 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrefill-Based Jailbreak: A Novel Approach of Bypassing LLM Safety Boundary
Apr 28, 2025Large Language Models (LLMs) are designed to generate helpful and safe content. However, adversarial attacks, commonly referred to as jailbreak, can bypass their safety protocols, prompting LLMs to generate harmful content or reveal sensitive data. Consequently, investigating jailbreak methodologies is crucial for exposing systemic vulnerabilities within LLMs, ultimately guiding the continuous implementation of security enhancements by developers. In this paper, we introduce a novel jailbreak attack method that leverages the prefilling feature of LLMs, a feature designed to enhance model output constraints. Unlike traditional jailbreak methods, the proposed attack circumvents LLMs' safety mechanisms by directly manipulating the probability distribution of subsequent tokens, thereby exerting control over the model's output. We propose two attack variants: Static Prefilling (SP), which employs a universal prefill text, and Optimized Prefilling (OP), which iteratively optimizes the prefill text to maximize the attack success rate. Experiments on six state-of-the-art LLMs using the AdvBench benchmark validate the effectiveness of our method and demonstrate its capability to substantially enhance attack success rates when combined with existing jailbreak approaches. The OP method achieved attack success rates of up to 99.82% on certain models, significantly outperforming baseline methods. This work introduces a new jailbreak attack method in LLMs, emphasizing the need for robust content validation mechanisms to mitigate the adversarial exploitation of prefilling features. All code and data used in this paper are publicly available.
EG-GAN: Cross-Language Emotion Gain Synthesis based on Cycle-Consistent Adversarial Networks
May 27, 2019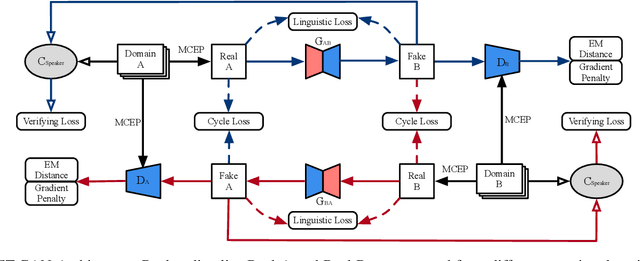
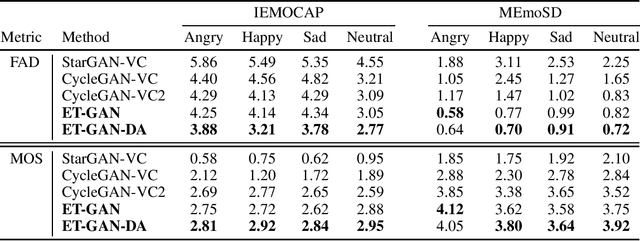
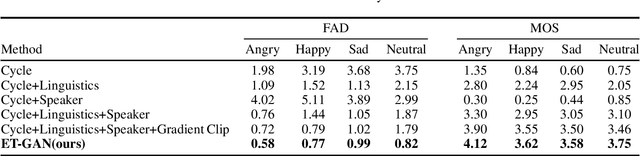

Despite remarkable contributions from existing emotional speech synthesizers, we find that these methods are based on Text-to-Speech system or limited by aligned speech pairs, which suffered from pure emotion gain synthesis. Meanwhile, few studies have discussed the cross-language generalization ability of above methods to cope with the task of emotional speech synthesis in various languages. We propose a cross-language emotion gain synthesis method named EG-GAN which can learn a language-independent mapping from source emotion domain to target emotion domain in the absence of paired speech samples. EG-GAN is based on cycle-consistent generation adversarial network with a gradient penalty and an auxiliary speaker discriminator. The domain adaptation is introduced to implement the rapid migrating and sharing of emotional gains among different languages. The experiment results show that our method can efficiently synthesize high quality emotional speech from any source speech for given emotion categories, without the limitation of language differences and aligned speech pairs.