 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Tri-Dynamic Preprocessing Framework for UGC Video Compression
Dec 18, 2025



In recent years, user generated content (UGC) has become the dominant force in internet traffic. However, UGC videos exhibit a higher degree of variability and diverse characteristics compared to traditional encoding test videos. This variance challenges the effectiveness of data-driven machine learning algorithms for optimizing encoding in the broader context of UGC scenarios. To address this issue, we propose a Tri-Dynamic Preprocessing framework for UGC. Firstly, we employ an adaptive factor to regulate preprocessing intensity. Secondly, an adaptive quantization level is employed to fine-tune the codec simulator. Thirdly, we utilize an adaptive lambda tradeoff to adjust the rate-distortion loss function. Experimental results on large-scale test sets demonstrate that our method attains exceptional performance.
Audio-Visual Cross-Modal Compression for Generative Face Video Coding
Dec 17, 2025Generative face video coding (GFVC) is vital for modern applications like video conferencing, yet existing methods primarily focus on video motion while neglecting the significant bitrate contribution of audio. Despite the well-established correlation between audio and lip movements, this cross-modal coherence has not been systematically exploited for compression. To address this, we propose an Audio-Visual Cross-Modal Compression (AVCC) framework that jointly compresses audio and video streams. Our framework extracts motion information from video and tokenizes audio features, then aligns them through a unified audio-video diffusion process. This allows synchronized reconstruction of both modalities from a shared representation. In extremely low-rate scenarios, AVCC can even reconstruct one modality from the other. Experiments show that AVCC significantly outperforms the Versatile Video Coding (VVC) standard and state-of-the-art GFVC schemes in rate-distortion performance, paving the way for more efficient multimodal communication systems.
A Preprocessing Framework for Video Machine Vision under Compression
Dec 17, 2025



There has been a growing trend in compressing and transmitting videos from terminals for machine vision tasks. Nevertheless, most video coding optimization method focus on minimizing distortion according to human perceptual metrics, overlooking the heightened demands posed by machine vision systems. In this paper, we propose a video preprocessing framework tailored for machine vision tasks to address this challenge. The proposed method incorporates a neural preprocessor which retaining crucial information for subsequent tasks, resulting in the boosting of rate-accuracy performance. We further introduce a differentiable virtual codec to provide constraints on rate and distortion during the training stage. We directly apply widely used standard codecs for testing. Therefore, our solution can be easily applied to real-world scenarios. We conducted extensive experiments evaluating our compression method on two typical downstream tasks with various backbone networks. The experimental results indicate that our approach can save over 15% of bitrate compared to using only the standard codec anchor version.
Generative Preprocessing for Image Compression with Pre-trained Diffusion Models
Dec 17, 2025Preprocessing is a well-established technique for optimizing compression, yet existing methods are predominantly Rate-Distortion (R-D) optimized and constrained by pixel-level fidelity. This work pioneers a shift towards Rate-Perception (R-P) optimization by, for the first time, adapting a large-scale pre-trained diffusion model for compression preprocessing. We propose a two-stage framework: first, we distill the multi-step Stable Diffusion 2.1 into a compact, one-step image-to-image model using Consistent Score Identity Distillation (CiD). Second, we perform a parameter-efficient fine-tuning of the distilled model's attention modules, guided by a Rate-Perception loss and a differentiable codec surrogate. Our method seamlessly integrates with standard codecs without any modification and leverages the model's powerful generative priors to enhance texture and mitigate artifacts. Experiments show substantial R-P gains, achieving up to a 30.13% BD-rate reduction in DISTS on the Kodak dataset and delivering superior subjective visual quality.
Region-Adaptive Video Sharpening via Rate-Perception Optimization
Aug 12, 2025



Sharpening is a widely adopted video enhancement technique. However, uniform sharpening intensity ignores texture variations, degrading video quality. Sharpening also increases bitrate, and there's a lack of techniques to optimally allocate these additional bits across diverse regions. Thus, this paper proposes RPO-AdaSharp, an end-to-end region-adaptive video sharpening model for both perceptual enhancement and bitrate savings. We use the coding tree unit (CTU) partition mask as prior information to guide and constrain the allocation of increased bits. Experiments on benchmarks demonstrate the effectiveness of the proposed model qualitatively and quantitatively.
Adaptive High-Frequency Preprocessing for Video Coding
Aug 12, 2025
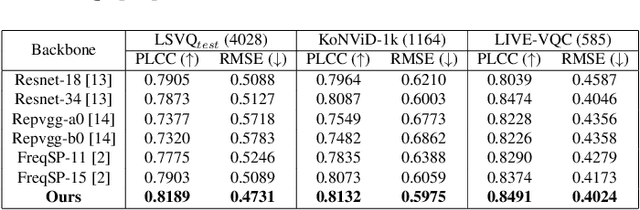
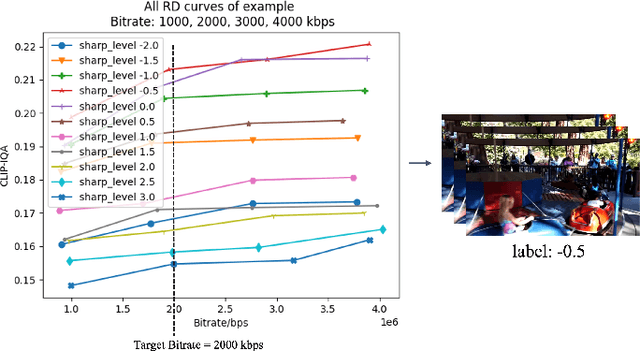
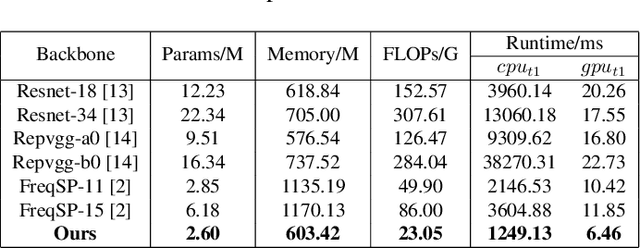
High-frequency components are crucial for maintaining video clarity and realism, but they also significantly impact coding bitrate, resulting in increased bandwidth and storage costs. This paper presents an end-to-end learning-based framework for adaptive high-frequency preprocessing to enhance subjective quality and save bitrate in video coding. The framework employs the Frequency-attentive Feature pyramid Prediction Network (FFPN) to predict the optimal high-frequency preprocessing strategy, guiding subsequent filtering operators to achieve the optimal tradeoff between bitrate and quality after compression. For training FFPN, we pseudo-label each training video with the optimal strategy, determined by comparing the rate-distortion (RD) performance across different preprocessing types and strengths. Distortion is measured using the latest quality assessment metric. Comprehensive evaluations on multiple datasets demonstrate the visually appealing enhancement capabilities and bitrate savings achieved by our framework.
Frequency-Assisted Adaptive Sharpening Scheme Considering Bitrate and Quality Tradeoff
Aug 12, 2025Sharpening is a widely adopted technique to improve video quality, which can effectively emphasize textures and alleviate blurring. However, increasing the sharpening level comes with a higher video bitrate, resulting in degraded Quality of Service (QoS). Furthermore, the video quality does not necessarily improve with increasing sharpening levels, leading to issues such as over-sharpening. Clearly, it is essential to figure out how to boost video quality with a proper sharpening level while also controlling bandwidth costs effectively. This paper thus proposes a novel Frequency-assisted Sharpening level Prediction model (FreqSP). We first label each video with the sharpening level correlating to the optimal bitrate and quality tradeoff as ground truth. Then taking uncompressed source videos as inputs, the proposed FreqSP leverages intricate CNN features and high-frequency components to estimate the optimal sharpening level. Extensive experiments demonstrate the effectiveness of our method.
MIND-Edit: MLLM Insight-Driven Editing via Language-Vision Projection
May 25, 2025Recent advances in AI-generated content (AIGC) have significantly accelerated image editing techniques, driving increasing demand for diverse and fine-grained edits. Despite these advances, existing image editing methods still face challenges in achieving high precision and semantic accuracy in complex scenarios. Recent studies address this issue by incorporating multimodal large language models (MLLMs) into image editing pipelines. However, current MLLM-based methods mainly rely on interpreting textual instructions, leaving the intrinsic visual understanding of large models largely unexplored, thus resulting in insufficient alignment between textual semantics and visual outcomes. To overcome these limitations, we propose MIND-Edit, an end-to-end image-editing framework integrating pretrained diffusion model with MLLM. MIND-Edit introduces two complementary strategies: (1) a text instruction optimization strategy that clarifies ambiguous user instructions based on semantic reasoning from the MLLM, and (2) an MLLM insight-driven editing strategy that explicitly leverages the intrinsic visual understanding capability of the MLLM to infer editing intent and guide the diffusion process via generated visual embeddings. Furthermore, we propose a joint training approach to effectively integrate both strategies, allowing them to reinforce each other for more accurate instruction interpretation and visually coherent edits aligned with user intent. Extensive experiments demonstrate that MIND-Edit outperforms state-of-the-art image editing methods in both quantitative metrics and visual quality, particularly under complex and challenging scenarios.
NTIRE 2025 Challenge on UGC Video Enhancement: Methods and Results
May 05, 2025This paper presents an overview of the NTIRE 2025 Challenge on UGC Video Enhancement. The challenge constructed a set of 150 user-generated content videos without reference ground truth, which suffer from real-world degradations such as noise, blur, faded colors, compression artifacts, etc. The goal of the participants was to develop an algorithm capable of improving the visual quality of such videos. Given the widespread use of UGC on short-form video platforms, this task holds substantial practical importance. The evaluation was based on subjective quality assessment in crowdsourcing, obtaining votes from over 8000 assessors. The challenge attracted more than 25 teams submitting solutions, 7 of which passed the final phase with source code verification. The outcomes may provide insights into the state-of-the-art in UGC video enhancement and highlight emerging trends and effective strategies in this evolving research area. All data, including the processed videos and subjective comparison votes and scores, is made publicly available at https://github.com/msu-video-group/NTIRE25_UGC_Video_Enhancement.
Prefill-Based Jailbreak: A Novel Approach of Bypassing LLM Safety Boundary
Apr 28, 2025Large Language Models (LLMs) are designed to generate helpful and safe content. However, adversarial attacks, commonly referred to as jailbreak, can bypass their safety protocols, prompting LLMs to generate harmful content or reveal sensitive data. Consequently, investigating jailbreak methodologies is crucial for exposing systemic vulnerabilities within LLMs, ultimately guiding the continuous implementation of security enhancements by developers. In this paper, we introduce a novel jailbreak attack method that leverages the prefilling feature of LLMs, a feature designed to enhance model output constraints. Unlike traditional jailbreak methods, the proposed attack circumvents LLMs' safety mechanisms by directly manipulating the probability distribution of subsequent tokens, thereby exerting control over the model's output. We propose two attack variants: Static Prefilling (SP), which employs a universal prefill text, and Optimized Prefilling (OP), which iteratively optimizes the prefill text to maximize the attack success rate. Experiments on six state-of-the-art LLMs using the AdvBench benchmark validate the effectiveness of our method and demonstrate its capability to substantially enhance attack success rates when combined with existing jailbreak approaches. The OP method achieved attack success rates of up to 99.82% on certain models, significantly outperforming baseline methods. This work introduces a new jailbreak attack method in LLMs, emphasizing the need for robust content validation mechanisms to mitigate the adversarial exploitation of prefilling features. All code and data used in this paper are publicly available.