 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearchable Hidden Intermediates for End-to-End Models of Decomposable Sequence Tasks
May 02, 2021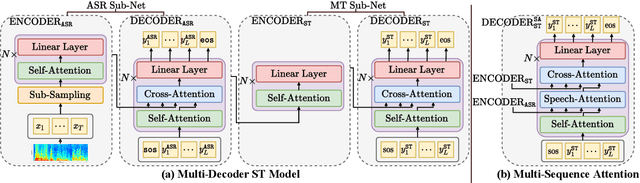
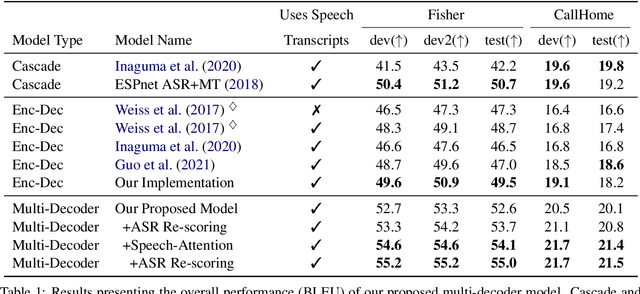
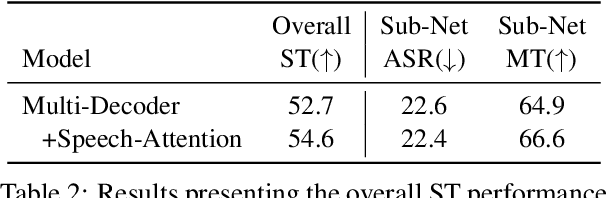
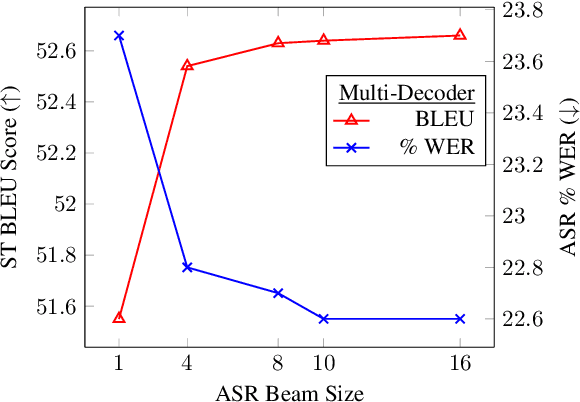
End-to-end approaches for sequence tasks are becoming increasingly popular. Yet for complex sequence tasks, like speech translation, systems that cascade several models trained on sub-tasks have shown to be superior, suggesting that the compositionality of cascaded systems simplifies learning and enables sophisticated search capabilities. In this work, we present an end-to-end framework that exploits compositionality to learn searchable hidden representations at intermediate stages of a sequence model using decomposed sub-tasks. These hidden intermediates can be improved using beam search to enhance the overall performance and can also incorporate external models at intermediate stages of the network to re-score or adapt towards out-of-domain data. One instance of the proposed framework is a Multi-Decoder model for speech translation that extracts the searchable hidden intermediates from a speech recognition sub-task. The model demonstrates the aforementioned benefits and outperforms the previous state-of-the-art by around +6 and +3 BLEU on the two test sets of Fisher-CallHome and by around +3 and +4 BLEU on the English-German and English-French test sets of MuST-C.
NoiseQA: Challenge Set Evaluation for User-Centric Question Answering
Feb 16, 2021
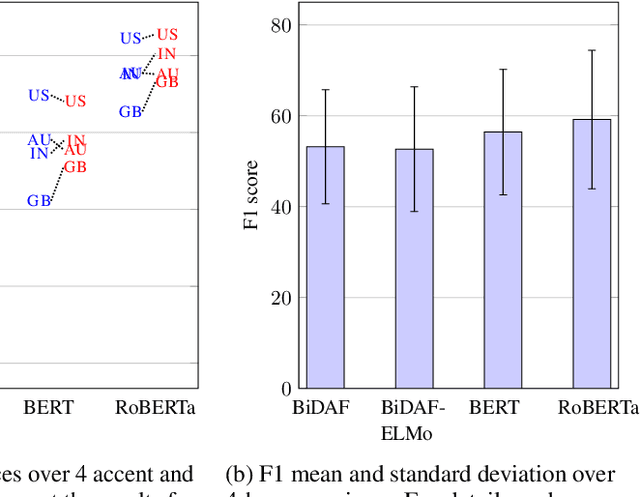

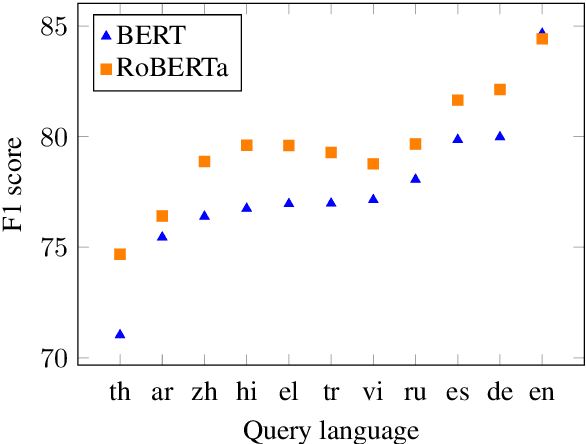
When Question-Answering (QA) systems are deployed in the real world, users query them through a variety of interfaces, such as speaking to voice assistants, typing questions into a search engine, or even translating questions to languages supported by the QA system. While there has been significant community attention devoted to identifying correct answers in passages assuming a perfectly formed question, we show that components in the pipeline that precede an answering engine can introduce varied and considerable sources of error, and performance can degrade substantially based on these upstream noise sources even for powerful pre-trained QA models. We conclude that there is substantial room for progress before QA systems can be effectively deployed, highlight the need for QA evaluation to expand to consider real-world use, and hope that our findings will spur greater community interest in the issues that arise when our systems actually need to be of utility to humans.
Transformer-Transducers for Code-Switched Speech Recognition
Nov 30, 2020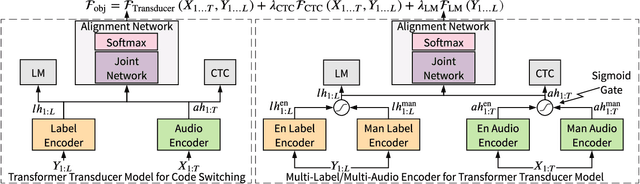
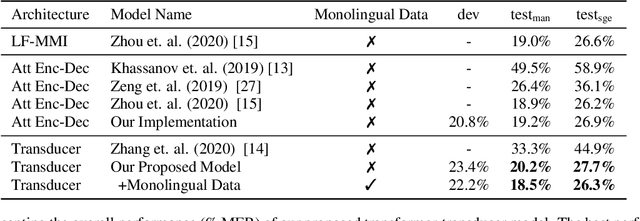


We live in a world where 60% of the population can speak two or more languages fluently. Members of these communities constantly switch between languages when having a conversation. As automatic speech recognition (ASR) systems are being deployed to the real-world, there is a need for practical systems that can handle multiple languages both within an utterance or across utterances. In this paper, we present an end-to-end ASR system using a transformer-transducer model architecture for code-switched speech recognition. We propose three modifications over the vanilla model in order to handle various aspects of code-switching. First, we introduce two auxiliary loss functions to handle the low-resource scenario of code-switching. Second, we propose a novel mask-based training strategy with language ID information to improve the label encoder training towards intra-sentential code-switching. Finally, we propose a multi-label/multi-audio encoder structure to leverage the vast monolingual speech corpora towards code-switching. We demonstrate the efficacy of our proposed approaches on the SEAME dataset, a public Mandarin-English code-switching corpus, achieving a mixed error rate of 18.5% and 26.3% on test_man and test_sge sets respectively.
On Long-Tailed Phenomena in Neural Machine Translation
Oct 10, 2020
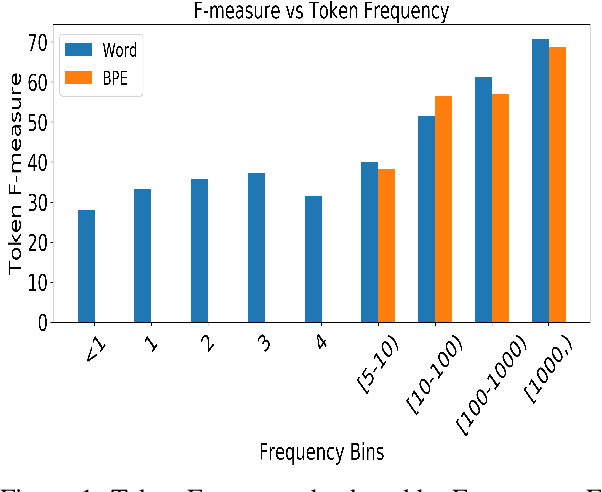
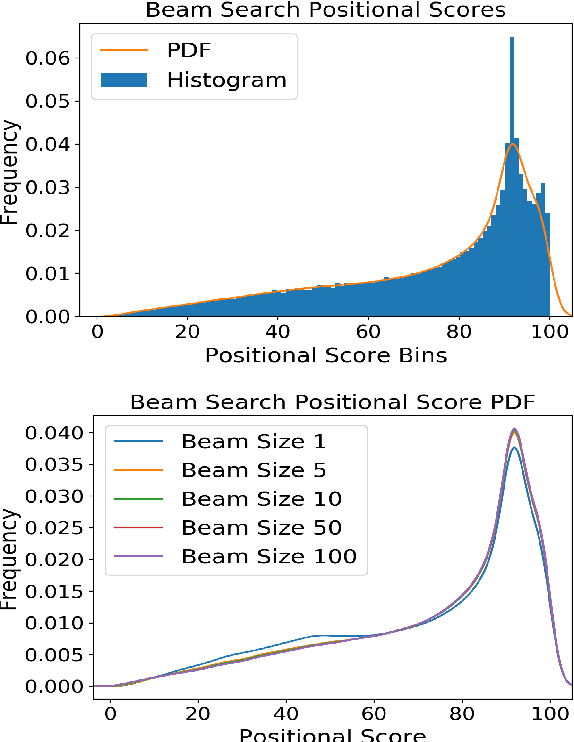
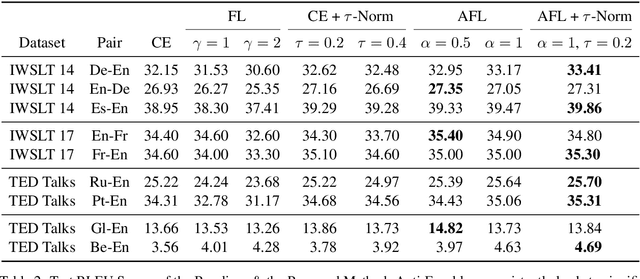
State-of-the-art Neural Machine Translation (NMT) models struggle with generating low-frequency tokens, tackling which remains a major challenge. The analysis of long-tailed phenomena in the context of structured prediction tasks is further hindered by the added complexities of search during inference. In this work, we quantitatively characterize such long-tailed phenomena at two levels of abstraction, namely, token classification and sequence generation. We propose a new loss function, the Anti-Focal loss, to better adapt model training to the structural dependencies of conditional text generation by incorporating the inductive biases of beam search in the training process. We show the efficacy of the proposed technique on a number of Machine Translation (MT) datasets, demonstrating that it leads to significant gains over cross-entropy across different language pairs, especially on the generation of low-frequency words. We have released the code to reproduce our results.
Universal Phone Recognition with a Multilingual Allophone System
Feb 26, 2020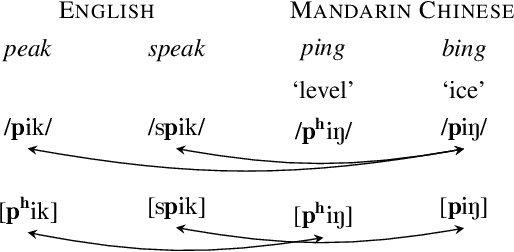

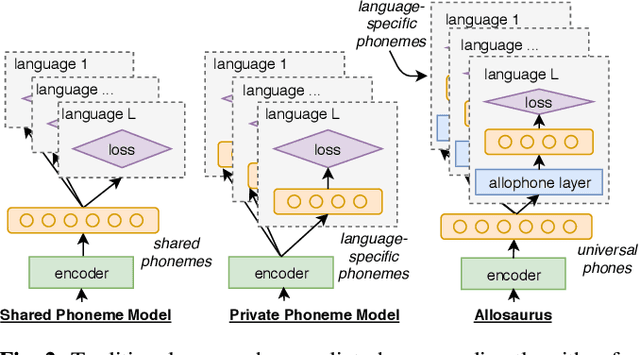

Multilingual models can improve language processing, particularly for low resource situations, by sharing parameters across languages. Multilingual acoustic models, however, generally ignore the difference between phonemes (sounds that can support lexical contrasts in a particular language) and their corresponding phones (the sounds that are actually spoken, which are language independent). This can lead to performance degradation when combining a variety of training languages, as identically annotated phonemes can actually correspond to several different underlying phonetic realizations. In this work, we propose a joint model of both language-independent phone and language-dependent phoneme distributions. In multilingual ASR experiments over 11 languages, we find that this model improves testing performance by 2% phoneme error rate absolute in low-resource conditions. Additionally, because we are explicitly modeling language-independent phones, we can build a (nearly-)universal phone recognizer that, when combined with the PHOIBLE large, manually curated database of phone inventories, can be customized into 2,000 language dependent recognizers. Experiments on two low-resourced indigenous languages, Inuktitut and Tusom, show that our recognizer achieves phone accuracy improvements of more than 17%, moving a step closer to speech recognition for all languages in the world.
Towards Zero-shot Learning for Automatic Phonemic Transcription
Feb 26, 2020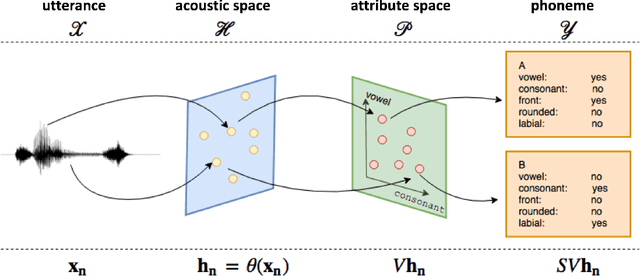
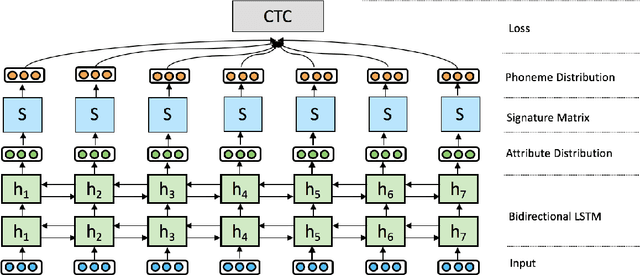
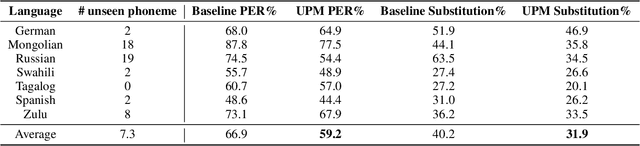
Automatic phonemic transcription tools are useful for low-resource language documentation. However, due to the lack of training sets, only a tiny fraction of languages have phonemic transcription tools. Fortunately, multilingual acoustic modeling provides a solution given limited audio training data. A more challenging problem is to build phonemic transcribers for languages with zero training data. The difficulty of this task is that phoneme inventories often differ between the training languages and the target language, making it infeasible to recognize unseen phonemes. In this work, we address this problem by adopting the idea of zero-shot learning. Our model is able to recognize unseen phonemes in the target language without any training data. In our model, we decompose phonemes into corresponding articulatory attributes such as vowel and consonant. Instead of predicting phonemes directly, we first predict distributions over articulatory attributes, and then compute phoneme distributions with a customized acoustic model. We evaluate our model by training it using 13 languages and testing it using 7 unseen languages. We find that it achieves 7.7% better phoneme error rate on average over a standard multilingual model.
Enforcing Encoder-Decoder Modularity in Sequence-to-Sequence Models
Nov 09, 2019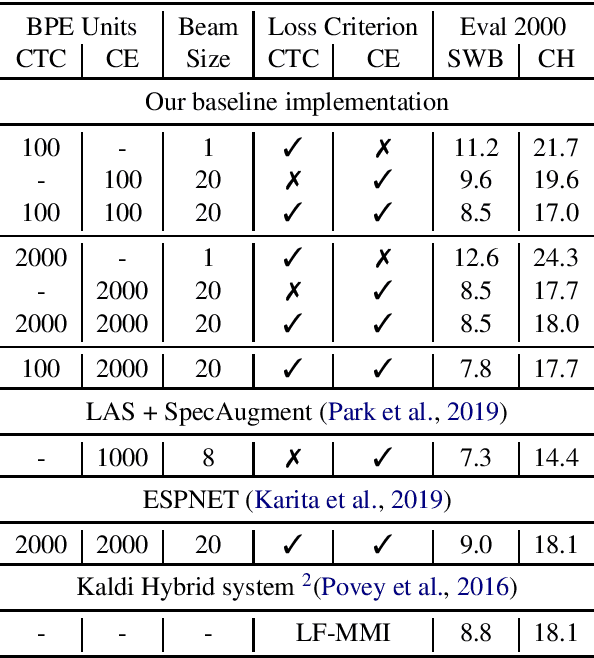
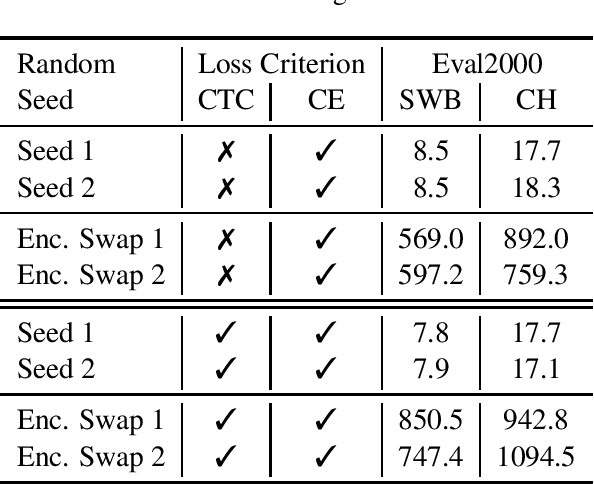
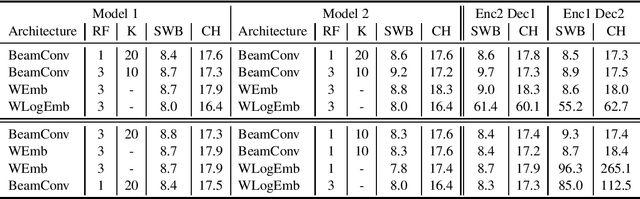
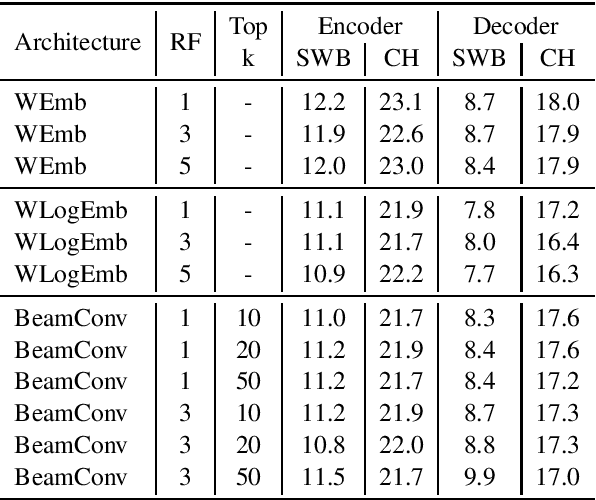
Inspired by modular software design principles of independence, interchangeability, and clarity of interface, we introduce a method for enforcing encoder-decoder modularity in seq2seq models without sacrificing the overall model quality or its full differentiability. We discretize the encoder output units into a predefined interpretable vocabulary space using the Connectionist Temporal Classification (CTC) loss. Our modular systems achieve near SOTA performance on the 300h Switchboard benchmark, with WER of 8.3% and 17.6% on the SWB and CH subsets, using seq2seq models with encoder and decoder modules which are independent and interchangeable.
SANTLR: Speech Annotation Toolkit for Low Resource Languages
Aug 02, 2019
While low resource speech recognition has attracted a lot of attention from the speech community, there are a few tools available to facilitate low resource speech collection. In this work, we present SANTLR: Speech Annotation Toolkit for Low Resource Languages. It is a web-based toolkit which allows researchers to easily collect and annotate a corpus of speech in a low resource language. Annotators may use this toolkit for two purposes: transcription or recording. In transcription, annotators would transcribe audio files provided by the researchers; in recording, annotators would record their voice by reading provided texts. We highlight two properties of this toolkit. First, SANTLR has a very user-friendly User Interface (UI). Both researchers and annotators may use this simple web interface to interact. There is no requirement for the annotators to have any expertise in audio or text processing. The toolkit would handle all preprocessing and postprocessing steps. Second, we employ a multi-step ranking mechanism facilitate the annotation process. In particular, the toolkit would give higher priority to utterances which are easier to annotate and are more beneficial to achieving the goal of the annotation, e.g. quickly training an acoustic model.
Multilingual Speech Recognition with Corpus Relatedness Sampling
Aug 02, 2019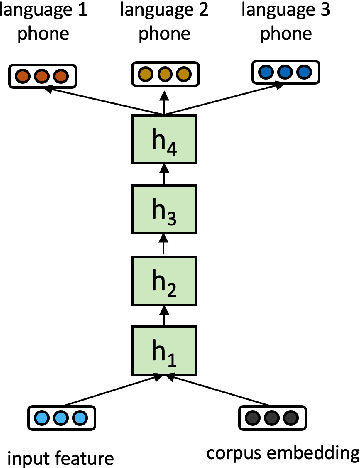
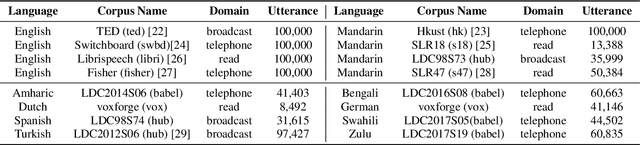
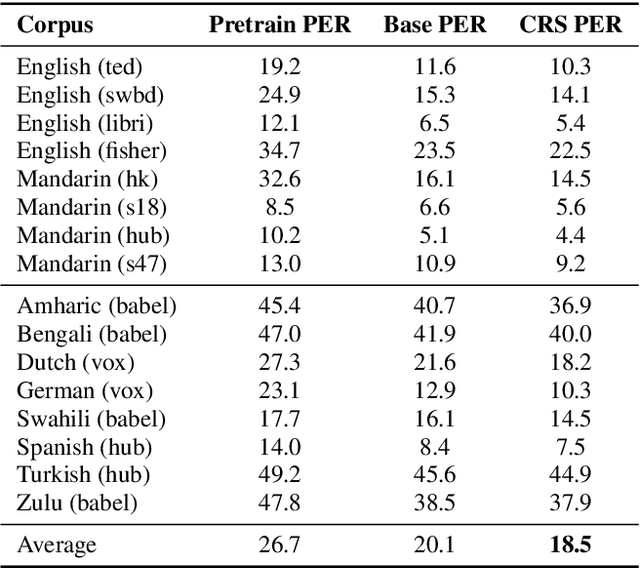
Multilingual acoustic models have been successfully applied to low-resource speech recognition. Most existing works have combined many small corpora together and pretrained a multilingual model by sampling from each corpus uniformly. The model is eventually fine-tuned on each target corpus. This approach, however, fails to exploit the relatedness and similarity among corpora in the training set. For example, the target corpus might benefit more from a corpus in the same domain or a corpus from a close language. In this work, we propose a simple but useful sampling strategy to take advantage of this relatedness. We first compute the corpus-level embeddings and estimate the similarity between each corpus. Next, we start training the multilingual model with uniform-sampling from each corpus at first, then we gradually increase the probability to sample from related corpora based on its similarity with the target corpus. Finally, the model would be fine-tuned automatically on the target corpus. Our sampling strategy outperforms the baseline multilingual model on 16 low-resource tasks. Additionally, we demonstrate that our corpus embeddings capture the language and domain information of each corpus.
Cross-Attention End-to-End ASR for Two-Party Conversations
Jul 24, 2019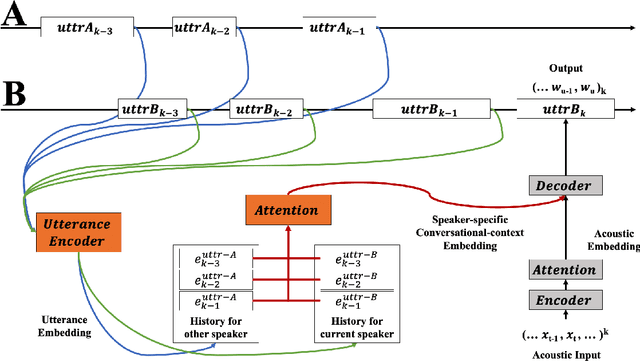
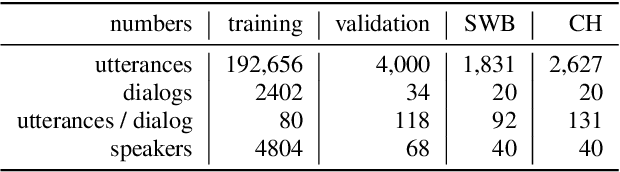
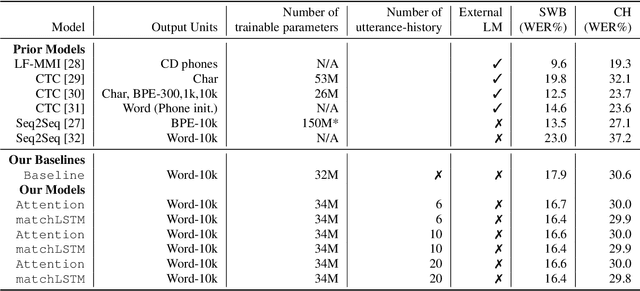
We present an end-to-end speech recognition model that learns interaction between two speakers based on the turn-changing information. Unlike conventional speech recognition models, our model exploits two speakers' history of conversational-context information that spans across multiple turns within an end-to-end framework. Specifically, we propose a speaker-specific cross-attention mechanism that can look at the output of the other speaker side as well as the one of the current speaker for better at recognizing long conversations. We evaluated the models on the Switchboard conversational speech corpus and show that our model outperforms standard end-to-end speech recognition models.