 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusing Bidirectional Chains of Thought and Reward Mechanisms A Method for Enhancing Question-Answering Capabilities of Large Language Models for Chinese Intangible Cultural Heritage
May 14, 2025



The rapid development of large language models (LLMs) has provided significant support and opportunities for the advancement of domain-specific LLMs. However, fine-tuning these large models using Intangible Cultural Heritage (ICH) data inevitably faces challenges such as bias, incorrect knowledge inheritance, and catastrophic forgetting. To address these issues, we propose a novel training method that integrates a bidirectional chains of thought and a reward mechanism. This method is built upon ICH-Qwen, a large language model specifically designed for the field of intangible cultural heritage. The proposed method enables the model to not only perform forward reasoning but also enhances the accuracy of the generated answers by utilizing reverse questioning and reverse reasoning to activate the model's latent knowledge. Additionally, a reward mechanism is introduced during training to optimize the decision-making process. This mechanism improves the quality of the model's outputs through structural and content evaluations with different weighting schemes. We conduct comparative experiments on ICH-Qwen, with results demonstrating that our method outperforms 0-shot, step-by-step reasoning, knowledge distillation, and question augmentation methods in terms of accuracy, Bleu-4, and Rouge-L scores on the question-answering task. Furthermore, the paper highlights the effectiveness of combining the bidirectional chains of thought and reward mechanism through ablation experiments. In addition, a series of generalizability experiments are conducted, with results showing that the proposed method yields improvements on various domain-specific datasets and advanced models in areas such as Finance, Wikidata, and StrategyQA. This demonstrates that the method is adaptable to multiple domains and provides a valuable approach for model training in future applications across diverse fields.
Illuminating Mario Scenes in the Latent Space of a Generative Adversarial Network
Jul 11, 2020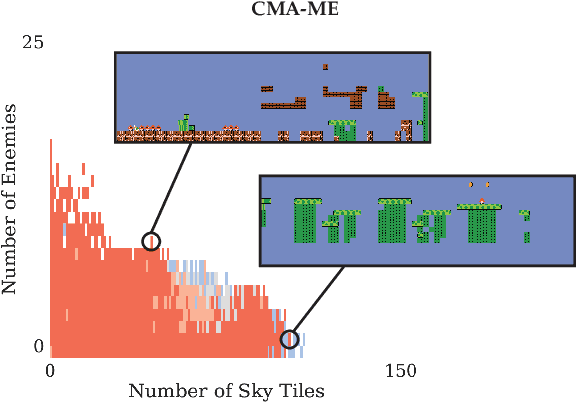


Recent developments in machine learning techniques have allowed automatic generation of video game levels that are stylistically similar to human-designed examples. While the output of machine learning models such as generative adversarial networks (GANs) is notoriously hard to control, the recently proposed latent variable evolution (LVE) technique searches the space of GAN parameters to generate outputs that optimize some objective performance metric, such as level playability. However, the question remains on how to automatically generate a diverse range of high-quality solutions based on a prespecified set of desired characteristics. We introduce a new method called latent space illumination (LSI), which uses state-of-the-art quality diversity algorithms designed to optimize in continuous spaces, i.e., MAP-Elites with a directional variation operator and Covariance Matrix Adaptation MAP-Elites, to effectively search the parameter space of theGAN along a set of multiple level mechanics. We show the performance of LSI algorithms in three experiments in SuperMario Bros., a benchmark domain for procedural content generation. Results suggest that LSI generates sets of Mario levels that are reliably mechanically diverse as well as playable.