 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairness-aware Summarization for Justified Decision-Making
Paper and Code

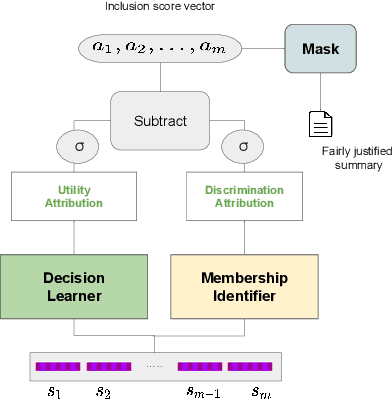

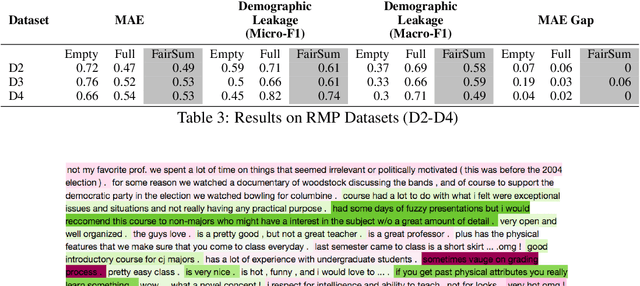
In many applications such as recidivism prediction, facility inspection, and benefit assignment, it's important for individuals to know the decision-relevant information for the model's prediction. In addition, the model's predictions should be fairly justified. Essentially, decision-relevant features should provide sufficient information for the predicted outcome and should be independent of the membership of individuals in protected groups such as race and gender. In this work, we focus on the problem of (un)fairness in the justification of the text-based neural models. We tie the explanatory power of the model to fairness in the outcome and propose a fairness-aware summarization mechanism to detect and counteract the bias in such models. Given a potentially biased natural language explanation for a decision, we use a multi-task neural model and an attribution mechanism based on integrated gradients to extract the high-utility and discrimination-free justifications in the form of a summary. The extracted summary is then used for training a model to make decisions for individuals. Results on several real-world datasets suggests that our method: (i) assists users to understand what information is used for the model's decision and (ii) enhances the fairness in outcomes while significantly reducing the demographic leakage.