 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained Distribution-Dependent Learning Curves
Aug 31, 2022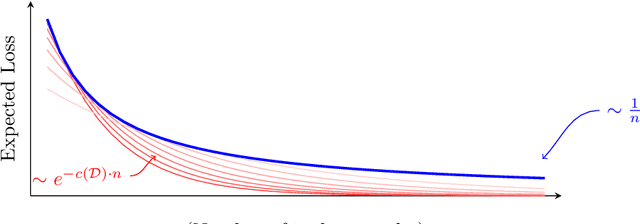
Learning curves plot the expected error of a learning algorithm as a function of the number of labeled input samples. They are widely used by machine learning practitioners as a measure of an algorithm's performance, but classic PAC learning theory cannot explain their behavior. In this paper we introduce a new combinatorial characterization called the VCL dimension that improves and refines the recent results of Bousquet et al. (2021). Our characterization sheds new light on the structure of learning curves by providing fine-grained bounds, and showing that for classes with finite VCL, the rate of decay can be decomposed into a linear component that depends only on the hypothesis class and an exponential component that depends also on the target distribution. In particular, the finer nuance of the VCL dimension implies lower bounds that are quantitatively stronger than the bounds of Bousquet et al. (2021) and qualitatively stronger than classic 'no free lunch' lower bounds. The VCL characterization solves an open problem studied by Antos and Lugosi (1998), who asked in what cases such lower bounds exist. As a corollary, we recover their lower bound for half-spaces in $\mathbb{R}^d$, and we do so in a principled way that should be applicable to other cases as well. Finally, to provide another viewpoint on our work and how it compares to traditional PAC learning bounds, we also present an alternative formulation of our results in a language that is closer to the PAC setting.
Integral Probability Metrics PAC-Bayes Bounds
Jul 06, 2022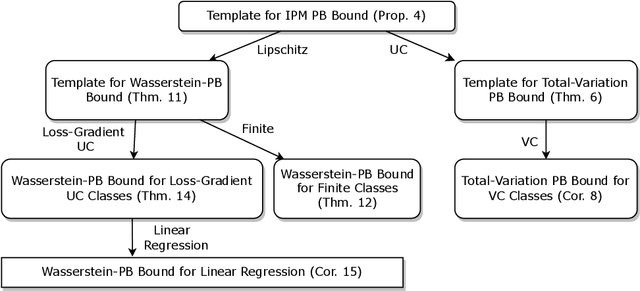
We present a PAC-Bayes-style generalization bound which enables the replacement of the KL-divergence with a variety of Integral Probability Metrics (IPM). We provide instances of this bound with the IPM being the total variation metric and the Wasserstein distance. A notable feature of the obtained bounds is that they naturally interpolate between classical uniform convergence bounds in the worst case (when the prior and posterior are far away from each other), and preferable bounds in better cases (when the posterior and prior are close). This illustrates the possibility of reinforcing classical generalization bounds with algorithm- and data-dependent components, thus making them more suitable to analyze algorithms that use a large hypothesis space.
Understanding Generalization via Leave-One-Out Conditional Mutual Information
Jun 29, 2022
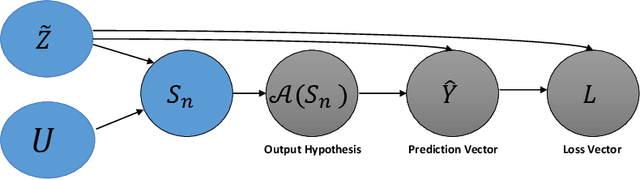
We study the mutual information between (certain summaries of) the output of a learning algorithm and its $n$ training data, conditional on a supersample of $n+1$ i.i.d. data from which the training data is chosen at random without replacement. These leave-one-out variants of the conditional mutual information (CMI) of an algorithm (Steinke and Zakynthinou, 2020) are also seen to control the mean generalization error of learning algorithms with bounded loss functions. For learning algorithms achieving zero empirical risk under 0-1 loss (i.e., interpolating algorithms), we provide an explicit connection between leave-one-out CMI and the classical leave-one-out error estimate of the risk. Using this connection, we obtain upper and lower bounds on risk in terms of the (evaluated) leave-one-out CMI. When the limiting risk is constant or decays polynomially, the bounds converge to within a constant factor of two. As an application, we analyze the population risk of the one-inclusion graph algorithm, a general-purpose transductive learning algorithm for VC classes in the realizable setting. Using leave-one-out CMI, we match the optimal bound for learning VC classes in the realizable setting, answering an open challenge raised by Steinke and Zakynthinou (2020). Finally, in order to understand the role of leave-one-out CMI in studying generalization, we place leave-one-out CMI in a hierarchy of measures, with a novel unconditional mutual information at the root. For 0-1 loss and interpolating learning algorithms, this mutual information is observed to be precisely the risk.
A Resilient Distributed Boosting Algorithm
Jun 13, 2022Given a learning task where the data is distributed among several parties, communication is one of the fundamental resources which the parties would like to minimize. We present a distributed boosting algorithm which is resilient to a limited amount of noise. Our algorithm is similar to classical boosting algorithms, although it is equipped with a new component, inspired by Impagliazzo's hard-core lemma [Impagliazzo95], adding a robustness quality to the algorithm. We also complement this result by showing that resilience to any asymptotically larger noise is not achievable by a communication-efficient algorithm.
Active Learning with Label Comparisons
Apr 10, 2022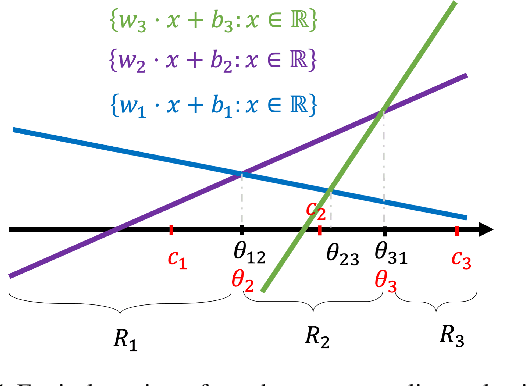
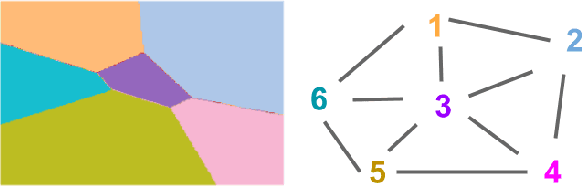
Supervised learning typically relies on manual annotation of the true labels. When there are many potential classes, searching for the best one can be prohibitive for a human annotator. On the other hand, comparing two candidate labels is often much easier. We focus on this type of pairwise supervision and ask how it can be used effectively in learning, and in particular in active learning. We obtain several insightful results in this context. In principle, finding the best of $k$ labels can be done with $k-1$ active queries. We show that there is a natural class where this approach is sub-optimal, and that there is a more comparison-efficient active learning scheme. A key element in our analysis is the "label neighborhood graph" of the true distribution, which has an edge between two classes if they share a decision boundary. We also show that in the PAC setting, pairwise comparisons cannot provide improved sample complexity in the worst case. We complement our theoretical results with experiments, clearly demonstrating the effect of the neighborhood graph on sample complexity.
A Characterization of Multiclass Learnability
Mar 03, 2022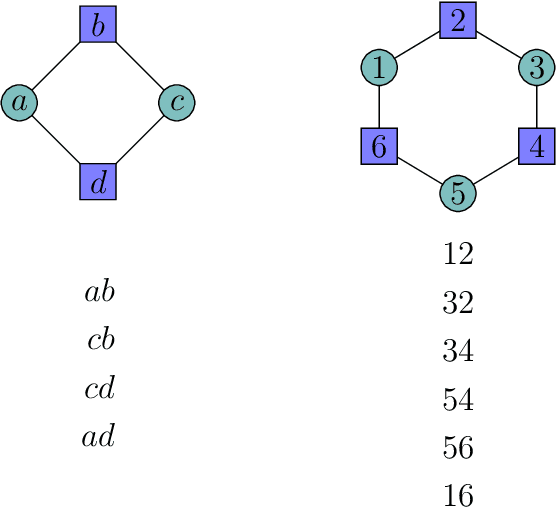
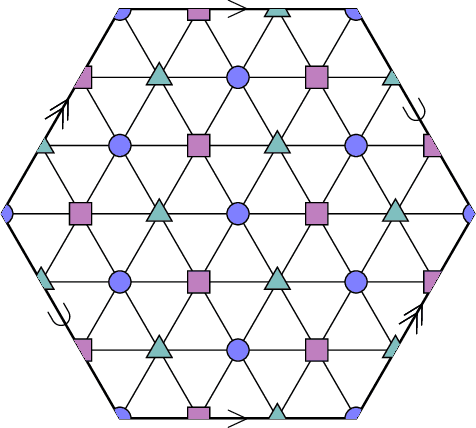
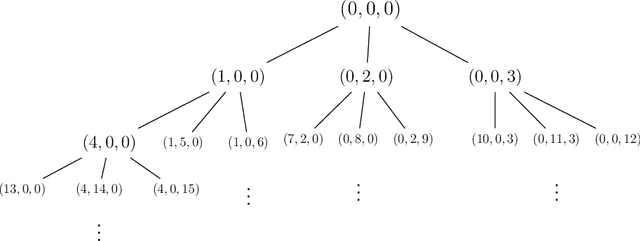
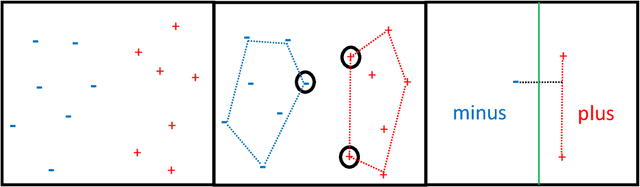
A seminal result in learning theory characterizes the PAC learnability of binary classes through the Vapnik-Chervonenkis dimension. Extending this characterization to the general multiclass setting has been open since the pioneering works on multiclass PAC learning in the late 1980s. This work resolves this problem: we characterize multiclass PAC learnability through the DS dimension, a combinatorial dimension defined by Daniely and Shalev-Shwartz (2014). The classical characterization of the binary case boils down to empirical risk minimization. In contrast, our characterization of the multiclass case involves a variety of algorithmic ideas; these include a natural setting we call list PAC learning. In the list learning setting, instead of predicting a single outcome for a given unseen input, the goal is to provide a short menu of predictions. Our second main result concerns the Natarajan dimension, which has been a central candidate for characterizing multiclass learnability. This dimension was introduced by Natarajan (1988) as a barrier for PAC learning. Whether the Natarajan dimension characterizes PAC learnability in general has been posed as an open question in several papers since. This work provides a negative answer: we construct a non-learnable class with Natarajan dimension one. For the construction, we identify a fundamental connection between concept classes and topology (i.e., colorful simplicial complexes). We crucially rely on a deep and involved construction of hyperbolic pseudo-manifolds by Januszkiewicz and Swiatkowski. It is interesting that hyperbolicity is directly related to learning problems that are difficult to solve although no obvious barriers exist. This is another demonstration of the fruitful links machine learning has with different areas in mathematics.
Monotone Learning
Feb 10, 2022
The amount of training-data is one of the key factors which determines the generalization capacity of learning algorithms. Intuitively, one expects the error rate to decrease as the amount of training-data increases. Perhaps surprisingly, natural attempts to formalize this intuition give rise to interesting and challenging mathematical questions. For example, in their classical book on pattern recognition, Devroye, Gyorfi, and Lugosi (1996) ask whether there exists a {monotone} Bayes-consistent algorithm. This question remained open for over 25 years, until recently Pestov (2021) resolved it for binary classification, using an intricate construction of a monotone Bayes-consistent algorithm. We derive a general result in multiclass classification, showing that every learning algorithm A can be transformed to a monotone one with similar performance. Further, the transformation is efficient and only uses a black-box oracle access to A. This demonstrates that one can provably avoid non-monotonic behaviour without compromising performance, thus answering questions asked by Devroye et al (1996), Viering, Mey, and Loog (2019), Viering and Loog (2021), and by Mhammedi (2021). Our transformation readily implies monotone learners in a variety of contexts: for example it extends Pestov's result to classification tasks with an arbitrary number of labels. This is in contrast with Pestov's work which is tailored to binary classification. In addition, we provide uniform bounds on the error of the monotone algorithm. This makes our transformation applicable in distribution-free settings. For example, in PAC learning it implies that every learnable class admits a monotone PAC learner. This resolves questions by Viering, Mey, and Loog (2019); Viering and Loog (2021); Mhammedi (2021).
Uniform Brackets, Containers, and Combinatorial Macbeath Regions
Nov 19, 2021We study the connections between three seemingly different combinatorial structures - "uniform" brackets in statistics and probability theory, "containers" in online and distributed learning theory, and "combinatorial Macbeath regions", or Mnets in discrete and computational geometry. We show that these three concepts are manifestations of a single combinatorial property that can be expressed under a unified framework along the lines of Vapnik-Chervonenkis type theory for uniform convergence. These new connections help us to bring tools from discrete and computational geometry to prove improved bounds for these objects. Our improved bounds help to get an optimal algorithm for distributed learning of halfspaces, an improved algorithm for the distributed convex set disjointness problem, and improved regret bounds for online algorithms against a smoothed adversary for a large class of semi-algebraic threshold functions.
Towards a Unified Information-Theoretic Framework for Generalization
Nov 17, 2021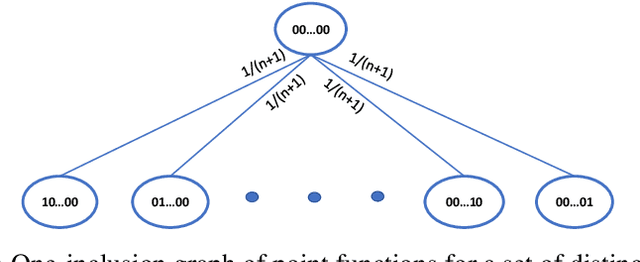
In this work, we investigate the expressiveness of the "conditional mutual information" (CMI) framework of Steinke and Zakynthinou (2020) and the prospect of using it to provide a unified framework for proving generalization bounds in the realizable setting. We first demonstrate that one can use this framework to express non-trivial (but sub-optimal) bounds for any learning algorithm that outputs hypotheses from a class of bounded VC dimension. We prove that the CMI framework yields the optimal bound on the expected risk of Support Vector Machines (SVMs) for learning halfspaces. This result is an application of our general result showing that stable compression schemes Bousquet al. (2020) of size $k$ have uniformly bounded CMI of order $O(k)$. We further show that an inherent limitation of proper learning of VC classes contradicts the existence of a proper learner with constant CMI, and it implies a negative resolution to an open problem of Steinke and Zakynthinou (2020). We further study the CMI of empirical risk minimizers (ERMs) of class $H$ and show that it is possible to output all consistent classifiers (version space) with bounded CMI if and only if $H$ has a bounded star number (Hanneke and Yang (2015)). Moreover, we prove a general reduction showing that "leave-one-out" analysis is expressible via the CMI framework. As a corollary we investigate the CMI of the one-inclusion-graph algorithm proposed by Haussler et al. (1994). More generally, we show that the CMI framework is universal in the sense that for every consistent algorithm and data distribution, the expected risk vanishes as the number of samples diverges if and only if its evaluated CMI has sublinear growth with the number of samples.
Agnostic Online Learning and Excellent Sets
Sep 03, 2021We use algorithmic methods from online learning to revisit a key idea from the interaction of model theory and combinatorics, the existence of large "indivisible" sets, called "$\epsilon$-excellent," in $k$-edge stable graphs (equivalently, Littlestone classes). These sets arise in the Stable Regularity Lemma, a theorem characterizing the appearance of irregular pairs in Szemer\'edi's celebrated Regularity Lemma. Translating to the language of probability, we find a quite different existence proof for $\epsilon$-excellent sets in Littlestone classes, using regret bounds in online learning. This proof applies to any $\epsilon < {1}/{2}$, compared to $< {1}/{2^{2^k}}$ or so in the original proof. We include a second proof using closure properties and the VC theorem, with other advantages but weaker bounds. As a simple corollary, the Littlestone dimension remains finite under some natural modifications to the definition. A theme in these proofs is the interaction of two abstract notions of majority, arising from measure, and from rank or dimension; we prove that these densely often coincide and that this is characteristic of Littlestone (stable) classes. The last section lists several open problems.