 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Demoireing with Learnable Bandpass Filters
Apr 01, 2020
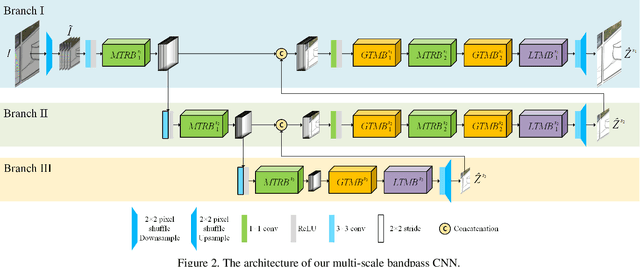

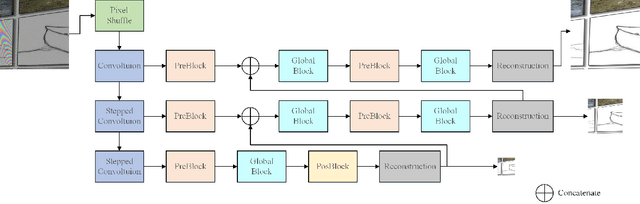
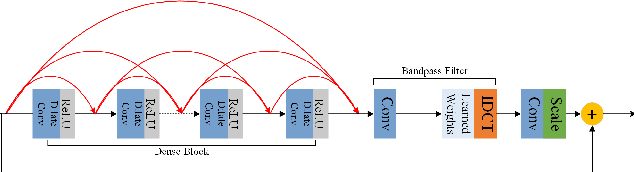
Image demoireing is a multi-faceted image restoration task involving both texture and color restoration. In this paper, we propose a novel multiscale bandpass convolutional neural network (MBCNN) to address this problem. As an end-to-end solution, MBCNN respectively solves the two sub-problems. For texture restoration, we propose a learnable bandpass filter (LBF) to learn the frequency prior for moire texture removal. For color restoration, we propose a two-step tone mapping strategy, which first applies a global tone mapping to correct for a global color shift, and then performs local fine tuning of the color per pixel. Through an ablation study, we demonstrate the effectiveness of the different components of MBCNN. Experimental results on two public datasets show that our method outperforms state-of-the-art methods by a large margin (more than 2dB in terms of PSNR).
AIM 2019 Challenge on Image Demoireing: Methods and Results
Nov 08, 2019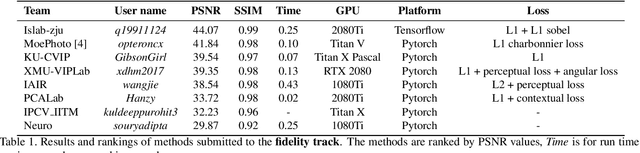
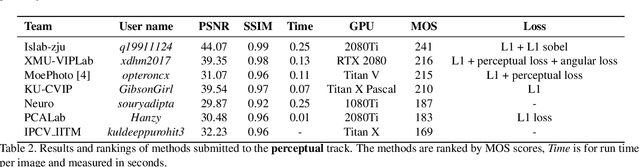
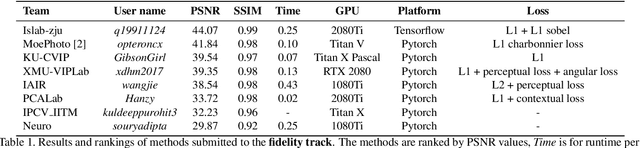
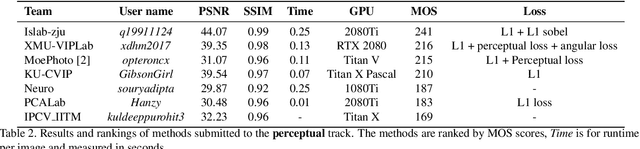
This paper reviews the first-ever image demoireing challenge that was part of the Advances in Image Manipulation (AIM) workshop, held in conjunction with ICCV 2019. This paper describes the challenge, and focuses on the proposed solutions and their results. Demoireing is a difficult task of removing moire patterns from an image to reveal an underlying clean image. A new dataset, called LCDMoire was created for this challenge, and consists of 10,200 synthetically generated image pairs (moire and clean ground truth). The challenge was divided into 2 tracks. Track 1 targeted fidelity, measuring the ability of demoire methods to obtain a moire-free image compared with the ground truth, while Track 2 examined the perceptual quality of demoire methods. The tracks had 60 and 39 registered participants, respectively. A total of eight teams competed in the final testing phase. The entries span the current the state-of-the-art in the image demoireing problem.
AIM 2019 Challenge on Image Demoireing: Dataset and Study
Nov 06, 2019

This paper introduces a novel dataset, called LCDMoire, which was created for the first-ever image demoireing challenge that was part of the Advances in Image Manipulation (AIM) workshop, held in conjunction with ICCV 2019. The dataset comprises 10,200 synthetically generated image pairs (consisting of an image degraded by moire and a clean ground truth image). In addition to describing the dataset and its creation, this paper also reviews the challenge tracks, competition, and results, the latter summarizing the current state-of-the-art on this dataset.
RGB-based 3D Hand Pose Estimation via Privileged Learning with Depth Images
Nov 18, 2018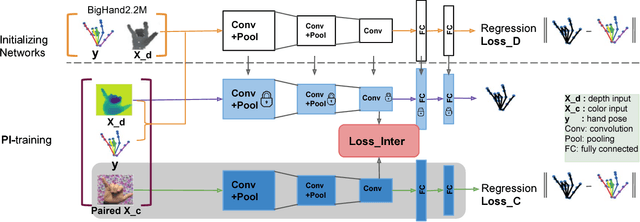
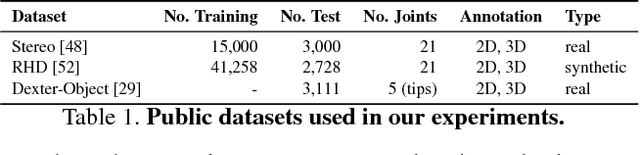
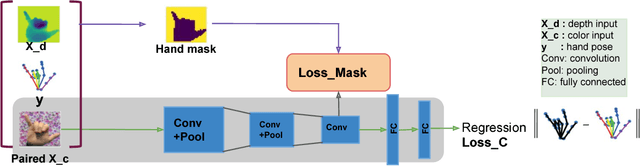
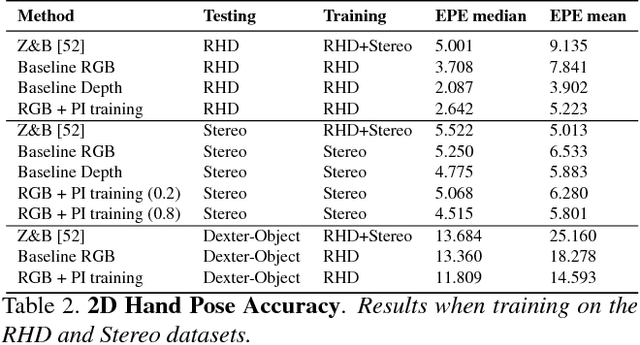
This paper proposes a method for hand pose estimation from RGB images that uses both external large-scale depth image datasets and paired depth and RGB images as privileged information at training time. We show that providing depth information during training significantly improves performance of pose estimation from RGB images during testing. We explore different ways of using this privileged information: (1) using depth data to initially train a depth-based network, (2) using the features from the depth-based network of the paired depth images to constrain mid-level RGB network weights, and (3) using the foreground mask, obtained from the depth data, to suppress the responses from the background area. By using paired RGB and depth images, we are able to supervise the RGB-based network to learn middle layer features that mimic that of the corresponding depth-based network, which is trained on large-scale, accurately annotated depth data. During testing, when only an RGB image is available, our method produces accurate 3D hand pose predictions. Our method is also tested on 2D hand pose estimation. Experiments on three public datasets show that the method outperforms the state-of-the-art methods for hand pose estimation using RGB image input.
First-Person Hand Action Benchmark with RGB-D Videos and 3D Hand Pose Annotations
Apr 10, 2018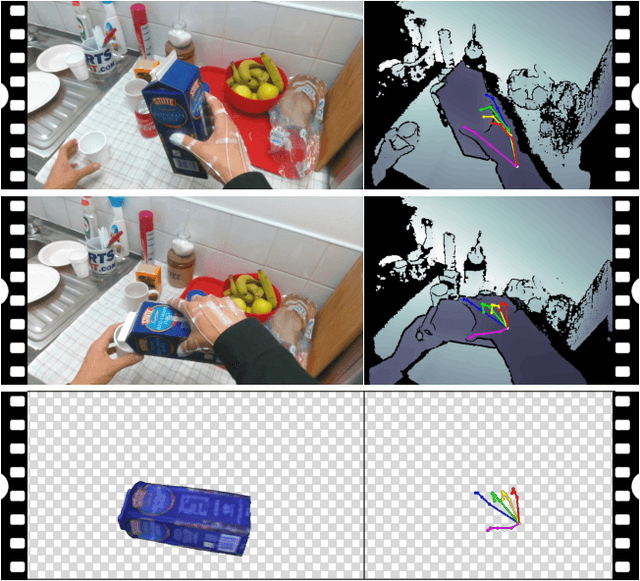
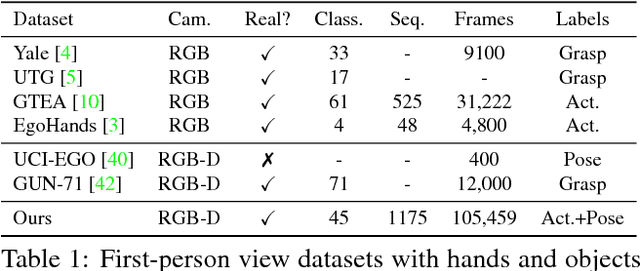

In this work we study the use of 3D hand poses to recognize first-person dynamic hand actions interacting with 3D objects. Towards this goal, we collected RGB-D video sequences comprised of more than 100K frames of 45 daily hand action categories, involving 26 different objects in several hand configurations. To obtain hand pose annotations, we used our own mo-cap system that automatically infers the 3D location of each of the 21 joints of a hand model via 6 magnetic sensors and inverse kinematics. Additionally, we recorded the 6D object poses and provide 3D object models for a subset of hand-object interaction sequences. To the best of our knowledge, this is the first benchmark that enables the study of first-person hand actions with the use of 3D hand poses. We present an extensive experimental evaluation of RGB-D and pose-based action recognition by 18 baselines/state-of-the-art approaches. The impact of using appearance features, poses, and their combinations are measured, and the different training/testing protocols are evaluated. Finally, we assess how ready the 3D hand pose estimation field is when hands are severely occluded by objects in egocentric views and its influence on action recognition. From the results, we see clear benefits of using hand pose as a cue for action recognition compared to other data modalities. Our dataset and experiments can be of interest to communities of 3D hand pose estimation, 6D object pose, and robotics as well as action recognition.
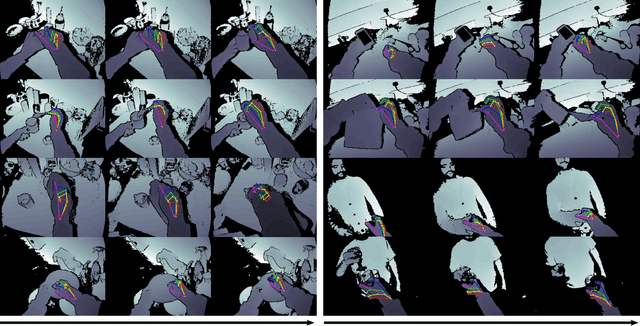
Depth-Based 3D Hand Pose Estimation: From Current Achievements to Future Goals
Mar 29, 2018
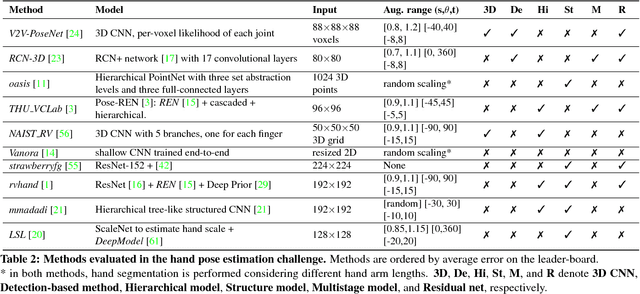
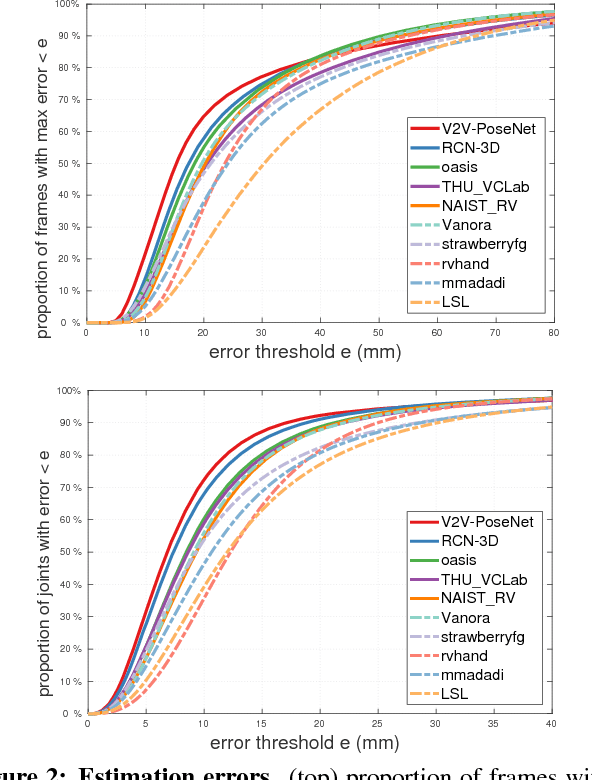
In this paper, we strive to answer two questions: What is the current state of 3D hand pose estimation from depth images? And, what are the next challenges that need to be tackled? Following the successful Hands In the Million Challenge (HIM2017), we investigate the top 10 state-of-the-art methods on three tasks: single frame 3D pose estimation, 3D hand tracking, and hand pose estimation during object interaction. We analyze the performance of different CNN structures with regard to hand shape, joint visibility, view point and articulation distributions. Our findings include: (1) isolated 3D hand pose estimation achieves low mean errors (10 mm) in the view point range of [70, 120] degrees, but it is far from being solved for extreme view points; (2) 3D volumetric representations outperform 2D CNNs, better capturing the spatial structure of the depth data; (3) Discriminative methods still generalize poorly to unseen hand shapes; (4) While joint occlusions pose a challenge for most methods, explicit modeling of structure constraints can significantly narrow the gap between errors on visible and occluded joints.
BigHand2.2M Benchmark: Hand Pose Dataset and State of the Art Analysis
Dec 09, 2017
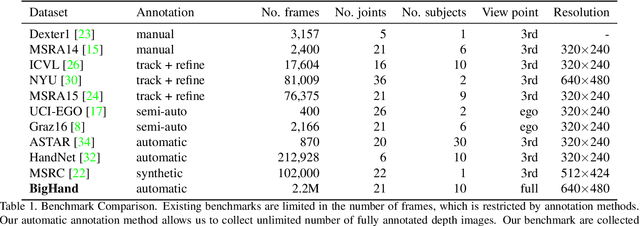
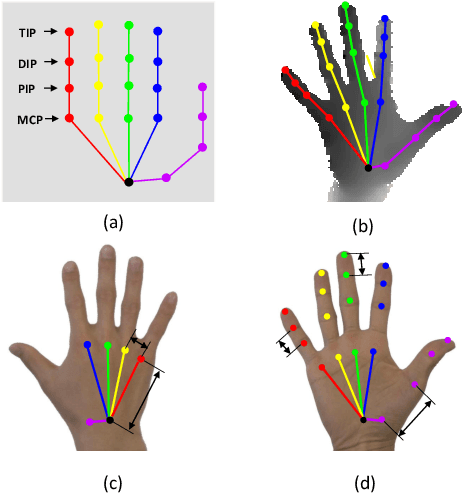

In this paper we introduce a large-scale hand pose dataset, collected using a novel capture method. Existing datasets are either generated synthetically or captured using depth sensors: synthetic datasets exhibit a certain level of appearance difference from real depth images, and real datasets are limited in quantity and coverage, mainly due to the difficulty to annotate them. We propose a tracking system with six 6D magnetic sensors and inverse kinematics to automatically obtain 21-joints hand pose annotations of depth maps captured with minimal restriction on the range of motion. The capture protocol aims to fully cover the natural hand pose space. As shown in embedding plots, the new dataset exhibits a significantly wider and denser range of hand poses compared to existing benchmarks. Current state-of-the-art methods are evaluated on the dataset, and we demonstrate significant improvements in cross-benchmark performance. We also show significant improvements in egocentric hand pose estimation with a CNN trained on the new dataset.
The 2017 Hands in the Million Challenge on 3D Hand Pose Estimation
Jul 07, 2017
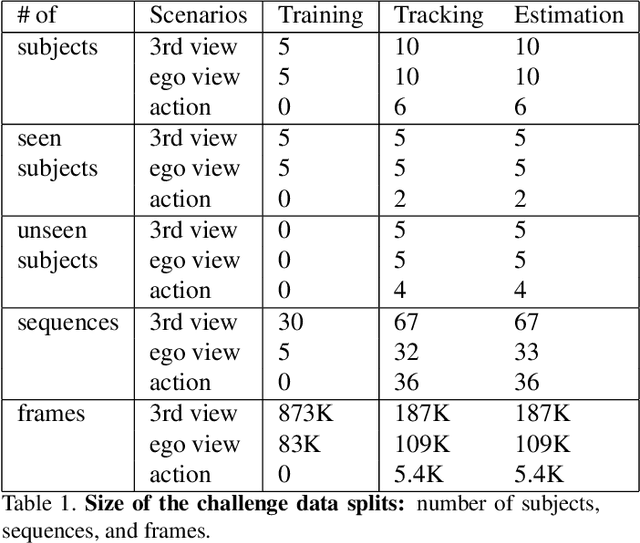

We present the 2017 Hands in the Million Challenge, a public competition designed for the evaluation of the task of 3D hand pose estimation. The goal of this challenge is to assess how far is the state of the art in terms of solving the problem of 3D hand pose estimation as well as detect major failure and strength modes of both systems and evaluation metrics that can help to identify future research directions. The challenge follows up the recent publication of BigHand2.2M and First-Person Hand Action datasets, which have been designed to exhaustively cover multiple hand, viewpoint, hand articulation, and occlusion. The challenge consists of a standardized dataset, an evaluation protocol for two different tasks, and a public competition. In this document we describe the different aspects of the challenge and, jointly with the results of the participants, it will be presented at the 3rd International Workshop on Observing and Understanding Hands in Action, HANDS 2017, with ICCV 2017.
Spatial Attention Deep Net with Partial PSO for Hierarchical Hybrid Hand Pose Estimation
Oct 20, 2016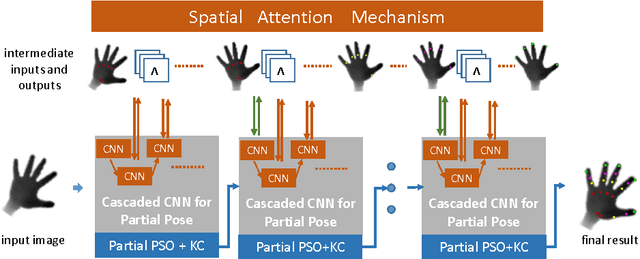
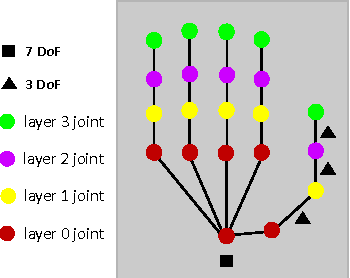
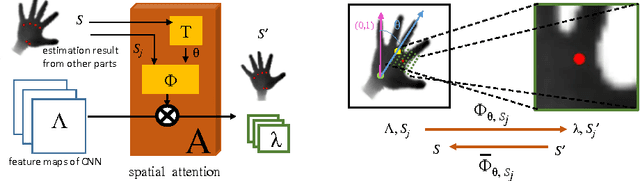
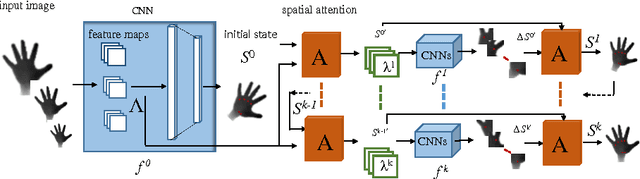
Discriminative methods often generate hand poses kinematically implausible, then generative methods are used to correct (or verify) these results in a hybrid method. Estimating 3D hand pose in a hierarchy, where the high-dimensional output space is decomposed into smaller ones, has been shown effective. Existing hierarchical methods mainly focus on the decomposition of the output space while the input space remains almost the same along the hierarchy. In this paper, a hybrid hand pose estimation method is proposed by applying the kinematic hierarchy strategy to the input space (as well as the output space) of the discriminative method by a spatial attention mechanism and to the optimization of the generative method by hierarchical Particle Swarm Optimization (PSO). The spatial attention mechanism integrates cascaded and hierarchical regression into a CNN framework by transforming both the input(and feature space) and the output space, which greatly reduces the viewpoint and articulation variations. Between the levels in the hierarchy, the hierarchical PSO forces the kinematic constraints to the results of the CNNs. The experimental results show that our method significantly outperforms four state-of-the-art methods and three baselines on three public benchmarks.