 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivate (Stochastic) Non-Convex Optimization Revisited: Second-Order Stationary Points and Excess Risks
Feb 20, 2023


We consider the problem of minimizing a non-convex objective while preserving the privacy of the examples in the training data. Building upon the previous variance-reduced algorithm SpiderBoost, we introduce a new framework that utilizes two different kinds of gradient oracles. The first kind of oracles can estimate the gradient of one point, and the second kind of oracles, less precise and more cost-effective, can estimate the gradient difference between two points. SpiderBoost uses the first kind periodically, once every few steps, while our framework proposes using the first oracle whenever the total drift has become large and relies on the second oracle otherwise. This new framework ensures the gradient estimations remain accurate all the time, resulting in improved rates for finding second-order stationary points. Moreover, we address a more challenging task of finding the global minima of a non-convex objective using the exponential mechanism. Our findings indicate that the regularized exponential mechanism can closely match previous empirical and population risk bounds, without requiring smoothness assumptions for algorithms with polynomial running time. Furthermore, by disregarding running time considerations, we show that the exponential mechanism can achieve a good population risk bound and provide a nearly matching lower bound.
Why Is Public Pretraining Necessary for Private Model Training?
Feb 19, 2023



In the privacy-utility tradeoff of a model trained on benchmark language and vision tasks, remarkable improvements have been widely reported with the use of pretraining on publicly available data. This is in part due to the benefits of transfer learning, which is the standard motivation for pretraining in non-private settings. However, the stark contrast in the improvement achieved through pretraining under privacy compared to non-private settings suggests that there may be a deeper, distinct cause driving these gains. To explain this phenomenon, we hypothesize that the non-convex loss landscape of a model training necessitates an optimization algorithm to go through two phases. In the first, the algorithm needs to select a good "basin" in the loss landscape. In the second, the algorithm solves an easy optimization within that basin. The former is a harder problem to solve with private data, while the latter is harder to solve with public data due to a distribution shift or data scarcity. Guided by this intuition, we provide theoretical constructions that provably demonstrate the separation between private training with and without public pretraining. Further, systematic experiments on CIFAR10 and LibriSpeech provide supporting evidence for our hypothesis.
One-shot Empirical Privacy Estimation for Federated Learning
Feb 08, 2023



Privacy auditing techniques for differentially private (DP) algorithms are useful for estimating the privacy loss to compare against analytical bounds, or empirically measure privacy in settings where known analytical bounds on the DP loss are not tight. However, existing privacy auditing techniques usually make strong assumptions on the adversary (e.g., knowledge of intermediate model iterates or the training data distribution), are tailored to specific tasks and model architectures, and require retraining the model many times (typically on the order of thousands). These shortcomings make deploying such techniques at scale difficult in practice, especially in federated settings where model training can take days or weeks. In this work, we present a novel "one-shot" approach that can systematically address these challenges, allowing efficient auditing or estimation of the privacy loss of a model during the same, single training run used to fit model parameters. Our privacy auditing method for federated learning does not require a priori knowledge about the model architecture or task. We show that our method provides provably correct estimates for privacy loss under the Gaussian mechanism, and we demonstrate its performance on a well-established FL benchmark dataset under several adversarial models.
Near Optimal Private and Robust Linear Regression
Jan 30, 2023



We study the canonical statistical estimation problem of linear regression from $n$ i.i.d.~examples under $(\varepsilon,\delta)$-differential privacy when some response variables are adversarially corrupted. We propose a variant of the popular differentially private stochastic gradient descent (DP-SGD) algorithm with two innovations: a full-batch gradient descent to improve sample complexity and a novel adaptive clipping to guarantee robustness. When there is no adversarial corruption, this algorithm improves upon the existing state-of-the-art approach and achieves a near optimal sample complexity. Under label-corruption, this is the first efficient linear regression algorithm to guarantee both $(\varepsilon,\delta)$-DP and robustness. Synthetic experiments confirm the superiority of our approach.
Machine Learning-Aided Efficient Decoding of Reed-Muller Subcodes
Jan 16, 2023



Reed-Muller (RM) codes achieve the capacity of general binary-input memoryless symmetric channels and have a comparable performance to that of random codes in terms of scaling laws. However, they lack efficient decoders with performance close to that of a maximum-likelihood decoder for general code parameters. Also, they only admit limited sets of rates. In this paper, we focus on subcodes of RM codes with flexible rates. We first extend the recently-introduced recursive projection-aggregation (RPA) decoding algorithm to RM subcodes. To lower the complexity of our decoding algorithm, referred to as subRPA, we investigate different approaches to prune the projections. Next, we derive the soft-decision based version of our algorithm, called soft-subRPA, that not only improves upon the performance of subRPA but also enables a differentiable decoding algorithm. Building upon the soft-subRPA algorithm, we then provide a framework for training a machine learning (ML) model to search for \textit{good} sets of projections that minimize the decoding error rate. Training our ML model enables achieving very close to the performance of full-projection decoding with a significantly smaller number of projections. We also show that the choice of the projections in decoding RM subcodes matters significantly, and our ML-aided projection pruning scheme is able to find a \textit{good} selection, i.e., with negligible performance degradation compared to the full-projection case, given a reasonable number of projections.
MAUVE Scores for Generative Models: Theory and Practice
Dec 30, 2022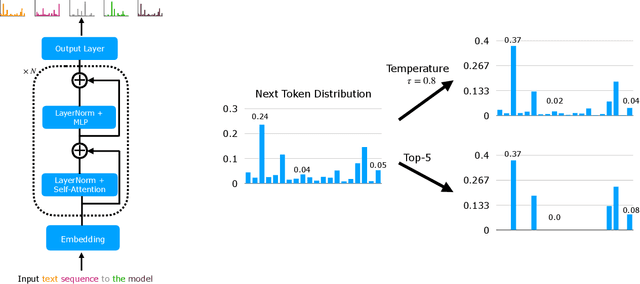
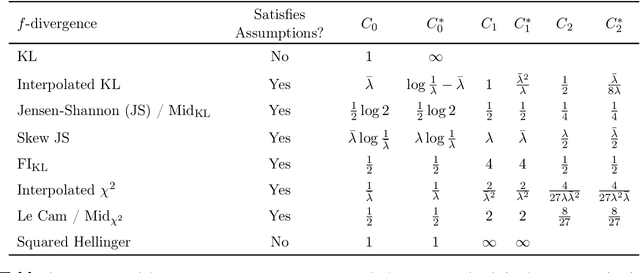
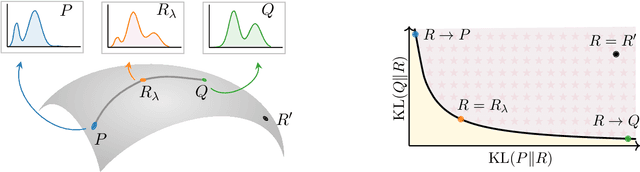

Generative AI has matured to a point where large-scale models can generate text that seems indistinguishable from human-written text and remarkably photorealistic images. Automatically measuring how close the distribution of generated data is to the target real data distribution is a key step in diagnosing existing models and developing better models. We present MAUVE, a family of comparison measures between pairs of distributions such as those encountered in the generative modeling of text or images. These scores are statistical summaries of divergence frontiers capturing two types of errors in generative modeling. We explore four approaches to statistically estimate these scores: vector quantization, non-parametric estimation, classifier-based estimation, and parametric Gaussian approximations. We provide statistical bounds for the vector quantization approach. Empirically, we find that the proposed scores paired with a range of $f$-divergences and statistical estimation methods can quantify the gaps between the distributions of human-written text and those of modern neural language models by correlating with human judgments and identifying known properties of the generated texts. We conclude the paper by demonstrating its applications to other AI domains and discussing practical recommendations.
Learning to Generate Image Embeddings with User-level Differential Privacy
Nov 20, 2022



Small on-device models have been successfully trained with user-level differential privacy (DP) for next word prediction and image classification tasks in the past. However, existing methods can fail when directly applied to learn embedding models using supervised training data with a large class space. To achieve user-level DP for large image-to-embedding feature extractors, we propose DP-FedEmb, a variant of federated learning algorithms with per-user sensitivity control and noise addition, to train from user-partitioned data centralized in the datacenter. DP-FedEmb combines virtual clients, partial aggregation, private local fine-tuning, and public pretraining to achieve strong privacy utility trade-offs. We apply DP-FedEmb to train image embedding models for faces, landmarks and natural species, and demonstrate its superior utility under same privacy budget on benchmark datasets DigiFace, EMNIST, GLD and iNaturalist. We further illustrate it is possible to achieve strong user-level DP guarantees of $\epsilon<2$ while controlling the utility drop within 5%, when millions of users can participate in training.
Zonotope Domains for Lagrangian Neural Network Verification
Oct 14, 2022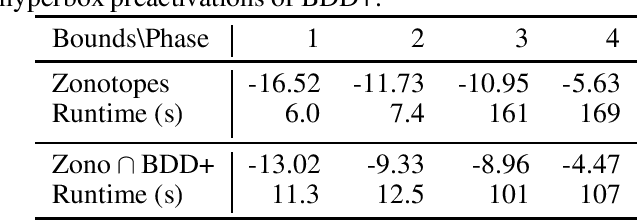
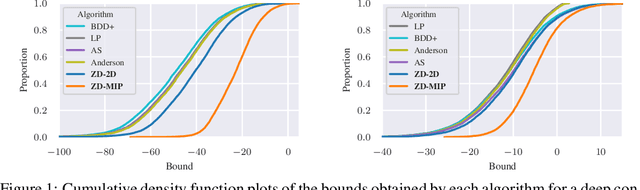
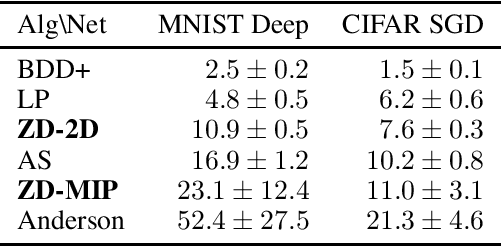
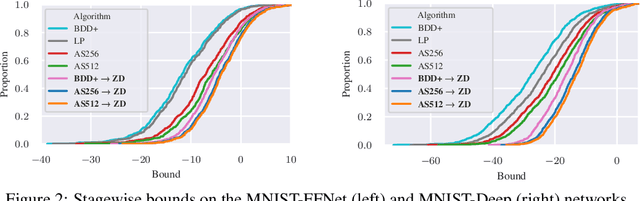
Neural network verification aims to provide provable bounds for the output of a neural network for a given input range. Notable prior works in this domain have either generated bounds using abstract domains, which preserve some dependency between intermediate neurons in the network; or framed verification as an optimization problem and solved a relaxation using Lagrangian methods. A key drawback of the latter technique is that each neuron is treated independently, thereby ignoring important neuron interactions. We provide an approach that merges these two threads and uses zonotopes within a Lagrangian decomposition. Crucially, we can decompose the problem of verifying a deep neural network into the verification of many 2-layer neural networks. While each of these problems is provably hard, we provide efficient relaxation methods that are amenable to efficient dual ascent procedures. Our technique yields bounds that improve upon both linear programming and Lagrangian-based verification techniques in both time and bound tightness.
Few-shot Backdoor Attacks via Neural Tangent Kernels
Oct 12, 2022

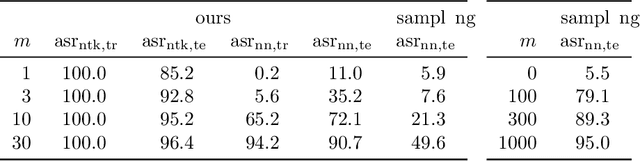

In a backdoor attack, an attacker injects corrupted examples into the training set. The goal of the attacker is to cause the final trained model to predict the attacker's desired target label when a predefined trigger is added to test inputs. Central to these attacks is the trade-off between the success rate of the attack and the number of corrupted training examples injected. We pose this attack as a novel bilevel optimization problem: construct strong poison examples that maximize the attack success rate of the trained model. We use neural tangent kernels to approximate the training dynamics of the model being attacked and automatically learn strong poison examples. We experiment on subclasses of CIFAR-10 and ImageNet with WideResNet-34 and ConvNeXt architectures on periodic and patch trigger attacks and show that NTBA-designed poisoned examples achieve, for example, an attack success rate of 90% with ten times smaller number of poison examples injected compared to the baseline. We provided an interpretation of the NTBA-designed attacks using the analysis of kernel linear regression. We further demonstrate a vulnerability in overparametrized deep neural networks, which is revealed by the shape of the neural tangent kernel.
Stochastic optimization on matrices and a graphon McKean-Vlasov limit
Oct 02, 2022We consider stochastic gradient descents on the space of large symmetric matrices of suitable functions that are invariant under permuting the rows and columns using the same permutation. We establish deterministic limits of these random curves as the dimensions of the matrices go to infinity while the entries remain bounded. Under a ``small noise'' assumption the limit is shown to be the gradient flow of functions on graphons whose existence was established in arXiv:2111.09459. We also consider limits of stochastic gradient descents with added properly scaled reflected Brownian noise. The limiting curve of graphons is characterized by a family of stochastic differential equations with reflections and can be thought of as an extension of the classical McKean-Vlasov limit for interacting diffusions. The proofs introduce a family of infinite-dimensional exchangeable arrays of reflected diffusions and a novel notion of propagation of chaos for large matrices of interacting diffusions.