 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndustryBench: Probing the Industrial Knowledge Boundaries of LLMs
May 11, 2026In industrial procurement, an LLM answer is useful only if it survives a standards check: recommended material must match operating condition, every parameter must respect a regulated threshold, and no procedure may contradict a safety clause. Partial correctness can mask safety-critical contradictions that aggregate LLM benchmarks rarely capture. We introduce IndustryBench, a 2,049-item benchmark for industrial procurement QA in Chinese, grounded in Chinese national standards (GB/T) and structured industrial product records, organized by seven capability dimensions, ten industry categories, and panel-derived difficulty tiers, with item-aligned English, Russian, and Vietnamese renderings. Our construction pipeline rejects 70.3% of LLM-generated candidates at a search-based external-verification stage, calibrating how unreliable industrial QA remains after LLM-only filtering.Our evaluation decouples raw correctness, scored by a Qwen3-Max judge validated at $κ_w = 0.798$ against a domain expert, from a separate safety-violation (SV) check against source texts. Across 17 models in Chinese and an 8-model intersection over four languages, we find: (i) the best system reaches only 2.083 on the 0--3 rubric, leaving substantial headroom; (ii) Standards & Terminology is the most persistent capability weakness and survives item-aligned translation; (iii) extended reasoning lowers safety-adjusted scores for 12 of 13 models, primarily by introducing unsupported safety-critical details into longer final answers; and (iv) safety-violation rates reshuffle the leaderboard -- GPT-5.4 climbs from rank 6 to rank 3 after SV adjustment, while Kimi-k2.5-1T-A32B drops seven positions.Industrial LLM evaluation therefore requires source-grounded, safety-aware diagnosis rather than aggregate accuracy. We release IndustryBench with all prompts, scoring scripts, and dataset documentation.
PDEAgent-Bench: A Multi-Metric, Multi-Library Benchmark for PDE Solver Generation
May 10, 2026PDE-to-solver code generation aims to automatically synthesize executable numerical solvers from partial differential equation (PDE) specifications. This task requires not only understanding the mathematical structure of PDEs, but also selecting appropriate discretization schemes and solver configurations, and correctly implementing the resulting formulations in finite-element method (FEM) libraries. Existing code generation benchmarks mainly evaluate syntactic correctness, or success on predefined test cases. To our knowledge, there is currently no publicly available benchmark specifically for PDE-to-solver code generation, and general-purpose code benchmarks do not fully capture the unique challenges of numerical PDE solution, such as ensuring solver accuracy, efficiency, and compatibility with professional FEM libraries. We introduce PDEAgent-Bench, to the best of our knowledge, the first multi-metric, multi-library benchmark for PDE-to-solver code generation. PDEAgent-Bench contains 645 instances across 6 mathematical categories and 11 PDE families, with common FEM libraries for DOLFINx, Firedrake, and deal.II. Each instance provides an agent-facing problem specification, a reference solution on a prescribed evaluation grid, and case-specific accuracy and runtime targets. PDEAgent-Bench adopts a staged evaluation framework in which generated solvers must sequentially pass executability, numerical accuracy, and computational efficiency checks. Experiments with representative LLMs and code agents show that models can often produce runnable code, but their pass rate drops substantially once accuracy and efficiency requirements are enforced. These results indicate that current agents remain limited in producing numerically reliable and efficient PDE solvers, and that PDEAgent-Bench provides a reproducible testbed grounded in the practical requirements of numerical PDE solving.
OpenCOOD-Air: Prompting Heterogeneous Ground-Air Collaborative Perception with Spatial Conversion and Offset Prediction
Mar 14, 2026While Vehicle-to-Vehicle (V2V) collaboration extends sensing ranges through multi-agent data sharing, its reliability remains severely constrained by ground-level occlusions and the limited perspective of chassis-mounted sensors, which often result in critical perception blind spots. We propose OpenCOOD-Air, a novel framework that integrates UAVs as extensible platforms into V2V collaborative perception to overcome these constraints. To mitigate gradient interference from ground-air domain gaps and data sparsity, we adopt a transfer learning strategy to fine-tune UAV weights from pre-trained V2V models. To prevent the spatial information loss inherent in this transition, we formulate ground-air collaborative perception as a heterogeneous integration task with explicit altitude supervision and introduce a Cross-Domain Spatial Converter (CDSC) and a Spatial Offset Prediction Transformer (SOPT). Furthermore, we present the OPV2V-Air benchmark to validate the transition from V2V to Vehicle-to-Vehicle-to-UAV. Compared to state-of-the-art methods, our approach improves 2D and 3D AP@0.7 by 4% and 7%, respectively.
MambaOcc: Visual State Space Model for BEV-based Occupancy Prediction with Local Adaptive Reordering
Aug 21, 2024Occupancy prediction has attracted intensive attention and shown great superiority in the development of autonomous driving systems. The fine-grained environmental representation brought by occupancy prediction in terms of both geometry and semantic information has facilitated the general perception and safe planning under open scenarios. However, it also brings high computation costs and heavy parameters in existing works that utilize voxel-based 3d dense representation and Transformer-based quadratic attention. To address these challenges, in this paper, we propose a Mamba-based occupancy prediction method (MambaOcc) adopting BEV features to ease the burden of 3D scenario representation, and linear Mamba-style attention to achieve efficient long-range perception. Besides, to address the sensitivity of Mamba to sequence order, we propose a local adaptive reordering (LAR) mechanism with deformable convolution and design a hybrid BEV encoder comprised of convolution layers and Mamba. Extensive experiments on the Occ3D-nuScenes dataset demonstrate that MambaOcc achieves state-of-the-art performance in terms of both accuracy and computational efficiency. For example, compared to FlashOcc, MambaOcc delivers superior results while reducing the number of parameters by 42\% and computational costs by 39\%. Code will be available at https://github.com/Hub-Tian/MambaOcc.
Deep Learning-enabled Spatial Phase Unwrapping for 3D Measurement
Aug 06, 2022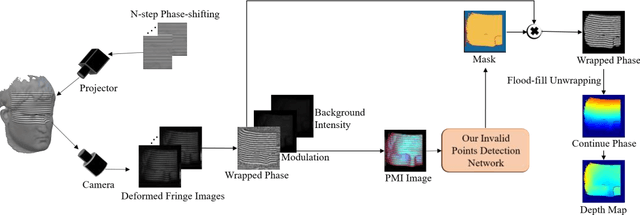
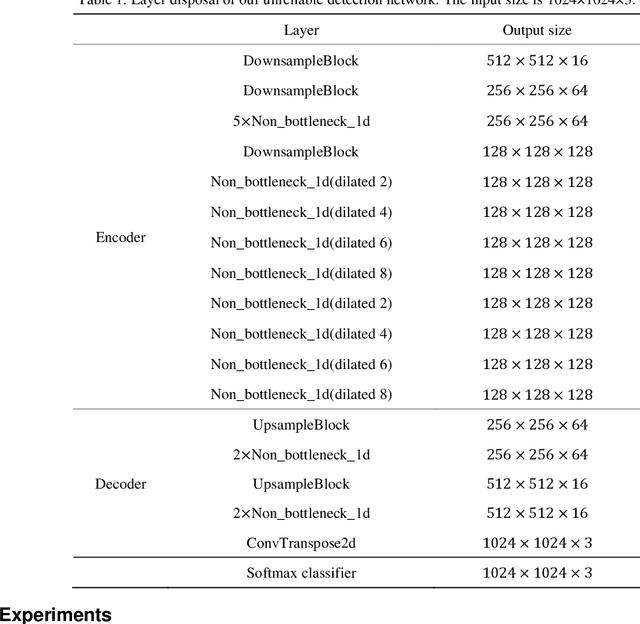
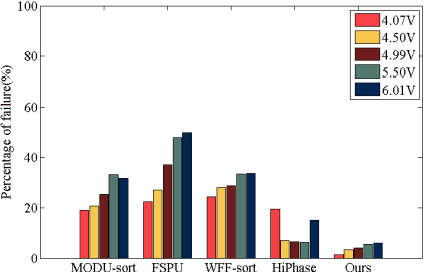
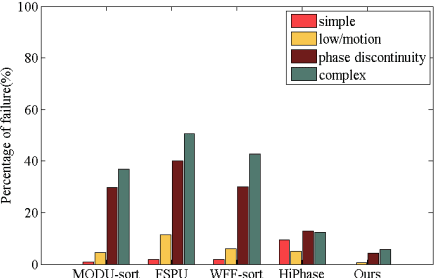
In terms of 3D imaging speed and system cost, the single-camera system projecting single-frequency patterns is the ideal option among all proposed Fringe Projection Profilometry (FPP) systems. This system necessitates a robust spatial phase unwrapping (SPU) algorithm. However, robust SPU remains a challenge in complex scenes. Quality-guided SPU algorithms need more efficient ways to identify the unreliable points in phase maps before unwrapping. End-to-end deep learning SPU methods face generality and interpretability problems. This paper proposes a hybrid method combining deep learning and traditional path-following for robust SPU in FPP. This hybrid SPU scheme demonstrates better robustness than traditional quality-guided SPU methods, better interpretability than end-to-end deep learning scheme, and generality on unseen data. Experiments on the real dataset of multiple illumination conditions and multiple FPP systems differing in image resolution, the number of fringes, fringe direction, and optics wavelength verify the effectiveness of the proposed method.