 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Style Breaks Safety: Defending Language Models Against Superficial Style Alignment
Jun 09, 2025Large language models (LLMs) can be prompted with specific styles (e.g., formatting responses as lists), including in jailbreak queries. Although these style patterns are semantically unrelated to the malicious intents behind jailbreak queries, their safety impact remains unclear. In this work, we seek to understand whether style patterns compromise LLM safety, how superficial style alignment increases model vulnerability, and how best to mitigate these risks during alignment. We evaluate 32 LLMs across seven jailbreak benchmarks, and find that malicious queries with style patterns inflate the attack success rate (ASR) for nearly all models. Notably, ASR inflation correlates with both the length of style patterns and the relative attention an LLM exhibits on them. We then investigate superficial style alignment, and find that fine-tuning with specific styles makes LLMs more vulnerable to jailbreaks of those same styles. Finally, we propose SafeStyle, a defense strategy that incorporates a small amount of safety training data augmented to match the distribution of style patterns in the fine-tuning data. Across three LLMs and five fine-tuning style settings, SafeStyle consistently outperforms baselines in maintaining LLM safety.
Layered Unlearning for Adversarial Relearning
May 14, 2025Our goal is to understand how post-training methods, such as fine-tuning, alignment, and unlearning, modify language model behavior and representations. We are particularly interested in the brittle nature of these modifications that makes them easy to bypass through prompt engineering or relearning. Recent results suggest that post-training induces shallow context-dependent ``circuits'' that suppress specific response patterns. This could be one explanation for the brittleness of post-training. To test this hypothesis, we design an unlearning algorithm, Layered Unlearning (LU), that creates distinct inhibitory mechanisms for a growing subset of the data. By unlearning the first $i$ folds while retaining the remaining $k - i$ at the $i$th of $k$ stages, LU limits the ability of relearning on a subset of data to recover the full dataset. We evaluate LU through a combination of synthetic and large language model (LLM) experiments. We find that LU improves robustness to adversarial relearning for several different unlearning methods. Our results contribute to the state-of-the-art of machine unlearning and provide insight into the effect of post-training updates.
One-shot Empirical Privacy Estimation for Federated Learning
Feb 08, 2023



Privacy auditing techniques for differentially private (DP) algorithms are useful for estimating the privacy loss to compare against analytical bounds, or empirically measure privacy in settings where known analytical bounds on the DP loss are not tight. However, existing privacy auditing techniques usually make strong assumptions on the adversary (e.g., knowledge of intermediate model iterates or the training data distribution), are tailored to specific tasks and model architectures, and require retraining the model many times (typically on the order of thousands). These shortcomings make deploying such techniques at scale difficult in practice, especially in federated settings where model training can take days or weeks. In this work, we present a novel "one-shot" approach that can systematically address these challenges, allowing efficient auditing or estimation of the privacy loss of a model during the same, single training run used to fit model parameters. Our privacy auditing method for federated learning does not require a priori knowledge about the model architecture or task. We show that our method provides provably correct estimates for privacy loss under the Gaussian mechanism, and we demonstrate its performance on a well-established FL benchmark dataset under several adversarial models.
3D Reasoning for Unsupervised Anomaly Detection in Pediatric WbMRI
Mar 24, 2021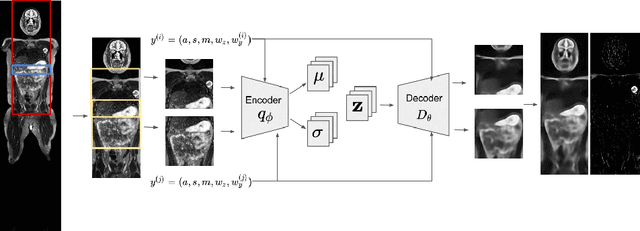
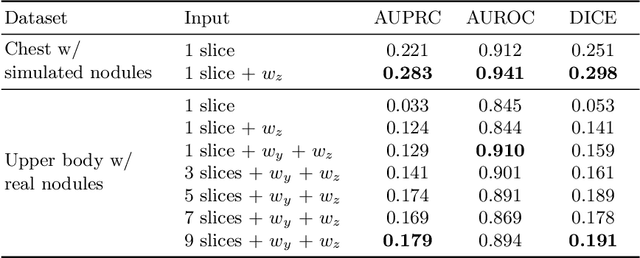

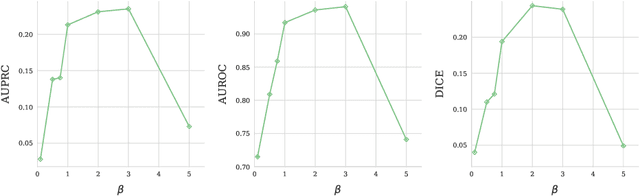
Modern deep unsupervised learning methods have shown great promise for detecting diseases across a variety of medical imaging modalities. While previous generative modeling approaches successfully perform anomaly detection by learning the distribution of healthy 2D image slices, they process such slices independently and ignore the fact that they are correlated, all being sampled from a 3D volume. We show that incorporating the 3D context and processing whole-body MRI volumes is beneficial to distinguishing anomalies from their benign counterparts. In our work, we introduce a multi-channel sliding window generative model to perform lesion detection in whole-body MRI (wbMRI). Our experiments demonstrate that our proposed method significantly outperforms processing individual images in isolation and our ablations clearly show the importance of 3D reasoning. Moreover, our work also shows that it is beneficial to include additional patient-specific features to further improve anomaly detection in pediatric scans.