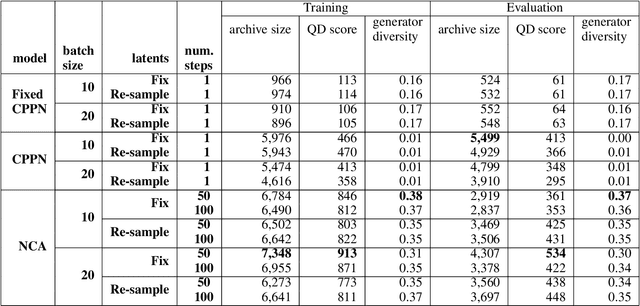
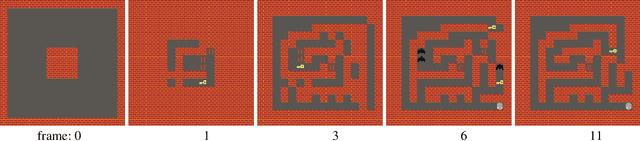
We present a method of generating a collection of neural cellular automata (NCA) to design video game levels. While NCAs have so far only been trained via supervised learning, we present a quality diversity (QD) approach to generating a collection of NCA level generators. By framing the problem as a QD problem, our approach can train diverse level generators, whose output levels vary based on aesthetic or functional criteria. To efficiently generate NCAs, we train generators via Covariance Matrix Adaptation MAP-Elites (CMA-ME), a quality diversity algorithm which specializes in continuous search spaces. We apply our new method to generate level generators for several 2D tile-based games: a maze game, Sokoban, and Zelda. Our results show that CMA-ME can generate small NCAs that are diverse yet capable, often satisfying complex solvability criteria for deterministic agents. We compare against a Compositional Pattern-Producing Network (CPPN) baseline trained to produce diverse collections of generators and show that the NCA representation yields a better exploration of level-space.
Robotic Lime Picking by Considering Leaves as Permeable Obstacles
Aug 31, 2021
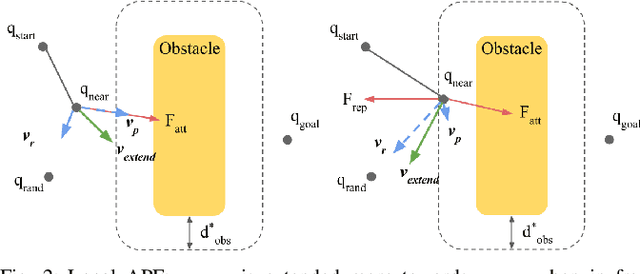
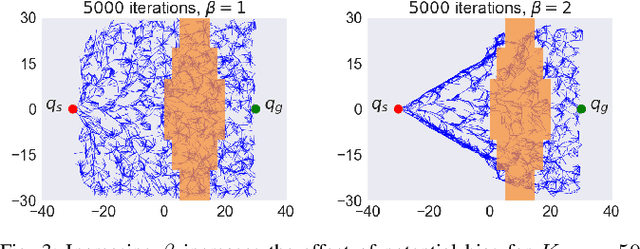
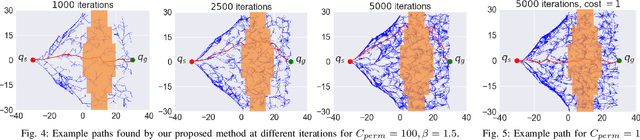
The problem of robotic lime picking is challenging; lime plants have dense foliage which makes it difficult for a robotic arm to grasp a lime without coming in contact with leaves. Existing approaches either do not consider leaves, or treat them as obstacles and completely avoid them, often resulting in undesirable or infeasible plans. We focus on reaching a lime in the presence of dense foliage by considering the leaves of a plant as 'permeable obstacles' with a collision cost. We then adapt the rapidly exploring random tree star (RRT*) algorithm for the problem of fruit harvesting by incorporating the cost of collision with leaves into the path cost. To reduce the time required for finding low-cost paths to goal, we bias the growth of the tree using an artificial potential field (APF). We compare our proposed method with prior work in a 2-D environment and a 6-DOF robot simulation. Our experiments and a real-world demonstration on a robotic lime picking task demonstrate the applicability of our approach.
Design and Evaluation of a Hair Combing System Using a General-Purpose Robotic Arm
Aug 03, 2021
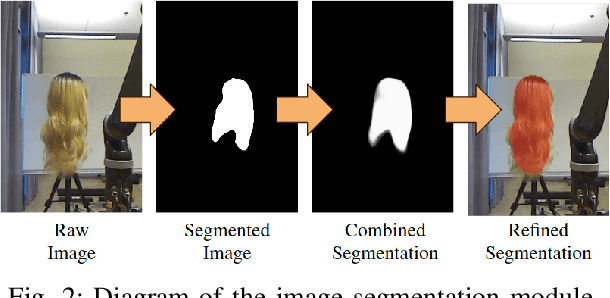
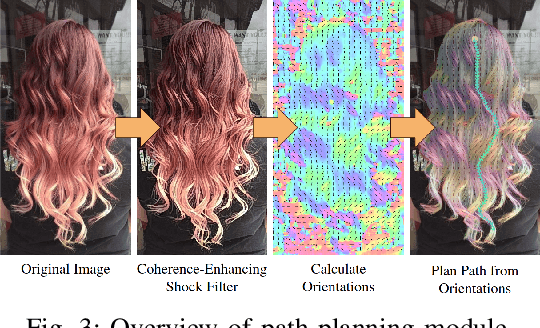
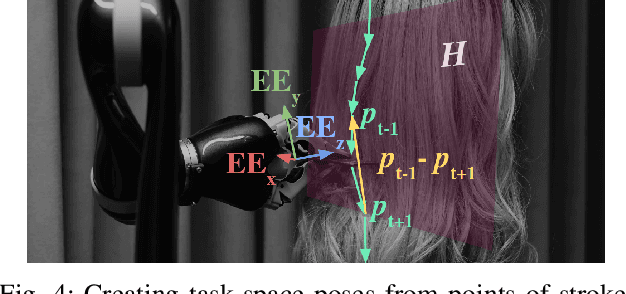
This work introduces an approach for automatic hair combing by a lightweight robot. For people living with limited mobility, dexterity, or chronic fatigue, combing hair is often a difficult task that negatively impacts personal routines. We propose a modular system for enabling general robot manipulators to assist with a hair-combing task. The system consists of three main components. The first component is the segmentation module, which segments the location of hair in space. The second component is the path planning module that proposes automatically-generated paths through hair based on user input. The final component creates a trajectory for the robot to execute. We quantitatively evaluate the effectiveness of the paths planned by the system with 48 users and qualitatively evaluate the system with 30 users watching videos of the robot performing a hair-combing task in the physical world. The system is shown to effectively comb different hairstyles.
Personalizing User Engagement Dynamics in a Non-Verbal Communication Game for Cerebral Palsy
Jul 15, 2021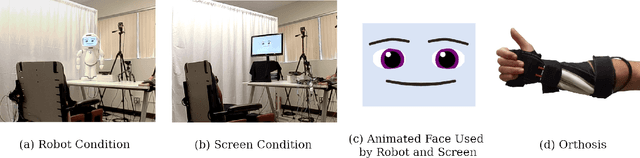

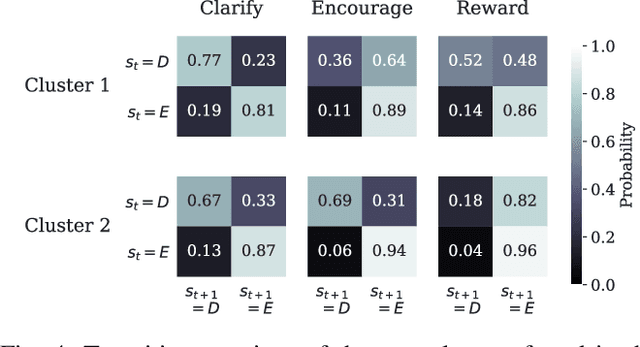
Children and adults with cerebral palsy (CP) can have involuntary upper limb movements as a consequence of the symptoms that characterize their motor disability, leading to difficulties in communicating with caretakers and peers. We describe how a socially assistive robot may help individuals with CP to practice non-verbal communicative gestures using an active orthosis in a one-on-one number-guessing game. We performed a user study and data collection with participants with CP; we found that participants preferred an embodied robot over a screen-based agent, and we used the participant data to train personalized models of participant engagement dynamics that can be used to select personalized robot actions. Our work highlights the benefit of personalized models in the engagement of users with CP with a socially assistive robot and offers design insights for future work in this area.
On the Importance of Environments in Human-Robot Coordination
Jun 28, 2021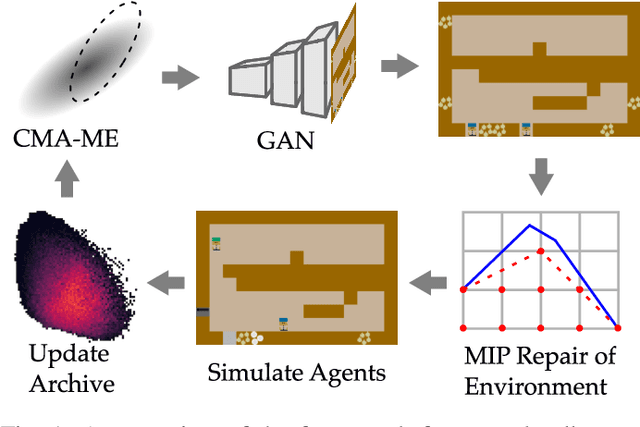
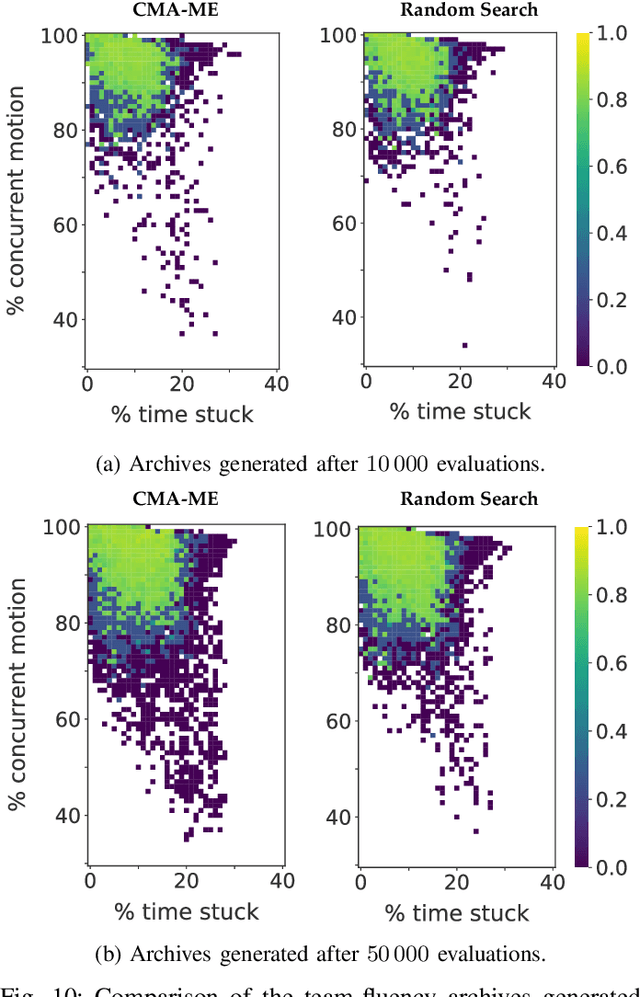
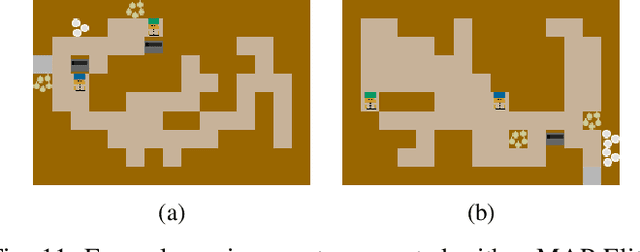
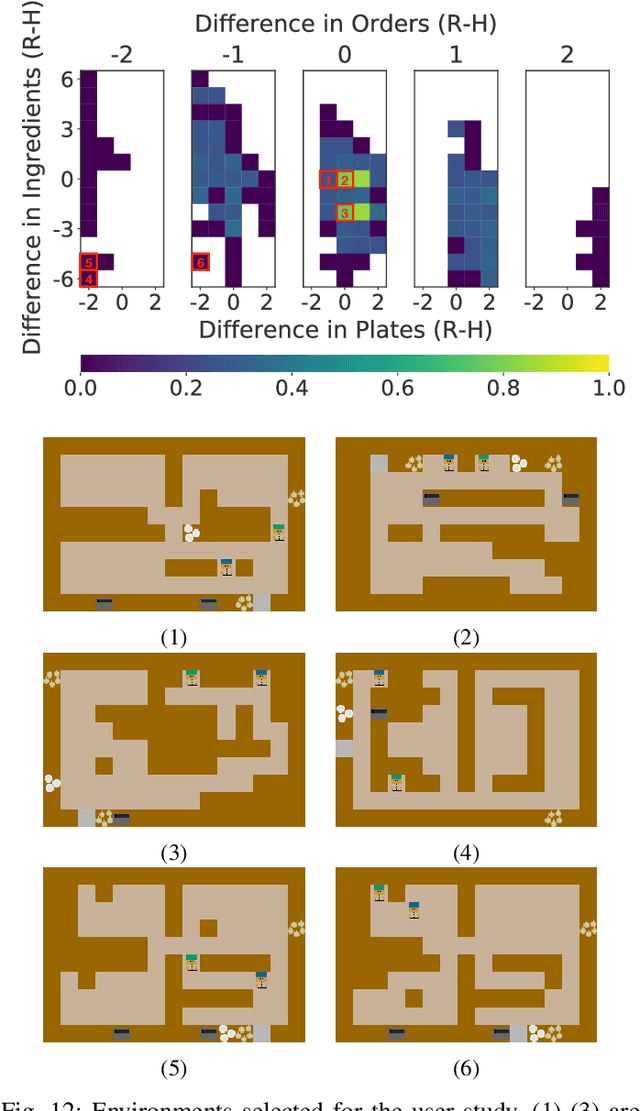
When studying robots collaborating with humans, much of the focus has been on robot policies that coordinate fluently with human teammates in collaborative tasks. However, less emphasis has been placed on the effect of the environment on coordination behaviors. To thoroughly explore environments that result in diverse behaviors, we propose a framework for procedural generation of environments that are (1) stylistically similar to human-authored environments, (2) guaranteed to be solvable by the human-robot team, and (3) diverse with respect to coordination measures. We analyze the procedurally generated environments in the Overcooked benchmark domain via simulation and an online user study. Results show that the environments result in qualitatively different emerging behaviors and statistically significant differences in collaborative fluency metrics, even when the robot runs the same planning algorithm.
Differentiable Quality Diversity
Jun 07, 2021
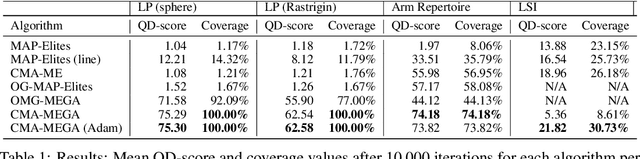
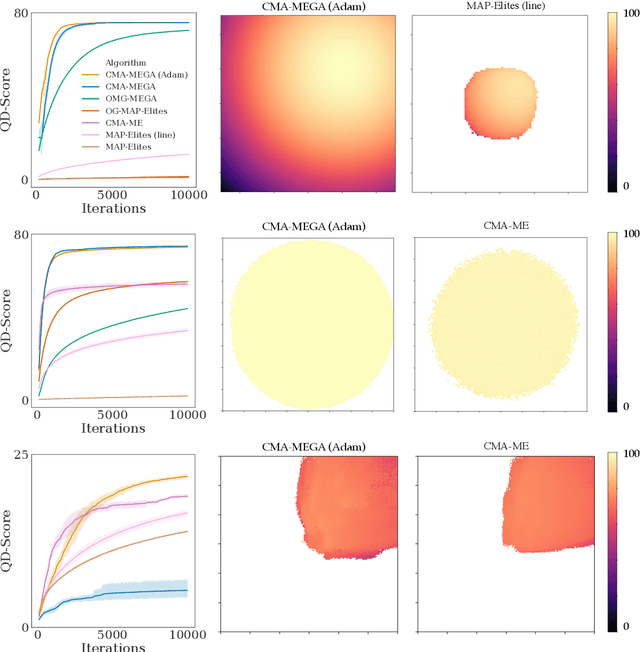
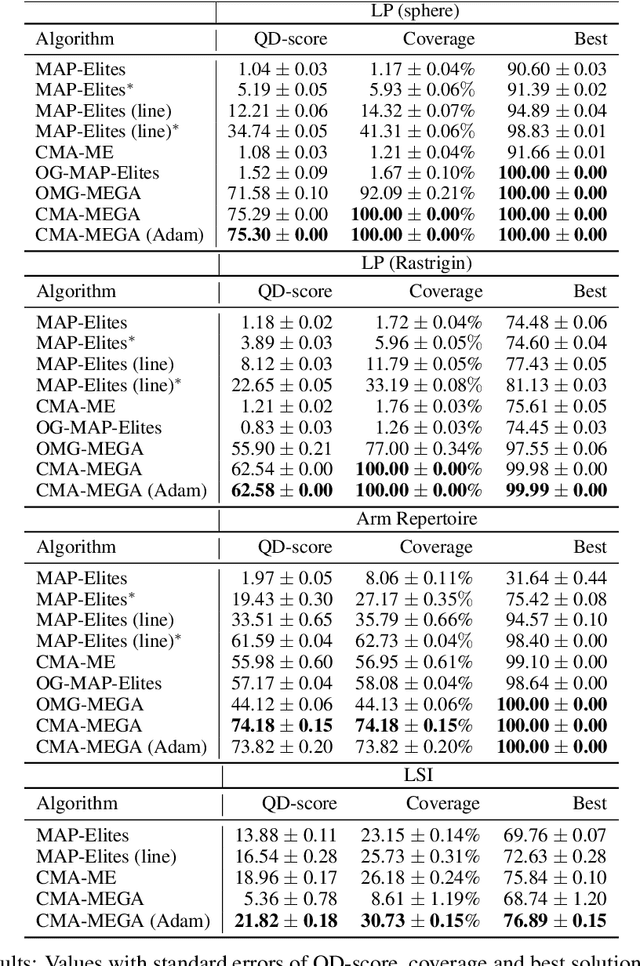
Quality diversity (QD) is a growing branch of stochastic optimization research that studies the problem of generating an archive of solutions that maximize a given objective function but are also diverse with respect to a set of specified measure functions. However, even when these functions are differentiable, QD algorithms treat them as "black boxes", ignoring gradient information. We present the differentiable quality diversity (DQD) problem, a special case of QD, where both the objective and measure functions are first order differentiable. We then present MAP-Elites via Gradient Arborescence (MEGA), a DQD algorithm that leverages gradient information to efficiently explore the joint range of the objective and measure functions. Results in two QD benchmark domains and in searching the latent space of a StyleGAN show that MEGA significantly outperforms state-of-the-art QD algorithms, highlighting DQD's promise for efficient quality diversity optimization when gradient information is available. Source code is available at https://github.com/icaros-usc/dqd.