 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotion-Based Generator Model: Unsupervised Disentanglement of Appearance, Trackable and Intrackable Motions in Dynamic Patterns
Nov 26, 2019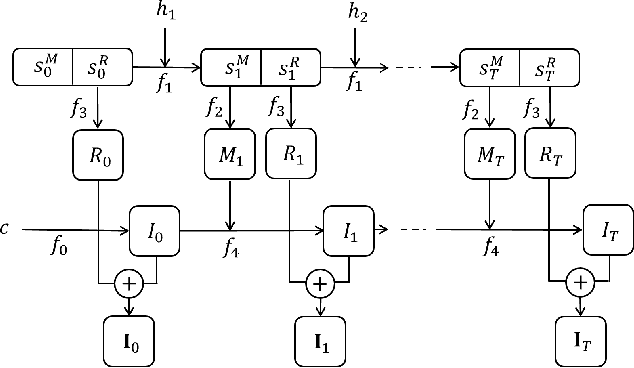

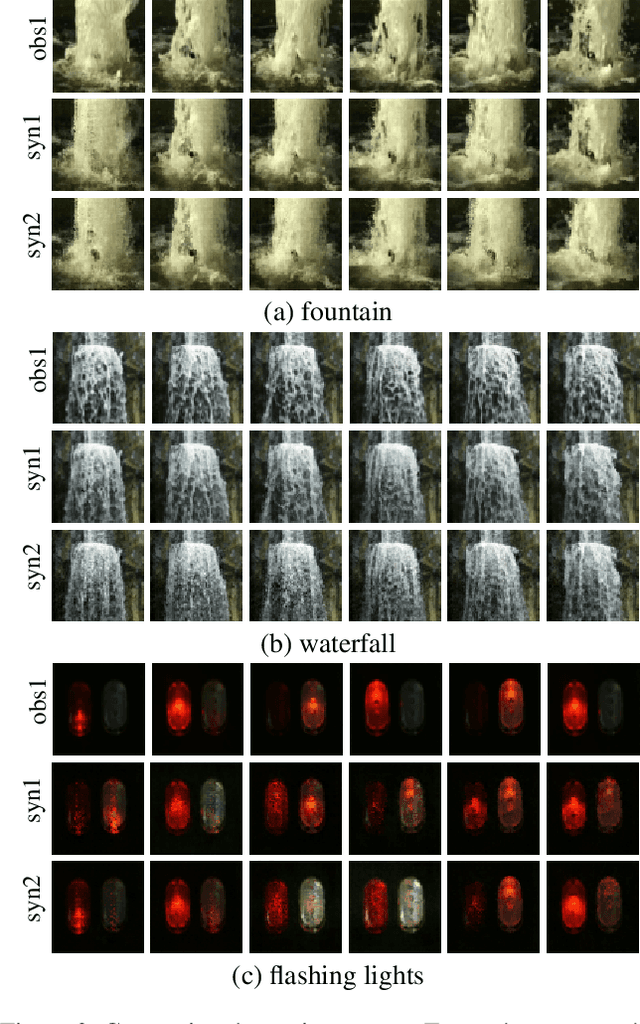
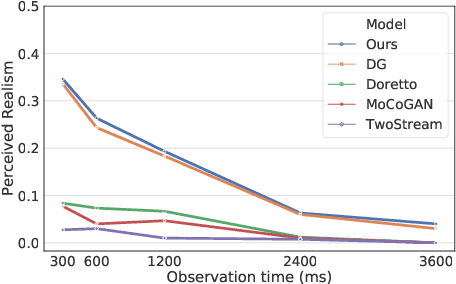
Dynamic patterns are characterized by complex spatial and motion patterns. Understanding dynamic patterns requires a disentangled representational model that separates the factorial components. A commonly used model for dynamic patterns is the state space model, where the state evolves over time according to a transition model and the state generates the observed image frames according to an emission model. To model the motions explicitly, it is natural for the model to be based on the motions or the displacement fields of the pixels. Thus in the emission model, we let the hidden state generate the displacement field, which warps the trackable component in the previous image frame to generate the next frame while adding a simultaneously emitted residual image to account for the change that cannot be explained by the deformation. The warping of the previous image is about the trackable part of the change of image frame, while the residual image is about the intrackable part of the image. We use a maximum likelihood algorithm to learn the model that iterates between inferring latent noise vectors that drive the transition model and updating the parameters given the inferred latent vectors. Meanwhile we adopt a regularization term to penalize the norms of the residual images to encourage the model to explain the change of image frames by trackable motion. Unlike existing methods on dynamic patterns, we learn our model in unsupervised setting without ground truth displacement fields. In addition, our model defines a notion of intrackability by the separation of warped component and residual component in each image frame. We show that our method can synthesize realistic dynamic pattern, and disentangling appearance, trackable and intrackable motions. The learned models are useful for motion transfer, and it is natural to adopt it to define and measure intrackability of a dynamic pattern.
Theory-based Causal Transfer: Integrating Instance-level Induction and Abstract-level Structure Learning
Nov 25, 2019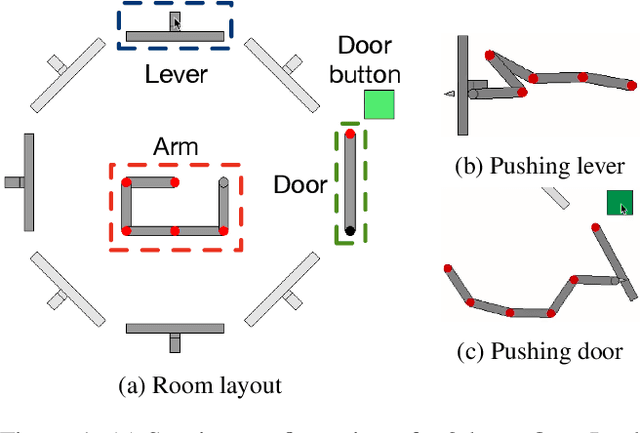
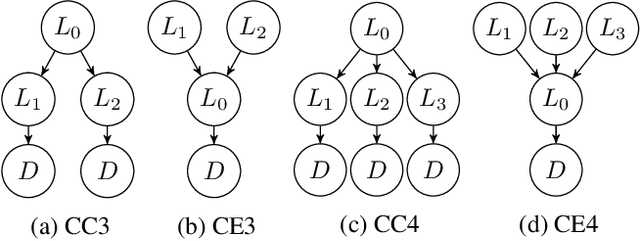
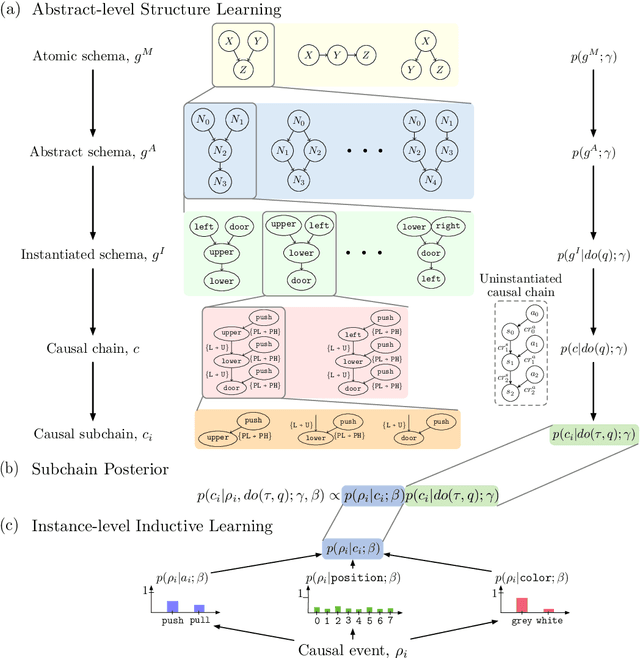
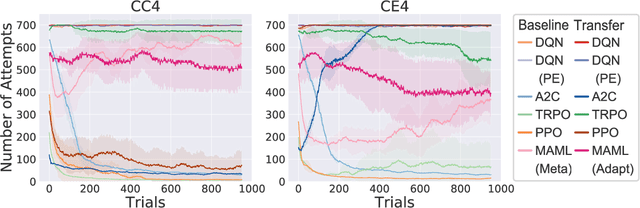
Learning transferable knowledge across similar but different settings is a fundamental component of generalized intelligence. In this paper, we approach the transfer learning challenge from a causal theory perspective. Our agent is endowed with two basic yet general theories for transfer learning: (i) a task shares a common abstract structure that is invariant across domains, and (ii) the behavior of specific features of the environment remain constant across domains. We adopt a Bayesian perspective of causal theory induction and use these theories to transfer knowledge between environments. Given these general theories, the goal is to train an agent by interactively exploring the problem space to (i) discover, form, and transfer useful abstract and structural knowledge, and (ii) induce useful knowledge from the instance-level attributes observed in the environment. A hierarchy of Bayesian structures is used to model abstract-level structural causal knowledge, and an instance-level associative learning scheme learns which specific objects can be used to induce state changes through interaction. This model-learning scheme is then integrated with a model-based planner to achieve a task in the OpenLock environment, a virtual ``escape room'' with a complex hierarchy that requires agents to reason about an abstract, generalized causal structure. We compare performances against a set of predominate model-free reinforcement learning(RL) algorithms. RL agents showed poor ability transferring learned knowledge across different trials. Whereas the proposed model revealed similar performance trends as human learners, and more importantly, demonstrated transfer behavior across trials and learning situations.
DenseRaC: Joint 3D Pose and Shape Estimation by Dense Render-and-Compare
Oct 09, 2019
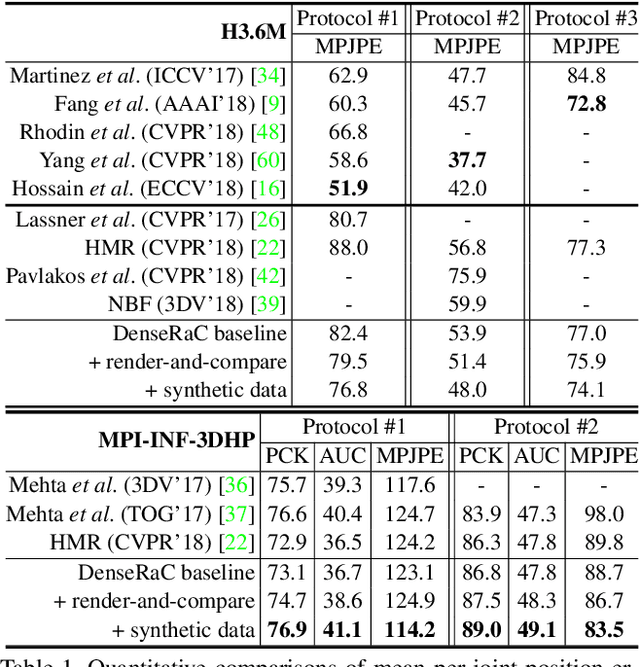
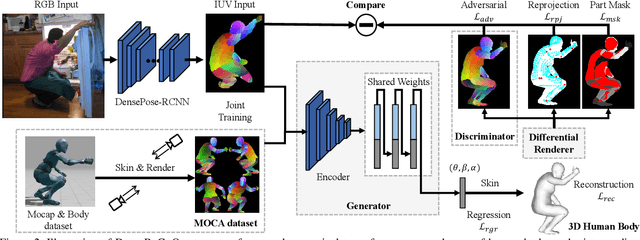
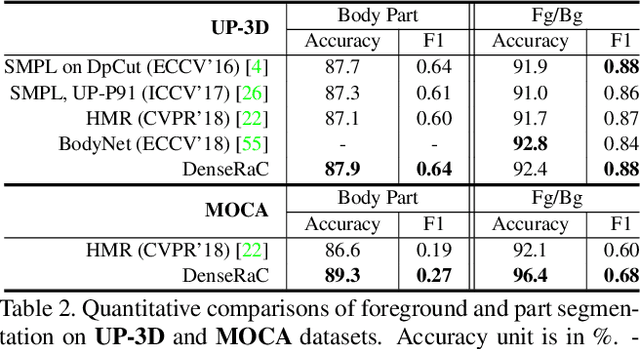
We present DenseRaC, a novel end-to-end framework for jointly estimating 3D human pose and body shape from a monocular RGB image. Our two-step framework takes the body pixel-to-surface correspondence map (i.e., IUV map) as proxy representation and then performs estimation of parameterized human pose and shape. Specifically, given an estimated IUV map, we develop a deep neural network optimizing 3D body reconstruction losses and further integrating a render-and-compare scheme to minimize differences between the input and the rendered output, i.e., dense body landmarks, body part masks, and adversarial priors. To boost learning, we further construct a large-scale synthetic dataset (MOCA) utilizing web-crawled Mocap sequences, 3D scans and animations. The generated data covers diversified camera views, human actions and body shapes, and is paired with full ground truth. Our model jointly learns to represent the 3D human body from hybrid datasets, mitigating the problem of unpaired training data. Our experiments show that DenseRaC obtains superior performance against state of the art on public benchmarks of various humanrelated tasks.
Learning Energy-based Spatial-Temporal Generative ConvNets for Dynamic Patterns
Sep 26, 2019
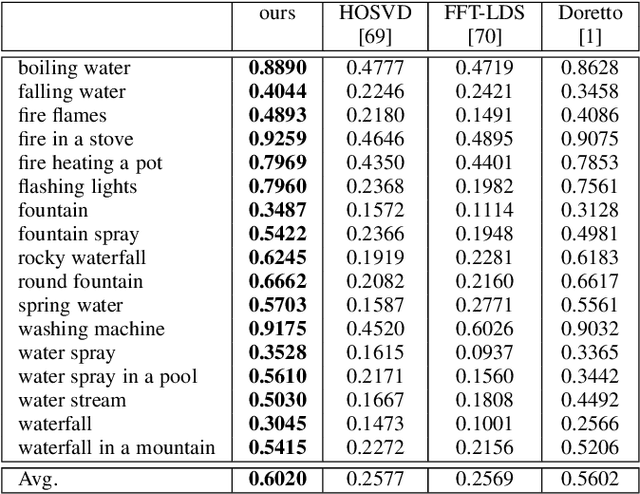

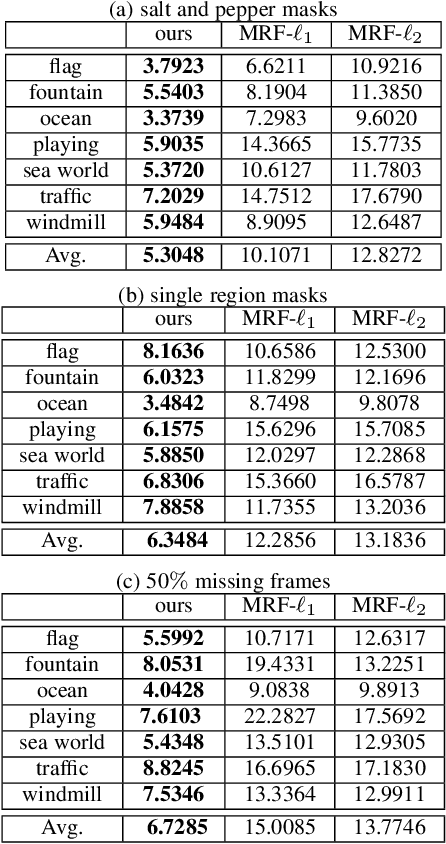
Video sequences contain rich dynamic patterns, such as dynamic texture patterns that exhibit stationarity in the temporal domain, and action patterns that are non-stationary in either spatial or temporal domain. We show that an energy-based spatial-temporal generative ConvNet can be used to model and synthesize dynamic patterns. The model defines a probability distribution on the video sequence, and the log probability is defined by a spatial-temporal ConvNet that consists of multiple layers of spatial-temporal filters to capture spatial-temporal patterns of different scales. The model can be learned from the training video sequences by an "analysis by synthesis" learning algorithm that iterates the following two steps. Step 1 synthesizes video sequences from the currently learned model. Step 2 then updates the model parameters based on the difference between the synthesized video sequences and the observed training sequences. We show that the learning algorithm can synthesize realistic dynamic patterns. We also show that it is possible to learn the model from incomplete training sequences with either occluded pixels or missing frames, so that model learning and pattern completion can be accomplished simultaneously.
X-ToM: Explaining with Theory-of-Mind for Gaining Justified Human Trust
Sep 15, 2019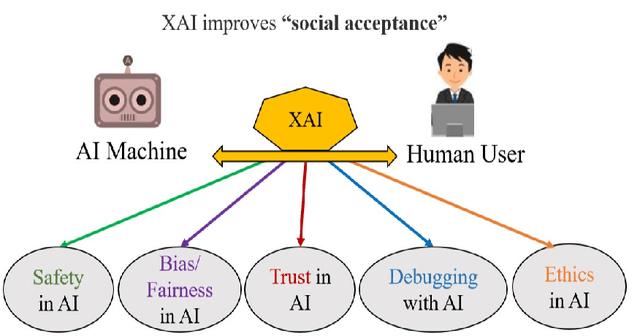

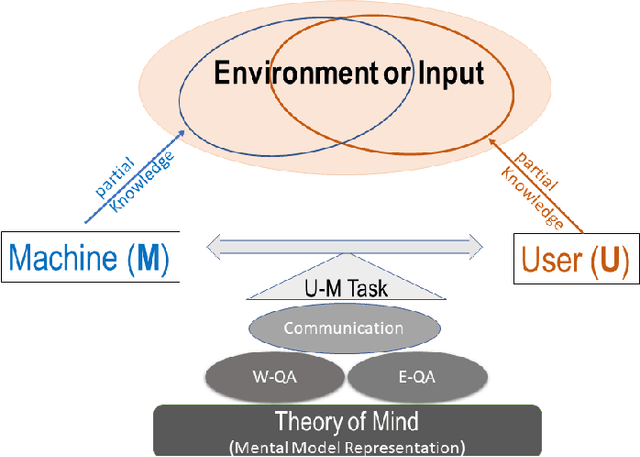
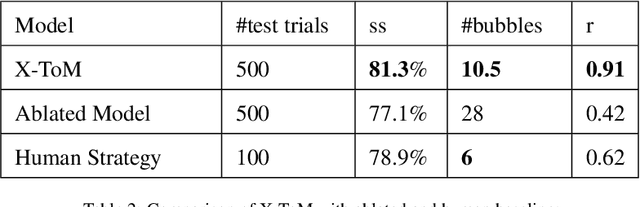
We present a new explainable AI (XAI) framework aimed at increasing justified human trust and reliance in the AI machine through explanations. We pose explanation as an iterative communication process, i.e. dialog, between the machine and human user. More concretely, the machine generates sequence of explanations in a dialog which takes into account three important aspects at each dialog turn: (a) human's intention (or curiosity); (b) human's understanding of the machine; and (c) machine's understanding of the human user. To do this, we use Theory of Mind (ToM) which helps us in explicitly modeling human's intention, machine's mind as inferred by the human as well as human's mind as inferred by the machine. In other words, these explicit mental representations in ToM are incorporated to learn an optimal explanation policy that takes into account human's perception and beliefs. Furthermore, we also show that ToM facilitates in quantitatively measuring justified human trust in the machine by comparing all the three mental representations. We applied our framework to three visual recognition tasks, namely, image classification, action recognition, and human body pose estimation. We argue that our ToM based explanations are practical and more natural for both expert and non-expert users to understand the internal workings of complex machine learning models. To the best of our knowledge, this is the first work to derive explanations using ToM. Extensive human study experiments verify our hypotheses, showing that the proposed explanations significantly outperform the state-of-the-art XAI methods in terms of all the standard quantitative and qualitative XAI evaluation metrics including human trust, reliance, and explanation satisfaction.
Towards Interpretable Image Synthesis by Learning Sparsely Connected AND-OR Networks
Sep 10, 2019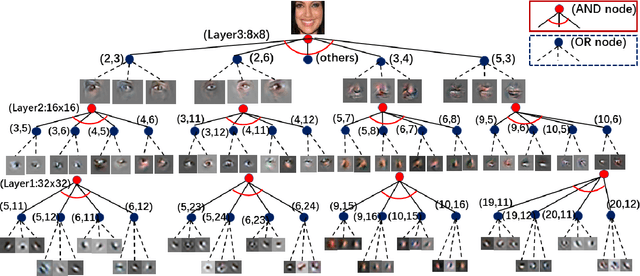

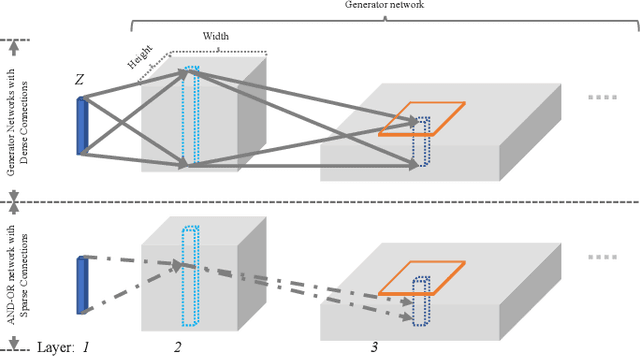

This paper proposes interpretable image synthesis by learning hierarchical AND-OR networks of sparsely connected semantically meaningful nodes. The proposed method is based on the compositionality and interpretability of scene-objects-parts-subparts-primitives hierarchy in image representation. A scene has different types (i.e., OR) each of which consists of a number of objects (i.e., AND). This can be recursively formulated across the scene-objects-parts-subparts hierarchy and is terminated at the primitive level (e.g., Gabor wavelets-like basis). To realize this interpretable AND-OR hierarchy in image synthesis, the proposed method consists of two components: (i) Each layer of the hierarchy is represented by an over-completed set of basis functions. The basis functions are instantiated using convolution to be translation covariant. Off-the-shelf convolutional neural architectures are then exploited to implement the hierarchy. (ii) Sparsity-inducing constraints are introduced in end-to-end training, which facilitate a sparsely connected AND-OR network to emerge from initially densely connected convolutional neural networks. A straightforward sparsity-inducing constraint is utilized, that is to only allow the top-$k$ basis functions to be active at each layer (where $k$ is a hyperparameter). The learned basis functions are also capable of image reconstruction to explain away input images. In experiments, the proposed method is tested on five benchmark datasets. The results show that meaningful and interpretable hierarchical representations are learned with better qualities of image synthesis and reconstruction obtained than state-of-the-art baselines.
Understanding Human Gaze Communication by Spatio-Temporal Graph Reasoning
Sep 04, 2019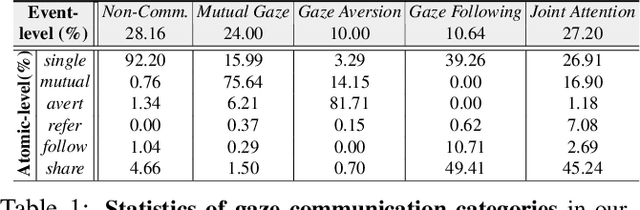

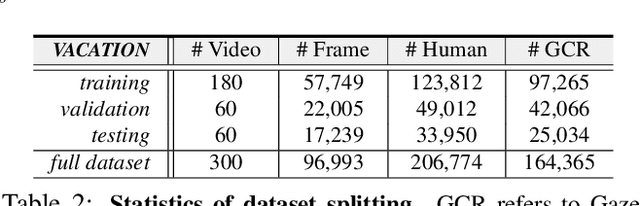
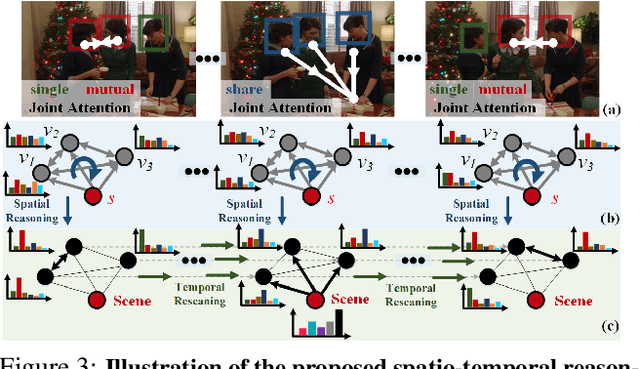
This paper addresses a new problem of understanding human gaze communication in social videos from both atomic-level and event-level, which is significant for studying human social interactions. To tackle this novel and challenging problem, we contribute a large-scale video dataset, VACATION, which covers diverse daily social scenes and gaze communication behaviors with complete annotations of objects and human faces, human attention, and communication structures and labels in both atomic-level and event-level. Together with VACATION, we propose a spatio-temporal graph neural network to explicitly represent the diverse gaze interactions in the social scenes and to infer atomic-level gaze communication by message passing. We further propose an event network with encoder-decoder structure to predict the event-level gaze communication. Our experiments demonstrate that the proposed model improves various baselines significantly in predicting the atomic-level and event-level gaze
Holistic++ Scene Understanding: Single-view 3D Holistic Scene Parsing and Human Pose Estimation with Human-Object Interaction and Physical Commonsense
Sep 04, 2019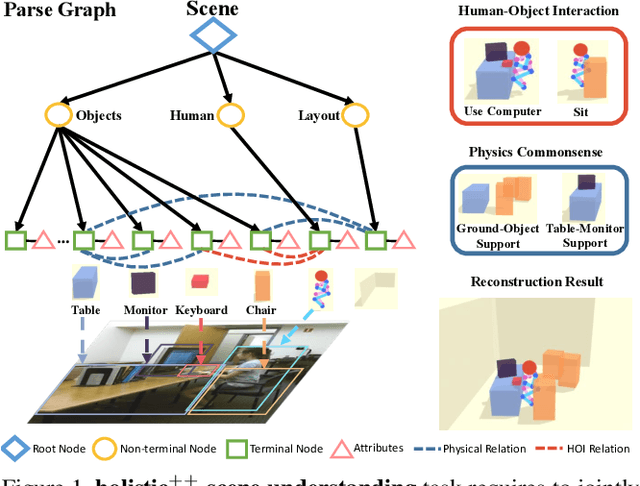
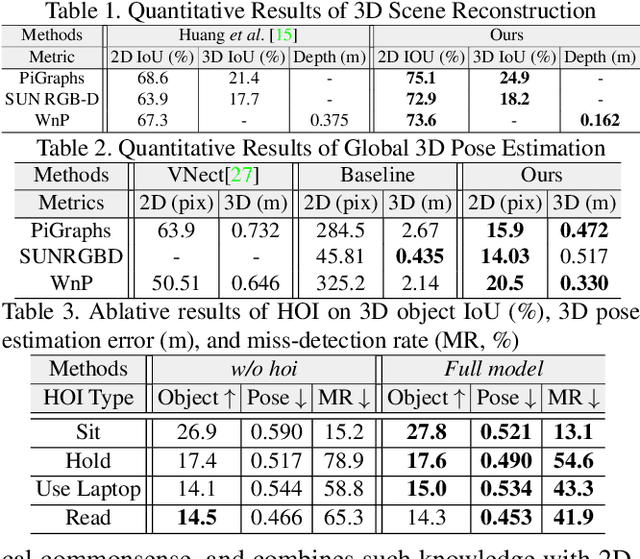
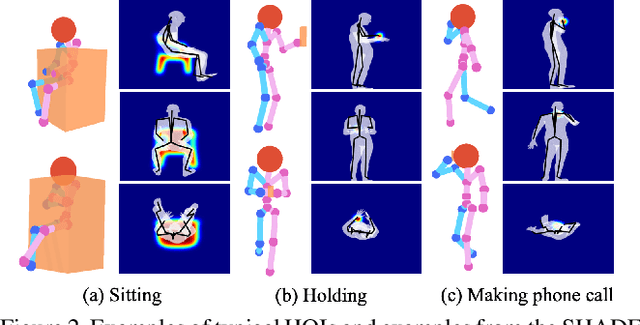

We propose a new 3D holistic++ scene understanding problem, which jointly tackles two tasks from a single-view image: (i) holistic scene parsing and reconstruction---3D estimations of object bounding boxes, camera pose, and room layout, and (ii) 3D human pose estimation. The intuition behind is to leverage the coupled nature of these two tasks to improve the granularity and performance of scene understanding. We propose to exploit two critical and essential connections between these two tasks: (i) human-object interaction (HOI) to model the fine-grained relations between agents and objects in the scene, and (ii) physical commonsense to model the physical plausibility of the reconstructed scene. The optimal configuration of the 3D scene, represented by a parse graph, is inferred using Markov chain Monte Carlo (MCMC), which efficiently traverses through the non-differentiable joint solution space. Experimental results demonstrate that the proposed algorithm significantly improves the performance of the two tasks on three datasets, showing an improved generalization ability.
HUGE2: a Highly Untangled Generative-model Engine for Edge-computing
Jul 25, 2019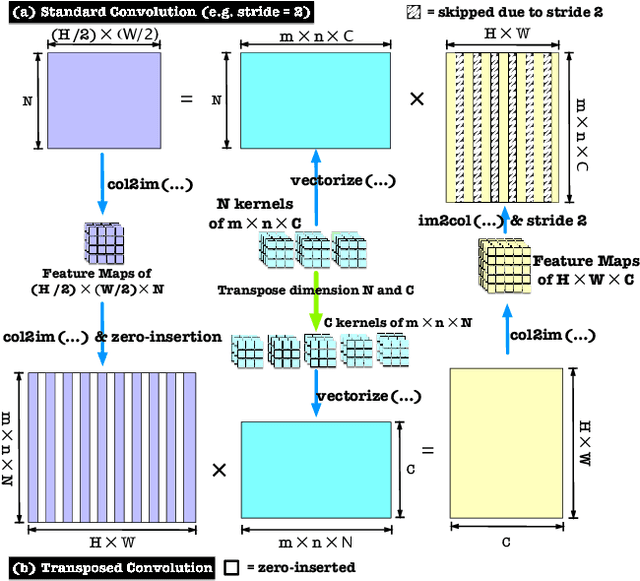
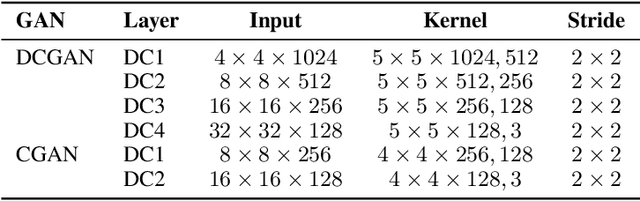

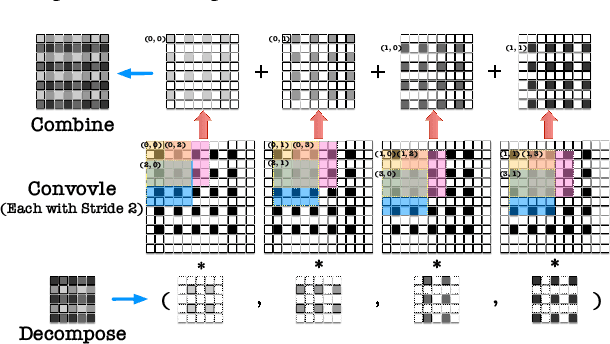
As a type of prominent studies in deep learning, generative models have been widely investigated in research recently. Two research branches of the deep learning models, the Generative Networks (GANs, VAE) and the Semantic Segmentation, rely highly on the upsampling operations, especially the transposed convolution and the dilated convolution. However, these two types of convolutions are intrinsically different from standard convolution regarding the insertion of zeros in input feature maps or in kernels respectively. This distinct nature severely degrades the performance of the existing deep learning engine or frameworks, such as Darknet, Tensorflow, and PyTorch, which are mainly developed for the standard convolution. Another trend in deep learning realm is to deploy the model onto edge/ embedded devices, in which the memory resource is scarce. In this work, we propose a Highly Untangled Generative-model Engine for Edge-computing or HUGE2 for accelerating these two special convolutions on the edge-computing platform by decomposing the kernels and untangling these smaller convolutions by performing basic matrix multiplications. The methods we propose use much smaller memory footprint, hence much fewer memory accesses, and the data access patterns also dramatically increase the reusability of the data already fetched in caches, hence increasing the localities of caches. Our engine achieves a speedup of nearly 5x on embedded CPUs, and around 10x on embedded GPUs, and more than 50% reduction of memory access.
Reasoning Visual Dialogs with Structural and Partial Observations
May 28, 2019
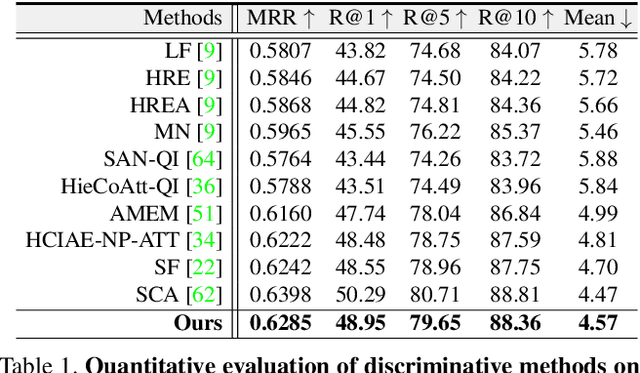
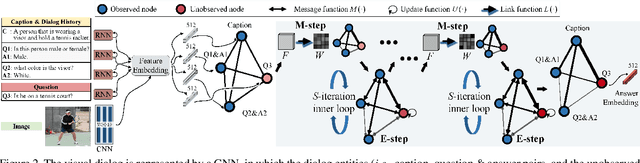
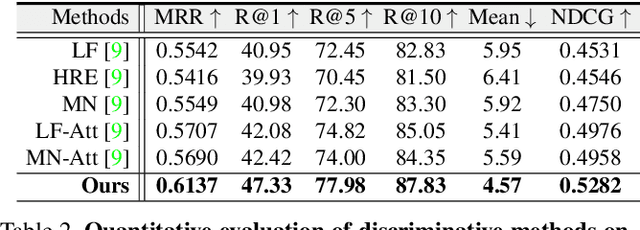
We propose a novel model to address the task of Visual Dialog which exhibits complex dialog structures. To obtain a reasonable answer based on the current question and the dialog history, the underlying semantic dependencies between dialog entities are essential. In this paper, we explicitly formalize this task as inference in a graphical model with partially observed nodes and unknown graph structures (relations in dialog). The given dialog entities are viewed as the observed nodes. The answer to a given question is represented by a node with missing value. We first introduce an Expectation Maximization algorithm to infer both the underlying dialog structures and the missing node values (desired answers). Based on this, we proceed to propose a differentiable graph neural network (GNN) solution that approximates this process. Experiment results on the VisDial and VisDial-Q datasets show that our model outperforms comparative methods. It is also observed that our method can infer the underlying dialog structure for better dialog reasoning.