 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenCOOD-Air: Prompting Heterogeneous Ground-Air Collaborative Perception with Spatial Conversion and Offset Prediction
Mar 14, 2026While Vehicle-to-Vehicle (V2V) collaboration extends sensing ranges through multi-agent data sharing, its reliability remains severely constrained by ground-level occlusions and the limited perspective of chassis-mounted sensors, which often result in critical perception blind spots. We propose OpenCOOD-Air, a novel framework that integrates UAVs as extensible platforms into V2V collaborative perception to overcome these constraints. To mitigate gradient interference from ground-air domain gaps and data sparsity, we adopt a transfer learning strategy to fine-tune UAV weights from pre-trained V2V models. To prevent the spatial information loss inherent in this transition, we formulate ground-air collaborative perception as a heterogeneous integration task with explicit altitude supervision and introduce a Cross-Domain Spatial Converter (CDSC) and a Spatial Offset Prediction Transformer (SOPT). Furthermore, we present the OPV2V-Air benchmark to validate the transition from V2V to Vehicle-to-Vehicle-to-UAV. Compared to state-of-the-art methods, our approach improves 2D and 3D AP@0.7 by 4% and 7%, respectively.
Adaptive and Azimuth-Aware Fusion Network of Multimodal Local Features for 3D Object Detection
Oct 10, 2019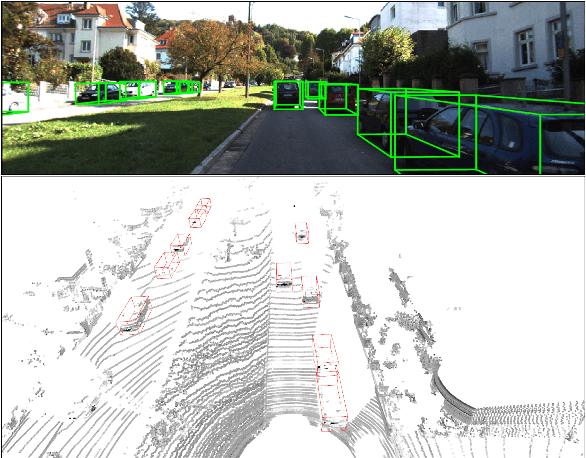
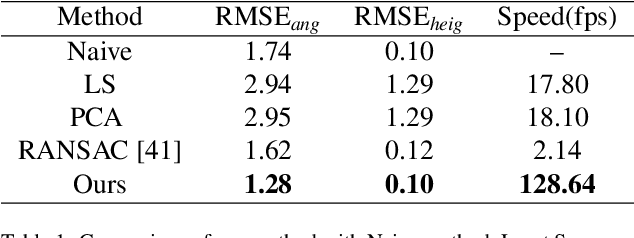
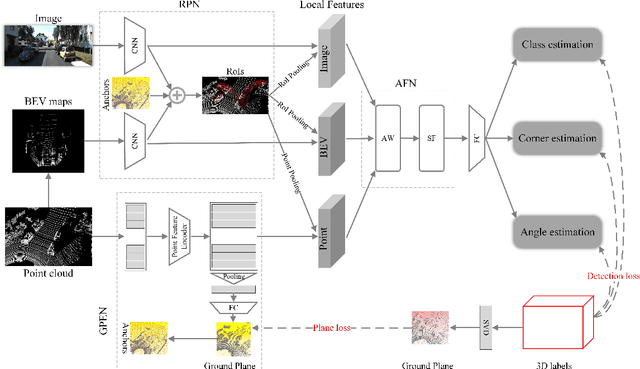
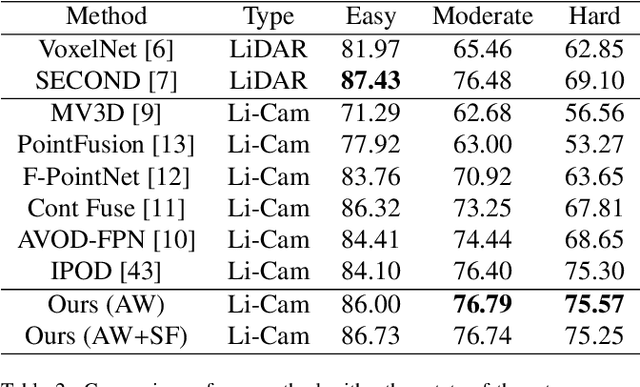
This paper focuses on the construction of stronger local features and the effective fusion of image and LiDAR data. We adopt different modalities of LiDAR data to generate richer features and present an adaptive and azimuth-aware network to aggregate local features from image, bird's eye view maps and point cloud. Our network mainly consists of three subnetworks: ground plane estimation network, region proposal network and adaptive fusion network. The ground plane estimation network extracts features of point cloud and predicts the parameters of a plane which are used for generating abundant 3D anchors. The region proposal network generates features of image and bird's eye view maps to output region proposals. To integrate heterogeneous image and point cloud features, the adaptive fusion network explicitly adjusts the intensity of multiple local features and achieves the orientation consistency between image and LiDAR data by introduce an azimuth-aware fusion module. Experiments are conducted on KITTI dataset and the results validate the advantages of our aggregation of multimodal local features and the adaptive fusion network.