 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEquation Discovery with Bayesian Spike-and-Slab Priors and Efficient Kernels
Oct 09, 2023



Discovering governing equations from data is important to many scientific and engineering applications. Despite promising successes, existing methods are still challenged by data sparsity as well as noise issues, both of which are ubiquitous in practice. Moreover, state-of-the-art methods lack uncertainty quantification and/or are costly in training. To overcome these limitations, we propose a novel equation discovery method based on Kernel learning and BAyesian Spike-and-Slab priors (KBASS). We use kernel regression to estimate the target function, which is flexible, expressive, and more robust to data sparsity and noises. We combine it with a Bayesian spike-and-slab prior -- an ideal Bayesian sparse distribution -- for effective operator selection and uncertainty quantification. We develop an expectation propagation expectation-maximization (EP-EM) algorithm for efficient posterior inference and function estimation. To overcome the computational challenge of kernel regression, we place the function values on a mesh and induce a Kronecker product construction, and we use tensor algebra methods to enable efficient computation and optimization. We show the significant advantages of KBASS on a list of benchmark ODE and PDE discovery tasks.
Multi-Resolution Active Learning of Fourier Neural Operators
Oct 08, 2023



Fourier Neural Operator (FNO) is a popular operator learning framework, which not only achieves the state-of-the-art performance in many tasks, but also is highly efficient in training and prediction. However, collecting training data for the FNO is a costly bottleneck in practice, because it often demands expensive physical simulations. To overcome this problem, we propose Multi-Resolution Active learning of FNO (MRA-FNO), which can dynamically select the input functions and resolutions to lower the data cost as much as possible while optimizing the learning efficiency. Specifically, we propose a probabilistic multi-resolution FNO and use ensemble Monte-Carlo to develop an effective posterior inference algorithm. To conduct active learning, we maximize a utility-cost ratio as the acquisition function to acquire new examples and resolutions at each step. We use moment matching and the matrix determinant lemma to enable tractable, efficient utility computation. Furthermore, we develop a cost annealing framework to avoid over-penalizing high-resolution queries at the early stage. The over-penalization is severe when the cost difference is significant between the resolutions, which renders active learning often stuck at low-resolution queries and inferior performance. Our method overcomes this problem and applies to general multi-fidelity active learning and optimization problems. We have shown the advantage of our method in several benchmark operator learning tasks.
BayOTIDE: Bayesian Online Multivariate Time series Imputation with functional decomposition
Aug 28, 2023In real-world scenarios like traffic and energy, massive time-series data with missing values and noises are widely observed, even sampled irregularly. While many imputation methods have been proposed, most of them work with a local horizon, which means models are trained by splitting the long sequence into batches of fit-sized patches. This local horizon can make models ignore global trends or periodic patterns. More importantly, almost all methods assume the observations are sampled at regular time stamps, and fail to handle complex irregular sampled time series arising from different applications. Thirdly, most existing methods are learned in an offline manner. Thus, it is not suitable for many applications with fast-arriving streaming data. To overcome these limitations, we propose \ours: Bayesian Online Multivariate Time series Imputation with functional decomposition. We treat the multivariate time series as the weighted combination of groups of low-rank temporal factors with different patterns. We apply a group of Gaussian Processes (GPs) with different kernels as functional priors to fit the factors. For computational efficiency, we further convert the GPs into a state-space prior by constructing an equivalent stochastic differential equation (SDE), and developing a scalable algorithm for online inference. The proposed method can not only handle imputation over arbitrary time stamps, but also offer uncertainty quantification and interpretability for the downstream application. We evaluate our method on both synthetic and real-world datasets.
Provably Convergent Schrödinger Bridge with Applications to Probabilistic Time Series Imputation
May 12, 2023



The Schr\"odinger bridge problem (SBP) is gaining increasing attention in generative modeling and showing promising potential even in comparison with the score-based generative models (SGMs). SBP can be interpreted as an entropy-regularized optimal transport problem, which conducts projections onto every other marginal alternatingly. However, in practice, only approximated projections are accessible and their convergence is not well understood. To fill this gap, we present a first convergence analysis of the Schr\"odinger bridge algorithm based on approximated projections. As for its practical applications, we apply SBP to probabilistic time series imputation by generating missing values conditioned on observed data. We show that optimizing the transport cost improves the performance and the proposed algorithm achieves the state-of-the-art result in healthcare and environmental data while exhibiting the advantage of exploring both temporal and feature patterns in probabilistic time series imputation.
A unified scalable framework for causal sweeping strategies for Physics-Informed Neural Networks (PINNs) and their temporal decompositions
Feb 28, 2023



Physics-informed neural networks (PINNs) as a means of solving partial differential equations (PDE) have garnered much attention in Computational Science and Engineering (CS&E). However, a recent topic of interest is exploring various training (i.e., optimization) challenges - in particular, arriving at poor local minima in the optimization landscape results in a PINN approximation giving an inferior, and sometimes trivial, solution when solving forward time-dependent PDEs with no data. This problem is also found in, and in some sense more difficult, with domain decomposition strategies such as temporal decomposition using XPINNs. To address this problem, we first enable a general categorization for previous causality methods, from which we identify a gap in the previous approaches. We then furnish examples and explanations for different training challenges, their cause, and how they relate to information propagation and temporal decomposition. We propose a solution to fill this gap by reframing these causality concepts into a generalized information propagation framework in which any prior method or combination of methods can be described. Our unified framework moves toward reducing the number of PINN methods to consider and the implementation and retuning cost for thorough comparisons. We propose a new stacked-decomposition method that bridges the gap between time-marching PINNs and XPINNs. We also introduce significant computational speed-ups by using transfer learning concepts to initialize subnetworks in the domain and loss tolerance-based propagation for the subdomains. We formulate a new time-sweeping collocation point algorithm inspired by the previous PINNs causality literature, which our framework can still describe, and provides a significant computational speed-up via reduced-cost collocation point segmentation. Finally, we provide numerical results on baseline PDE problems.
Genetic Programming Based Symbolic Regression for Analytical Solutions to Differential Equations
Feb 07, 2023



In this paper, we present a machine learning method for the discovery of analytic solutions to differential equations. The method utilizes an inherently interpretable algorithm, genetic programming based symbolic regression. Unlike conventional accuracy measures in machine learning we demonstrate the ability to recover true analytic solutions, as opposed to a numerical approximation. The method is verified by assessing its ability to recover known analytic solutions for two separate differential equations. The developed method is compared to a conventional, purely data-driven genetic programming based symbolic regression algorithm. The reliability of successful evolution of the true solution, or an algebraic equivalent, is demonstrated.
Getting Away with More Network Pruning: From Sparsity to Geometry and Linear Regions
Jan 19, 2023



One surprising trait of neural networks is the extent to which their connections can be pruned with little to no effect on accuracy. But when we cross a critical level of parameter sparsity, pruning any further leads to a sudden drop in accuracy. This drop plausibly reflects a loss in model complexity, which we aim to avoid. In this work, we explore how sparsity also affects the geometry of the linear regions defined by a neural network, and consequently reduces the expected maximum number of linear regions based on the architecture. We observe that pruning affects accuracy similarly to how sparsity affects the number of linear regions and our proposed bound for the maximum number. Conversely, we find out that selecting the sparsity across layers to maximize our bound very often improves accuracy in comparison to pruning as much with the same sparsity in all layers, thereby providing us guidance on where to prune.
Meta Learning of Interface Conditions for Multi-Domain Physics-Informed Neural Networks
Oct 23, 2022



Physics-informed neural networks (PINNs) are emerging as popular mesh-free solvers for partial differential equations (PDEs). Recent extensions decompose the domain, applying different PINNs to solve the equation in each subdomain and aligning the solution at the interface of the subdomains. Hence, they can further alleviate the problem complexity, reduce the computational cost, and allow parallelization. However, the performance of the multi-domain PINNs is sensitive to the choice of the interface conditions for solution alignment. While quite a few conditions have been proposed, there is no suggestion about how to select the conditions according to specific problems. To address this gap, we propose META Learning of Interface Conditions (METALIC), a simple, efficient yet powerful approach to dynamically determine the optimal interface conditions for solving a family of parametric PDEs. Specifically, we develop two contextual multi-arm bandit models. The first one applies to the entire training procedure, and online updates a Gaussian process (GP) reward surrogate that given the PDE parameters and interface conditions predicts the solution error. The second one partitions the training into two stages, one is the stochastic phase and the other deterministic phase; we update a GP surrogate for each phase to enable different condition selections at the two stages so as to further bolster the flexibility and performance. We have shown the advantage of METALIC on four bench-mark PDE families.
Batch Multi-Fidelity Active Learning with Budget Constraints
Oct 23, 2022



Learning functions with high-dimensional outputs is critical in many applications, such as physical simulation and engineering design. However, collecting training examples for these applications is often costly, e.g. by running numerical solvers. The recent work (Li et al., 2022) proposes the first multi-fidelity active learning approach for high-dimensional outputs, which can acquire examples at different fidelities to reduce the cost while improving the learning performance. However, this method only queries at one pair of fidelity and input at a time, and hence has a risk to bring in strongly correlated examples to reduce the learning efficiency. In this paper, we propose Batch Multi-Fidelity Active Learning with Budget Constraints (BMFAL-BC), which can promote the diversity of training examples to improve the benefit-cost ratio, while respecting a given budget constraint for batch queries. Hence, our method can be more practically useful. Specifically, we propose a novel batch acquisition function that measures the mutual information between a batch of multi-fidelity queries and the target function, so as to penalize highly correlated queries and encourages diversity. The optimization of the batch acquisition function is challenging in that it involves a combinatorial search over many fidelities while subject to the budget constraint. To address this challenge, we develop a weighted greedy algorithm that can sequentially identify each (fidelity, input) pair, while achieving a near $(1 - 1/e)$-approximation of the optimum. We show the advantage of our method in several computational physics and engineering applications.
A Kernel Approach for PDE Discovery and Operator Learning
Oct 14, 2022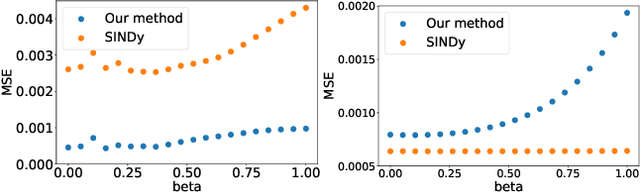
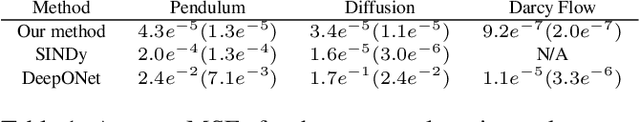
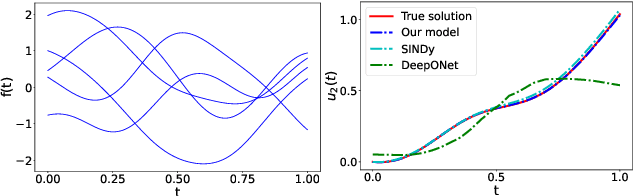
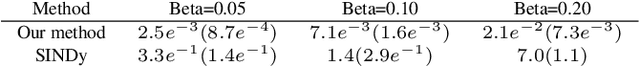
This article presents a three-step framework for learning and solving partial differential equations (PDEs) using kernel methods. Given a training set consisting of pairs of noisy PDE solutions and source/boundary terms on a mesh, kernel smoothing is utilized to denoise the data and approximate derivatives of the solution. This information is then used in a kernel regression model to learn the algebraic form of the PDE. The learned PDE is then used within a kernel based solver to approximate the solution of the PDE with a new source/boundary term, thereby constituting an operator learning framework. The proposed method is mathematically interpretable and amenable to analysis, and convenient to implement. Numerical experiments compare the method to state-of-the-art algorithms and demonstrate its superior performance on small amounts of training data and for PDEs with spatially variable coefficients.