 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Representation Learning for Histopathologic Images with Cluster Constraints
Oct 18, 2023



Recent advances in whole-slide image (WSI) scanners and computational capabilities have significantly propelled the application of artificial intelligence in histopathology slide analysis. While these strides are promising, current supervised learning approaches for WSI analysis come with the challenge of exhaustively labeling high-resolution slides - a process that is both labor-intensive and time-consuming. In contrast, self-supervised learning (SSL) pretraining strategies are emerging as a viable alternative, given that they don't rely on explicit data annotations. These SSL strategies are quickly bridging the performance disparity with their supervised counterparts. In this context, we introduce an SSL framework. This framework aims for transferable representation learning and semantically meaningful clustering by synergizing invariance loss and clustering loss in WSI analysis. Notably, our approach outperforms common SSL methods in downstream classification and clustering tasks, as evidenced by tests on the Camelyon16 and a pancreatic cancer dataset. The code and additional details are accessible at: https://github.com/wwyi1828/CluSiam.
* Accepted by ICCV2023
SimVLG: Simple and Efficient Pretraining of Visual Language Generative Models
Oct 07, 2023



In this paper, we propose ``SimVLG'', a streamlined framework for the pre-training of computationally intensive vision-language generative models, leveraging frozen pre-trained large language models (LLMs). The prevailing paradigm in vision-language pre-training (VLP) typically involves a two-stage optimization process: an initial resource-intensive phase dedicated to general-purpose vision-language representation learning, aimed at extracting and consolidating pertinent visual features, followed by a subsequent phase focusing on end-to-end alignment between visual and linguistic modalities. Our one-stage, single-loss framework circumvents the aforementioned computationally demanding first stage of training by gradually merging similar visual tokens during training. This gradual merging process effectively compacts the visual information while preserving the richness of semantic content, leading to fast convergence without sacrificing performance. Our experiments show that our approach can speed up the training of vision-language models by a factor $\times 5$ without noticeable impact on the overall performance. Additionally, we show that our models can achieve comparable performance to current vision-language models with only $1/10$ of the data. Finally, we demonstrate how our image-text models can be easily adapted to video-language generative tasks through a novel soft attentive temporal token merging modules.
Bootstrapping Vision-Language Learning with Decoupled Language Pre-training
Jul 13, 2023



We present a novel methodology aimed at optimizing the application of frozen large language models (LLMs) for resource-intensive vision-language (VL) pre-training. The current paradigm uses visual features as prompts to guide language models, with a focus on determining the most relevant visual features for corresponding text. Our approach diverges by concentrating on the language component, specifically identifying the optimal prompts to align with visual features. We introduce the Prompt-Transformer (P-Former), a model that predicts these ideal prompts, which is trained exclusively on linguistic data, bypassing the need for image-text pairings. This strategy subtly bifurcates the end-to-end VL training process into an additional, separate stage. Our experiments reveal that our framework significantly enhances the performance of a robust image-to-text baseline (BLIP-2), and effectively narrows the performance gap between models trained with either 4M or 129M image-text pairs. Importantly, our framework is modality-agnostic and flexible in terms of architectural design, as validated by its successful application in a video learning task using varied base modules. The code is available at https://github.com/yiren-jian/BLIText
Graph-Level Embedding for Time-Evolving Graphs
Jun 01, 2023Graph representation learning (also known as network embedding) has been extensively researched with varying levels of granularity, ranging from nodes to graphs. While most prior work in this area focuses on node-level representation, limited research has been conducted on graph-level embedding, particularly for dynamic or temporal networks. However, learning low-dimensional graph-level representations for dynamic networks is critical for various downstream graph retrieval tasks such as temporal graph similarity ranking, temporal graph isomorphism, and anomaly detection. In this paper, we present a novel method for temporal graph-level embedding that addresses this gap. Our approach involves constructing a multilayer graph and using a modified random walk with temporal backtracking to generate temporal contexts for the graph's nodes. We then train a "document-level" language model on these contexts to generate graph-level embeddings. We evaluate our proposed model on five publicly available datasets for the task of temporal graph similarity ranking, and our model outperforms baseline methods. Our experimental results demonstrate the effectiveness of our method in generating graph-level embeddings for dynamic networks.
Training Socially Aligned Language Models in Simulated Human Society
May 26, 2023



Social alignment in AI systems aims to ensure that these models behave according to established societal values. However, unlike humans, who derive consensus on value judgments through social interaction, current language models (LMs) are trained to rigidly replicate their training corpus in isolation, leading to subpar generalization in unfamiliar scenarios and vulnerability to adversarial attacks. This work presents a novel training paradigm that permits LMs to learn from simulated social interactions. In comparison to existing methodologies, our approach is considerably more scalable and efficient, demonstrating superior performance in alignment benchmarks and human evaluations. This paradigm shift in the training of LMs brings us a step closer to developing AI systems that can robustly and accurately reflect societal norms and values.
Knowledge from Large-Scale Protein Contact Prediction Models Can Be Transferred to the Data-Scarce RNA Contact Prediction Task
Feb 13, 2023RNA, whose functionality is largely determined by its structure, plays an important role in many biological activities. The prediction of pairwise structural proximity between each nucleotide of an RNA sequence can characterize the structural information of the RNA. Historically, this problem has been tackled by machine learning models using expert-engineered features and trained on scarce labeled datasets. Here, we find that the knowledge learned by a protein-coevolution Transformer-based deep neural network can be transferred to the RNA contact prediction task. As protein datasets are orders of magnitude larger than those for RNA contact prediction, our findings and the subsequent framework greatly reduce the data scarcity bottleneck. Experiments confirm that RNA contact prediction through transfer learning using a publicly available protein model is greatly improved. Our findings indicate that the learned structural patterns of proteins can be transferred to RNAs, opening up potential new avenues for research.
Capturing Topic Framing via Masked Language Modeling
Feb 07, 2023



Differential framing of issues can lead to divergent world views on important issues. This is especially true in domains where the information presented can reach a large audience, such as traditional and social media. Scalable and reliable measurement of such differential framing is an important first step in addressing them. In this work, based on the intuition that framing affects the tone and word choices in written language, we propose a framework for modeling the differential framing of issues through masked token prediction via large-scale fine-tuned language models (LMs). Specifically, we explore three key factors for our framework: 1) prompt generation methods for the masked token prediction; 2) methods for normalizing the output of fine-tuned LMs; 3) robustness to the choice of pre-trained LMs used for fine-tuning. Through experiments on a dataset of articles from traditional media outlets covering five diverse and politically polarized topics, we show that our framework can capture differential framing of these topics with high reliability.
* In Findings of EMNLP 2022
Second Thoughts are Best: Learning to Re-Align With Human Values from Text Edits
Jan 05, 2023



We present Second Thought, a new learning paradigm that enables language models (LMs) to re-align with human values. By modeling the chain-of-edits between value-unaligned and value-aligned text, with LM fine-tuning and additional refinement through reinforcement learning, Second Thought not only achieves superior performance in three value alignment benchmark datasets but also shows strong human-value transfer learning ability in few-shot scenarios. The generated editing steps also offer better interpretability and ease for interactive error correction. Extensive human evaluations further confirm its effectiveness.
Mind's Eye: Grounded Language Model Reasoning through Simulation
Oct 11, 2022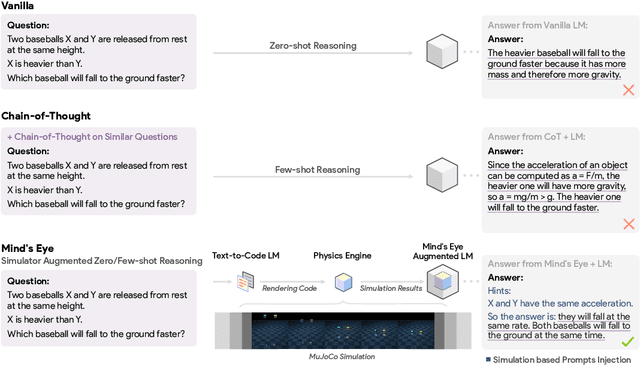


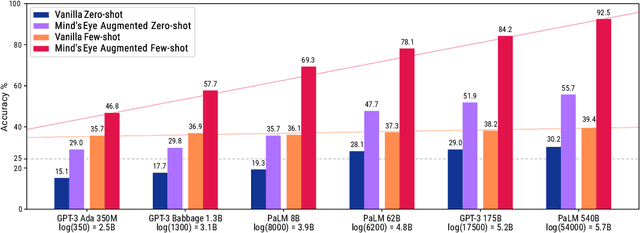
Successful and effective communication between humans and AI relies on a shared experience of the world. By training solely on written text, current language models (LMs) miss the grounded experience of humans in the real-world -- their failure to relate language to the physical world causes knowledge to be misrepresented and obvious mistakes in their reasoning. We present Mind's Eye, a paradigm to ground language model reasoning in the physical world. Given a physical reasoning question, we use a computational physics engine (DeepMind's MuJoCo) to simulate the possible outcomes, and then use the simulation results as part of the input, which enables language models to perform reasoning. Experiments on 39 tasks in a physics alignment benchmark demonstrate that Mind's Eye can improve reasoning ability by a large margin (27.9% zero-shot, and 46.0% few-shot absolute accuracy improvement on average). Smaller language models armed with Mind's Eye can obtain similar performance to models that are 100x larger. Finally, we confirm the robustness of Mind's Eye through ablation studies.
Language Models are Multilingual Chain-of-Thought Reasoners
Oct 06, 2022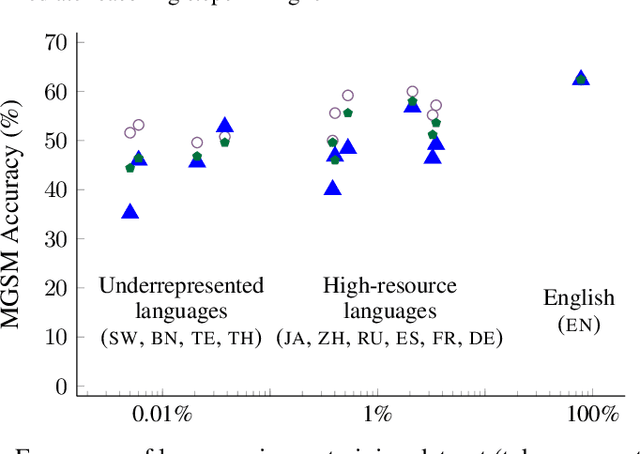


We evaluate the reasoning abilities of large language models in multilingual settings. We introduce the Multilingual Grade School Math (MGSM) benchmark, by manually translating 250 grade-school math problems from the GSM8K dataset (Cobbe et al., 2021) into ten typologically diverse languages. We find that the ability to solve MGSM problems via chain-of-thought prompting emerges with increasing model scale, and that models have strikingly strong multilingual reasoning abilities, even in underrepresented languages such as Bengali and Swahili. Finally, we show that the multilingual reasoning abilities of language models extend to other tasks such as commonsense reasoning and word-in-context semantic judgment. The MGSM benchmark is publicly available at https://github.com/google-research/url-nlp.