 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhyPrompt: RL-based Prompt Refinement for Physically Plausible Text-to-Video Generation
Mar 03, 2026State-of-the-art text-to-video (T2V) generators frequently violate physical laws despite high visual quality. We show this stems from insufficient physical constraints in prompts rather than model limitations: manually adding physics details reliably produces physically plausible videos, but requires expertise and does not scale. We present PhyPrompt, a two-stage reinforcement learning framework that automatically refines prompts for physically realistic generation. First, we fine-tune a large language model on a physics-focused Chain-of-Thought dataset to integrate principles like object motion and force interactions while preserving user intent. Second, we apply Group Relative Policy Optimization with a dynamic reward curriculum that initially prioritizes semantic fidelity, then progressively shifts toward physical commonsense. This curriculum achieves synergistic optimization: PhyPrompt-7B reaches 40.8\% joint success on VideoPhy2 (8.6pp gain), improving physical commonsense by 11pp (55.8\% to 66.8\%) while simultaneously increasing semantic adherence by 4.4pp (43.4\% to 47.8\%). Remarkably, our curriculum exceeds single-objective training on both metrics, demonstrating compositional prompt discovery beyond conventional multi-objective trade-offs. PhyPrompt outperforms GPT-4o (+3.8\% joint) and DeepSeek-V3 (+2.2\%, 100$\times$ larger) using only 7B parameters. The approach transfers zero-shot across diverse T2V architectures (Lavie, VideoCrafter2, CogVideoX-5B) with up to 16.8\% improvement, establishing that domain-specialized reinforcement learning with compositional curricula surpasses general-purpose scaling for physics-aware generation.
Phys4D: Fine-Grained Physics-Consistent 4D Modeling from Video Diffusion
Mar 03, 2026Recent video diffusion models have achieved impressive capabilities as large-scale generative world models. However, these models often struggle with fine-grained physical consistency, exhibiting physically implausible dynamics over time. In this work, we present \textbf{Phys4D}, a pipeline for learning physics-consistent 4D world representations from video diffusion models. Phys4D adopts \textbf{a three-stage training paradigm} that progressively lifts appearance-driven video diffusion models into physics-consistent 4D world representations. We first bootstrap robust geometry and motion representations through large-scale pseudo-supervised pretraining, establishing a foundation for 4D scene modeling. We then perform physics-grounded supervised fine-tuning using simulation-generated data, enforcing temporally consistent 4D dynamics. Finally, we apply simulation-grounded reinforcement learning to correct residual physical violations that are difficult to capture through explicit supervision. To evaluate fine-grained physical consistency beyond appearance-based metrics, we introduce a set of \textbf{4D world consistency evaluation} that probe geometric coherence, motion stability, and long-horizon physical plausibility. Experimental results demonstrate that Phys4D substantially improves fine-grained spatiotemporal and physical consistency compared to appearance-driven baselines, while maintaining strong generative performance. Our project page is available at https://sensational-brioche-7657e7.netlify.app/
Towards Sparse Video Understanding and Reasoning
Feb 14, 2026We present \revise (\underline{Re}asoning with \underline{Vi}deo \underline{S}parsity), a multi-round agent for video question answering (VQA). Instead of uniformly sampling frames, \revise selects a small set of informative frames, maintains a summary-as-state across rounds, and stops early when confident. It supports proprietary vision-language models (VLMs) in a ``plug-and-play'' setting and enables reinforcement fine-tuning for open-source models. For fine-tuning, we introduce EAGER (Evidence-Adjusted Gain for Efficient Reasoning), an annotation-free reward with three terms: (1) Confidence gain: after new frames are added, we reward the increase in the log-odds gap between the correct option and the strongest alternative; (2) Summary sufficiency: at answer time we re-ask using only the last committed summary and reward success; (3) Correct-and-early stop: answering correctly within a small turn budget is rewarded. Across multiple VQA benchmarks, \revise improves accuracy while reducing frames, rounds, and prompt tokens, demonstrating practical sparse video reasoning.
DPAR: Dynamic Patchification for Efficient Autoregressive Visual Generation
Dec 26, 2025Decoder-only autoregressive image generation typically relies on fixed-length tokenization schemes whose token counts grow quadratically with resolution, substantially increasing the computational and memory demands of attention. We present DPAR, a novel decoder-only autoregressive model that dynamically aggregates image tokens into a variable number of patches for efficient image generation. Our work is the first to demonstrate that next-token prediction entropy from a lightweight and unsupervised autoregressive model provides a reliable criterion for merging tokens into larger patches based on information content. DPAR makes minimal modifications to the standard decoder architecture, ensuring compatibility with multimodal generation frameworks and allocating more compute to generation of high-information image regions. Further, we demonstrate that training with dynamically sized patches yields representations that are robust to patch boundaries, allowing DPAR to scale to larger patch sizes at inference. DPAR reduces token count by 1.81x and 2.06x on Imagenet 256 and 384 generation resolution respectively, leading to a reduction of up to 40% FLOPs in training costs. Further, our method exhibits faster convergence and improves FID by up to 27.1% relative to baseline models.
A Generic Framework for Conformal Fairness
May 22, 2025



Conformal Prediction (CP) is a popular method for uncertainty quantification with machine learning models. While conformal prediction provides probabilistic guarantees regarding the coverage of the true label, these guarantees are agnostic to the presence of sensitive attributes within the dataset. In this work, we formalize \textit{Conformal Fairness}, a notion of fairness using conformal predictors, and provide a theoretically well-founded algorithm and associated framework to control for the gaps in coverage between different sensitive groups. Our framework leverages the exchangeability assumption (implicit to CP) rather than the typical IID assumption, allowing us to apply the notion of Conformal Fairness to data types and tasks that are not IID, such as graph data. Experiments were conducted on graph and tabular datasets to demonstrate that the algorithm can control fairness-related gaps in addition to coverage aligned with theoretical expectations.
Graph Sparsification for Enhanced Conformal Prediction in Graph Neural Networks
Oct 28, 2024



Conformal Prediction is a robust framework that ensures reliable coverage across machine learning tasks. Although recent studies have applied conformal prediction to graph neural networks, they have largely emphasized post-hoc prediction set generation. Improving conformal prediction during the training stage remains unaddressed. In this work, we tackle this challenge from a denoising perspective by introducing SparGCP, which incorporates graph sparsification and a conformal prediction-specific objective into GNN training. SparGCP employs a parameterized graph sparsification module to filter out task-irrelevant edges, thereby improving conformal prediction efficiency. Extensive experiments on real-world graph datasets demonstrate that SparGCP outperforms existing methods, reducing prediction set sizes by an average of 32\% and scaling seamlessly to large networks on commodity GPUs.
Benchmarking Graph Conformal Prediction: Empirical Analysis, Scalability, and Theoretical Insights
Sep 26, 2024

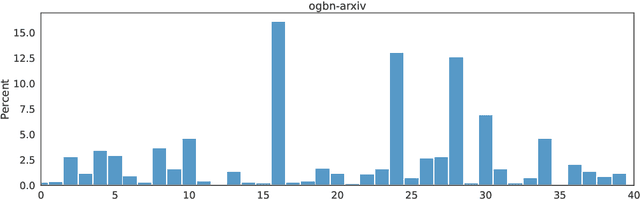

Conformal prediction has become increasingly popular for quantifying the uncertainty associated with machine learning models. Recent work in graph uncertainty quantification has built upon this approach for conformal graph prediction. The nascent nature of these explorations has led to conflicting choices for implementations, baselines, and method evaluation. In this work, we analyze the design choices made in the literature and discuss the tradeoffs associated with existing methods. Building on the existing implementations for existing methods, we introduce techniques to scale existing methods to large-scale graph datasets without sacrificing performance. Our theoretical and empirical results justify our recommendations for future scholarship in graph conformal prediction.
StyleML: Stylometry with Structure and Multitask Learning for Darkweb Markets
Apr 01, 2021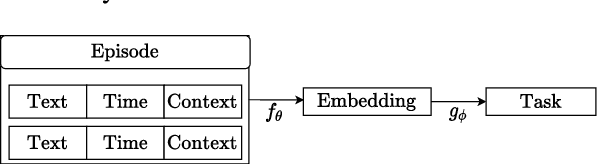
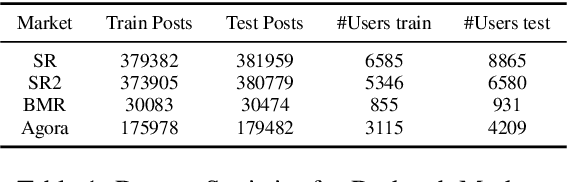
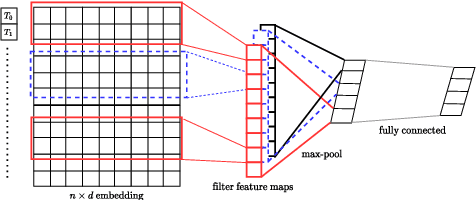
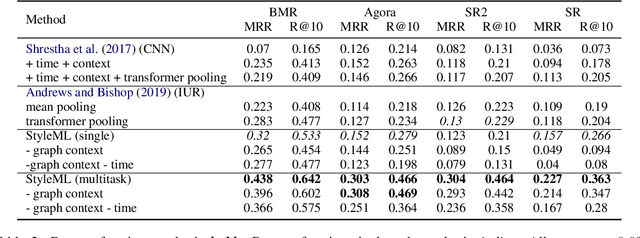
Darknet market forums are frequently used to exchange illegal goods and services between parties who use encryption to conceal their identities. The Tor network is used to host these markets, which guarantees additional anonymization from IP and location tracking, making it challenging to link across malicious users using multiple accounts (sybils). Additionally, users migrate to new forums when one is closed, making it difficult to link users across multiple forums. We develop a novel stylometry-based multitask learning approach for natural language and interaction modeling using graph embeddings to construct low-dimensional representations of short episodes of user activity for authorship attribution. We provide a comprehensive evaluation of our methods across four different darknet forums demonstrating its efficacy over the state-of-the-art, with a lift of up to 2.5X on Mean Retrieval Rank and 2X on Recall@10.
Understanding Knowledge Gaps in Visual Question Answering: Implications for Gap Identification and Testing
Apr 08, 2020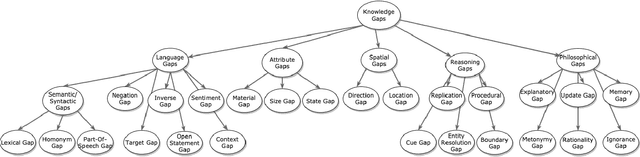
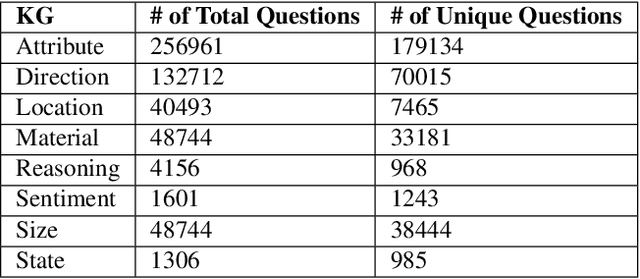

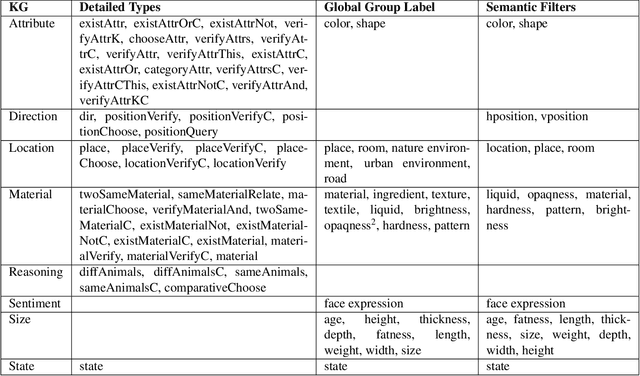
Visual Question Answering (VQA) systems are tasked with answering natural language questions corresponding to a presented image. Current VQA datasets typically contain questions related to the spatial information of objects, object attributes, or general scene questions. Recently, researchers have recognized the need for improving the balance of such datasets to reduce the system's dependency on memorized linguistic features and statistical biases and to allow for improved visual understanding. However, it is unclear as to whether there are any latent patterns that can be used to quantify and explain these failures. To better quantify our understanding of the performance of VQA models, we use a taxonomy of Knowledge Gaps (KGs) to identify/tag questions with one or more types of KGs. Each KG describes the reasoning abilities needed to arrive at a resolution, and failure to resolve gaps indicate an absence of the required reasoning ability. After identifying KGs for each question, we examine the skew in the distribution of the number of questions for each KG. In order to reduce the skew in the distribution of questions across KGs, we introduce a targeted question generation model. This model allows us to generate new types of questions for an image.
LEAF-QA: Locate, Encode & Attend for Figure Question Answering
Jul 30, 2019
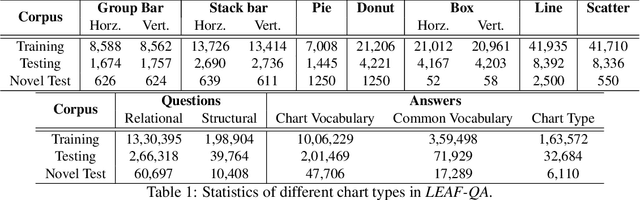
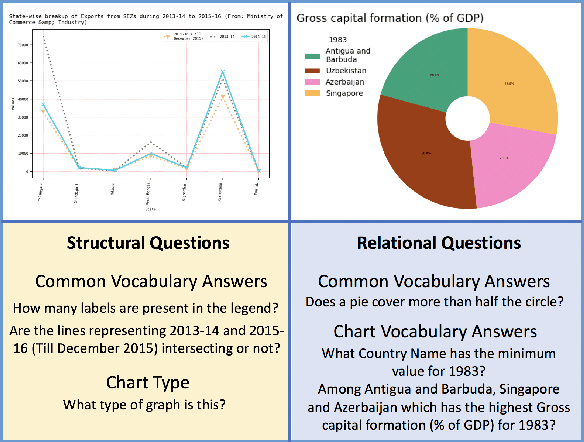
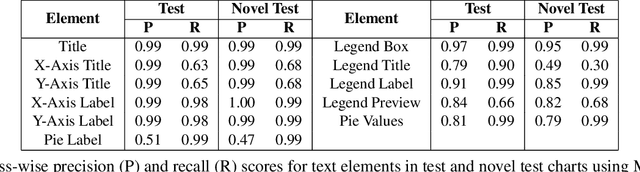
We introduce LEAF-QA, a comprehensive dataset of $250,000$ densely annotated figures/charts, constructed from real-world open data sources, along with ~2 million question-answer (QA) pairs querying the structure and semantics of these charts. LEAF-QA highlights the problem of multimodal QA, which is notably different from conventional visual QA (VQA), and has recently gained interest in the community. Furthermore, LEAF-QA is significantly more complex than previous attempts at chart QA, viz. FigureQA and DVQA, which present only limited variations in chart data. LEAF-QA being constructed from real-world sources, requires a novel architecture to enable question answering. To this end, LEAF-Net, a deep architecture involving chart element localization, question and answer encoding in terms of chart elements, and an attention network is proposed. Different experiments are conducted to demonstrate the challenges of QA on LEAF-QA. The proposed architecture, LEAF-Net also considerably advances the current state-of-the-art on FigureQA and DVQA.