 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDialogXpert: Driving Intelligent and Emotion-Aware Conversations through Online Value-Based Reinforcement Learning with LLM Priors
May 23, 2025Large-language-model (LLM) agents excel at reactive dialogue but struggle with proactive, goal-driven interactions due to myopic decoding and costly planning. We introduce DialogXpert, which leverages a frozen LLM to propose a small, high-quality set of candidate actions per turn and employs a compact Q-network over fixed BERT embeddings trained via temporal-difference learning to select optimal moves within this reduced space. By tracking the user's emotions, DialogXpert tailors each decision to advance the task while nurturing a genuine, empathetic connection. Across negotiation, emotional support, and tutoring benchmarks, DialogXpert drives conversations to under $3$ turns with success rates exceeding 94\% and, with a larger LLM prior, pushes success above 97\% while markedly improving negotiation outcomes. This framework delivers real-time, strategic, and emotionally intelligent dialogue planning at scale. Code available at https://github.com/declare-lab/dialogxpert/
From Grounding to Manipulation: Case Studies of Foundation Model Integration in Embodied Robotic Systems
May 21, 2025

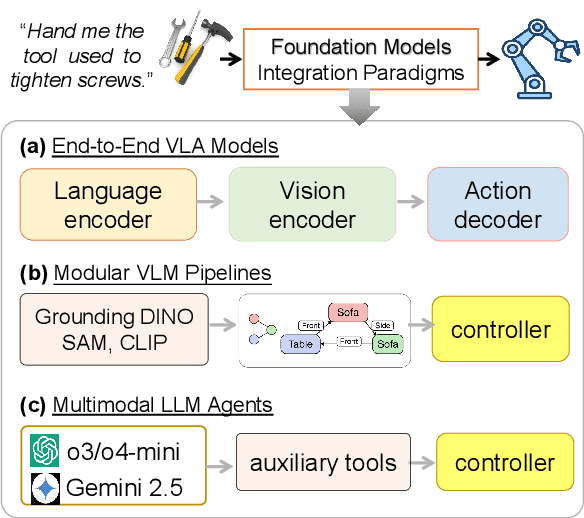

Foundation models (FMs) are increasingly used to bridge language and action in embodied agents, yet the operational characteristics of different FM integration strategies remain under-explored -- particularly for complex instruction following and versatile action generation in changing environments. This paper examines three paradigms for building robotic systems: end-to-end vision-language-action (VLA) models that implicitly integrate perception and planning, and modular pipelines incorporating either vision-language models (VLMs) or multimodal large language models (LLMs). We evaluate these paradigms through two focused case studies: a complex instruction grounding task assessing fine-grained instruction understanding and cross-modal disambiguation, and an object manipulation task targeting skill transfer via VLA finetuning. Our experiments in zero-shot and few-shot settings reveal trade-offs in generalization and data efficiency. By exploring performance limits, we distill design implications for developing language-driven physical agents and outline emerging challenges and opportunities for FM-powered robotics in real-world conditions.
PREMISE: Matching-based Prediction for Accurate Review Recommendation
May 02, 2025



We present PREMISE (PREdict with Matching ScorEs), a new architecture for the matching-based learning in the multimodal fields for the multimodal review helpfulness (MRHP) task. Distinct to previous fusion-based methods which obtains multimodal representations via cross-modal attention for downstream tasks, PREMISE computes the multi-scale and multi-field representations, filters duplicated semantics, and then obtained a set of matching scores as feature vectors for the downstream recommendation task. This new architecture significantly boosts the performance for such multimodal tasks whose context matching content are highly correlated to the targets of that task, compared to the state-of-the-art fusion-based methods. Experimental results on two publicly available datasets show that PREMISE achieves promising performance with less computational cost.
NORA: A Small Open-Sourced Generalist Vision Language Action Model for Embodied Tasks
Apr 28, 2025



Existing Visual-Language-Action (VLA) models have shown promising performance in zero-shot scenarios, demonstrating impressive task execution and reasoning capabilities. However, a significant challenge arises from the limitations of visual encoding, which can result in failures during tasks such as object grasping. Moreover, these models typically suffer from high computational overhead due to their large sizes, often exceeding 7B parameters. While these models excel in reasoning and task planning, the substantial computational overhead they incur makes them impractical for real-time robotic environments, where speed and efficiency are paramount. To address the limitations of existing VLA models, we propose NORA, a 3B-parameter model designed to reduce computational overhead while maintaining strong task performance. NORA adopts the Qwen-2.5-VL-3B multimodal model as its backbone, leveraging its superior visual-semantic understanding to enhance visual reasoning and action grounding. Additionally, our \model{} is trained on 970k real-world robot demonstrations and equipped with the FAST+ tokenizer for efficient action sequence generation. Experimental results demonstrate that NORA outperforms existing large-scale VLA models, achieving better task performance with significantly reduced computational overhead, making it a more practical solution for real-time robotic autonomy.
PromptDistill: Query-based Selective Token Retention in Intermediate Layers for Efficient Large Language Model Inference
Mar 30, 2025



As large language models (LLMs) tackle increasingly complex tasks and longer documents, their computational and memory costs during inference become a major bottleneck. To address this, we propose PromptDistill, a novel, training-free method that improves inference efficiency while preserving generation quality. PromptDistill identifies and retains the most informative tokens by leveraging attention interactions in early layers, preserving their hidden states while reducing the computational burden in later layers. This allows the model to focus on essential contextual information without fully processing all tokens. Unlike previous methods such as H2O and SnapKV, which perform compression only after processing the entire input, or GemFilter, which selects a fixed portion of the initial prompt without considering contextual dependencies, PromptDistill dynamically allocates computational resources to the most relevant tokens while maintaining a global awareness of the input. Experiments using our method and baseline approaches with base models such as LLaMA 3.1 8B Instruct, Phi 3.5 Mini Instruct, and Qwen2 7B Instruct on benchmarks including LongBench, InfBench, and Needle in a Haystack demonstrate that PromptDistill significantly improves efficiency while having minimal impact on output quality compared to the original models. With a single-stage selection strategy, PromptDistill effectively balances performance and efficiency, outperforming prior methods like GemFilter, H2O, and SnapKV due to its superior ability to retain essential information. Specifically, compared to GemFilter, PromptDistill achieves an overall $1\%$ to $5\%$ performance improvement while also offering better time efficiency. Additionally, we explore multi-stage selection, which further improves efficiency while maintaining strong generation performance.
DiffPO: Diffusion-styled Preference Optimization for Efficient Inference-Time Alignment of Large Language Models
Mar 06, 2025Inference-time alignment provides an efficient alternative for aligning LLMs with humans. However, these approaches still face challenges, such as limited scalability due to policy-specific value functions and latency during the inference phase. In this paper, we propose a novel approach, Diffusion-styled Preference Optimization (\model), which provides an efficient and policy-agnostic solution for aligning LLMs with humans. By directly performing alignment at sentence level, \model~avoids the time latency associated with token-level generation. Designed as a plug-and-play module, \model~can be seamlessly integrated with various base models to enhance their alignment. Extensive experiments on AlpacaEval 2, MT-bench, and HH-RLHF demonstrate that \model~achieves superior alignment performance across various settings, achieving a favorable trade-off between alignment quality and inference-time latency. Furthermore, \model~demonstrates model-agnostic scalability, significantly improving the performance of large models such as Llama-3-70B.
Pixel-Level Reasoning Segmentation via Multi-turn Conversations
Feb 13, 2025Existing visual perception systems focus on region-level segmentation in single-turn dialogues, relying on complex and explicit query instructions. Such systems cannot reason at the pixel level and comprehend dynamic user intent that changes over interaction. Our work tackles this issue by introducing a novel task, Pixel-level Reasoning Segmentation (Pixel-level RS) based on multi-turn conversations, tracking evolving user intent via multi-turn interactions for fine-grained segmentation. To establish a benchmark for this novel task, we build a Pixel-level ReasonIng Segmentation Dataset Based on Multi-Turn Conversations (PRIST), comprising 24k utterances from 8.3k multi-turn conversational scenarios with segmentation targets. Building on PRIST, we further propose MIRAS, a Multi-turn Interactive ReAsoning Segmentation framework, integrates pixel-level segmentation with robust multi-turn conversation understanding, generating pixel-grounded explanations aligned with user intent. The PRIST dataset and MIRSA framework fill the gap in pixel-level reasoning segmentation. Experimental results on the PRIST dataset demonstrate that our method outperforms current segmentation-specific baselines in terms of segmentation and LLM-based reasoning metrics. The code and data are available at: https://github.com/ccccai239/PixelRIST.
The Jumping Reasoning Curve? Tracking the Evolution of Reasoning Performance in GPT-[n] and o-[n] Models on Multimodal Puzzles
Feb 03, 2025![Figure 1 for The Jumping Reasoning Curve? Tracking the Evolution of Reasoning Performance in GPT-[n] and o-[n] Models on Multimodal Puzzles](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2F24658d26647e5a2123e7f3e0e71ede50cccc47d1%2F7-Table1-1.png&w=640&q=75)
![Figure 2 for The Jumping Reasoning Curve? Tracking the Evolution of Reasoning Performance in GPT-[n] and o-[n] Models on Multimodal Puzzles](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2F24658d26647e5a2123e7f3e0e71ede50cccc47d1%2F2-Figure2-1.png&w=640&q=75)
![Figure 3 for The Jumping Reasoning Curve? Tracking the Evolution of Reasoning Performance in GPT-[n] and o-[n] Models on Multimodal Puzzles](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2F24658d26647e5a2123e7f3e0e71ede50cccc47d1%2F11-Table2-1.png&w=640&q=75)
![Figure 4 for The Jumping Reasoning Curve? Tracking the Evolution of Reasoning Performance in GPT-[n] and o-[n] Models on Multimodal Puzzles](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2F24658d26647e5a2123e7f3e0e71ede50cccc47d1%2F3-Figure3-1.png&w=640&q=75)
The releases of OpenAI's o1 and o3 mark a significant paradigm shift in Large Language Models towards advanced reasoning capabilities. Notably, o3 outperformed humans in novel problem-solving and skill acquisition on the Abstraction and Reasoning Corpus for Artificial General Intelligence (ARC-AGI). However, this benchmark is limited to symbolic patterns, whereas humans often perceive and reason about multimodal scenarios involving both vision and language data. Thus, there is an urgent need to investigate advanced reasoning capabilities in multimodal tasks. To this end, we track the evolution of the GPT-[n] and o-[n] series models on challenging multimodal puzzles, requiring fine-grained visual perception with abstract or algorithmic reasoning. The superior performance of o1 comes at nearly 750 times the computational cost of GPT-4o, raising concerns about its efficiency. Our results reveal a clear upward trend in reasoning capabilities across model iterations, with notable performance jumps across GPT-series models and subsequently to o1. Nonetheless, we observe that the o1 model still struggles with simple multimodal puzzles requiring abstract reasoning. Furthermore, its performance in algorithmic puzzles remains poor. We plan to continuously track new models in the series and update our results in this paper accordingly. All resources used in this evaluation are openly available https://github.com/declare-lab/LLM-PuzzleTest.
PROEMO: Prompt-Driven Text-to-Speech Synthesis Based on Emotion and Intensity Control
Jan 10, 2025Speech synthesis has significantly advanced from statistical methods to deep neural network architectures, leading to various text-to-speech (TTS) models that closely mimic human speech patterns. However, capturing nuances such as emotion and style in speech synthesis is challenging. To address this challenge, we introduce an approach centered on prompt-based emotion control. The proposed architecture incorporates emotion and intensity control across multi-speakers. Furthermore, we leverage large language models (LLMs) to manipulate speech prosody while preserving linguistic content. Using embedding emotional cues, regulating intensity levels, and guiding prosodic variations with prompts, our approach infuses synthesized speech with human-like expressiveness and variability. Lastly, we demonstrate the effectiveness of our approach through a systematic exploration of the control mechanisms mentioned above.
TangoFlux: Super Fast and Faithful Text to Audio Generation with Flow Matching and Clap-Ranked Preference Optimization
Dec 30, 2024We introduce TangoFlux, an efficient Text-to-Audio (TTA) generative model with 515M parameters, capable of generating up to 30 seconds of 44.1kHz audio in just 3.7 seconds on a single A40 GPU. A key challenge in aligning TTA models lies in the difficulty of creating preference pairs, as TTA lacks structured mechanisms like verifiable rewards or gold-standard answers available for Large Language Models (LLMs). To address this, we propose CLAP-Ranked Preference Optimization (CRPO), a novel framework that iteratively generates and optimizes preference data to enhance TTA alignment. We demonstrate that the audio preference dataset generated using CRPO outperforms existing alternatives. With this framework, TangoFlux achieves state-of-the-art performance across both objective and subjective benchmarks. We open source all code and models to support further research in TTA generation.