 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Stability and Realizability of Recurrent Polynomial Surrogate Ternary Logic Gate Networks
May 23, 2026Recurrent Neural Networks (RNNs) can learn to predict Signal Temporal Logic (STL) verdicts online from partial trajectories, but deploying them as runtime monitors in safety-critical systems demands more than predictive accuracy. Standard RNN architectures offer no structural guarantee that outputs degrade gracefully under sensor degradation; a dropped input can silently flip a verdict from safe to unsafe. We introduce the Recurrent Differentiable Ternary Logic Gate Network (R-DTLGN), a recurrent architecture that operates over Kleene's three-valued logic $\{-1, 0, +1\}$, where $0$ explicitly represents unknown. The R-DTLGN trains through continuous polynomial surrogates and hardens to a discrete ternary logic circuit at inference. We analyze the hardened circuit through two gate vocabularies derived from two orderings on the ternary domain: numerically monotone gates ensure stable recurrent dynamics, while information-monotone gates, when present, guarantee principled abstention (unknown inputs never produce wrong outputs) and monotonicity in input certainty (more information can only improve the verdict). We show that the recurrent connections required by bounded STL operators use exclusively AND and OR, which belong to both vocabularies, linking the monitoring task to the architecture's guarantees. A realizability bound derived from the STL formula's temporal operators directly sizes the network's hidden state, replacing hyperparameter search with a formula-driven specification. We evaluate on STL specifications over D4RL PointMaze navigation data, testing prediction accuracy, degradation under predicate dropout, and the accuracy-versus-safety tradeoff between two label construction pipelines. The R-DTLGN is, to our knowledge, the first recurrent architecture that couples learned temporal prediction with formal degradation guarantees rooted in three-valued logic.
Polynomial Surrogate Training for Differentiable Ternary Logic Gate Networks
Feb 27, 2026Differentiable logic gate networks (DLGNs) learn compact, interpretable Boolean circuits via gradient-based training, but all existing variants are restricted to the 16 two-input binary gates. Extending DLGNs to Ternary Kleene $K_3$ logic and training DTLGNs where the UNKNOWN state enables principled abstention under uncertainty is desirable. However, the support set of potential gates per neuron explodes to $19{,}683$, making the established softmax-over-gates training approach intractable. We introduce Polynomial Surrogate Training (PST), which represents each ternary neuron as a degree-$(2,2)$ polynomial with 9 learnable coefficients (a $2{,}187\times$ parameter reduction) and prove that the gap between the trained network and its discretized logic circuit is bounded by a data-independent commitment loss that vanishes at convergence. Scaling experiments from 48K to 512K neurons on CIFAR-10 demonstrate that this hardening gap contracts with overparameterization. Ternary networks train $2$-$3\times$ faster than binary DLGNs and discover true ternary gates that are functionally diverse. On synthetic and tabular tasks we find that the UNKNOWN output acts as a Bayes-optimal uncertainty proxy, enabling selective prediction in which ternary circuits surpass binary accuracy once low-confidence predictions are filtered. More broadly, PST establishes a general polynomial-surrogate methodology whose parameterization cost grows only quadratically with logic valence, opening the door to many-valued differentiable logic.
Signal Temporal Logic-Guided Apprenticeship Learning
Nov 09, 2023



Apprenticeship learning crucially depends on effectively learning rewards, and hence control policies from user demonstrations. Of particular difficulty is the setting where the desired task consists of a number of sub-goals with temporal dependencies. The quality of inferred rewards and hence policies are typically limited by the quality of demonstrations, and poor inference of these can lead to undesirable outcomes. In this letter, we show how temporal logic specifications that describe high level task objectives, are encoded in a graph to define a temporal-based metric that reasons about behaviors of demonstrators and the learner agent to improve the quality of inferred rewards and policies. Through experiments on a diverse set of robot manipulator simulations, we show how our framework overcomes the drawbacks of prior literature by drastically improving the number of demonstrations required to learn a control policy.
Learning Performance Graphs from Demonstrations via Task-Based Evaluations
Apr 12, 2022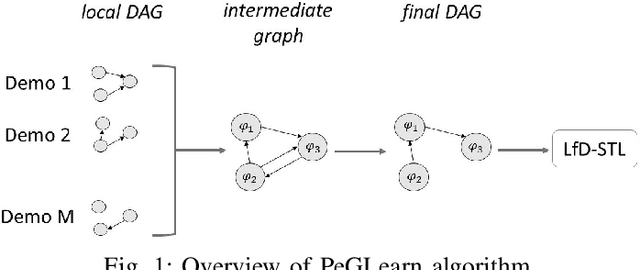
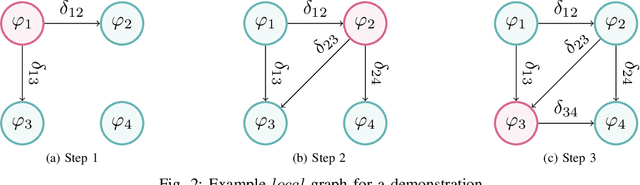
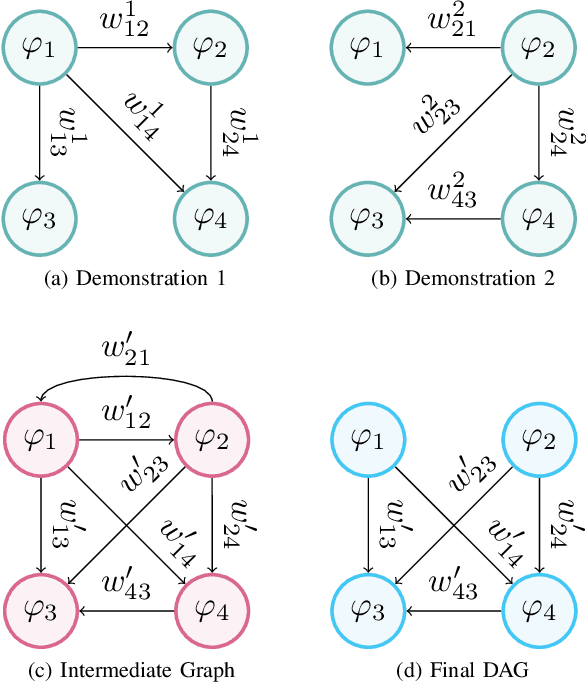
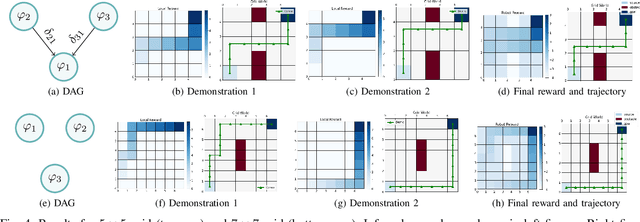
In the learning from demonstration (LfD) paradigm, understanding and evaluating the demonstrated behaviors plays a critical role in extracting control policies for robots. Without this knowledge, a robot may infer incorrect reward functions that lead to undesirable or unsafe control policies. Recent work has proposed an LfD framework where a user provides a set of formal task specifications to guide LfD, to address the challenge of reward shaping. However, in this framework, specifications are manually ordered in a performance graph (a partial order that specifies relative importance between the specifications). The main contribution of this paper is an algorithm to learn the performance graph directly from the user-provided demonstrations, and show that the reward functions generated using the learned performance graph generate similar policies to those from manually specified performance graphs. We perform a user study that shows that priorities specified by users on behaviors in a simulated highway driving domain match the automatically inferred performance graph. This establishes that we can accurately evaluate user demonstrations with respect to task specifications without expert criteria.
Learning from Demonstrations using Signal Temporal Logic
Feb 15, 2021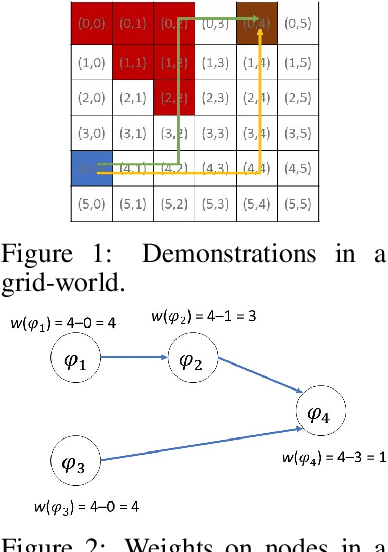
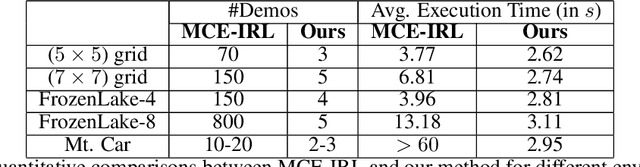
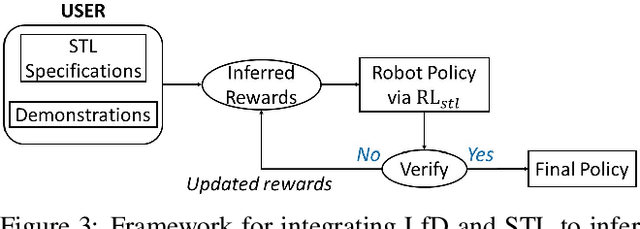

Learning-from-demonstrations is an emerging paradigm to obtain effective robot control policies for complex tasks via reinforcement learning without the need to explicitly design reward functions. However, it is susceptible to imperfections in demonstrations and also raises concerns of safety and interpretability in the learned control policies. To address these issues, we use Signal Temporal Logic to evaluate and rank the quality of demonstrations. Temporal logic-based specifications allow us to create non-Markovian rewards, and also define interesting causal dependencies between tasks such as sequential task specifications. We validate our approach through experiments on discrete-world and OpenAI Gym environments, and show that our approach outperforms the state-of-the-art Maximum Causal Entropy Inverse Reinforcement Learning.
Mining Environment Assumptions for Cyber-Physical System Models
May 18, 2020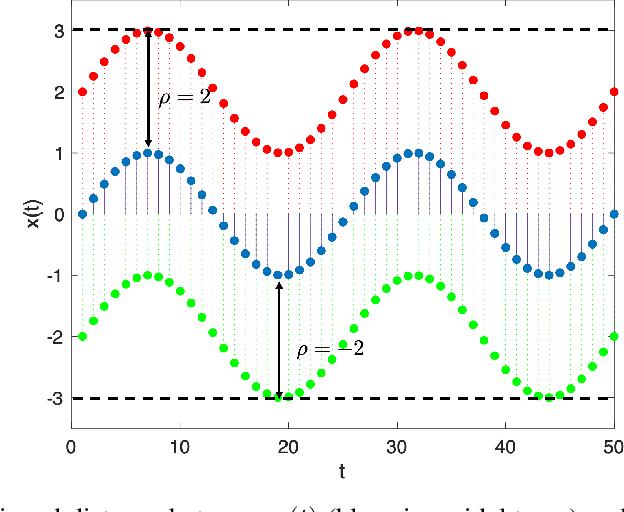
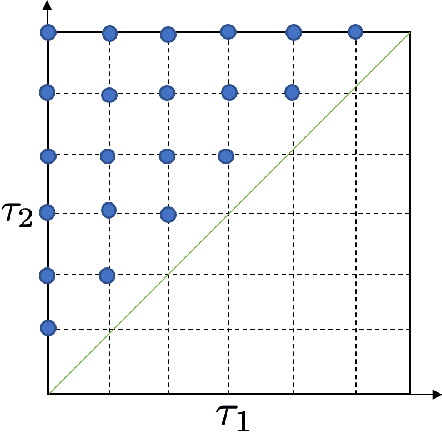
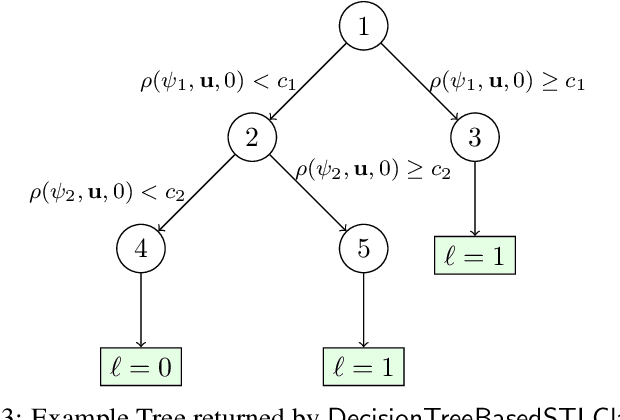
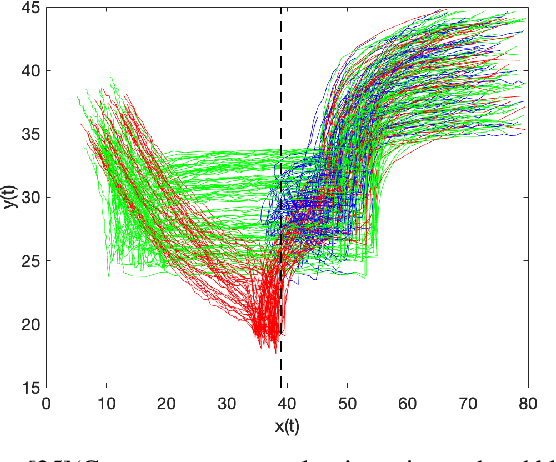
Many complex cyber-physical systems can be modeled as heterogeneous components interacting with each other in real-time. We assume that the correctness of each component can be specified as a requirement satisfied by the output signals produced by the component, and that such an output guarantee is expressed in a real-time temporal logic such as Signal Temporal Logic (STL). In this paper, we hypothesize that a large subset of input signals for which the corresponding output signals satisfy the output requirement can also be compactly described using an STL formula that we call the environment assumption. We propose an algorithm to mine such an environment assumption using a supervised learning technique. Essentially, our algorithm treats the environment assumption as a classifier that labels input signals as good if the corresponding output signal satisfies the output requirement, and as bad otherwise. Our learning method simultaneously learns the structure of the STL formula as well as the values of the numeric constants appearing in the formula. To achieve this, we combine a procedure to systematically enumerate candidate Parametric STL (PSTL) formulas, with a decision-tree based approach to learn parameter values. We demonstrate experimental results on real world data from several domains including transportation and health care.
Interpretable Classification of Time-Series Data using Efficient Enumerative Techniques
Jul 24, 2019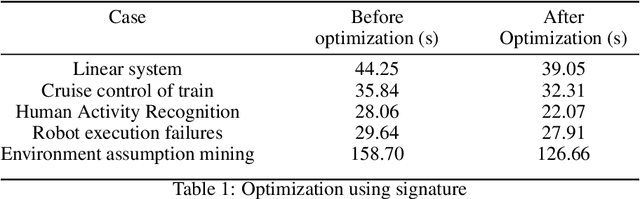
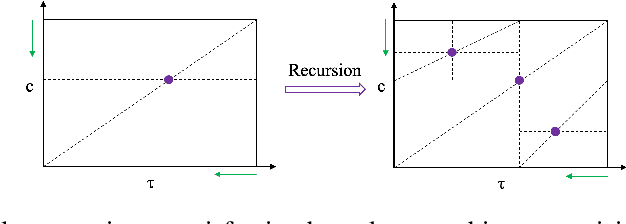
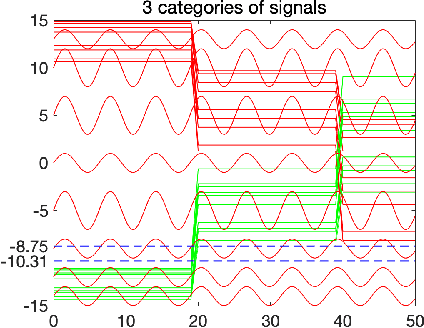
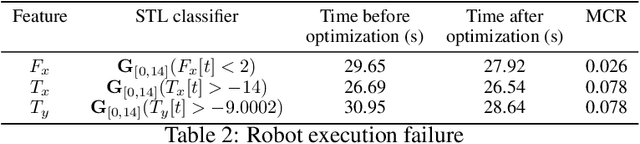
Cyber-physical system applications such as autonomous vehicles, wearable devices, and avionic systems generate a large volume of time-series data. Designers often look for tools to help classify and categorize the data. Traditional machine learning techniques for time-series data offer several solutions to solve these problems; however, the artifacts trained by these algorithms often lack interpretability. On the other hand, temporal logics, such as Signal Temporal Logic (STL) have been successfully used in the formal methods community as specifications of time-series behaviors. In this work, we propose a new technique to automatically learn temporal logic formulae that are able to cluster and classify real-valued time-series data. Previous work on learning STL formulas from data either assumes a formula-template to be given by the user, or assumes some special fragment of STL that enables exploring the formula structure in a systematic fashion. In our technique, we relax these assumptions, and provide a way to systematically explore the space of all STL formulas. As the space of all STL formulas is very large, and contains many semantically equivalent formulas, we suggest a technique to heuristically prune the space of formulas considered. Finally, we illustrate our technique on various case studies from the automotive, transportation and healthcare domain.