 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Long Roll-outs of Auto-regressive Neural Operators for the Compressible Navier-Stokes Equations with Conserved Quantity Correction
Jan 30, 2026Deep learning has been proposed as an efficient alternative for the numerical approximation of PDE solutions, offering fast, iterative simulation of PDEs through the approximation of solution operators. However, deep learning solutions have struggle to perform well over long prediction durations due to the accumulation of auto-regressive error, which is compounded by the inability of models to conserve physical quantities. In this work, we present conserved quantity correction, a model-agnostic technique for incorporation physical conservation criteria within deep learning models. Our results demonstrate consistent improvement in the long-term stability of auto-regressive neural operator models, regardless of the model architecture. Furthermore, we analyze the performance of neural operators from the spectral domain, highlighting significant limitations of present architectures. These results highlight the need for future work to consider architectures that place specific emphasis on high frequency components, which are integral to the understanding and modeling of turbulent flows.
DiffER: Categorical Diffusion for Chemical Retrosynthesis
May 29, 2025Methods for automatic chemical retrosynthesis have found recent success through the application of models traditionally built for natural language processing, primarily through transformer neural networks. These models have demonstrated significant ability to translate between the SMILES encodings of chemical products and reactants, but are constrained as a result of their autoregressive nature. We propose DiffER, an alternative template-free method for retrosynthesis prediction in the form of categorical diffusion, which allows the entire output SMILES sequence to be predicted in unison. We construct an ensemble of diffusion models which achieves state-of-the-art performance for top-1 accuracy and competitive performance for top-3, top-5, and top-10 accuracy among template-free methods. We prove that DiffER is a strong baseline for a new class of template-free model, capable of learning a variety of synthetic techniques used in laboratory settings and outperforming a variety of other template-free methods on top-k accuracy metrics. By constructing an ensemble of categorical diffusion models with a novel length prediction component with variance, our method is able to approximately sample from the posterior distribution of reactants, producing results with strong metrics of confidence and likelihood. Furthermore, our analyses demonstrate that accurate prediction of the SMILES sequence length is key to further boosting the performance of categorical diffusion models.
FairMod: Fair Link Prediction and Recommendation via Graph Modification
Jan 27, 2022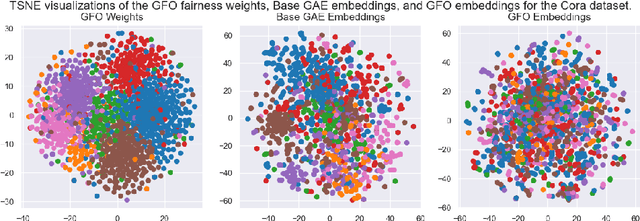
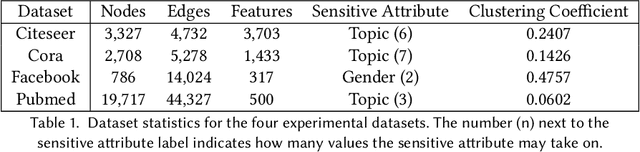
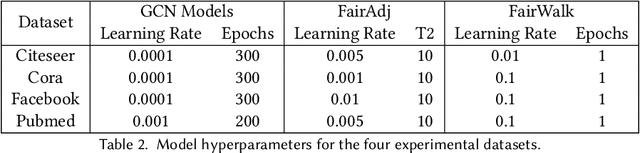
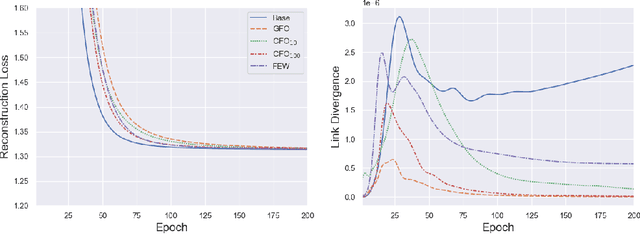
As machine learning becomes more widely adopted across domains, it is critical that researchers and ML engineers think about the inherent biases in the data that may be perpetuated by the model. Recently, many studies have shown that such biases are also imbibed in Graph Neural Network (GNN) models if the input graph is biased. In this work, we aim to mitigate the bias learned by GNNs through modifying the input graph. To that end, we propose FairMod, a Fair Graph Modification methodology with three formulations: the Global Fairness Optimization (GFO), Community Fairness Optimization (CFO), and Fair Edge Weighting (FEW) models. Our proposed models perform either microscopic or macroscopic edits to the input graph while training GNNs and learn node embeddings that are both accurate and fair under the context of link recommendations. We demonstrate the effectiveness of our approach on four real world datasets and show that we can improve the recommendation fairness by several factors at negligible cost to link prediction accuracy.
Aedes-AI: Neural Network Models of Mosquito Abundance
Apr 21, 2021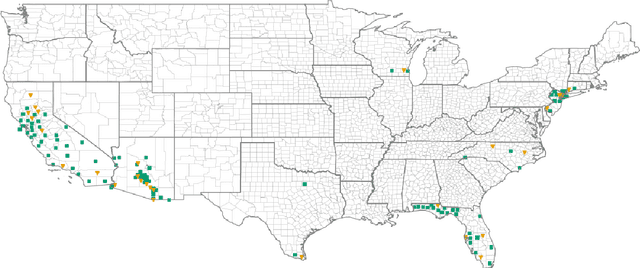
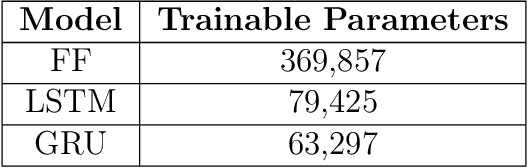
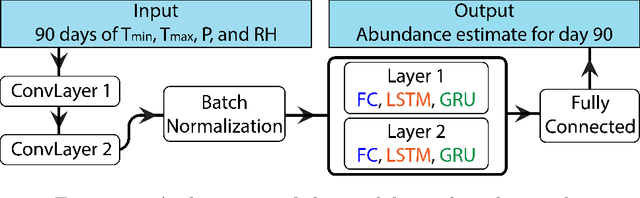
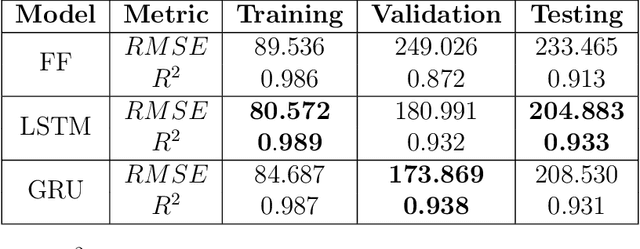
We present artificial neural networks as a feasible replacement for a mechanistic model of mosquito abundance. We develop a feed-forward neural network, a long short-term memory recurrent neural network, and a gated recurrent unit network. We evaluate the networks in their ability to replicate the spatiotemporal features of mosquito populations predicted by the mechanistic model, and discuss how augmenting the training data with both actual and artificially created time series affects model performance. We conclude with an outlook on how such equation-free models may facilitate vector control or the estimation of disease risk at arbitrary spatial scales.