 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked LoGoNet: Fast and Accurate 3D Image Analysis for Medical Domain
Feb 09, 2024



Standard modern machine-learning-based imaging methods have faced challenges in medical applications due to the high cost of dataset construction and, thereby, the limited labeled training data available. Additionally, upon deployment, these methods are usually used to process a large volume of data on a daily basis, imposing a high maintenance cost on medical facilities. In this paper, we introduce a new neural network architecture, termed LoGoNet, with a tailored self-supervised learning (SSL) method to mitigate such challenges. LoGoNet integrates a novel feature extractor within a U-shaped architecture, leveraging Large Kernel Attention (LKA) and a dual encoding strategy to capture both long-range and short-range feature dependencies adeptly. This is in contrast to existing methods that rely on increasing network capacity to enhance feature extraction. This combination of novel techniques in our model is especially beneficial in medical image segmentation, given the difficulty of learning intricate and often irregular body organ shapes, such as the spleen. Complementary, we propose a novel SSL method tailored for 3D images to compensate for the lack of large labeled datasets. The method combines masking and contrastive learning techniques within a multi-task learning framework and is compatible with both Vision Transformer (ViT) and CNN-based models. We demonstrate the efficacy of our methods in numerous tasks across two standard datasets (i.e., BTCV and MSD). Benchmark comparisons with eight state-of-the-art models highlight LoGoNet's superior performance in both inference time and accuracy.
Modeling Sequences as Star Graphs to Address Over-smoothing in Self-attentive Sequential Recommendation
Nov 13, 2023



Self-attention (SA) mechanisms have been widely used in developing sequential recommendation (SR) methods, and demonstrated state-of-the-art performance. However, in this paper, we show that self-attentive SR methods substantially suffer from the over-smoothing issue that item embeddings within a sequence become increasingly similar across attention blocks. As widely demonstrated in the literature, this issue could lead to a loss of information in individual items, and significantly degrade models' scalability and performance. To address the over-smoothing issue, in this paper, we view items within a sequence constituting a star graph and develop a method, denoted as MSSG, for SR. Different from existing self-attentive methods, MSSG introduces an additional internal node to specifically capture the global information within the sequence, and does not require information propagation among items. This design fundamentally addresses the over-smoothing issue and enables MSSG a linear time complexity with respect to the sequence length. We compare MSSG with ten state-of-the-art baseline methods on six public benchmark datasets. Our experimental results demonstrate that MSSG significantly outperforms the baseline methods, with an improvement of as much as 10.10%. Our analysis shows the superior scalability of MSSG over the state-of-the-art self-attentive methods. Our complexity analysis and run-time performance comparison together show that MSSG is both theoretically and practically more efficient than self-attentive methods. Our analysis of the attention weights learned in SA-based methods indicates that on sparse recommendation data, modeling dependencies in all item pairs using the SA mechanism yields limited information gain, and thus, might not benefit the recommendation performance
Towards Efficient and Effective Adaptation of Large Language Models for Sequential Recommendation
Oct 02, 2023



In recent years, with large language models (LLMs) achieving state-of-the-art performance in context understanding, increasing efforts have been dedicated to developing LLM-enhanced sequential recommendation (SR) methods. Considering that most existing LLMs are not specifically optimized for recommendation tasks, adapting them for SR becomes a critical step in LLM-enhanced SR methods. Though numerous adaptation methods have been developed, it still remains a significant challenge to adapt LLMs for SR both efficiently and effectively. To address this challenge, in this paper, we introduce a novel side sequential network adaptation method, denoted as SSNA, for LLM enhanced SR. SSNA features three key designs to allow both efficient and effective LLM adaptation. First, SSNA learns adapters separate from LLMs, while fixing all the pre-trained parameters within LLMs to allow efficient adaptation. In addition, SSNA adapts the top-a layers of LLMs jointly, and integrates adapters sequentially for enhanced effectiveness (i.e., recommendation performance). We compare SSNA against five state-of-the-art baseline methods on five benchmark datasets using three LLMs. The experimental results demonstrate that SSNA significantly outperforms all the baseline methods in terms of recommendation performance, and achieves substantial improvement over the best-performing baseline methods at both run-time and memory efficiency during training. Our analysis shows the effectiveness of integrating adapters in a sequential manner. Our parameter study demonstrates the effectiveness of jointly adapting the top-a layers of LLMs.
Multi-modality Meets Re-learning: Mitigating Negative Transfer in Sequential Recommendation
Sep 20, 2023



Learning effective recommendation models from sparse user interactions represents a fundamental challenge in developing sequential recommendation methods. Recently, pre-training-based methods have been developed to tackle this challenge. Though promising, in this paper, we show that existing methods suffer from the notorious negative transfer issue, where the model adapted from the pre-trained model results in worse performance compared to the model learned from scratch in the task of interest (i.e., target task). To address this issue, we develop a method, denoted as ANT, for transferable sequential recommendation. ANT mitigates negative transfer by 1) incorporating multi-modality item information, including item texts, images and prices, to effectively learn more transferable knowledge from related tasks (i.e., auxiliary tasks); and 2) better capturing task-specific knowledge in the target task using a re-learning-based adaptation strategy. We evaluate ANT against eight state-of-the-art baseline methods on five target tasks. Our experimental results demonstrate that ANT does not suffer from the negative transfer issue on any of the target tasks. The results also demonstrate that ANT substantially outperforms baseline methods in the target tasks with an improvement of as much as 15.2%. Our analysis highlights the superior effectiveness of our re-learning-based strategy compared to fine-tuning on the target tasks.
Shape-conditioned 3D Molecule Generation via Equivariant Diffusion Models
Sep 12, 2023



Ligand-based drug design aims to identify novel drug candidates of similar shapes with known active molecules. In this paper, we formulated an in silico shape-conditioned molecule generation problem to generate 3D molecule structures conditioned on the shape of a given molecule. To address this problem, we developed a translation- and rotation-equivariant shape-guided generative model ShapeMol. ShapeMol consists of an equivariant shape encoder that maps molecular surface shapes into latent embeddings, and an equivariant diffusion model that generates 3D molecules based on these embeddings. Experimental results show that ShapeMol can generate novel, diverse, drug-like molecules that retain 3D molecular shapes similar to the given shape condition. These results demonstrate the potential of ShapeMol in designing drug candidates of desired 3D shapes binding to protein target pockets.
PolicyClusterGCN: Identifying Efficient Clusters for Training Graph Convolutional Networks
Jun 25, 2023



Graph convolutional networks (GCNs) have achieved huge success in several machine learning (ML) tasks on graph-structured data. Recently, several sampling techniques have been proposed for the efficient training of GCNs and to improve the performance of GCNs on ML tasks. Specifically, the subgraph-based sampling approaches such as ClusterGCN and GraphSAINT have achieved state-of-the-art performance on the node classification tasks. These subgraph-based sampling approaches rely on heuristics -- such as graph partitioning via edge cuts -- to identify clusters that are then treated as minibatches during GCN training. In this work, we hypothesize that rather than relying on such heuristics, one can learn a reinforcement learning (RL) policy to compute efficient clusters that lead to effective GCN performance. To that end, we propose PolicyClusterGCN, an online RL framework that can identify good clusters for GCN training. We develop a novel Markov Decision Process (MDP) formulation that allows the policy network to predict ``importance" weights on the edges which are then utilized by a clustering algorithm (Graclus) to compute the clusters. We train the policy network using a standard policy gradient algorithm where the rewards are computed from the classification accuracies while training GCN using clusters given by the policy. Experiments on six real-world datasets and several synthetic datasets show that PolicyClusterGCN outperforms existing state-of-the-art models on node classification task.
FairMILE: A Multi-Level Framework for Fair and Scalable Graph Representation Learning
Nov 17, 2022Graph representation learning models have been deployed for making decisions in multiple high-stakes scenarios. It is therefore critical to ensure that these models are fair. Prior research has shown that graph neural networks can inherit and reinforce the bias present in graph data. Researchers have begun to examine ways to mitigate the bias in such models. However, existing efforts are restricted by their inefficiency, limited applicability, and the constraints they place on sensitive attributes. To address these issues, we present FairMILE a general framework for fair and scalable graph representation learning. FairMILE is a multi-level framework that allows contemporary unsupervised graph embedding methods to scale to large graphs in an agnostic manner. FairMILE learns both fair and high-quality node embeddings where the fairness constraints are incorporated in each phase of the framework. Our experiments across two distinct tasks demonstrate that FairMILE can learn node representations that often achieve superior fairness scores and high downstream performance while significantly outperforming all the baselines in terms of efficiency.
Recursive Attentive Methods with Reused Item Representations for Sequential Recommendation
Sep 16, 2022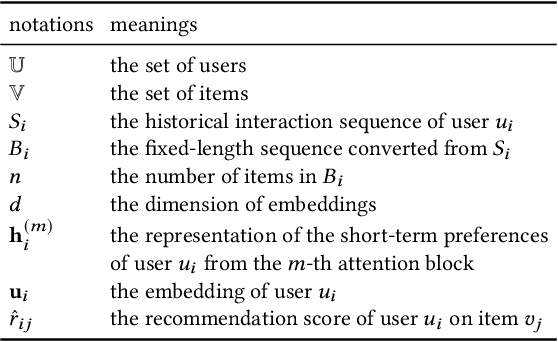
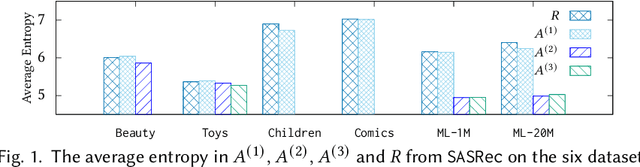
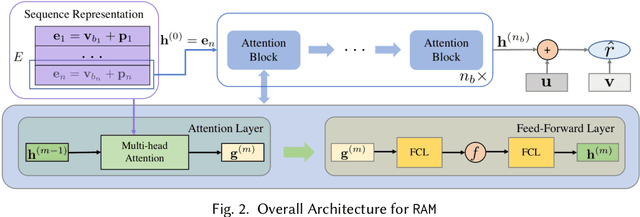
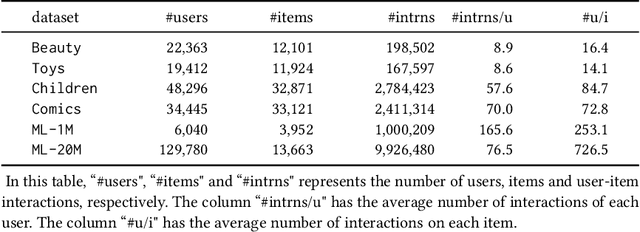
Sequential recommendation aims to recommend the next item of users' interest based on their historical interactions. Recently, the self-attention mechanism has been adapted for sequential recommendation, and demonstrated state-of-the-art performance. However, in this manuscript, we show that the self-attention-based sequential recommendation methods could suffer from the localization-deficit issue. As a consequence, in these methods, over the first few blocks, the item representations may quickly diverge from their original representations, and thus, impairs the learning in the following blocks. To mitigate this issue, in this manuscript, we develop a recursive attentive method with reused item representations (RAM) for sequential recommendation. We compare RAM with five state-of-the-art baseline methods on six public benchmark datasets. Our experimental results demonstrate that RAM significantly outperforms the baseline methods on benchmark datasets, with an improvement of as much as 11.3%. Our stability analysis shows that RAM could enable deeper and wider models for better performance. Our run-time performance comparison signifies that RAM could also be more efficient on benchmark datasets.
Prospective Preference Enhanced Mixed Attentive Model for Session-based Recommendation
Jun 04, 2022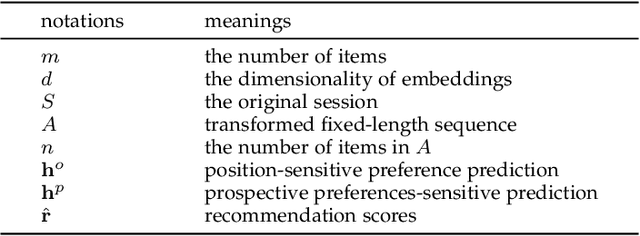
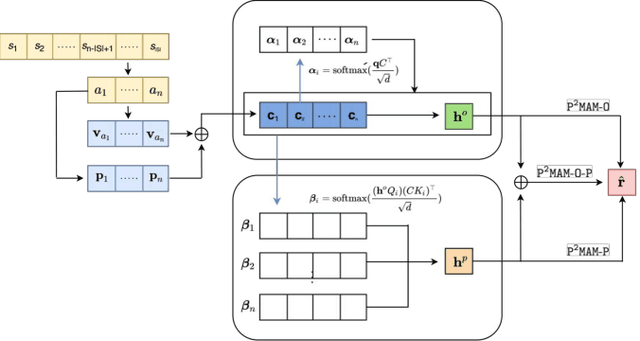
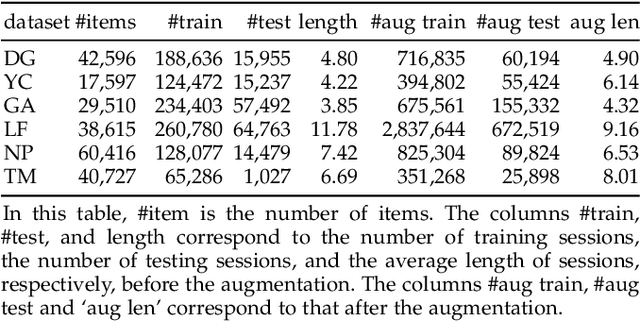
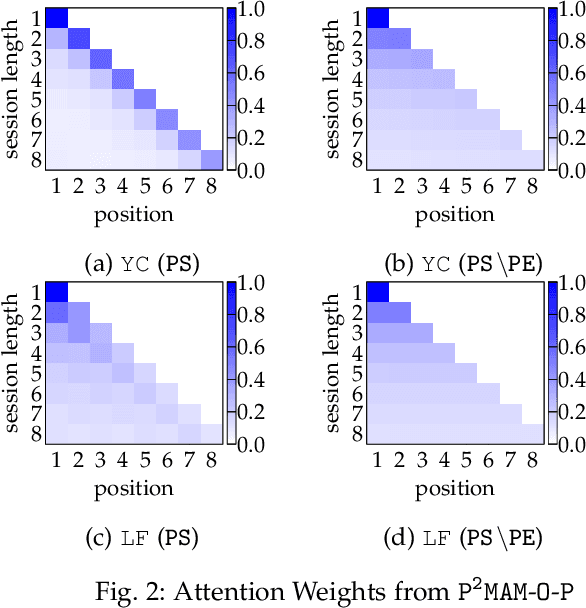
Session-based recommendation aims to generate recommendations for the next item of users' interest based on a given session. In this manuscript, we develop prospective preference enhanced mixed attentive model (P2MAM) to generate session-based recommendations using two important factors: temporal patterns and estimates of users' prospective preferences. Unlike existing methods, P2MAM models the temporal patterns using a light-weight while effective position-sensitive attention mechanism. In P2MAM, we also leverage the estimate of users' prospective preferences to signify important items, and generate better recommendations. Our experimental results demonstrate that P2MAM models significantly outperform the state-of-the-art methods in six benchmark datasets, with an improvement as much as 19.2%. In addition, our run-time performance comparison demonstrates that during testing, P2MAM models are much more efficient than the best baseline method, with a significant average speedup of 47.7 folds.
MultiBiSage: A Web-Scale Recommendation System Using Multiple Bipartite Graphs at Pinterest
May 21, 2022

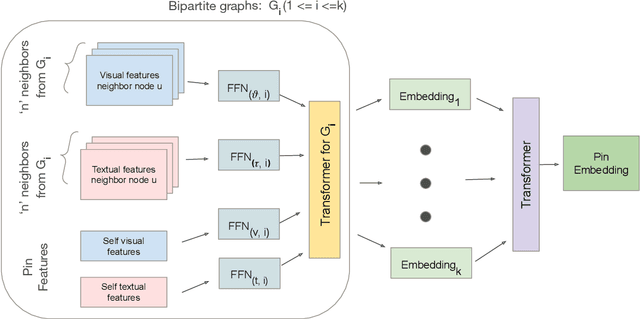
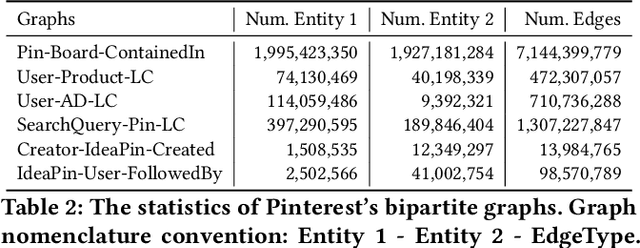
Graph Convolutional Networks (GCN) can efficiently integrate graph structure and node features to learn high-quality node embeddings. These embeddings can then be used for several tasks such as recommendation and search. At Pinterest, we have developed and deployed PinSage, a data-efficient GCN that learns pin embeddings from the Pin-Board graph. The Pin-Board graph contains pin and board entities and the graph captures the pin belongs to a board interaction. However, there exist several entities at Pinterest such as users, idea pins, creators, and there exist heterogeneous interactions among these entities such as add-to-cart, follow, long-click. In this work, we show that training deep learning models on graphs that captures these diverse interactions would result in learning higher-quality pin embeddings than training PinSage on only the Pin-Board graph. To that end, we model the diverse entities and their diverse interactions through multiple bipartite graphs and propose a novel data-efficient MultiBiSage model. MultiBiSage can capture the graph structure of multiple bipartite graphs to learn high-quality pin embeddings. We take this pragmatic approach as it allows us to utilize the existing infrastructure developed at Pinterest -- such as Pixie system that can perform optimized random-walks on billion node graphs, along with existing training and deployment workflows. We train MultiBiSage on six bipartite graphs including our Pin-Board graph. Our offline metrics show that MultiBiSage significantly outperforms the deployed latest version of PinSage on multiple user engagement metrics.