 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeP-STMO: Pre-Trained Spatial Temporal Many-to-One Model for 3D Human Pose Estimation
Mar 15, 2022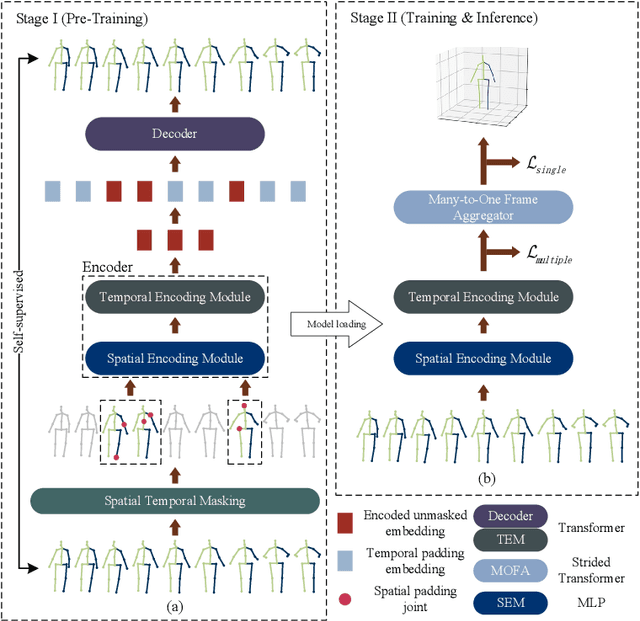
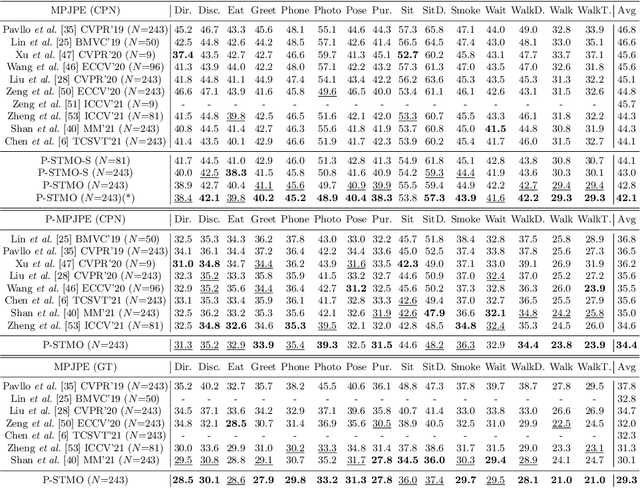

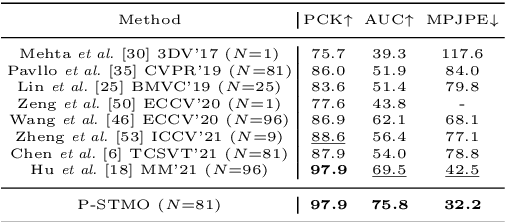
This paper introduces a novel Pre-trained Spatial Temporal Many-to-One (P-STMO) model for 2D-to-3D human pose estimation task. To reduce the difficulty of capturing spatial and temporal information, we divide this task into two stages: pre-training (Stage I) and fine-tuning (Stage II). In Stage I, a self-supervised pre-training sub-task, termed masked pose modeling, is proposed. The human joints in the input sequence are randomly masked in both spatial and temporal domains. A general form of denoising auto-encoder is exploited to recover the original 2D poses and the encoder is capable of capturing spatial and temporal dependencies in this way. In Stage II, the pre-trained encoder is loaded to STMO model and fine-tuned. The encoder is followed by a many-to-one frame aggregator to predict the 3D pose in the current frame. Especially, an MLP block is utilized as the spatial feature extractor in STMO, which yields better performance than other methods. In addition, a temporal downsampling strategy is proposed to diminish data redundancy. Extensive experiments on two benchmarks show that our method outperforms state-of-the-art methods with fewer parameters and less computational overhead. For example, our P-STMO model achieves 42.1mm MPJPE on Human3.6M dataset when using 2D poses from CPN as inputs. Meanwhile, it brings a 1.5-7.1 times speedup to state-of-the-art methods. Code is available at https://github.com/paTRICK-swk/P-STMO.
Cross-SRN: Structure-Preserving Super-Resolution Network with Cross Convolution
Jan 07, 2022



It is challenging to restore low-resolution (LR) images to super-resolution (SR) images with correct and clear details. Existing deep learning works almost neglect the inherent structural information of images, which acts as an important role for visual perception of SR results. In this paper, we design a hierarchical feature exploitation network to probe and preserve structural information in a multi-scale feature fusion manner. First, we propose a cross convolution upon traditional edge detectors to localize and represent edge features. Then, cross convolution blocks (CCBs) are designed with feature normalization and channel attention to consider the inherent correlations of features. Finally, we leverage multi-scale feature fusion group (MFFG) to embed the cross convolution blocks and develop the relations of structural features in different scales hierarchically, invoking a lightweight structure-preserving network named as Cross-SRN. Experimental results demonstrate the Cross-SRN achieves competitive or superior restoration performances against the state-of-the-art methods with accurate and clear structural details. Moreover, we set a criterion to select images with rich structural textures. The proposed Cross-SRN outperforms the state-of-the-art methods on the selected benchmark, which demonstrates that our network has a significant advantage in preserving edges.
Improving Robustness and Accuracy via Relative Information Encoding in 3D Human Pose Estimation
Jul 29, 2021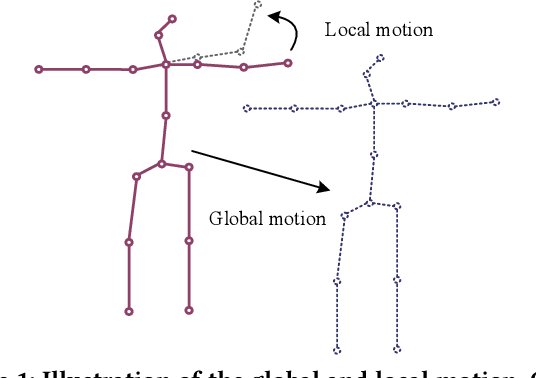
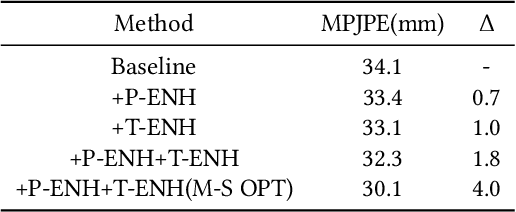
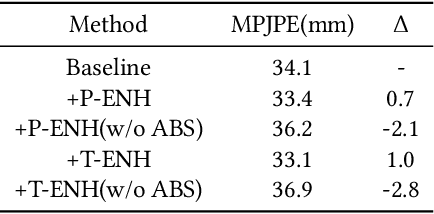
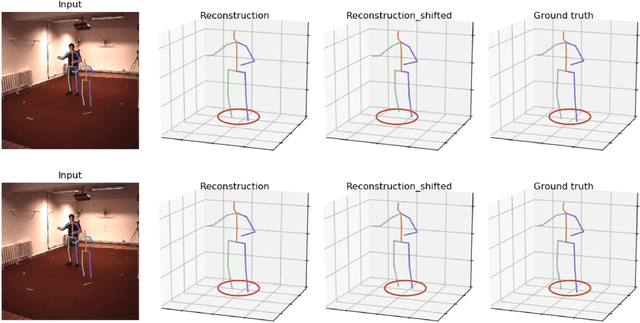
Most of the existing 3D human pose estimation approaches mainly focus on predicting 3D positional relationships between the root joint and other human joints (local motion) instead of the overall trajectory of the human body (global motion). Despite the great progress achieved by these approaches, they are not robust to global motion, and lack the ability to accurately predict local motion with a small movement range. To alleviate these two problems, we propose a relative information encoding method that yields positional and temporal enhanced representations. Firstly, we encode positional information by utilizing relative coordinates of 2D poses to enhance the consistency between the input and output distribution. The same posture with different absolute 2D positions can be mapped to a common representation. It is beneficial to resist the interference of global motion on the prediction results. Second, we encode temporal information by establishing the connection between the current pose and other poses of the same person within a period of time. More attention will be paid to the movement changes before and after the current pose, resulting in better prediction performance on local motion with a small movement range. The ablation studies validate the effectiveness of the proposed relative information encoding method. Besides, we introduce a multi-stage optimization method to the whole framework to further exploit the positional and temporal enhanced representations. Our method outperforms state-of-the-art methods on two public datasets. Code is available at https://github.com/paTRICK-swk/Pose3D-RIE.
Rate Distortion Characteristic Modeling for Neural Image Compression
Jun 24, 2021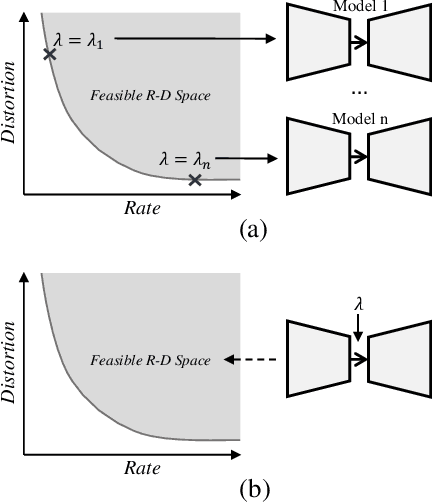

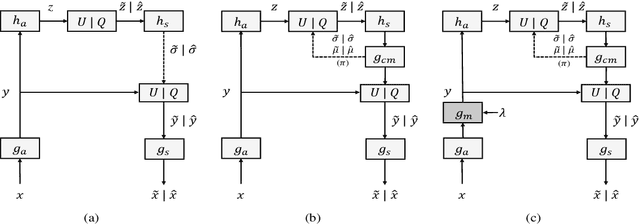
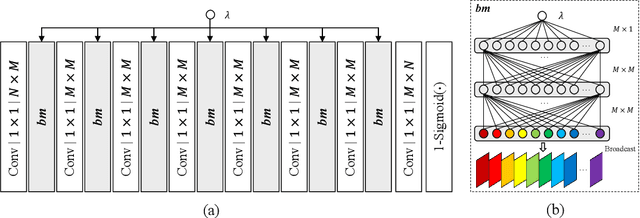
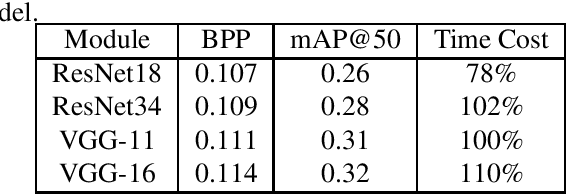
End-to-end optimization capability offers neural image compression (NIC) superior lossy compression performance. However, distinct models are required to be trained to reach different points in the rate-distortion (R-D) space. In this paper, we consider the problem of R-D characteristic analysis and modeling for NIC. We make efforts to formulate the essential mathematical functions to describe the R-D behavior of NIC using deep network and statistical modeling. Thus continuous bit-rate points could be elegantly realized by leveraging such model via a single trained network. In this regard, we propose a plugin-in module to learn the relationship between the target bit-rate and the binary representation for the latent variable of auto-encoder. Furthermore, we model the rate and distortion characteristic of NIC as a function of the coding parameter $\lambda$ respectively. Our experiments show our proposed method is easy to adopt and obtains competitive coding performance with fixed-rate coding approaches, which would benefit the practical deployment of NIC. In addition, the proposed model could be applied to NIC rate control with limited bit-rate error using a single network.
Visual Analysis Motivated Rate-Distortion Model for Image Coding
Apr 21, 2021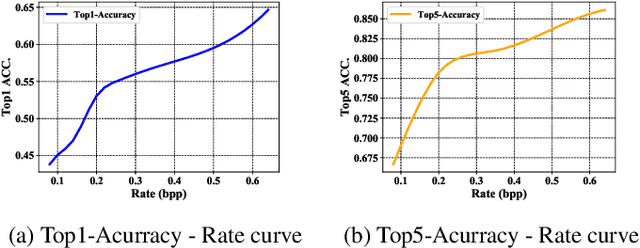
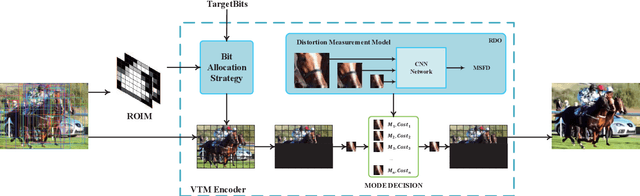

Optimized for pixel fidelity metrics, images compressed by existing image codec are facing systematic challenges when used for visual analysis tasks, especially under low-bitrate coding. This paper proposes a visual analysis-motivated rate-distortion model for Versatile Video Coding (VVC) intra compression. The proposed model has two major contributions, a novel rate allocation strategy and a new distortion measurement model. We first propose the region of interest for machine (ROIM) to evaluate the degree of importance for each coding tree unit (CTU) in visual analysis. Then, a novel CTU-level bit allocation model is proposed based on ROIM and the local texture characteristics of each CTU. After an in-depth analysis of multiple distortion models, a visual analysis friendly distortion criteria is subsequently proposed by extracting deep feature of each coding unit (CU). To alleviate the problem of lacking spatial context information when calculating the distortion of each CU, we finally propose a multi-scale feature distortion (MSFD) metric using different neighboring pixels by weighting the extracted deep features in each scale. Extensive experimental results show that the proposed scheme could achieve up to 28.17\% bitrate saving under the same analysis performance among several typical visual analysis tasks such as image classification, object detection, and semantic segmentation.
Sub-sampled Cross-component Prediction for Emerging Video Coding Standards
Dec 30, 2020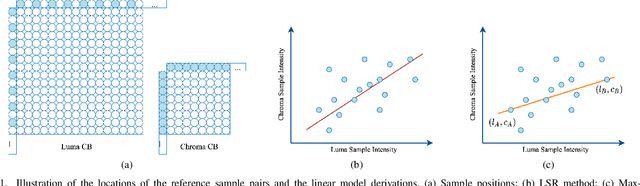
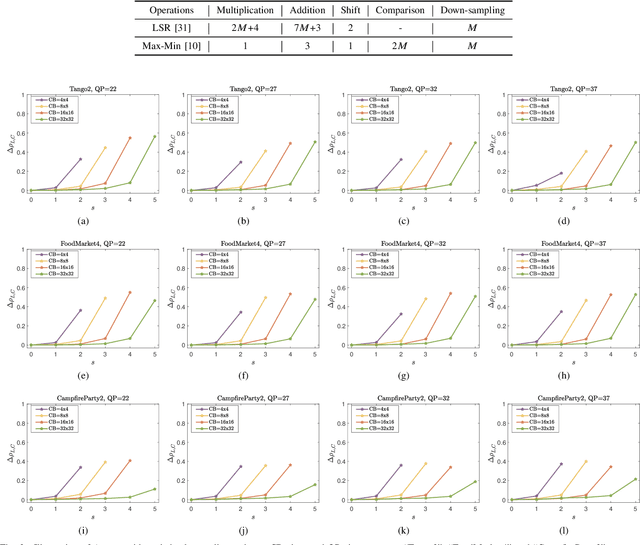
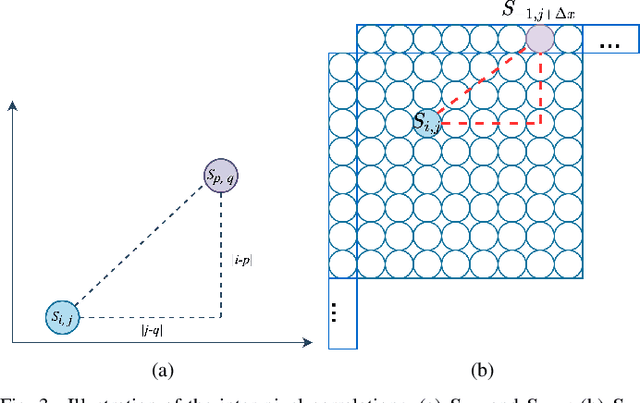

Cross-component linear model (CCLM) prediction has been repeatedly proven to be effective in reducing the inter-channel redundancies in video compression. Essentially speaking, the linear model is identically trained by employing accessible luma and chroma reference samples at both encoder and decoder, elevating the level of operational complexity due to the least square regression or max-min based model parameter derivation. In this paper, we investigate the capability of the linear model in the context of sub-sampled based cross-component correlation mining, as a means of significantly releasing the operation burden and facilitating the hardware and software design for both encoder and decoder. In particular, the sub-sampling ratios and positions are elaborately designed by exploiting the spatial correlation and the inter-channel correlation. Extensive experiments verify that the proposed method is characterized by its simplicity in operation and robustness in terms of rate-distortion performance, leading to the adoption by Versatile Video Coding (VVC) standard and the third generation of Audio Video Coding Standard (AVS3).
Implicit Subspace Prior Learning for Dual-Blind Face Restoration
Oct 12, 2020
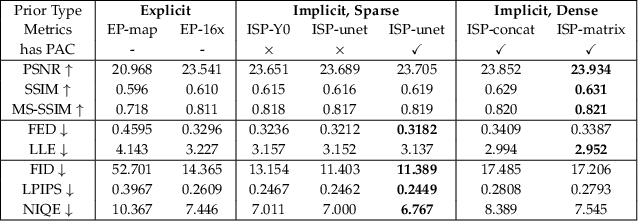


Face restoration is an inherently ill-posed problem, where additional prior constraints are typically considered crucial for mitigating such pathology. However, real-world image prior are often hard to simulate with precise mathematical models, which inevitably limits the performance and generalization ability of existing prior-regularized restoration methods. In this paper, we study the problem of face restoration under a more practical ``dual blind'' setting, i.e., without prior assumptions or hand-crafted regularization terms on the degradation profile or image contents. To this end, a novel implicit subspace prior learning (ISPL) framework is proposed as a generic solution to dual-blind face restoration, with two key elements: 1) an implicit formulation to circumvent the ill-defined restoration mapping and 2) a subspace prior decomposition and fusion mechanism to dynamically handle inputs at varying degradation levels with consistent high-quality restoration results. Experimental results demonstrate significant perception-distortion improvement of ISPL against existing state-of-the-art methods for a variety of restoration subtasks, including a 3.69db PSNR and 45.8% FID gain against ESRGAN, the 2018 NTIRE SR challenge winner. Overall, we prove that it is possible to capture and utilize prior knowledge without explicitly formulating it, which will help inspire new research paradigms towards low-level vision tasks.
Progressive Multi-Scale Residual Network for Single Image Super-Resolution
Jul 19, 2020

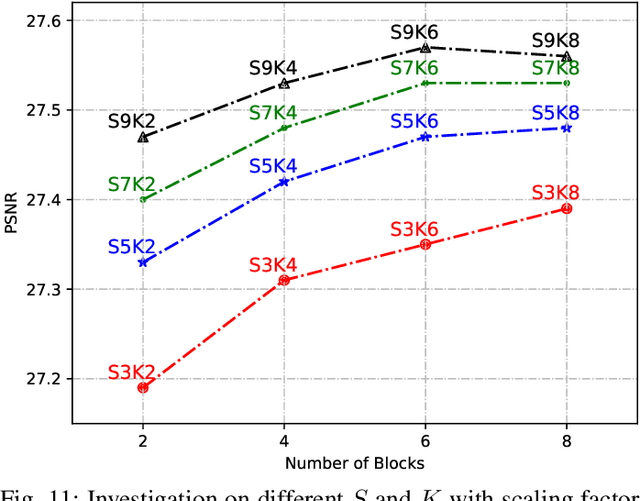
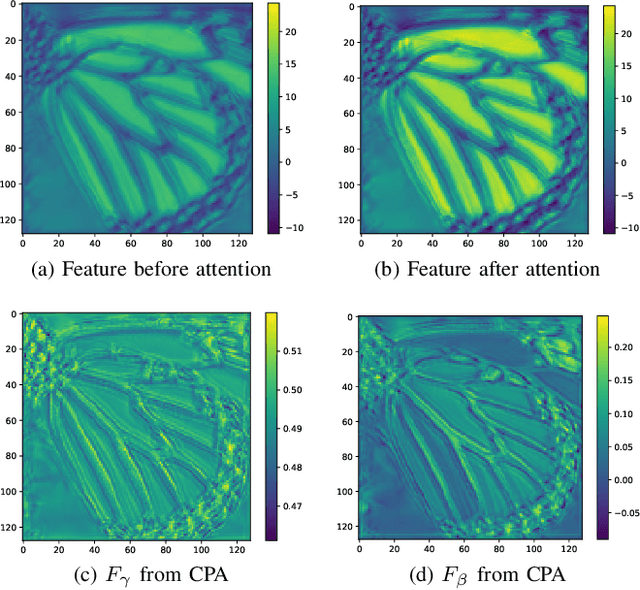
Super-resolution is a classical issue in image restoration field. In recent years, deep learning methods have achieved significant success in super-resolution topic, which concentrate on different elaborate network designs to exploit the image features more effectively. However, most of the networks focus on increasing the depth or width for superior capacities with a large number of parameters, which cause a high computation complexity cost and seldom focus on the inherent correlation of different features. This paper proposes a progressive multi-scale residual network (PMRN) for single image super-resolution problem by sequentially exploiting features with restricted parameters. Specifically, we design a progressive multi-scale residual block (PMRB) to progressively explore the multi-scale features with different layer combinations, aiming to consider the correlations of different scales. The combinations for feature exploitation are defined in a recursive fashion for introducing the non-linearity and better feature representation with limited parameters. Furthermore, we investigate a joint channel-wise and pixel-wise attention mechanism for comprehensive correlation exploration, termed as CPA, which is utilized in PMRB by considering both scale and bias factors for features in parallel. Experimental results show that proposed PMRN recovers structural textures more effectively with superior PSNR/SSIM results than other lightweight works. The extension model PMRN+ with self-ensemble achieves competitive or better results than large networks with much fewer parameters and lower computation complexity.
Towards Fine-grained Human Pose Transfer with Detail Replenishing Network
May 26, 2020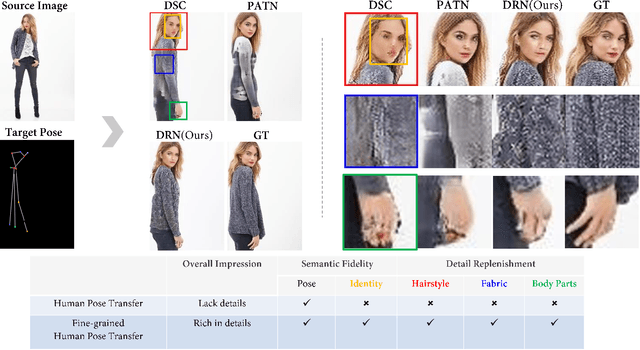
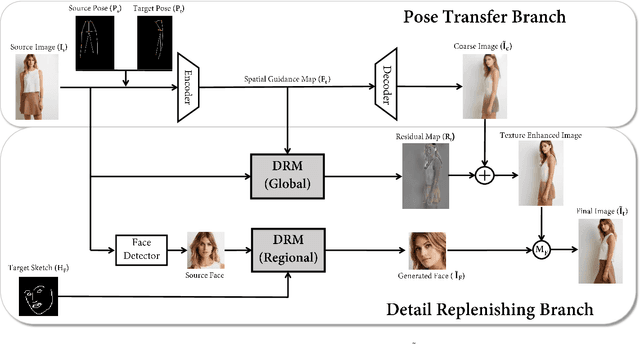
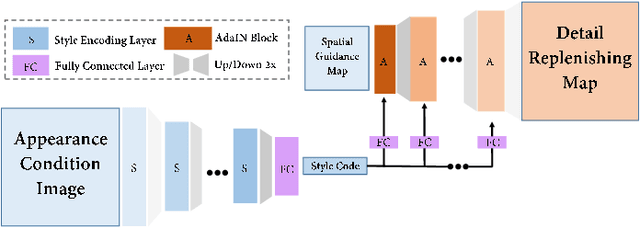

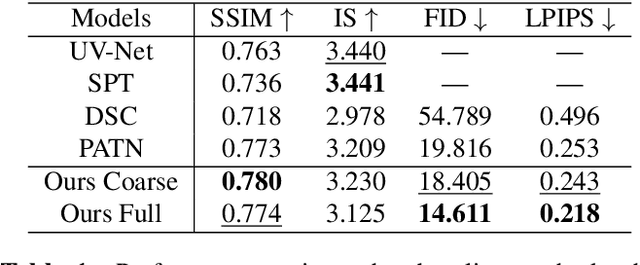
Human pose transfer (HPT) is an emerging research topic with huge potential in fashion design, media production, online advertising and virtual reality. For these applications, the visual realism of fine-grained appearance details is crucial for production quality and user engagement. However, existing HPT methods often suffer from three fundamental issues: detail deficiency, content ambiguity and style inconsistency, which severely degrade the visual quality and realism of generated images. Aiming towards real-world applications, we develop a more challenging yet practical HPT setting, termed as Fine-grained Human Pose Transfer (FHPT), with a higher focus on semantic fidelity and detail replenishment. Concretely, we analyze the potential design flaws of existing methods via an illustrative example, and establish the core FHPT methodology by combing the idea of content synthesis and feature transfer together in a mutually-guided fashion. Thereafter, we substantiate the proposed methodology with a Detail Replenishing Network (DRN) and a corresponding coarse-to-fine model training scheme. Moreover, we build up a complete suite of fine-grained evaluation protocols to address the challenges of FHPT in a comprehensive manner, including semantic analysis, structural detection and perceptual quality assessment. Extensive experiments on the DeepFashion benchmark dataset have verified the power of proposed benchmark against start-of-the-art works, with 12\%-14\% gain on top-10 retrieval recall, 5\% higher joint localization accuracy, and near 40\% gain on face identity preservation. Moreover, the evaluation results offer further insights to the subject matter, which could inspire many promising future works along this direction.
Region-adaptive Texture Enhancement for Detailed Person Image Synthesis
May 26, 2020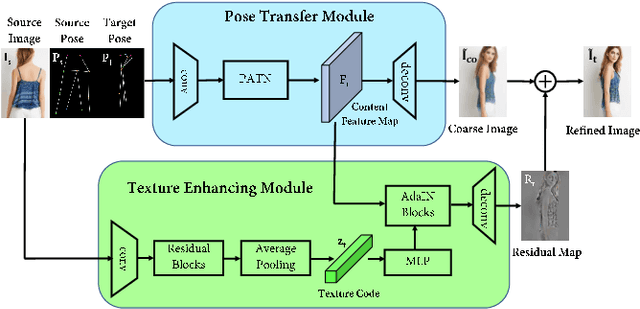

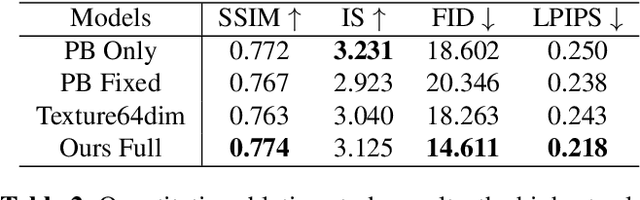
The ability to produce convincing textural details is essential for the fidelity of synthesized person images. However, existing methods typically follow a ``warping-based'' strategy that propagates appearance features through the same pathway used for pose transfer. However, most fine-grained features would be lost due to down-sampling, leading to over-smoothed clothes and missing details in the output images. In this paper we presents RATE-Net, a novel framework for synthesizing person images with sharp texture details. The proposed framework leverages an additional texture enhancing module to extract appearance information from the source image and estimate a fine-grained residual texture map, which helps to refine the coarse estimation from the pose transfer module. In addition, we design an effective alternate updating strategy to promote mutual guidance between two modules for better shape and appearance consistency. Experiments conducted on DeepFashion benchmark dataset have demonstrated the superiority of our framework compared with existing networks.