 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Fault-tolerant Control of Underwater Vehicles with Thruster Failures
Apr 22, 2025



This paper presents a fault-tolerant control for the trajectory tracking of autonomous underwater vehicles (AUVs) against thruster failures. We formulate faults in AUV thrusters as discrete switching events during a UAV mission, and develop a soft-switching approach in facilitating shift of control strategies across fault scenarios. We mathematically define AUV thruster fault scenarios, and develop the fault-tolerant control that captures the fault scenario via Bayesian approach. Particularly, when the AUV fault type switches from one to another, the developed control captures the fault states and maintains the control by a linear quadratic tracking controller. With the captured fault states by Bayesian approach, we derive the control law by aggregating the control outputs for individual fault scenarios weighted by their Bayesian posterior probability. The developed fault-tolerant control works in an adaptive way and guarantees soft-switching across fault scenarios, and requires no complicated fault detection dedicated to different type of faults. The entailed soft-switching ensures stable AUV trajectory tracking when fault type shifts, which otherwise leads to reduced control under hard-switching control strategies. We conduct numerical simulations with diverse AUV thruster fault settings. The results demonstrate that the proposed control can provide smooth transition across thruster failures, and effectively sustain AUV trajectory tracking control in case of thruster failures and failure shifts.
OmniAudio: Generating Spatial Audio from 360-Degree Video
Apr 21, 2025


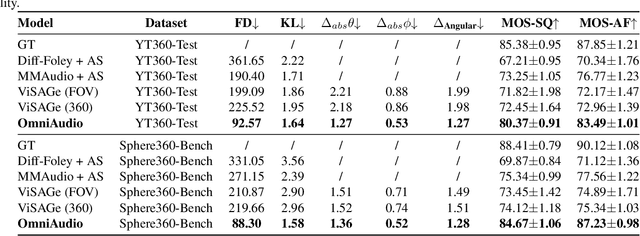
Traditional video-to-audio generation techniques primarily focus on field-of-view (FoV) video and non-spatial audio, often missing the spatial cues necessary for accurately representing sound sources in 3D environments. To address this limitation, we introduce a novel task, 360V2SA, to generate spatial audio from 360-degree videos, specifically producing First-order Ambisonics (FOA) audio - a standard format for representing 3D spatial audio that captures sound directionality and enables realistic 3D audio reproduction. We first create Sphere360, a novel dataset tailored for this task that is curated from real-world data. We also design an efficient semi-automated pipeline for collecting and cleaning paired video-audio data. To generate spatial audio from 360-degree video, we propose a novel framework OmniAudio, which leverages self-supervised pre-training using both spatial audio data (in FOA format) and large-scale non-spatial data. Furthermore, OmniAudio features a dual-branch framework that utilizes both panoramic and FoV video inputs to capture comprehensive local and global information from 360-degree videos. Experimental results demonstrate that OmniAudio achieves state-of-the-art performance across both objective and subjective metrics on Sphere360. Code and datasets will be released at https://github.com/liuhuadai/OmniAudio. The demo page is available at https://OmniAudio-360V2SA.github.io.
Evolved Hierarchical Masking for Self-Supervised Learning
Apr 12, 2025Existing Masked Image Modeling methods apply fixed mask patterns to guide the self-supervised training. As those mask patterns resort to different criteria to depict image contents, sticking to a fixed pattern leads to a limited vision cues modeling capability.This paper introduces an evolved hierarchical masking method to pursue general visual cues modeling in self-supervised learning. The proposed method leverages the vision model being trained to parse the input visual cues into a hierarchy structure, which is hence adopted to generate masks accordingly. The accuracy of hierarchy is on par with the capability of the model being trained, leading to evolved mask patterns at different training stages. Initially, generated masks focus on low-level visual cues to grasp basic textures, then gradually evolve to depict higher-level cues to reinforce the learning of more complicated object semantics and contexts. Our method does not require extra pre-trained models or annotations and ensures training efficiency by evolving the training difficulty. We conduct extensive experiments on seven downstream tasks including partial-duplicate image retrieval relying on low-level details, as well as image classification and semantic segmentation that require semantic parsing capability. Experimental results demonstrate that it substantially boosts performance across these tasks. For instance, it surpasses the recent MAE by 1.1\% in imageNet-1K classification and 1.4\% in ADE20K segmentation with the same training epochs. We also align the proposed method with the current research focus on LLMs. The proposed approach bridges the gap with large-scale pre-training on semantic demanding tasks and enhances intricate detail perception in tasks requiring low-level feature recognition.
Multi-modal Reference Learning for Fine-grained Text-to-Image Retrieval
Apr 10, 2025Fine-grained text-to-image retrieval aims to retrieve a fine-grained target image with a given text query. Existing methods typically assume that each training image is accurately depicted by its textual descriptions. However, textual descriptions can be ambiguous and fail to depict discriminative visual details in images, leading to inaccurate representation learning. To alleviate the effects of text ambiguity, we propose a Multi-Modal Reference learning framework to learn robust representations. We first propose a multi-modal reference construction module to aggregate all visual and textual details of the same object into a comprehensive multi-modal reference. The multi-modal reference hence facilitates the subsequent representation learning and retrieval similarity computation. Specifically, a reference-guided representation learning module is proposed to use multi-modal references to learn more accurate visual and textual representations. Additionally, we introduce a reference-based refinement method that employs the object references to compute a reference-based similarity that refines the initial retrieval results. Extensive experiments are conducted on five fine-grained text-to-image retrieval datasets for different text-to-image retrieval tasks. The proposed method has achieved superior performance over state-of-the-art methods. For instance, on the text-to-person image retrieval dataset RSTPReid, our method achieves the Rank1 accuracy of 56.2\%, surpassing the recent CFine by 5.6\%.
Exploring the Generalizability of Geomagnetic Navigation: A Deep Reinforcement Learning approach with Policy Distillation
Feb 07, 2025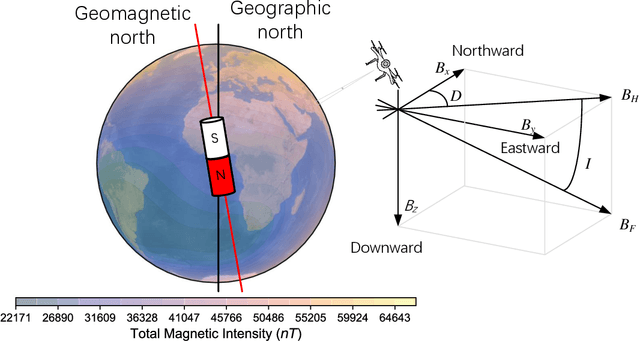
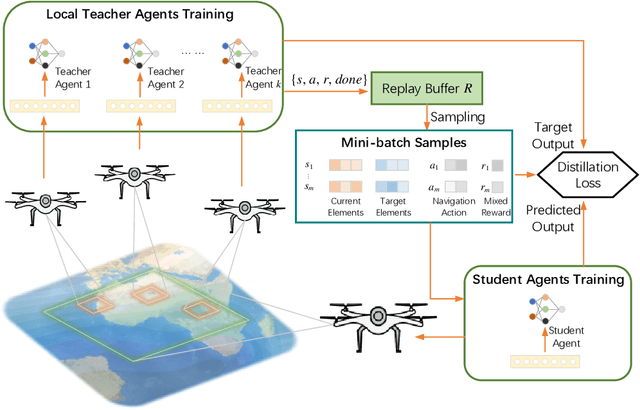
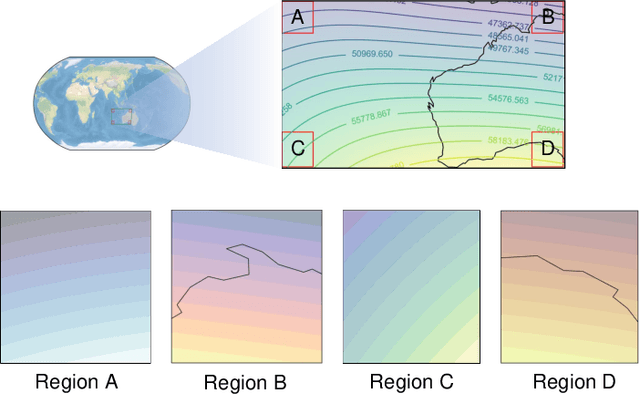
The advancement in autonomous vehicles has empowered navigation and exploration in unknown environments. Geomagnetic navigation for autonomous vehicles has drawn increasing attention with its independence from GPS or inertial navigation devices. While geomagnetic navigation approaches have been extensively investigated, the generalizability of learned geomagnetic navigation strategies remains unexplored. The performance of a learned strategy can degrade outside of its source domain where the strategy is learned, due to a lack of knowledge about the geomagnetic characteristics in newly entered areas. This paper explores the generalization of learned geomagnetic navigation strategies via deep reinforcement learning (DRL). Particularly, we employ DRL agents to learn multiple teacher models from distributed domains that represent dispersed navigation strategies, and amalgamate the teacher models for generalizability across navigation areas. We design a reward shaping mechanism in training teacher models where we integrate both potential-based and intrinsic-motivated rewards. The designed reward shaping can enhance the exploration efficiency of the DRL agent and improve the representation of the teacher models. Upon the gained teacher models, we employ multi-teacher policy distillation to merge the policies learned by individual teachers, leading to a navigation strategy with generalizability across navigation domains. We conduct numerical simulations, and the results demonstrate an effective transfer of the learned DRL model from a source domain to new navigation areas. Compared to existing evolutionary-based geomagnetic navigation methods, our approach provides superior performance in terms of navigation length, duration, heading deviation, and success rate in cross-domain navigation.
Unispeaker: A Unified Approach for Multimodality-driven Speaker Generation
Jan 11, 2025



Recent advancements in personalized speech generation have brought synthetic speech increasingly close to the realism of target speakers' recordings, yet multimodal speaker generation remains on the rise. This paper introduces UniSpeaker, a unified approach for multimodality-driven speaker generation. Specifically, we propose a unified voice aggregator based on KV-Former, applying soft contrastive loss to map diverse voice description modalities into a shared voice space, ensuring that the generated voice aligns more closely with the input descriptions. To evaluate multimodality-driven voice control, we build the first multimodality-based voice control (MVC) benchmark, focusing on voice suitability, voice diversity, and speech quality. UniSpeaker is evaluated across five tasks using the MVC benchmark, and the experimental results demonstrate that UniSpeaker outperforms previous modality-specific models. Speech samples are available at \url{https://UniSpeaker.github.io}.
MinMo: A Multimodal Large Language Model for Seamless Voice Interaction
Jan 10, 2025



Recent advancements in large language models (LLMs) and multimodal speech-text models have laid the groundwork for seamless voice interactions, enabling real-time, natural, and human-like conversations. Previous models for voice interactions are categorized as native and aligned. Native models integrate speech and text processing in one framework but struggle with issues like differing sequence lengths and insufficient pre-training. Aligned models maintain text LLM capabilities but are often limited by small datasets and a narrow focus on speech tasks. In this work, we introduce MinMo, a Multimodal Large Language Model with approximately 8B parameters for seamless voice interaction. We address the main limitations of prior aligned multimodal models. We train MinMo through multiple stages of speech-to-text alignment, text-to-speech alignment, speech-to-speech alignment, and duplex interaction alignment, on 1.4 million hours of diverse speech data and a broad range of speech tasks. After the multi-stage training, MinMo achieves state-of-the-art performance across various benchmarks for voice comprehension and generation while maintaining the capabilities of text LLMs, and also facilitates full-duplex conversation, that is, simultaneous two-way communication between the user and the system. Moreover, we propose a novel and simple voice decoder that outperforms prior models in voice generation. The enhanced instruction-following capabilities of MinMo supports controlling speech generation based on user instructions, with various nuances including emotions, dialects, and speaking rates, and mimicking specific voices. For MinMo, the speech-to-text latency is approximately 100ms, full-duplex latency is approximately 600ms in theory and 800ms in practice. The MinMo project web page is https://funaudiollm.github.io/minmo, and the code and models will be released soon.
Hardware-in-the-loop Simulation Testbed for Geomagnetic Navigation
Dec 16, 2024



Geomagnetic navigation leverages the ubiquitous Earth's magnetic signals to navigate missions, without dependence on GPS services or pre-stored geographic maps. It has drawn increasing attention and is promising particularly for long-range navigation into unexplored areas. Current geomagnetic navigation studies are still in the early stages with simulations and computational validations, without concrete efforts to develop cost-friendly test platforms that can empower deployment and experimental analysis of the developed approaches. This paper presents a hardware-in-the-loop simulation testbed to support geomagnetic navigation experimentation. Our testbed is dedicated to synthesizing geomagnetic field environment for the navigation. We develop the software in the testbed to simulate the dynamics of the navigation environment, and we build the hardware to generate the physical magnetic field, which follows and aligns with the simulated environment. The testbed aims to provide controllable magnetic field that can be used to experiment with geomagnetic navigation in labs, thus avoiding real and expensive navigation experiments, e.g., in the ocean, for validating navigation prototypes. We build the testbed with off-the-shelf hardware in an unshielded environment to reduce cost. We also develop the field generation control and hardware parameter optimization for quality magnetic field generation. We conduct a detailed performance analysis to show the quality of the field generation by the testbed, and we report the experimental results on performance indicators, including accuracy, uniformity, stability, and convergence of the generated field towards the target geomagnetic environment.
CosyVoice 2: Scalable Streaming Speech Synthesis with Large Language Models
Dec 13, 2024



In our previous work, we introduced CosyVoice, a multilingual speech synthesis model based on supervised discrete speech tokens. By employing progressive semantic decoding with two popular generative models, language models (LMs) and Flow Matching, CosyVoice demonstrated high prosody naturalness, content consistency, and speaker similarity in speech in-context learning. Recently, significant progress has been made in multi-modal large language models (LLMs), where the response latency and real-time factor of speech synthesis play a crucial role in the interactive experience. Therefore, in this report, we present an improved streaming speech synthesis model, CosyVoice 2, which incorporates comprehensive and systematic optimizations. Specifically, we introduce finite-scalar quantization to improve the codebook utilization of speech tokens. For the text-speech LM, we streamline the model architecture to allow direct use of a pre-trained LLM as the backbone. In addition, we develop a chunk-aware causal flow matching model to support various synthesis scenarios, enabling both streaming and non-streaming synthesis within a single model. By training on a large-scale multilingual dataset, CosyVoice 2 achieves human-parity naturalness, minimal response latency, and virtually lossless synthesis quality in the streaming mode. We invite readers to listen to the demos at https://funaudiollm.github.io/cosyvoice2.
Anti-Forgetting Adaptation for Unsupervised Person Re-identification
Nov 22, 2024



Regular unsupervised domain adaptive person re-identification (ReID) focuses on adapting a model from a source domain to a fixed target domain. However, an adapted ReID model can hardly retain previously-acquired knowledge and generalize to unseen data. In this paper, we propose a Dual-level Joint Adaptation and Anti-forgetting (DJAA) framework, which incrementally adapts a model to new domains without forgetting source domain and each adapted target domain. We explore the possibility of using prototype and instance-level consistency to mitigate the forgetting during the adaptation. Specifically, we store a small number of representative image samples and corresponding cluster prototypes in a memory buffer, which is updated at each adaptation step. With the buffered images and prototypes, we regularize the image-to-image similarity and image-to-prototype similarity to rehearse old knowledge. After the multi-step adaptation, the model is tested on all seen domains and several unseen domains to validate the generalization ability of our method. Extensive experiments demonstrate that our proposed method significantly improves the anti-forgetting, generalization and backward-compatible ability of an unsupervised person ReID model.