 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Generalization of Metric Learning via Listwise Self-distillation
Jun 17, 2022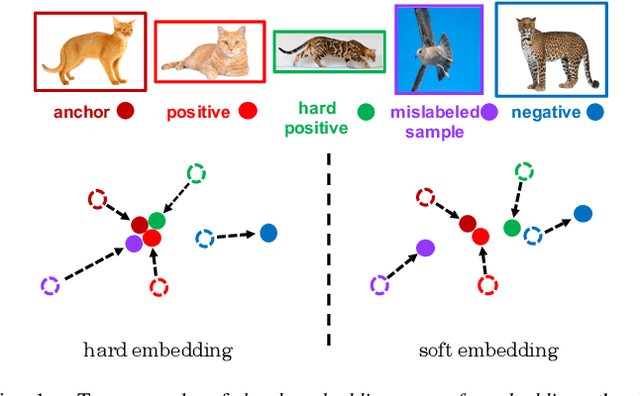
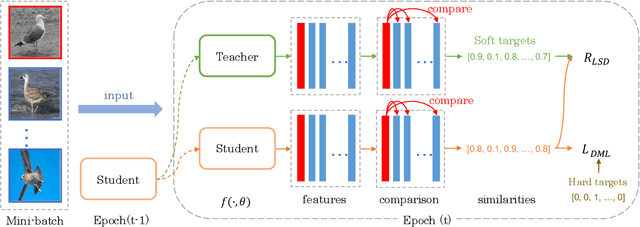


Most deep metric learning (DML) methods employ a strategy that forces all positive samples to be close in the embedding space while keeping them away from negative ones. However, such a strategy ignores the internal relationships of positive (negative) samples and often leads to overfitting, especially in the presence of hard samples and mislabeled samples. In this work, we propose a simple yet effective regularization, namely Listwise Self-Distillation (LSD), which progressively distills a model's own knowledge to adaptively assign a more appropriate distance target to each sample pair in a batch. LSD encourages smoother embeddings and information mining within positive (negative) samples as a way to mitigate overfitting and thus improve generalization. Our LSD can be directly integrated into general DML frameworks. Extensive experiments show that LSD consistently boosts the performance of various metric learning methods on multiple datasets.
Unsupervised Foggy Scene Understanding via Self Spatial-Temporal Label Diffusion
Jun 10, 2022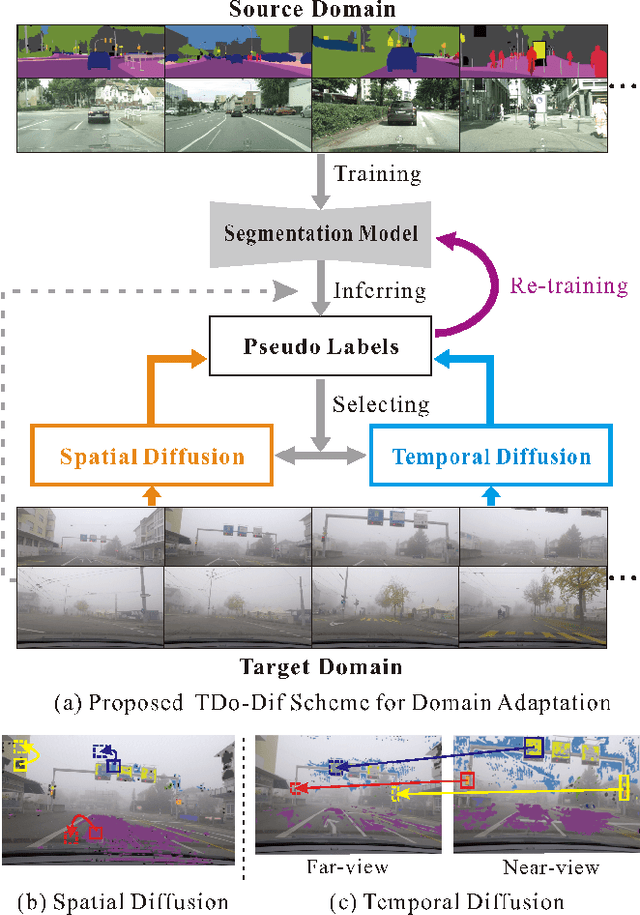
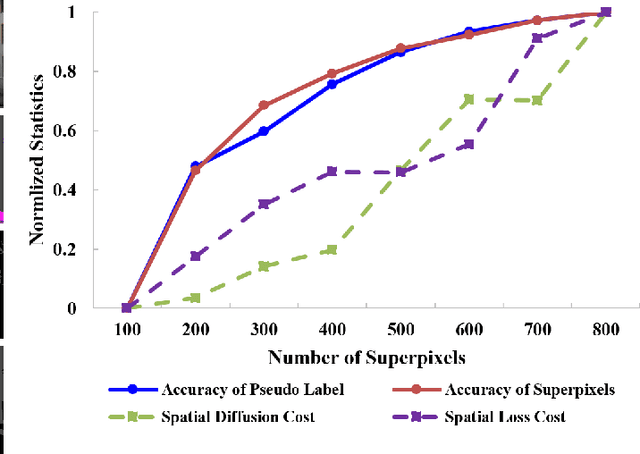
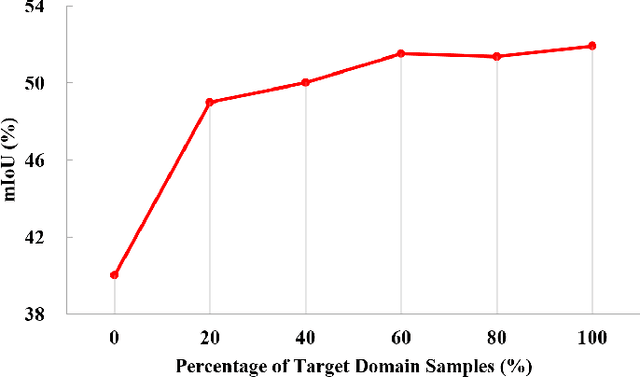
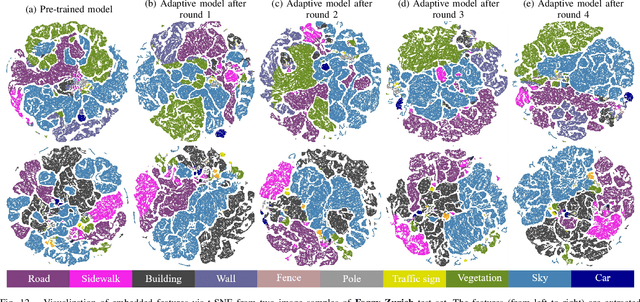
Understanding foggy image sequence in the driving scenes is critical for autonomous driving, but it remains a challenging task due to the difficulty in collecting and annotating real-world images of adverse weather. Recently, the self-training strategy has been considered a powerful solution for unsupervised domain adaptation, which iteratively adapts the model from the source domain to the target domain by generating target pseudo labels and re-training the model. However, the selection of confident pseudo labels inevitably suffers from the conflict between sparsity and accuracy, both of which will lead to suboptimal models. To tackle this problem, we exploit the characteristics of the foggy image sequence of driving scenes to densify the confident pseudo labels. Specifically, based on the two discoveries of local spatial similarity and adjacent temporal correspondence of the sequential image data, we propose a novel Target-Domain driven pseudo label Diffusion (TDo-Dif) scheme. It employs superpixels and optical flows to identify the spatial similarity and temporal correspondence, respectively and then diffuses the confident but sparse pseudo labels within a superpixel or a temporal corresponding pair linked by the flow. Moreover, to ensure the feature similarity of the diffused pixels, we introduce local spatial similarity loss and temporal contrastive loss in the model re-training stage. Experimental results show that our TDo-Dif scheme helps the adaptive model achieve 51.92% and 53.84% mean intersection-over-union (mIoU) on two publicly available natural foggy datasets (Foggy Zurich and Foggy Driving), which exceeds the state-of-the-art unsupervised domain adaptive semantic segmentation methods. Models and data can be found at https://github.com/velor2012/TDo-Dif.
Geo-Localization via Ground-to-Satellite Cross-View Image Retrieval
May 22, 2022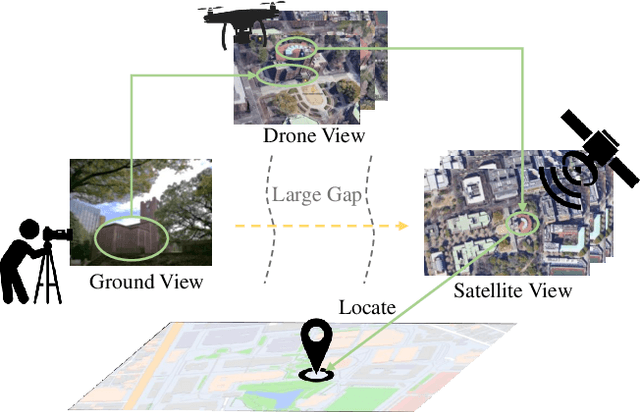
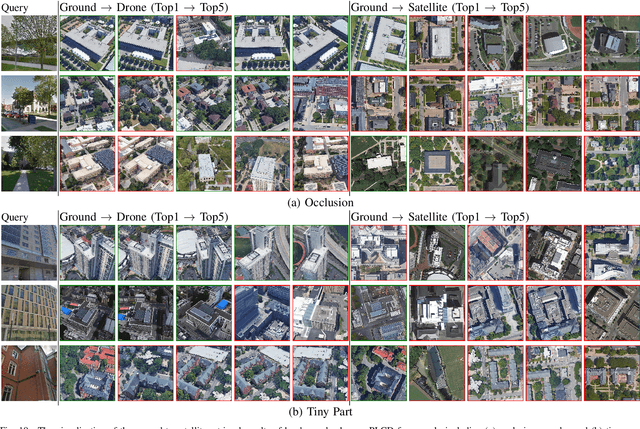
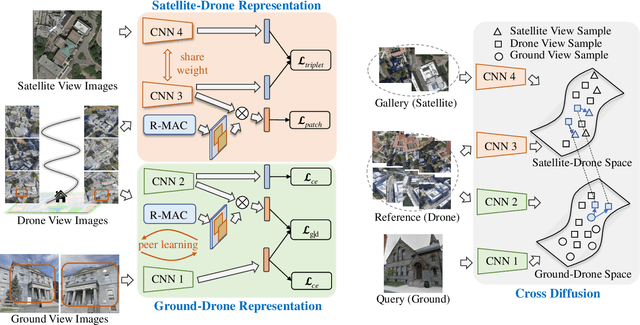
The large variation of viewpoint and irrelevant content around the target always hinder accurate image retrieval and its subsequent tasks. In this paper, we investigate an extremely challenging task: given a ground-view image of a landmark, we aim to achieve cross-view geo-localization by searching out its corresponding satellite-view images. Specifically, the challenge comes from the gap between ground-view and satellite-view, which includes not only large viewpoint changes (some parts of the landmark may be invisible from front view to top view) but also highly irrelevant background (the target landmark tend to be hidden in other surrounding buildings), making it difficult to learn a common representation or a suitable mapping. To address this issue, we take advantage of drone-view information as a bridge between ground-view and satellite-view domains. We propose a Peer Learning and Cross Diffusion (PLCD) framework. PLCD consists of three parts: 1) a peer learning across ground-view and drone-view to find visible parts to benefit ground-drone cross-view representation learning; 2) a patch-based network for satellite-drone cross-view representation learning; 3) a cross diffusion between ground-drone space and satellite-drone space. Extensive experiments conducted on the University-Earth and University-Google datasets show that our method outperforms state-of-the-arts significantly.
* 13 pages, 10 figures
Neural Global Shutter: Learn to Restore Video from a Rolling Shutter Camera with Global Reset Feature
Apr 03, 2022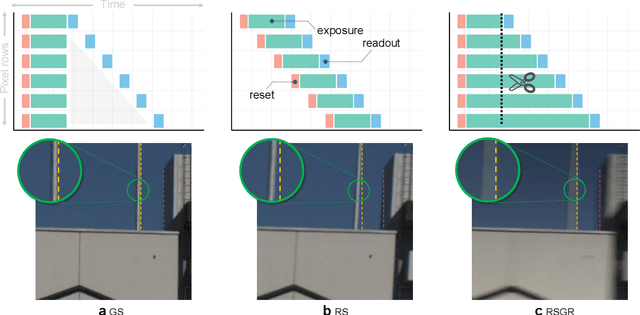
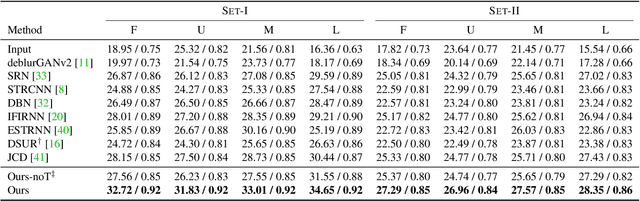
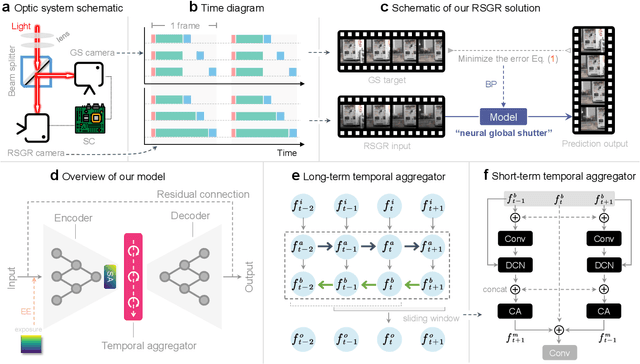
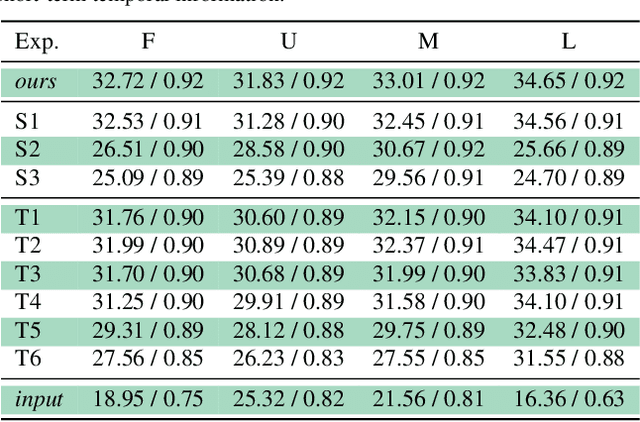
Most computer vision systems assume distortion-free images as inputs. The widely used rolling-shutter (RS) image sensors, however, suffer from geometric distortion when the camera and object undergo motion during capture. Extensive researches have been conducted on correcting RS distortions. However, most of the existing work relies heavily on the prior assumptions of scenes or motions. Besides, the motion estimation steps are either oversimplified or computationally inefficient due to the heavy flow warping, limiting their applicability. In this paper, we investigate using rolling shutter with a global reset feature (RSGR) to restore clean global shutter (GS) videos. This feature enables us to turn the rectification problem into a deblur-like one, getting rid of inaccurate and costly explicit motion estimation. First, we build an optic system that captures paired RSGR/GS videos. Second, we develop a novel algorithm incorporating spatial and temporal designs to correct the spatial-varying RSGR distortion. Third, we demonstrate that existing image-to-image translation algorithms can recover clean GS videos from distorted RSGR inputs, yet our algorithm achieves the best performance with the specific designs. Our rendered results are not only visually appealing but also beneficial to downstream tasks. Compared to the state-of-the-art RS solution, our RSGR solution is superior in both effectiveness and efficiency. Considering it is easy to realize without changing the hardware, we believe our RSGR solution can potentially replace the RS solution in taking distortion-free videos with low noise and low budget.
Optimal Correction Cost for Object Detection Evaluation
Mar 28, 2022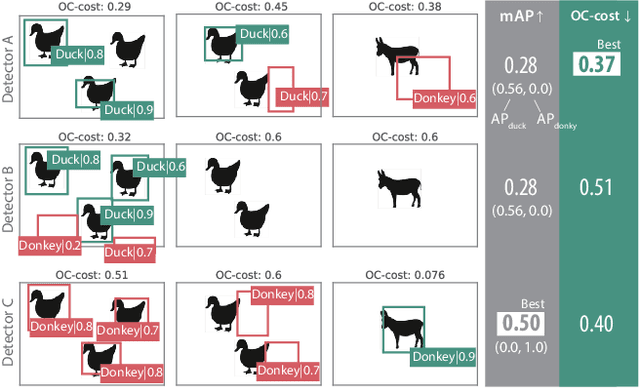
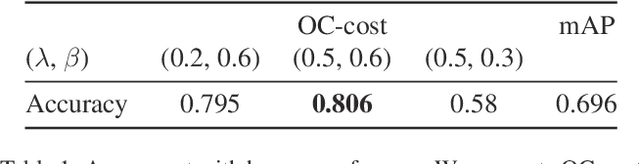
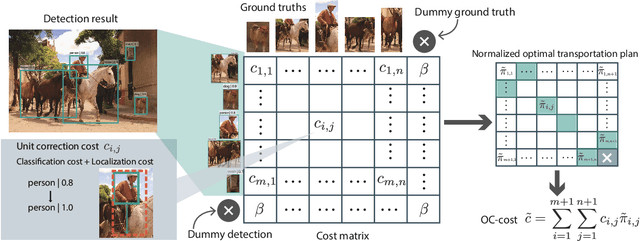

Mean Average Precision (mAP) is the primary evaluation measure for object detection. Although object detection has a broad range of applications, mAP evaluates detectors in terms of the performance of ranked instance retrieval. Such the assumption for the evaluation task does not suit some downstream tasks. To alleviate the gap between downstream tasks and the evaluation scenario, we propose Optimal Correction Cost (OC-cost), which assesses detection accuracy at image level. OC-cost computes the cost of correcting detections to ground truths as a measure of accuracy. The cost is obtained by solving an optimal transportation problem between the detections and the ground truths. Unlike mAP, OC-cost is designed to penalize false positive and false negative detections properly, and every image in a dataset is treated equally. Our experimental result validates that OC-cost has better agreement with human preference than a ranking-based measure, i.e., mAP for a single image. We also show that detectors' rankings by OC-cost are more consistent on different data splits than mAP. Our goal is not to replace mAP with OC-cost but provide an additional tool to evaluate detectors from another aspect. To help future researchers and developers choose a target measure, we provide a series of experiments to clarify how mAP and OC-cost differ.
Improving Camouflaged Object Detection with the Uncertainty of Pseudo-edge Labels
Oct 29, 2021
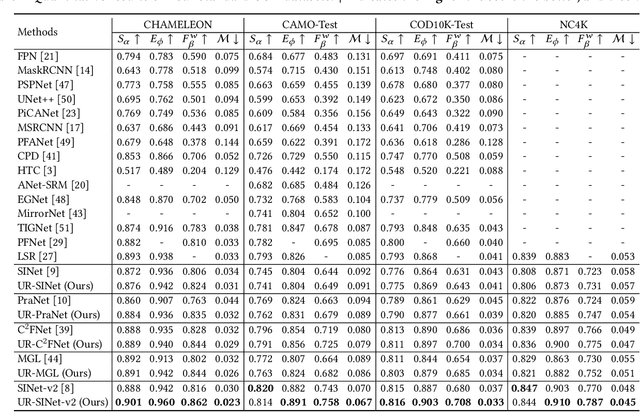
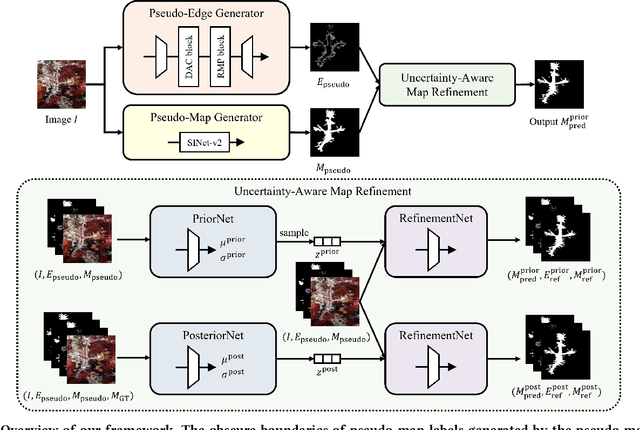

This paper focuses on camouflaged object detection (COD), which is a task to detect objects hidden in the background. Most of the current COD models aim to highlight the target object directly while outputting ambiguous camouflaged boundaries. On the other hand, the performance of the models considering edge information is not yet satisfactory. To this end, we propose a new framework that makes full use of multiple visual cues, i.e., saliency as well as edges, to refine the predicted camouflaged map. This framework consists of three key components, i.e., a pseudo-edge generator, a pseudo-map generator, and an uncertainty-aware refinement module. In particular, the pseudo-edge generator estimates the boundary that outputs the pseudo-edge label, and the conventional COD method serves as the pseudo-map generator that outputs the pseudo-map label. Then, we propose an uncertainty-based module to reduce the uncertainty and noise of such two pseudo labels, which takes both pseudo labels as input and outputs an edge-accurate camouflaged map. Experiments on various COD datasets demonstrate the effectiveness of our method with superior performance to the existing state-of-the-art methods.
Scalable Personalised Item Ranking through Parametric Density Estimation
May 11, 2021
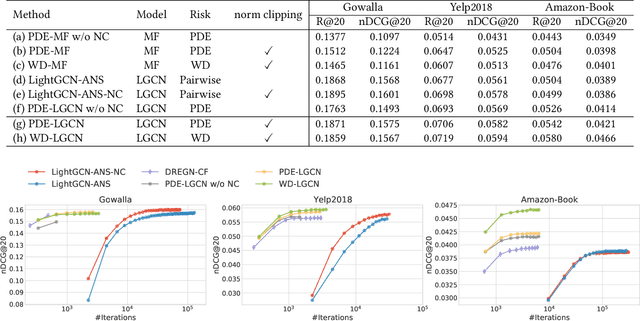
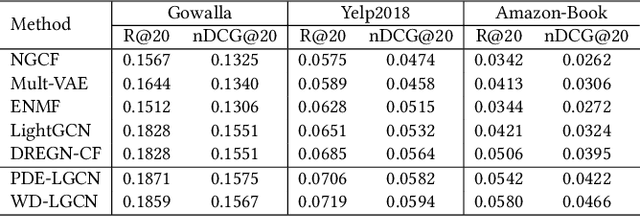
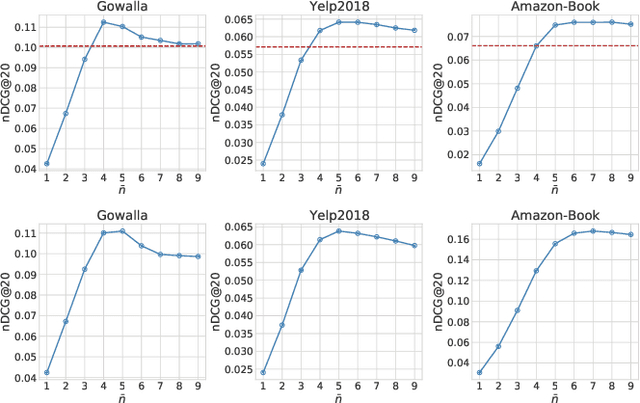
Learning from implicit feedback is challenging because of the difficult nature of the one-class problem: we can observe only positive examples. Most conventional methods use a pairwise ranking approach and negative samplers to cope with the one-class problem. However, such methods have two main drawbacks particularly in large-scale applications; (1) the pairwise approach is severely inefficient due to the quadratic computational cost; and (2) even recent model-based samplers (e.g. IRGAN) cannot achieve practical efficiency due to the training of an extra model. In this paper, we propose a learning-to-rank approach, which achieves convergence speed comparable to the pointwise counterpart while performing similarly to the pairwise counterpart in terms of ranking effectiveness. Our approach estimates the probability densities of positive items for each user within a rich class of distributions, viz. \emph{exponential family}. In our formulation, we derive a loss function and the appropriate negative sampling distribution based on maximum likelihood estimation. We also develop a practical technique for risk approximation and a regularisation scheme. We then discuss that our single-model approach is equivalent to an IRGAN variant under a certain condition. Through experiments on real-world datasets, our approach outperforms the pointwise and pairwise counterparts in terms of effectiveness and efficiency.
Density-Ratio Based Personalised Ranking from Implicit Feedback
Jan 19, 2021
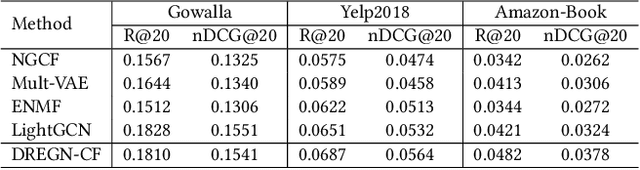
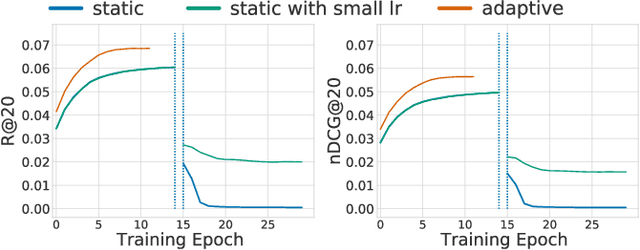
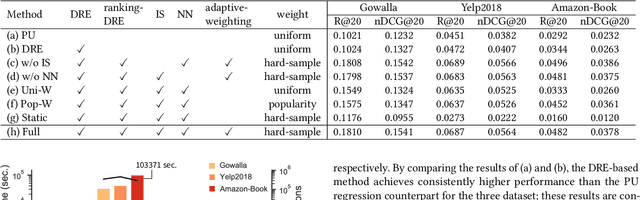
Learning from implicit user feedback is challenging as we can only observe positive samples but never access negative ones. Most conventional methods cope with this issue by adopting a pairwise ranking approach with negative sampling. However, the pairwise ranking approach has a severe disadvantage in the convergence time owing to the quadratically increasing computational cost with respect to the sample size; it is problematic, particularly for large-scale datasets and complex models such as neural networks. By contrast, a pointwise approach does not directly solve a ranking problem, and is therefore inferior to a pairwise counterpart in top-K ranking tasks; however, it is generally advantageous in regards to the convergence time. This study aims to establish an approach to learn personalised ranking from implicit feedback, which reconciles the training efficiency of the pointwise approach and ranking effectiveness of the pairwise counterpart. The key idea is to estimate the ranking of items in a pointwise manner; we first reformulate the conventional pointwise approach based on density ratio estimation and then incorporate the essence of ranking-oriented approaches (e.g. the pairwise approach) into our formulation. Through experiments on three real-world datasets, we demonstrate that our approach not only dramatically reduces the convergence time (one to two orders of magnitude faster) but also significantly improving the ranking performance.
Image Inpainting Guided by Coherence Priors of Semantics and Textures
Dec 15, 2020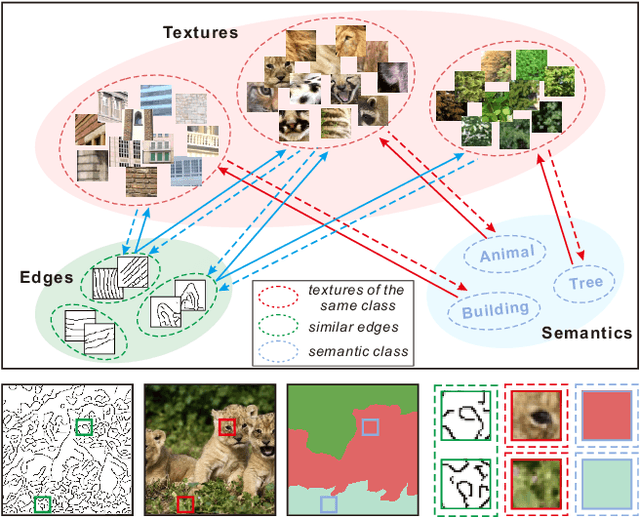
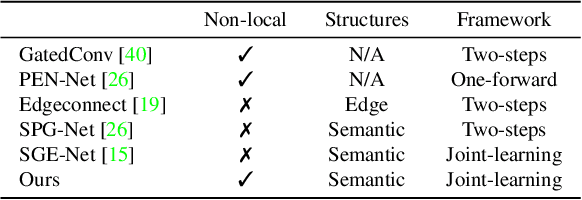
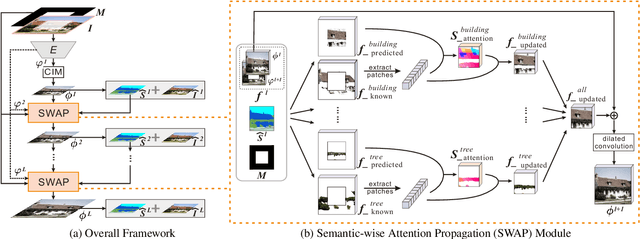
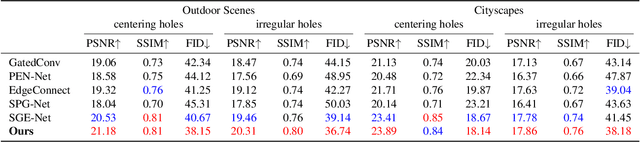
Existing inpainting methods have achieved promising performance in recovering defected images of specific scenes. However, filling holes involving multiple semantic categories remains challenging due to the obscure semantic boundaries and the mixture of different semantic textures. In this paper, we introduce coherence priors between the semantics and textures which make it possible to concentrate on completing separate textures in a semantic-wise manner. Specifically, we adopt a multi-scale joint optimization framework to first model the coherence priors and then accordingly interleavingly optimize image inpainting and semantic segmentation in a coarse-to-fine manner. A Semantic-Wise Attention Propagation (SWAP) module is devised to refine completed image textures across scales by exploring non-local semantic coherence, which effectively mitigates mix-up of textures. We also propose two coherence losses to constrain the consistency between the semantics and the inpainted image in terms of the overall structure and detailed textures. Experimental results demonstrate the superiority of our proposed method for challenging cases with complex holes.
Towards Unsupervised Crowd Counting via Regression-Detection Bi-knowledge Transfer
Aug 12, 2020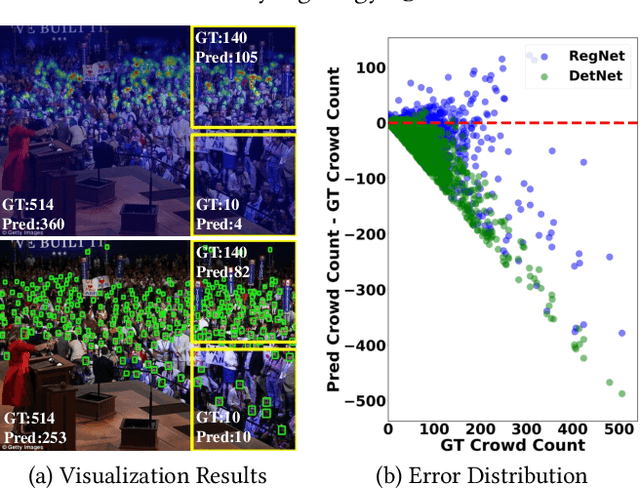
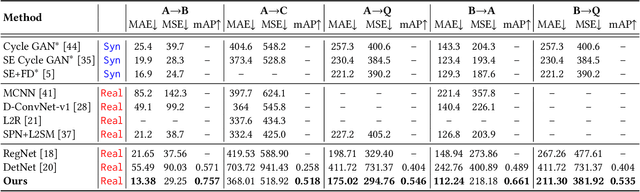
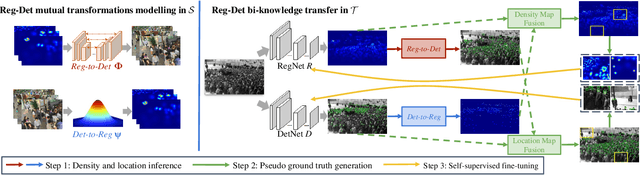
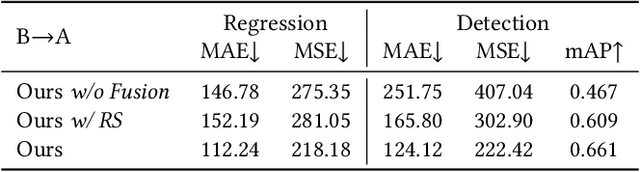
Unsupervised crowd counting is a challenging yet not largely explored task. In this paper, we explore it in a transfer learning setting where we learn to detect and count persons in an unlabeled target set by transferring bi-knowledge learnt from regression- and detection-based models in a labeled source set. The dual source knowledge of the two models is heterogeneous and complementary as they capture different modalities of the crowd distribution. We formulate the mutual transformations between the outputs of regression- and detection-based models as two scene-agnostic transformers which enable knowledge distillation between the two models. Given the regression- and detection-based models and their mutual transformers learnt in the source, we introduce an iterative self-supervised learning scheme with regression-detection bi-knowledge transfer in the target. Extensive experiments on standard crowd counting benchmarks, ShanghaiTech, UCF\_CC\_50, and UCF\_QNRF demonstrate a substantial improvement of our method over other state-of-the-arts in the transfer learning setting.