 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVARS: Video Assistant Referee System for Automated Soccer Decision Making from Multiple Views
Apr 10, 2023The Video Assistant Referee (VAR) has revolutionized association football, enabling referees to review incidents on the pitch, make informed decisions, and ensure fairness. However, due to the lack of referees in many countries and the high cost of the VAR infrastructure, only professional leagues can benefit from it. In this paper, we propose a Video Assistant Referee System (VARS) that can automate soccer decision-making. VARS leverages the latest findings in multi-view video analysis, to provide real-time feedback to the referee, and help them make informed decisions that can impact the outcome of a game. To validate VARS, we introduce SoccerNet-MVFoul, a novel video dataset of soccer fouls from multiple camera views, annotated with extensive foul descriptions by a professional soccer referee, and we benchmark our VARS to automatically recognize the characteristics of these fouls. We believe that VARS has the potential to revolutionize soccer refereeing and take the game to new heights of fairness and accuracy across all levels of professional and amateur federations.
SoccerNet-Caption: Dense Video Captioning for Soccer Broadcasts Commentaries
Apr 10, 2023



Soccer is more than just a game - it is a passion that transcends borders and unites people worldwide. From the roar of the crowds to the excitement of the commentators, every moment of a soccer match is a thrill. Yet, with so many games happening simultaneously, fans cannot watch them all live. Notifications for main actions can help, but lack the engagement of live commentary, leaving fans feeling disconnected. To fulfill this need, we propose in this paper a novel task of dense video captioning focusing on the generation of textual commentaries anchored with single timestamps. To support this task, we additionally present a challenging dataset consisting of almost 37k timestamped commentaries across 715.9 hours of soccer broadcast videos. Additionally, we propose a first benchmark and baseline for this task, highlighting the difficulty of temporally anchoring commentaries yet showing the capacity to generate meaningful commentaries. By providing broadcasters with a tool to summarize the content of their video with the same level of engagement as a live game, our method could help satisfy the needs of the numerous fans who follow their team but cannot necessarily watch the live game. We believe our method has the potential to enhance the accessibility and understanding of soccer content for a wider audience, bringing the excitement of the game to more people.
Towards Active Learning for Action Spotting in Association Football Videos
Apr 09, 2023



Association football is a complex and dynamic sport, with numerous actions occurring simultaneously in each game. Analyzing football videos is challenging and requires identifying subtle and diverse spatio-temporal patterns. Despite recent advances in computer vision, current algorithms still face significant challenges when learning from limited annotated data, lowering their performance in detecting these patterns. In this paper, we propose an active learning framework that selects the most informative video samples to be annotated next, thus drastically reducing the annotation effort and accelerating the training of action spotting models to reach the highest accuracy at a faster pace. Our approach leverages the notion of uncertainty sampling to select the most challenging video clips to train on next, hastening the learning process of the algorithm. We demonstrate that our proposed active learning framework effectively reduces the required training data for accurate action spotting in football videos. We achieve similar performances for action spotting with NetVLAD++ on SoccerNet-v2, using only one-third of the dataset, indicating significant capabilities for reducing annotation time and improving data efficiency. We further validate our approach on two new datasets that focus on temporally localizing actions of headers and passes, proving its effectiveness across different action semantics in football. We believe our active learning framework for action spotting would support further applications of action spotting algorithms and accelerate annotation campaigns in the sports domain.
MVTN: Learning Multi-View Transformations for 3D Understanding
Dec 27, 2022



Multi-view projection techniques have shown themselves to be highly effective in achieving top-performing results in the recognition of 3D shapes. These methods involve learning how to combine information from multiple view-points. However, the camera view-points from which these views are obtained are often fixed for all shapes. To overcome the static nature of current multi-view techniques, we propose learning these view-points. Specifically, we introduce the Multi-View Transformation Network (MVTN), which uses differentiable rendering to determine optimal view-points for 3D shape recognition. As a result, MVTN can be trained end-to-end with any multi-view network for 3D shape classification. We integrate MVTN into a novel adaptive multi-view pipeline that is capable of rendering both 3D meshes and point clouds. Our approach demonstrates state-of-the-art performance in 3D classification and shape retrieval on several benchmarks (ModelNet40, ScanObjectNN, ShapeNet Core55). Further analysis indicates that our approach exhibits improved robustness to occlusion compared to other methods. We also investigate additional aspects of MVTN, such as 2D pretraining and its use for segmentation. To support further research in this area, we have released MVTorch, a PyTorch library for 3D understanding and generation using multi-view projections.
Localizing Objects in 3D from Egocentric Videos with Visual Queries
Dec 14, 2022



With the recent advances in video and 3D understanding, novel 4D spatio-temporal challenges fusing both concepts have emerged. Towards this direction, the Ego4D Episodic Memory Benchmark proposed a task for Visual Queries with 3D Localization (VQ3D). Given an egocentric video clip and an image crop depicting a query object, the goal is to localize the 3D position of the center of that query object with respect to the camera pose of a query frame. Current methods tackle the problem of VQ3D by lifting the 2D localization results of the sister task Visual Queries with 2D Localization (VQ2D) into a 3D reconstruction. Yet, we point out that the low number of Queries with Poses (QwP) from previous VQ3D methods severally hinders their overall success rate and highlights the need for further effort in 3D modeling to tackle the VQ3D task. In this work, we formalize a pipeline that better entangles 3D multiview geometry with 2D object retrieval from egocentric videos. We estimate more robust camera poses, leading to more successful object queries and substantially improved VQ3D performance. In practice, our method reaches a top-1 overall success rate of 86.36% on the Ego4D Episodic Memory Benchmark VQ3D, a 10x improvement over the previous state-of-the-art. In addition, we provide a complete empirical study highlighting the remaining challenges in VQ3D.
SegNeRF: 3D Part Segmentation with Neural Radiance Fields
Nov 22, 2022



Recent advances in Neural Radiance Fields (NeRF) boast impressive performances for generative tasks such as novel view synthesis and 3D reconstruction. Methods based on neural radiance fields are able to represent the 3D world implicitly by relying exclusively on posed images. Yet, they have seldom been explored in the realm of discriminative tasks such as 3D part segmentation. In this work, we attempt to bridge that gap by proposing SegNeRF: a neural field representation that integrates a semantic field along with the usual radiance field. SegNeRF inherits from previous works the ability to perform novel view synthesis and 3D reconstruction, and enables 3D part segmentation from a few images. Our extensive experiments on PartNet show that SegNeRF is capable of simultaneously predicting geometry, appearance, and semantic information from posed images, even for unseen objects. The predicted semantic fields allow SegNeRF to achieve an average mIoU of $\textbf{30.30%}$ for 2D novel view segmentation, and $\textbf{37.46%}$ for 3D part segmentation, boasting competitive performance against point-based methods by using only a few posed images. Additionally, SegNeRF is able to generate an explicit 3D model from a single image of an object taken in the wild, with its corresponding part segmentation.
Estimating more camera poses for ego-centric videos is essential for VQ3D
Nov 18, 2022Visual queries 3D localization (VQ3D) is a task in the Ego4D Episodic Memory Benchmark. Given an egocentric video, the goal is to answer queries of the form "Where did I last see object X?", where the query object X is specified as a static image, and the answer should be a 3D displacement vector pointing to object X. However, current techniques use naive ways to estimate the camera poses of video frames, resulting in a low query with pose (QwP) ratio, thus a poor overall success rate. We design a new pipeline for the challenging egocentric video camera pose estimation problem in our work. Moreover, we revisit the current VQ3D framework and optimize it in terms of performance and efficiency. As a result, we get the top-1 overall success rate of 25.8% on VQ3D leaderboard, which is two times better than the 8.7% reported by the baseline.
SoccerNet 2022 Challenges Results
Oct 05, 2022
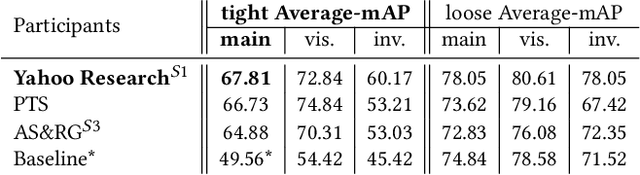
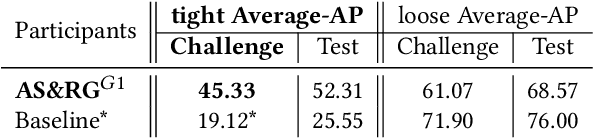
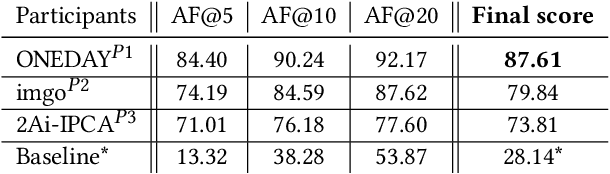
The SoccerNet 2022 challenges were the second annual video understanding challenges organized by the SoccerNet team. In 2022, the challenges were composed of 6 vision-based tasks: (1) action spotting, focusing on retrieving action timestamps in long untrimmed videos, (2) replay grounding, focusing on retrieving the live moment of an action shown in a replay, (3) pitch localization, focusing on detecting line and goal part elements, (4) camera calibration, dedicated to retrieving the intrinsic and extrinsic camera parameters, (5) player re-identification, focusing on retrieving the same players across multiple views, and (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams. Compared to last year's challenges, tasks (1-2) had their evaluation metrics redefined to consider tighter temporal accuracies, and tasks (3-6) were novel, including their underlying data and annotations. More information on the tasks, challenges and leaderboards are available on https://www.soccer-net.org. Baselines and development kits are available on https://github.com/SoccerNet.
SoccerNet-Tracking: Multiple Object Tracking Dataset and Benchmark in Soccer Videos
Apr 20, 2022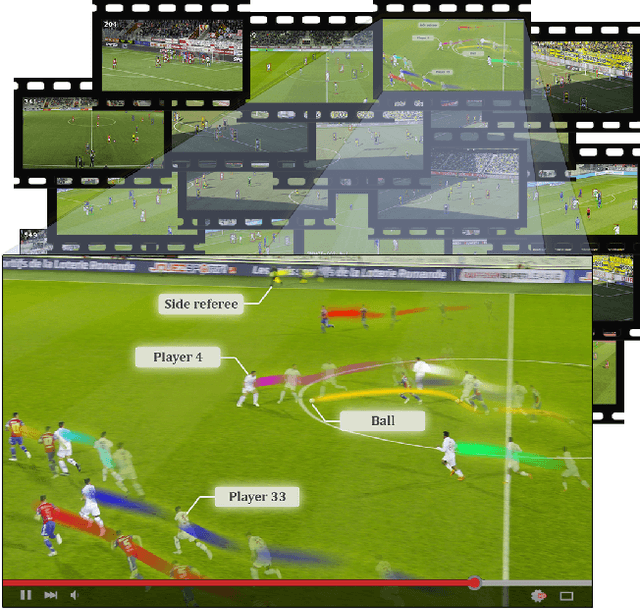
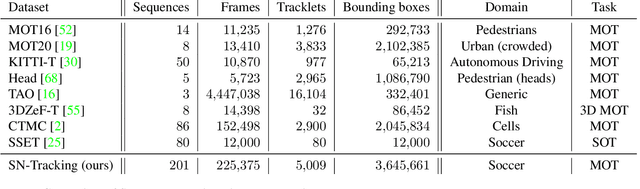
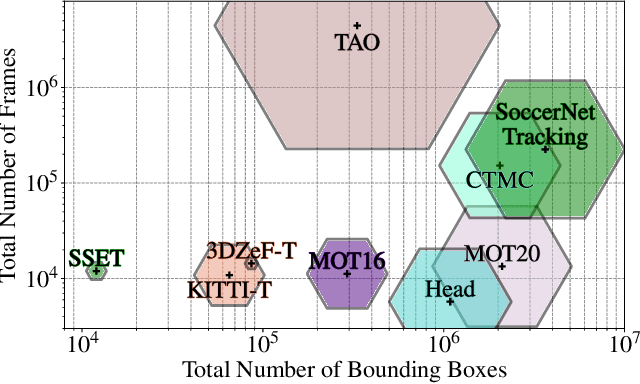
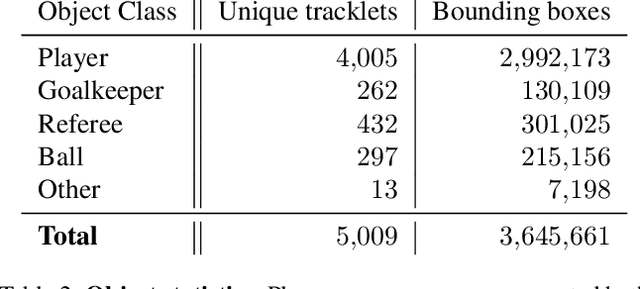
Tracking objects in soccer videos is extremely important to gather both player and team statistics, whether it is to estimate the total distance run, the ball possession or the team formation. Video processing can help automating the extraction of those information, without the need of any invasive sensor, hence applicable to any team on any stadium. Yet, the availability of datasets to train learnable models and benchmarks to evaluate methods on a common testbed is very limited. In this work, we propose a novel dataset for multiple object tracking composed of 200 sequences of 30s each, representative of challenging soccer scenarios, and a complete 45-minutes half-time for long-term tracking. The dataset is fully annotated with bounding boxes and tracklet IDs, enabling the training of MOT baselines in the soccer domain and a full benchmarking of those methods on our segregated challenge sets. Our analysis shows that multiple player, referee and ball tracking in soccer videos is far from being solved, with several improvement required in case of fast motion or in scenarios of severe occlusion.
3DeformRS: Certifying Spatial Deformations on Point Clouds
Apr 12, 2022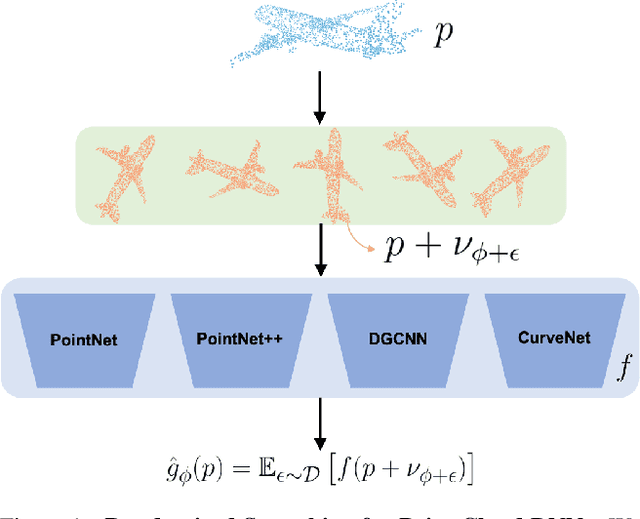



3D computer vision models are commonly used in security-critical applications such as autonomous driving and surgical robotics. Emerging concerns over the robustness of these models against real-world deformations must be addressed practically and reliably. In this work, we propose 3DeformRS, a method to certify the robustness of point cloud Deep Neural Networks (DNNs) against real-world deformations. We developed 3DeformRS by building upon recent work that generalized Randomized Smoothing (RS) from pixel-intensity perturbations to vector-field deformations. In particular, we specialized RS to certify DNNs against parameterized deformations (e.g. rotation, twisting), while enjoying practical computational costs. We leverage the virtues of 3DeformRS to conduct a comprehensive empirical study on the certified robustness of four representative point cloud DNNs on two datasets and against seven different deformations. Compared to previous approaches for certifying point cloud DNNs, 3DeformRS is fast, scales well with point cloud size, and provides comparable-to-better certificates. For instance, when certifying a plain PointNet against a 3{\deg} z-rotation on 1024-point clouds, 3DeformRS grants a certificate 3x larger and 20x faster than previous work.