 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Stratified Approach to Robustness for Randomly Smoothed Classifiers
Jun 12, 2019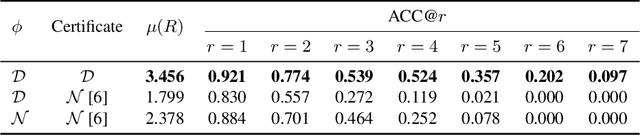
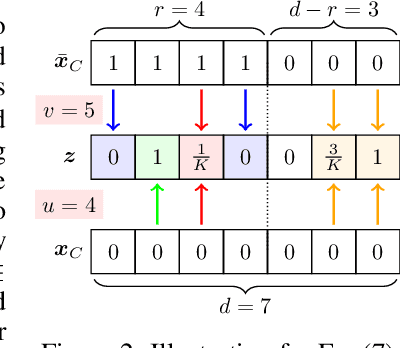

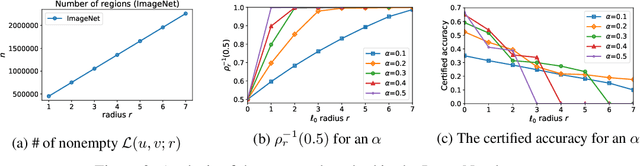
Strong theoretical guarantees of robustness can be given for ensembles of classifiers generated by input randomization. Specifically, an $\ell_2$ bounded adversary cannot alter the ensemble prediction generated by an isotropic Gaussian perturbation, where the radius for the adversary depends on both the variance of the perturbation as well as the ensemble margin at the point of interest. We build on and considerably expand this work across broad classes of perturbations. In particular, we offer guarantees and develop algorithms for the discrete case where the adversary is $\ell_0$ bounded. Moreover, we exemplify how the guarantees can be tightened with specific assumptions about the function class of the classifier such as a decision tree. We empirically illustrate these results with and without functional restrictions across image and molecule datasets.
Self-Supervised Learning for Contextualized Extractive Summarization
Jun 11, 2019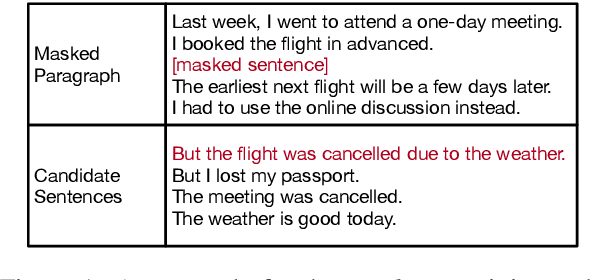
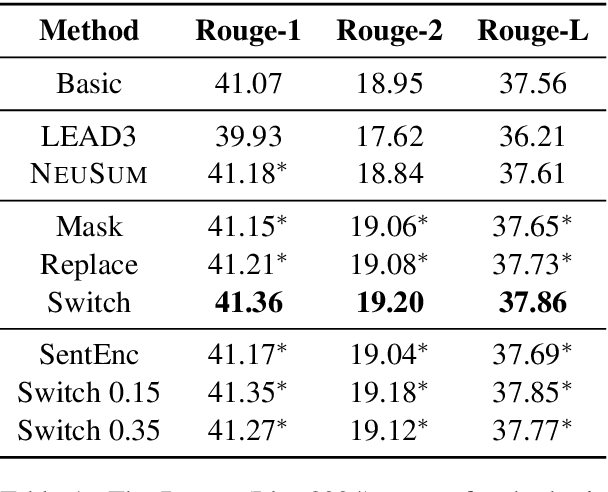
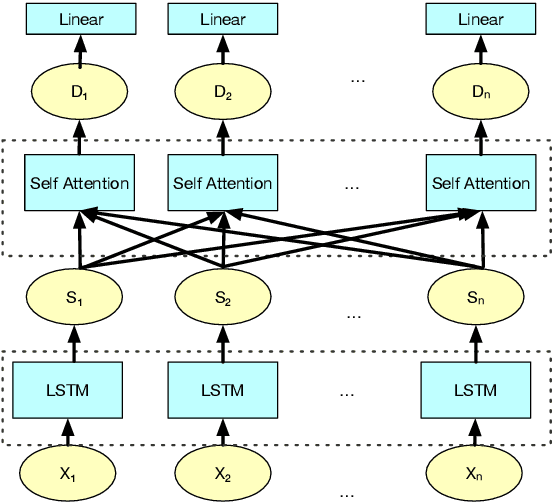
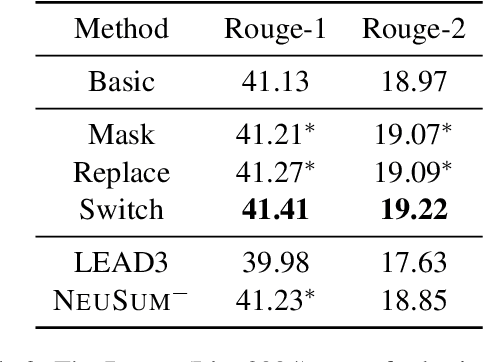
Existing models for extractive summarization are usually trained from scratch with a cross-entropy loss, which does not explicitly capture the global context at the document level. In this paper, we aim to improve this task by introducing three auxiliary pre-training tasks that learn to capture the document-level context in a self-supervised fashion. Experiments on the widely-used CNN/DM dataset validate the effectiveness of the proposed auxiliary tasks. Furthermore, we show that after pre-training, a clean model with simple building blocks is able to outperform previous state-of-the-art that are carefully designed.
Coupled Variational Recurrent Collaborative Filtering
Jun 11, 2019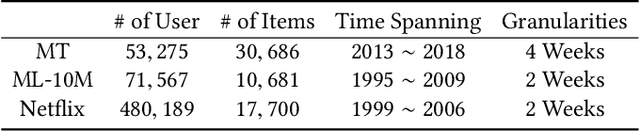
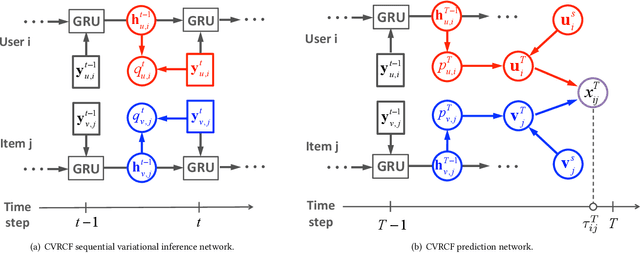
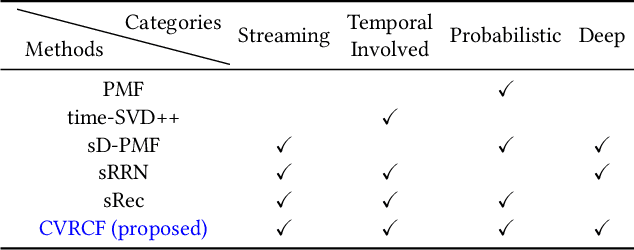
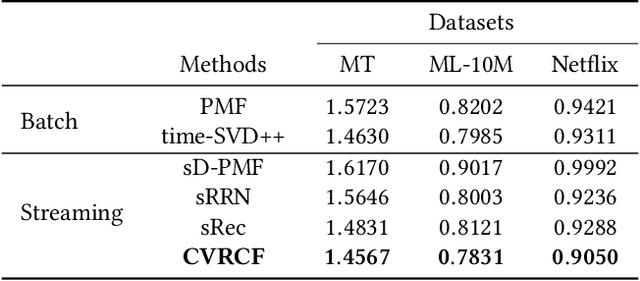
We focus on the problem of streaming recommender system and explore novel collaborative filtering algorithms to handle the data dynamicity and complexity in a streaming manner. Although deep neural networks have demonstrated the effectiveness of recommendation tasks, it is lack of explorations on integrating probabilistic models and deep architectures under streaming recommendation settings. Conjoining the complementary advantages of probabilistic models and deep neural networks could enhance both model effectiveness and the understanding of inference uncertainties. To bridge the gap, in this paper, we propose a Coupled Variational Recurrent Collaborative Filtering (CVRCF) framework based on the idea of Deep Bayesian Learning to handle the streaming recommendation problem. The framework jointly combines stochastic processes and deep factorization models under a Bayesian paradigm to model the generation and evolution of users' preferences and items' popularities. To ensure efficient optimization and streaming update, we further propose a sequential variational inference algorithm based on a cross variational recurrent neural network structure. Experimental results on three benchmark datasets demonstrate that the proposed framework performs favorably against the state-of-the-art methods in terms of both temporal dependency modeling and predictive accuracy. The learned latent variables also provide visualized interpretations for the evolution of temporal dynamics.
AUTOVC: Zero-Shot Voice Style Transfer with Only Autoencoder Loss
Jun 06, 2019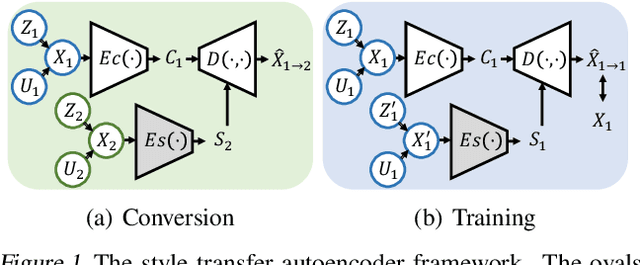


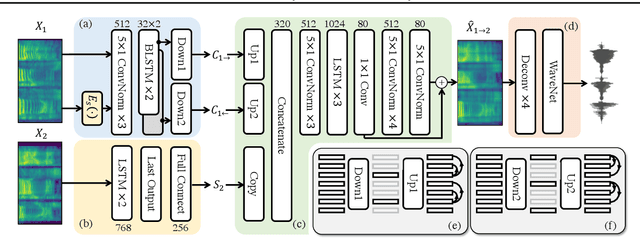
Non-parallel many-to-many voice conversion, as well as zero-shot voice conversion, remain under-explored areas. Deep style transfer algorithms, such as generative adversarial networks (GAN) and conditional variational autoencoder (CVAE), are being applied as new solutions in this field. However, GAN training is sophisticated and difficult, and there is no strong evidence that its generated speech is of good perceptual quality. On the other hand, CVAE training is simple but does not come with the distribution-matching property of a GAN. In this paper, we propose a new style transfer scheme that involves only an autoencoder with a carefully designed bottleneck. We formally show that this scheme can achieve distribution-matching style transfer by training only on a self-reconstruction loss. Based on this scheme, we proposed AUTOVC, which achieves state-of-the-art results in many-to-many voice conversion with non-parallel data, and which is the first to perform zero-shot voice conversion.
Improving Question Answering over Incomplete KBs with Knowledge-Aware Reader
May 31, 2019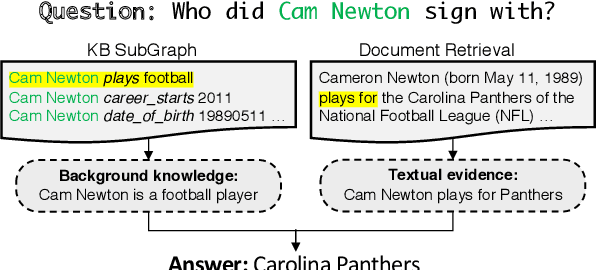
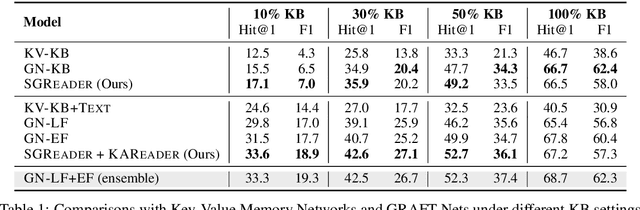
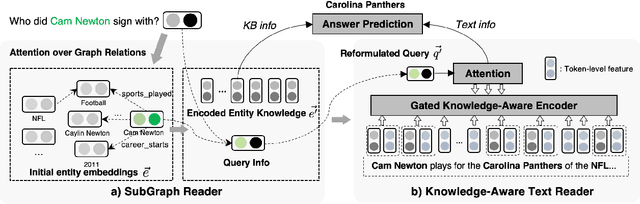

We propose a new end-to-end question answering model, which learns to aggregate answer evidence from an incomplete knowledge base (KB) and a set of retrieved text snippets. Under the assumptions that the structured KB is easier to query and the acquired knowledge can help the understanding of unstructured text, our model first accumulates knowledge of entities from a question-related KB subgraph; then reformulates the question in the latent space and reads the texts with the accumulated entity knowledge at hand. The evidence from KB and texts are finally aggregated to predict answers. On the widely-used KBQA benchmark WebQSP, our model achieves consistent improvements across settings with different extents of KB incompleteness.
Additive Adversarial Learning for Unbiased Authentication
May 28, 2019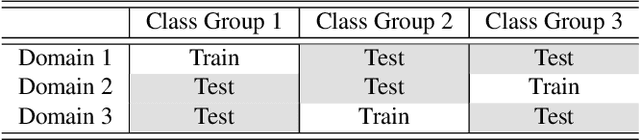
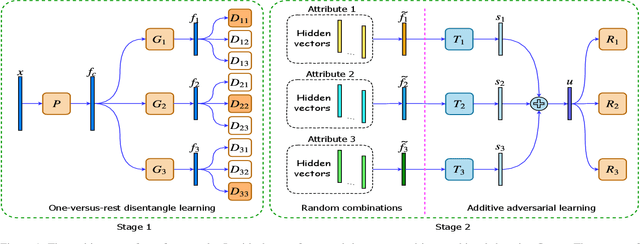

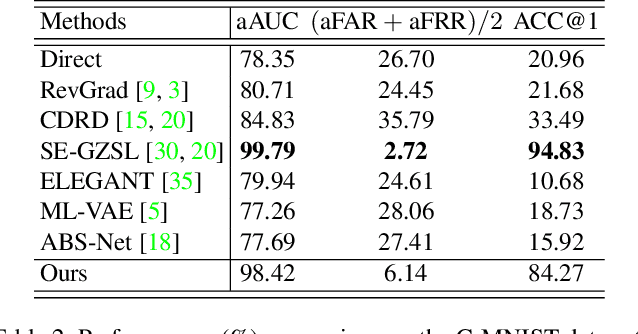
Authentication is a task aiming to confirm the truth between data instances and personal identities. Typical authentication applications include face recognition, person re-identification, authentication based on mobile devices and so on. The recently-emerging data-driven authentication process may encounter undesired biases, i.e., the models are often trained in one domain (e.g., for people wearing spring outfits) while required to apply in other domains (e.g., they change the clothes to summer outfits). To address this issue, we propose a novel two-stage method that disentangles the class/identity from domain-differences, and we consider multiple types of domain-difference. In the first stage, we learn disentangled representations by a one-versus-rest disentangle learning (OVRDL) mechanism. In the second stage, we improve the disentanglement by an additive adversarial learning (AAL) mechanism. Moreover, we discuss the necessity to avoid a learning dilemma due to disentangling causally related types of domain-difference. Comprehensive evaluation results demonstrate the effectiveness and superiority of the proposed method.
Selection Bias Explorations and Debias Methods for Natural Language Sentence Matching Datasets
May 20, 2019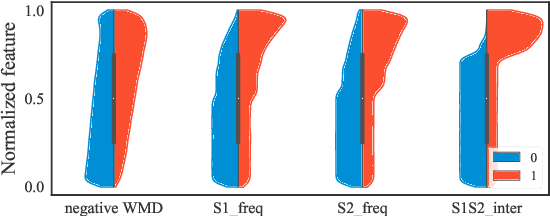
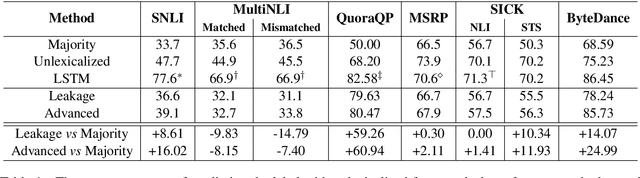
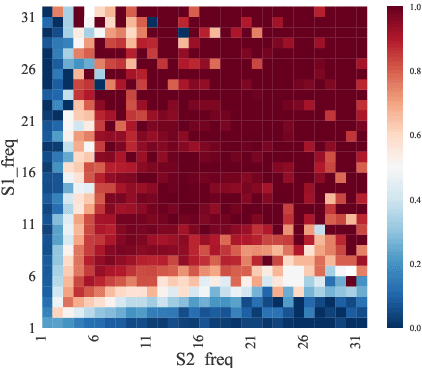
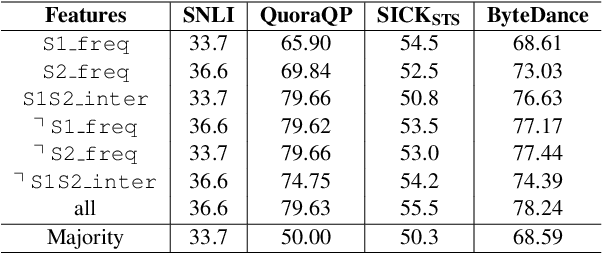
Natural Language Sentence Matching (NLSM) has gained substantial attention from both academics and the industry, and rich public datasets contribute a lot to this process. However, biased datasets can also hurt the generalization performance of trained models and give untrustworthy evaluation results. For many NLSM datasets, the providers select some pairs of sentences into the datasets, and this sampling procedure can easily bring unintended pattern, i.e., selection bias. One example is the QuoraQP dataset, where some content-independent naive features are unreasonably predictive. Such features are the reflection of the selection bias and termed as the leakage features. In this paper, we investigate the problem of selection bias on six NLSM datasets and find that four out of them are significantly biased. We further propose a training and evaluation framework to alleviate the bias. Experimental results on QuoraQP suggest that the proposed framework can improve the generalization ability of trained models, and give more trustworthy evaluation results for real-world adoptions.
Sentence Embedding Alignment for Lifelong Relation Extraction
Mar 26, 2019
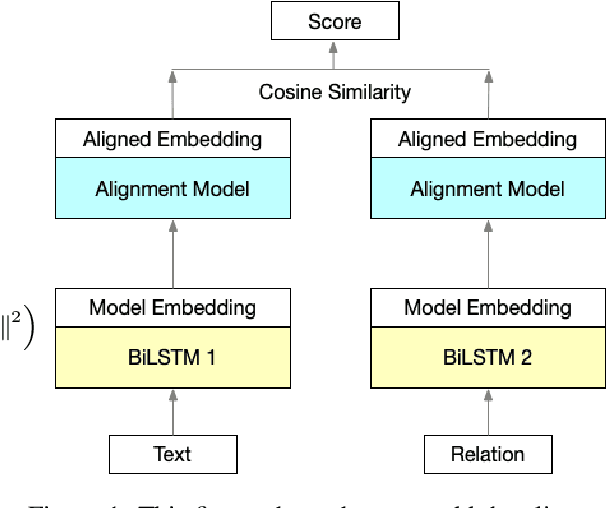
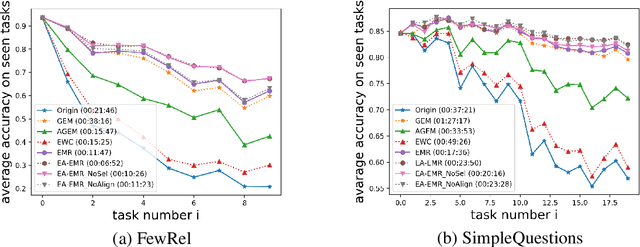
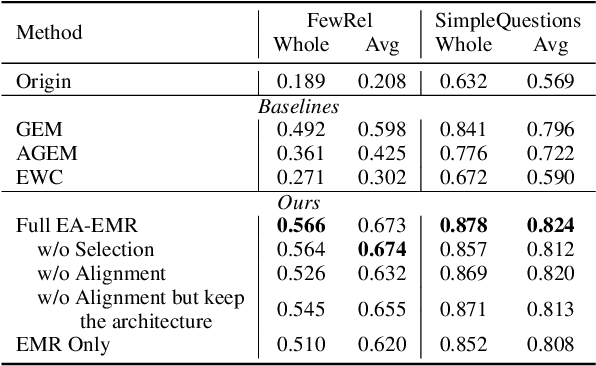
Conventional approaches to relation extraction usually require a fixed set of pre-defined relations. Such requirement is hard to meet in many real applications, especially when new data and relations are emerging incessantly and it is computationally expensive to store all data and re-train the whole model every time new data and relations come in. We formulate such a challenging problem as lifelong relation extraction and investigate memory-efficient incremental learning methods without catastrophically forgetting knowledge learned from previous tasks. We first investigate a modified version of the stochastic gradient methods with a replay memory, which surprisingly outperforms recent state-of-the-art lifelong learning methods. We further propose to improve this approach to alleviate the forgetting problem by anchoring the sentence embedding space. Specifically, we utilize an explicit alignment model to mitigate the sentence embedding distortion of the learned model when training on new data and new relations. Experiment results on multiple benchmarks show that our proposed method significantly outperforms the state-of-the-art lifelong learning approaches.
Hybrid Reinforcement Learning with Expert State Sequences
Mar 11, 2019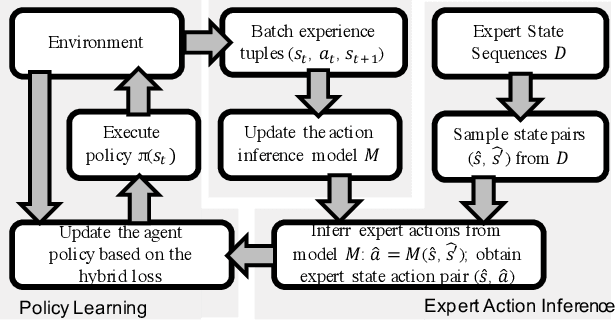
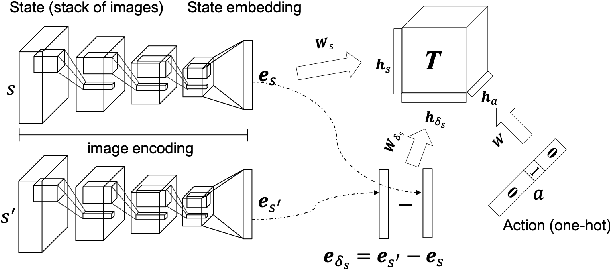
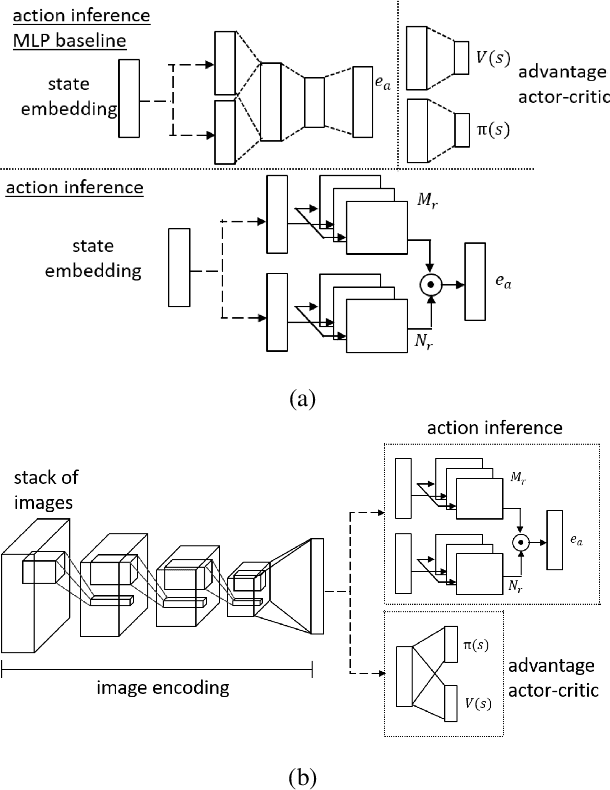
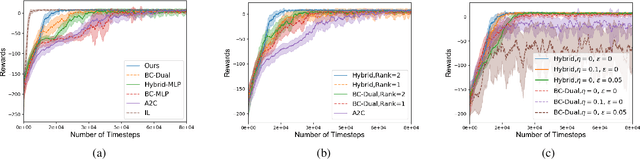
Existing imitation learning approaches often require that the complete demonstration data, including sequences of actions and states, are available. In this paper, we consider a more realistic and difficult scenario where a reinforcement learning agent only has access to the state sequences of an expert, while the expert actions are unobserved. We propose a novel tensor-based model to infer the unobserved actions of the expert state sequences. The policy of the agent is then optimized via a hybrid objective combining reinforcement learning and imitation learning. We evaluated our hybrid approach on an illustrative domain and Atari games. The empirical results show that (1) the agents are able to leverage state expert sequences to learn faster than pure reinforcement learning baselines, (2) our tensor-based action inference model is advantageous compared to standard deep neural networks in inferring expert actions, and (3) the hybrid policy optimization objective is robust against noise in expert state sequences.
Imposing Label-Relational Inductive Bias for Extremely Fine-Grained Entity Typing
Mar 06, 2019
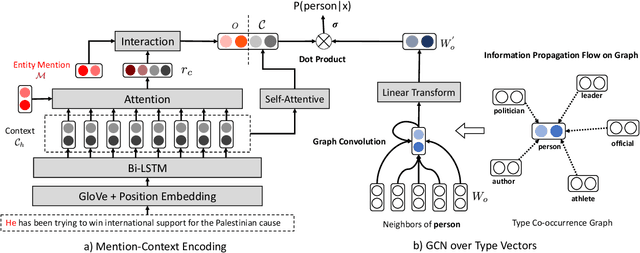
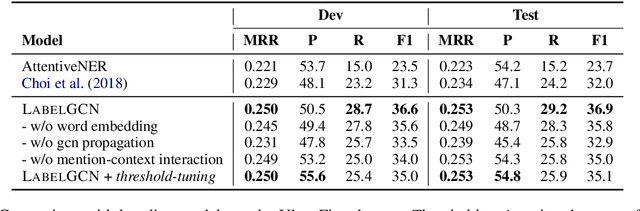
Existing entity typing systems usually exploit the type hierarchy provided by knowledge base (KB) schema to model label correlations and thus improve the overall performance. Such techniques, however, are not directly applicable to more open and practical scenarios where the type set is not restricted by KB schema and includes a vast number of free-form types. To model the underly-ing label correlations without access to manually annotated label structures, we introduce a novel label-relational inductive bias, represented by a graph propagation layer that effectively encodes both global label co-occurrence statistics and word-level similarities.On a large dataset with over 10,000 free-form types, the graph-enhanced model equipped with an attention-based matching module is able to achieve a much higher recall score while maintaining a high-level precision. Specifically, it achieves a 15.3% relative F1 improvement and also less inconsistency in the outputs. We further show that a simple modification of our proposed graph layer can also improve the performance on a conventional and widely-tested dataset that only includes KB-schema types.