 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrowd Counting via Hierarchical Scale Recalibration Network
Mar 07, 2020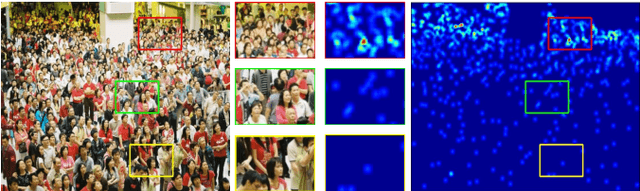
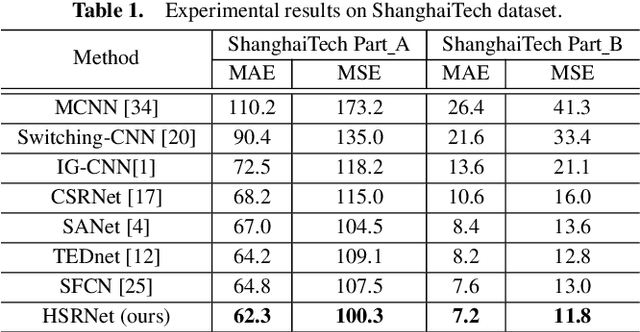
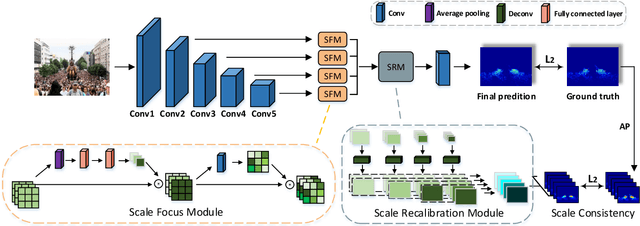
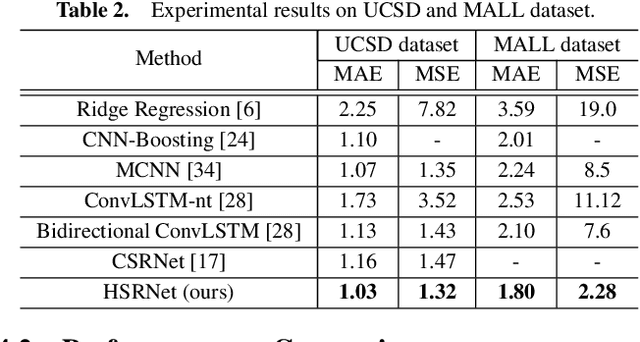
The task of crowd counting is extremely challenging due to complicated difficulties, especially the huge variation in vision scale. Previous works tend to adopt a naive concatenation of multi-scale information to tackle it, while the scale shifts between the feature maps are ignored. In this paper, we propose a novel Hierarchical Scale Recalibration Network (HSRNet), which addresses the above issues by modeling rich contextual dependencies and recalibrating multiple scale-associated information. Specifically, a Scale Focus Module (SFM) first integrates global context into local features by modeling the semantic inter-dependencies along channel and spatial dimensions sequentially. In order to reallocate channel-wise feature responses, a Scale Recalibration Module (SRM) adopts a step-by-step fusion to generate final density maps. Furthermore, we propose a novel Scale Consistency loss to constrain that the scale-associated outputs are coherent with groundtruth of different scales. With the proposed modules, our approach can ignore various noises selectively and focus on appropriate crowd scales automatically. Extensive experiments on crowd counting datasets (ShanghaiTech, MALL, WorldEXPO'10, and UCSD) show that our HSRNet can deliver superior results over all state-of-the-art approaches. More remarkably, we extend experiments on an extra vehicle dataset, whose results indicate that the proposed model is generalized to other applications.
Dynamic Graph Correlation Learning for Disease Diagnosis with Incomplete Labels
Feb 28, 2020
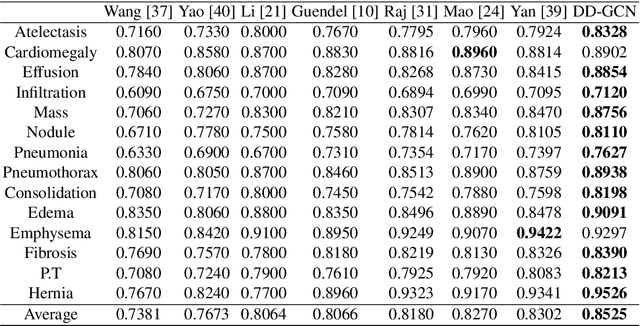
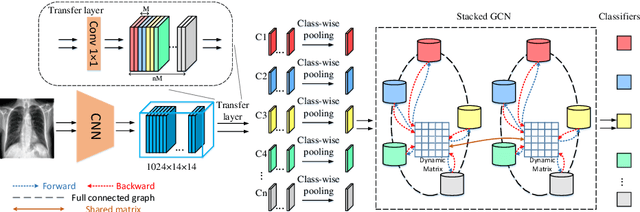
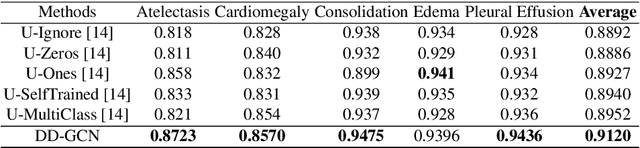
Disease diagnosis on chest X-ray images is a challenging multi-label classification task. Previous works generally classify the diseases independently on the input image without considering any correlation among diseases. However, such correlation actually exists, for example, Pleural Effusion is more likely to appear when Pneumothorax is present. In this work, we propose a Disease Diagnosis Graph Convolutional Network (DD-GCN) that presents a novel view of investigating the inter-dependency among different diseases by using a dynamic learnable adjacency matrix in graph structure to improve the diagnosis accuracy. To learn more natural and reliable correlation relationship, we feed each node with the image-level individual feature map corresponding to each type of disease. To our knowledge, our method is the first to build a graph over the feature maps with a dynamic adjacency matrix for correlation learning. To further deal with a practical issue of incomplete labels, DD-GCN also utilizes an adaptive loss and a curriculum learning strategy to train the model on incomplete labels. Experimental results on two popular chest X-ray (CXR) datasets show that our prediction accuracy outperforms state-of-the-arts, and the learned graph adjacency matrix establishes the correlation representations of different diseases, which is consistent with expert experience. In addition, we apply an ablation study to demonstrate the effectiveness of each component in DD-GCN.
Tell-the-difference: Fine-grained Visual Descriptor via a Discriminating Referee
Oct 14, 2019
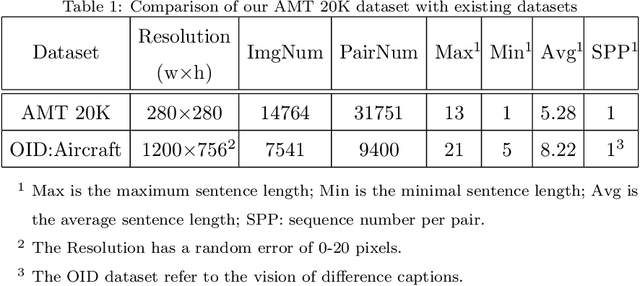
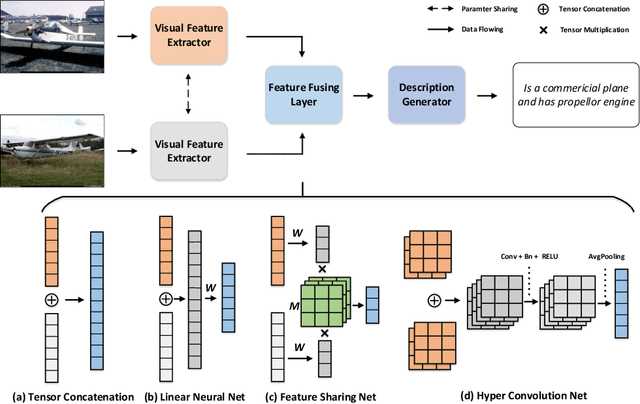

In this paper, we investigate a novel problem of telling the difference between image pairs in natural language. Compared to previous approaches for single image captioning, it is challenging to fetch linguistic representation from two independent visual information. To this end, we have proposed an effective encoder-decoder caption framework based on Hyper Convolution Net. In addition, a series of novel feature fusing techniques for pairwise visual information fusing are introduced and a discriminating referee is proposed to evaluate the pipeline. Because of the lack of appropriate datasets to support this task, we have collected and annotated a large new dataset with Amazon Mechanical Turk (AMT) for generating captions in a pairwise manner (with 14764 images and 26710 image pairs in total). The dataset is the first one on the relative difference caption task that provides descriptions in free language. We evaluate the effectiveness of our model on two datasets in the field and it outperforms the state-of-the-art approach by a large margin.
MHP-VOS: Multiple Hypotheses Propagation for Video Object Segmentation
Apr 17, 2019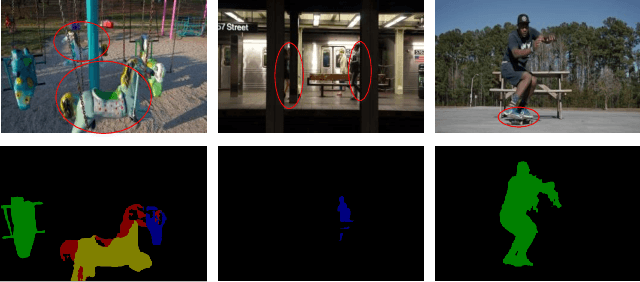
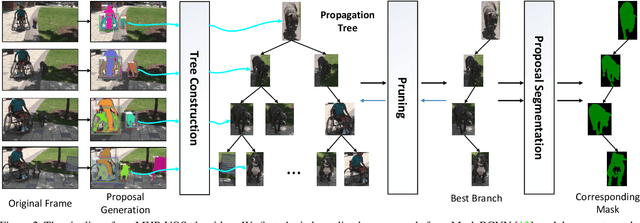
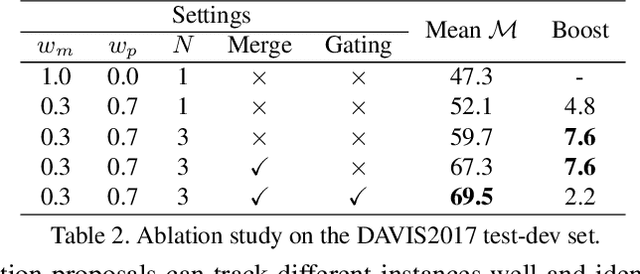
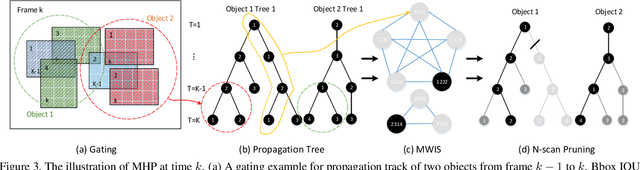
We address the problem of semi-supervised video object segmentation (VOS), where the masks of objects of interests are given in the first frame of an input video. To deal with challenging cases where objects are occluded or missing, previous work relies on greedy data association strategies that make decisions for each frame individually. In this paper, we propose a novel approach to defer the decision making for a target object in each frame, until a global view can be established with the entire video being taken into consideration. Our approach is in the same spirit as Multiple Hypotheses Tracking (MHT) methods, making several critical adaptations for the VOS problem. We employ the bounding box (bbox) hypothesis for tracking tree formation, and the multiple hypotheses are spawned by propagating the preceding bbox into the detected bbox proposals within a gated region starting from the initial object mask in the first frame. The gated region is determined by a gating scheme which takes into account a more comprehensive motion model rather than the simple Kalman filtering model in traditional MHT. To further design more customized algorithms tailored for VOS, we develop a novel mask propagation score instead of the appearance similarity score that could be brittle due to large deformations. The mask propagation score, together with the motion score, determines the affinity between the hypotheses during tree pruning. Finally, a novel mask merging strategy is employed to handle mask conflicts between objects. Extensive experiments on challenging datasets demonstrate the effectiveness of the proposed method, especially in the case of object missing.
Spatial-Temporal Synergic Residual Learning for Video Person Re-Identification
Jul 16, 2018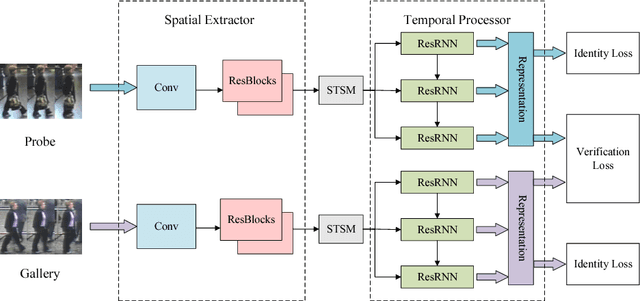
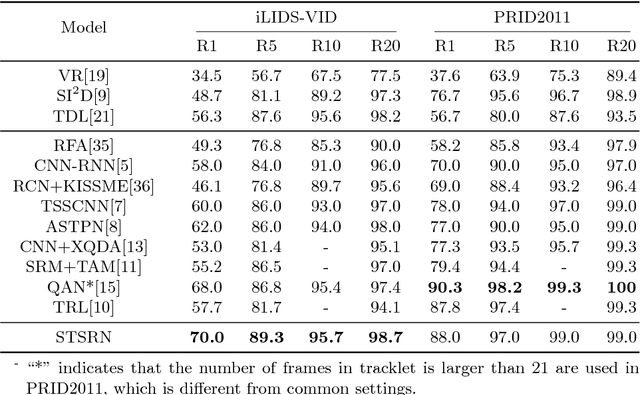
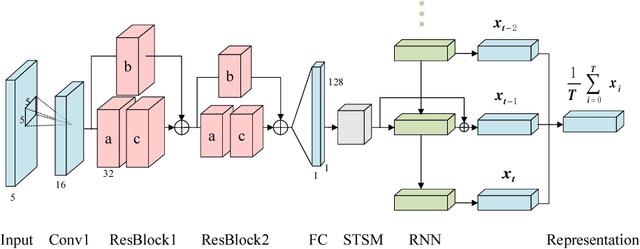
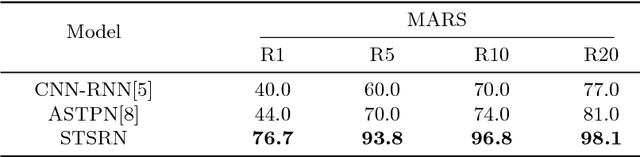
We tackle the problem of person re-identification in video setting in this paper, which has been viewed as a crucial task in many applications. Meanwhile, it is very challenging since the task requires learning effective representations from video sequences with heterogeneous spatial-temporal information. We present a novel method - Spatial-Temporal Synergic Residual Network (STSRN) for this problem. STSRN contains a spatial residual extractor, a temporal residual processor and a spatial-temporal smooth module. The smoother can alleviate sample noises along the spatial-temporal dimensions thus enable STSRN extracts more robust spatial-temporal features of consecutive frames. Extensive experiments are conducted on several challenging datasets including iLIDS-VID, PRID2011 and MARS. The results demonstrate that the proposed method achieves consistently superior performance over most of state-of-the-art methods.
Jointly Attentive Spatial-Temporal Pooling Networks for Video-based Person Re-Identification
Sep 29, 2017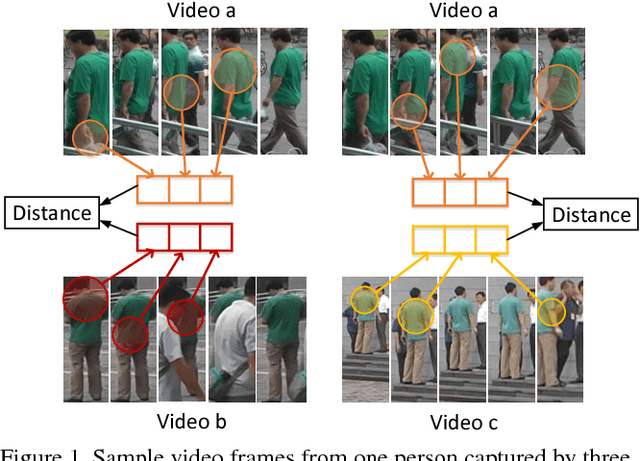
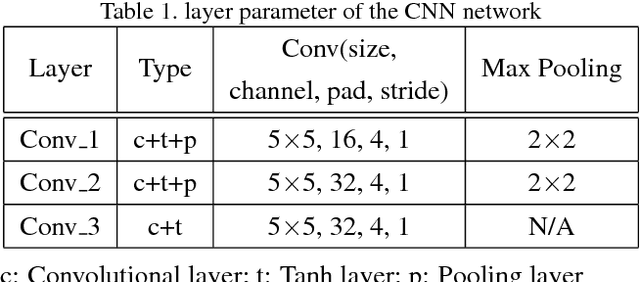
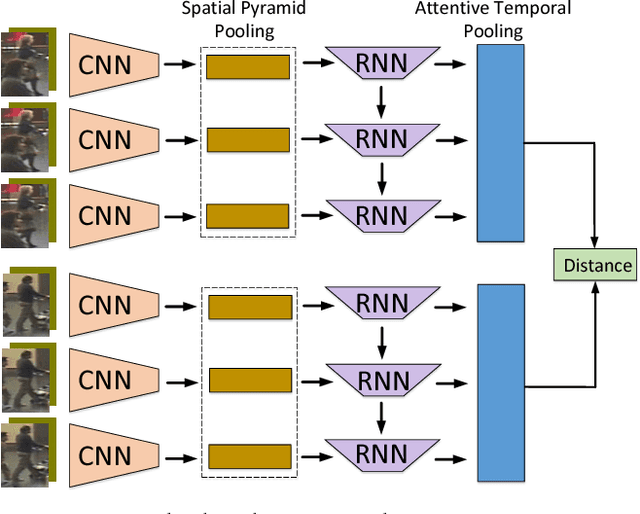
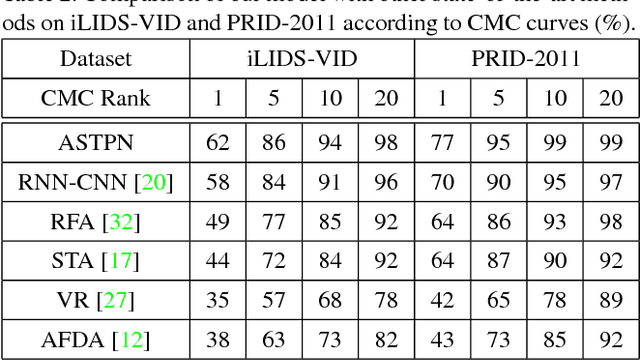
Person Re-Identification (person re-id) is a crucial task as its applications in visual surveillance and human-computer interaction. In this work, we present a novel joint Spatial and Temporal Attention Pooling Network (ASTPN) for video-based person re-identification, which enables the feature extractor to be aware of the current input video sequences, in a way that interdependency from the matching items can directly influence the computation of each other's representation. Specifically, the spatial pooling layer is able to select regions from each frame, while the attention temporal pooling performed can select informative frames over the sequence, both pooling guided by the information from distance matching. Experiments are conduced on the iLIDS-VID, PRID-2011 and MARS datasets and the results demonstrate that this approach outperforms existing state-of-art methods. We also analyze how the joint pooling in both dimensions can boost the person re-id performance more effectively than using either of them separately.