 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Model Calibration for Long-Tailed Object Detection and Instance Segmentation
Jul 05, 2021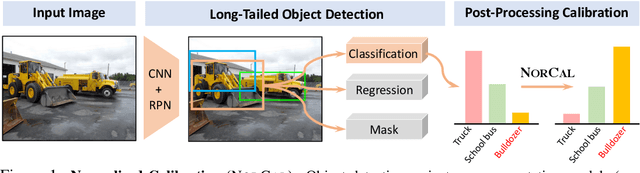
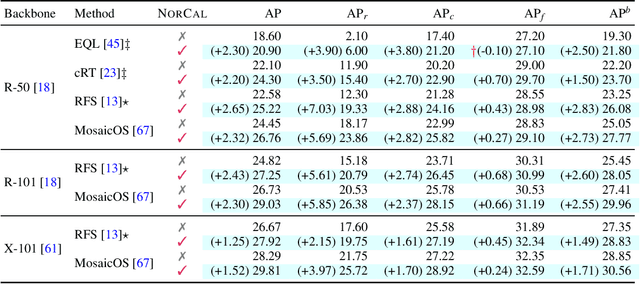
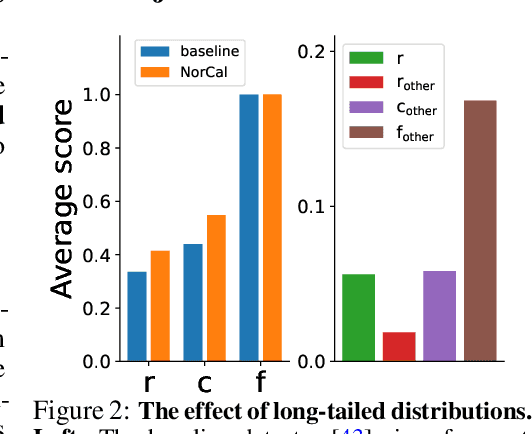

Vanilla models for object detection and instance segmentation suffer from the heavy bias toward detecting frequent objects in the long-tailed setting. Existing methods address this issue mostly during training, e.g., by re-sampling or re-weighting. In this paper, we investigate a largely overlooked approach -- post-processing calibration of confidence scores. We propose NorCal, Normalized Calibration for long-tailed object detection and instance segmentation, a simple and straightforward recipe that reweighs the predicted scores of each class by its training sample size. We show that separately handling the background class and normalizing the scores over classes for each proposal are keys to achieving superior performance. On the LVIS dataset, NorCal can effectively improve nearly all the baseline models not only on rare classes but also on common and frequent classes. Finally, we conduct extensive analysis and ablation studies to offer insights into various modeling choices and mechanisms of our approach.
2.5D Visual Relationship Detection
Apr 26, 2021
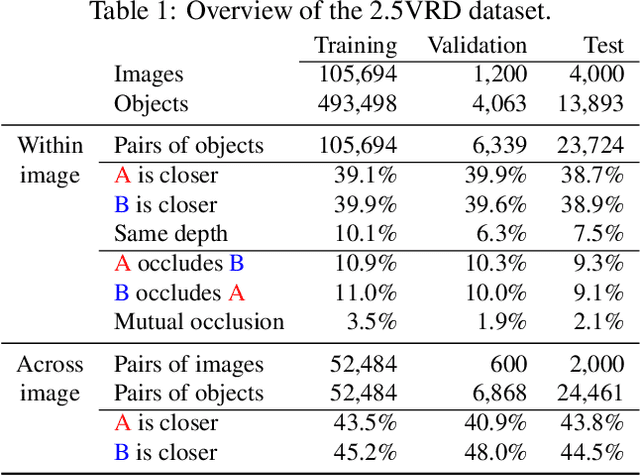
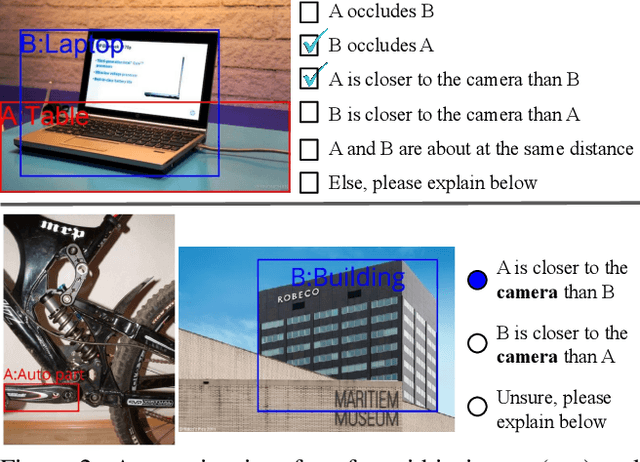

Visual 2.5D perception involves understanding the semantics and geometry of a scene through reasoning about object relationships with respect to the viewer in an environment. However, existing works in visual recognition primarily focus on the semantics. To bridge this gap, we study 2.5D visual relationship detection (2.5VRD), in which the goal is to jointly detect objects and predict their relative depth and occlusion relationships. Unlike general VRD, 2.5VRD is egocentric, using the camera's viewpoint as a common reference for all 2.5D relationships. Unlike depth estimation, 2.5VRD is object-centric and not only focuses on depth. To enable progress on this task, we create a new dataset consisting of 220k human-annotated 2.5D relationships among 512K objects from 11K images. We analyze this dataset and conduct extensive experiments including benchmarking multiple state-of-the-art VRD models on this task. Our results show that existing models largely rely on semantic cues and simple heuristics to solve 2.5VRD, motivating further research on models for 2.5D perception. The new dataset is available at https://github.com/google-research-datasets/2.5vrd.
Conceptual 12M: Pushing Web-Scale Image-Text Pre-Training To Recognize Long-Tail Visual Concepts
Feb 17, 2021
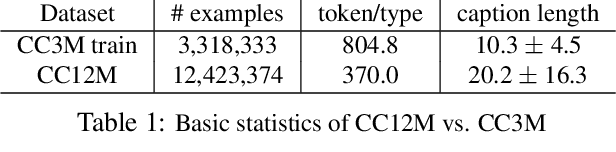

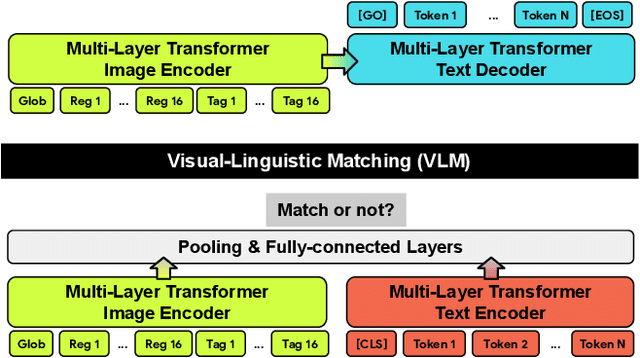
The availability of large-scale image captioning and visual question answering datasets has contributed significantly to recent successes in vision-and-language pre-training. However, these datasets are often collected with overrestrictive requirements, inherited from their original target tasks (e.g., image caption generation), which limit the resulting dataset scale and diversity. We take a step further in pushing the limits of vision-and-language pre-training data by relaxing the data collection pipeline used in Conceptual Captions 3M (CC3M) [Sharma et al. 2018] and introduce the Conceptual 12M (CC12M), a dataset with 12 million image-text pairs specifically meant to be used for vision-and-language pre-training. We perform an analysis of this dataset, as well as benchmark its effectiveness against CC3M on multiple downstream tasks with an emphasis on long-tail visual recognition. The quantitative and qualitative results clearly illustrate the benefit of scaling up pre-training data for vision-and-language tasks, as indicated by the new state-of-the-art results on both the nocaps and Conceptual Captions benchmarks.
A Simple and Effective Use of Object-Centric Images for Long-Tailed Object Detection
Feb 17, 2021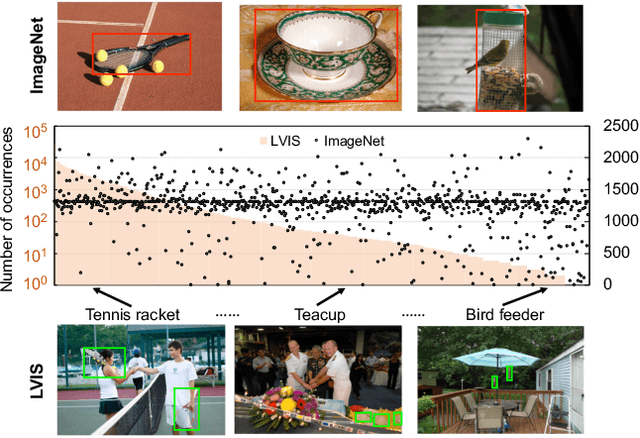
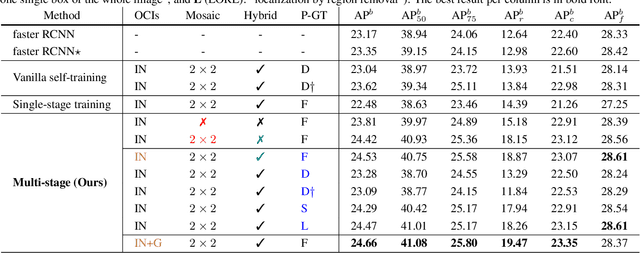

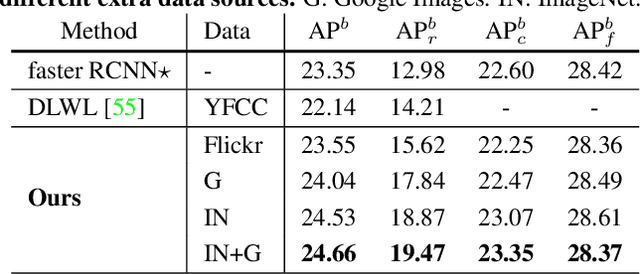
Object frequencies in daily scenes follow a long-tailed distribution. Many objects do not appear frequently enough in scene-centric images (e.g., sightseeing, street views) for us to train accurate object detectors. In contrast, these objects are captured at a higher frequency in object-centric images, which are intended to picture the objects of interest. Motivated by this phenomenon, we propose to take advantage of the object-centric images to improve object detection in scene-centric images. We present a simple yet surprisingly effective framework to do so. On the one hand, our approach turns an object-centric image into a useful training example for object detection in scene-centric images by mitigating the domain gap between the two image sources in both the input and label space. On the other hand, our approach employs a multi-stage procedure to train the object detector, such that the detector learns the diverse object appearances from object-centric images while being tied to the application domain of scene-centric images. On the LVIS dataset, our approach can improve the object detection (and instance segmentation) accuracy of rare objects by 50% (and 33%) relatively, without sacrificing the performance of other classes.
Telling the What while Pointing the Where: Fine-grained Mouse Trace and Language Supervision for Improved Image Retrieval
Feb 09, 2021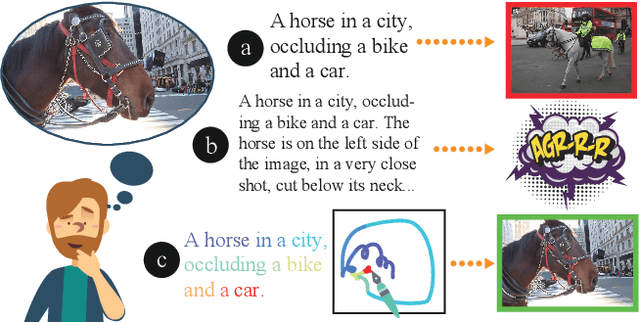
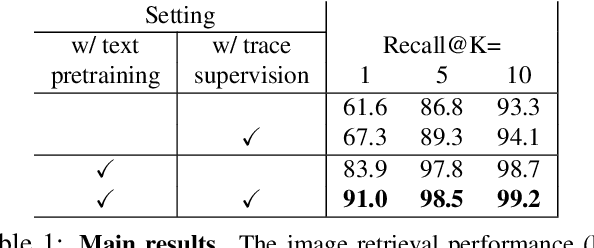


Existing image retrieval systems use text queries to provide a natural and practical way for users to express what they are looking for. However, fine-grained image retrieval often requires the ability to also express the where in the image the content they are looking for is. The textual modality can only cumbersomely express such localization preferences, whereas pointing would be a natural fit. In this paper, we describe an image retrieval setup where the user simultaneously describes an image using both spoken natural language (the "what") and mouse traces over an empty canvas (the "where") to express the characteristics of the desired target image. To this end, we learn an image retrieval model using the Localized Narratives dataset, which is capable of performing early fusion between text descriptions and synchronized mouse traces. Qualitative and quantitative experiments show that our model is capable of taking this spatial guidance into account, and provides more accurate retrieval results compared to text-only equivalent systems.
Weakly Supervised Content Selection for Improved Image Captioning
Sep 10, 2020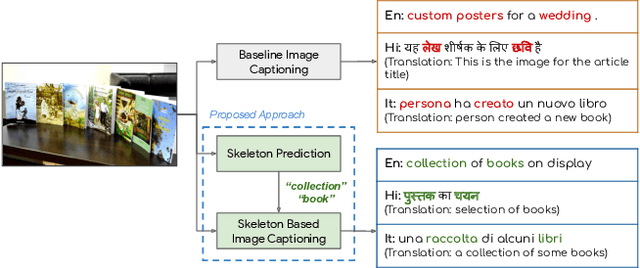
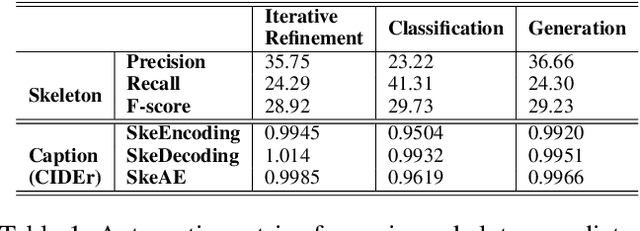
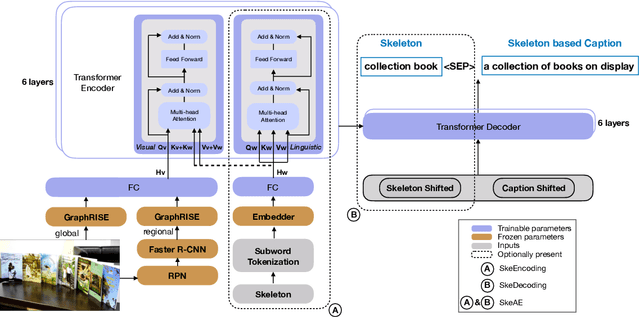
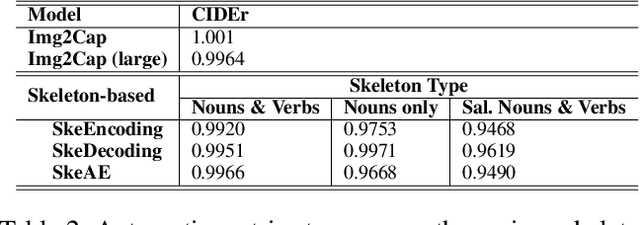
Image captioning involves identifying semantic concepts in the scene and describing them in fluent natural language. Recent approaches do not explicitly model the semantic concepts and train the model only for the end goal of caption generation. Such models lack interpretability and controllability, primarily due to sub-optimal content selection. We address this problem by breaking down the captioning task into two simpler, manageable and more controllable tasks -- skeleton prediction and skeleton-based caption generation. We approach the former as a weakly supervised task, using a simple off-the-shelf language syntax parser and avoiding the need for additional human annotations; the latter uses a supervised-learning approach. We investigate three methods of conditioning the caption on skeleton in the encoder, decoder and both. Our compositional model generates significantly better quality captions on out of domain test images, as judged by human annotators. Additionally, we demonstrate the cross-language effectiveness of the English skeleton to other languages including French, Italian, German, Spanish and Hindi. This compositional nature of captioning exhibits the potential of unpaired image captioning, thereby reducing the dependence on expensive image-caption pairs. Furthermore, we investigate the use of skeletons as a knob to control certain properties of the generated image caption, such as length, content, and gender expression.
Connecting Vision and Language with Localized Narratives
Dec 06, 2019
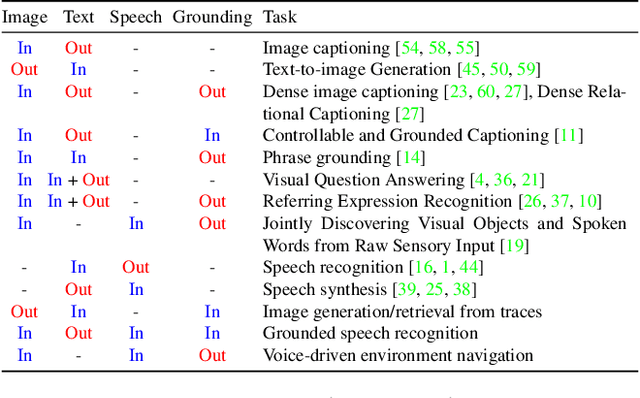

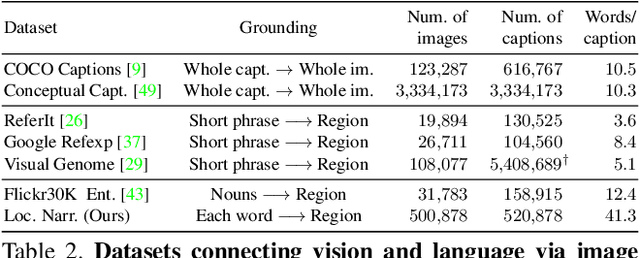
We propose Localized Narratives, an efficient way to collect image captions with dense visual grounding. We ask annotators to describe an image with their voice while simultaneously hovering their mouse over the region they are describing. Since the voice and the mouse pointer are synchronized, we can localize every single word in the description. This dense visual grounding takes the form of a mouse trace segment per word and is unique to our data. We annotate 500k images with Localized Narratives: the whole COCO dataset and 380k images of the Open Images dataset. We provide an extensive analysis of these annotations, which we will release early 2020. Moreover, we demonstrate the utility of our data on two applications which benefit from our mouse trace: controlled image captioning and image generation.
Decoupled Box Proposal and Featurization with Ultrafine-Grained Semantic Labels Improve Image Captioning and Visual Question Answering
Sep 04, 2019
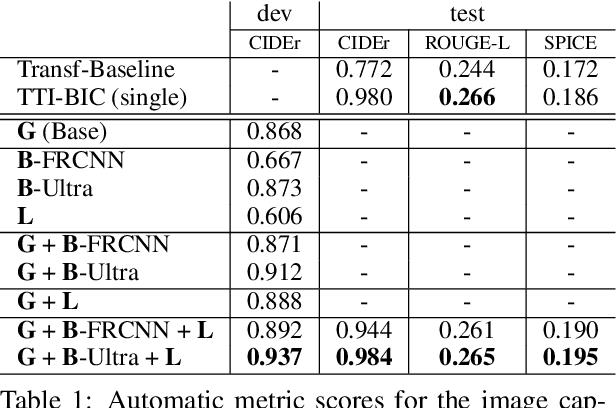

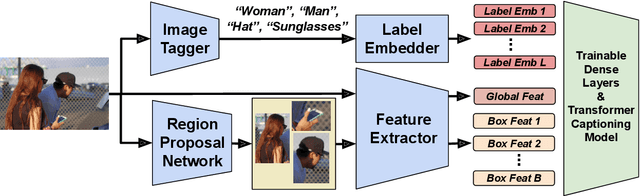
Object detection plays an important role in current solutions to vision and language tasks like image captioning and visual question answering. However, popular models like Faster R-CNN rely on a costly process of annotating ground-truths for both the bounding boxes and their corresponding semantic labels, making it less amenable as a primitive task for transfer learning. In this paper, we examine the effect of decoupling box proposal and featurization for down-stream tasks. The key insight is that this allows us to leverage a large amount of labeled annotations that were previously unavailable for standard object detection benchmarks. Empirically, we demonstrate that this leads to effective transfer learning and improved image captioning and visual question answering models, as measured on publicly available benchmarks.
Classifier and Exemplar Synthesis for Zero-Shot Learning
Dec 16, 2018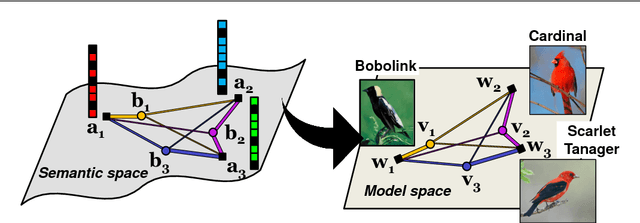
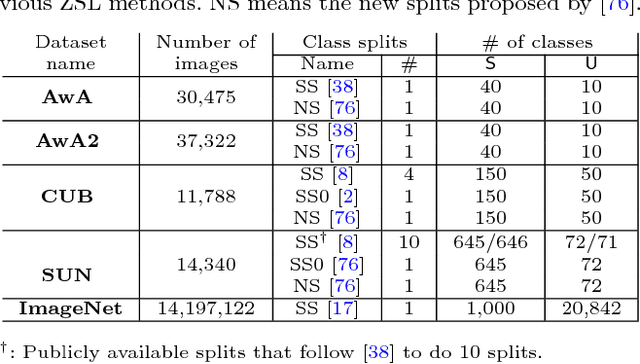
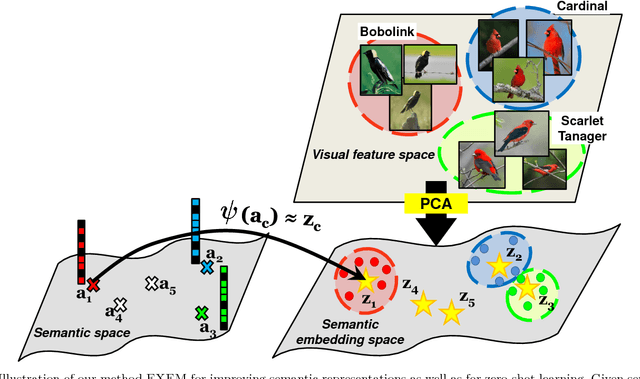
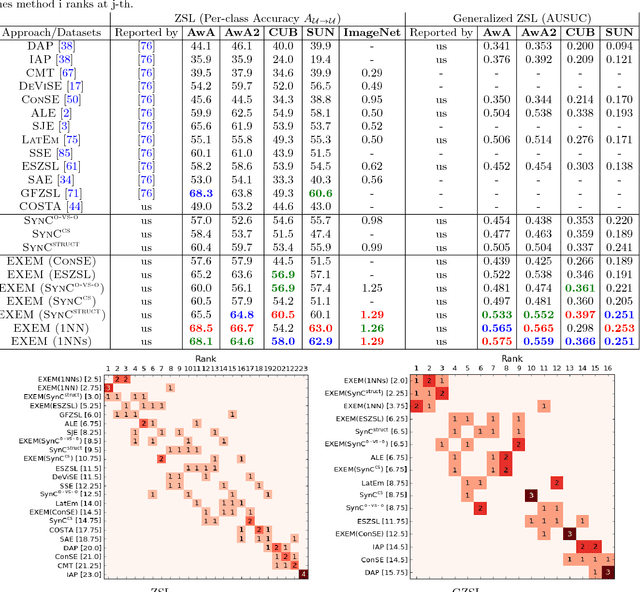
Zero-shot learning (ZSL) enables solving a task without the need to see its examples. In this paper, we propose two ZSL frameworks that learn to synthesize parameters for novel unseen classes. First, we propose to cast the problem of ZSL as learning manifold embeddings from graphs composed of object classes, leading to a flexible approach that synthesizes "classifiers" for the unseen classes. Then, we define an auxiliary task of synthesizing "exemplars" for the unseen classes to be used as an automatic denoising mechanism for any existing ZSL approaches or as an effective ZSL model by itself. On five visual recognition benchmark datasets, we demonstrate the superior performances of our proposed frameworks in various scenarios of both conventional and generalized ZSL. Finally, we provide valuable insights through a series of empirical analyses, among which are a comparison of semantic representations on the full ImageNet benchmark as well as a comparison of metrics used in generalized ZSL. Our code and data are publicly available at https://github.com/pujols/Zero-shot-learning-journal
Multi-Task Learning for Sequence Tagging: An Empirical Study
Aug 13, 2018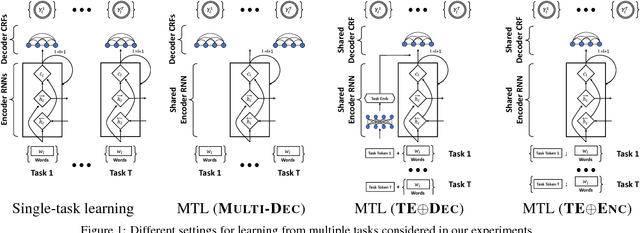
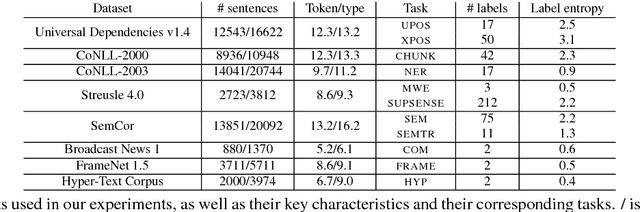

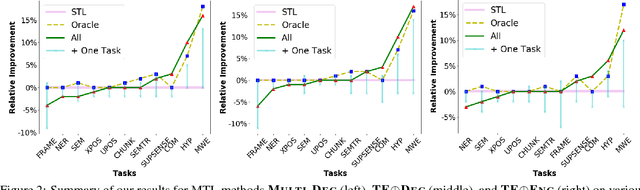
We study three general multi-task learning (MTL) approaches on 11 sequence tagging tasks. Our extensive empirical results show that in about 50% of the cases, jointly learning all 11 tasks improves upon either independent or pairwise learning of the tasks. We also show that pairwise MTL can inform us what tasks can benefit others or what tasks can be benefited if they are learned jointly. In particular, we identify tasks that can always benefit others as well as tasks that can always be harmed by others. Interestingly, one of our MTL approaches yields embeddings of the tasks that reveal the natural clustering of semantic and syntactic tasks. Our inquiries have opened the doors to further utilization of MTL in NLP.