 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Mixture Inference: What do BPE Tokenizers Reveal about their Training Data?
Jul 24, 2024



The pretraining data of today's strongest language models is opaque; in particular, little is known about the proportions of various domains or languages represented. In this work, we tackle a task which we call data mixture inference, which aims to uncover the distributional make-up of training data. We introduce a novel attack based on a previously overlooked source of information -- byte-pair encoding (BPE) tokenizers, used by the vast majority of modern language models. Our key insight is that the ordered list of merge rules learned by a BPE tokenizer naturally reveals information about the token frequencies in its training data: the first merge is the most common byte pair, the second is the most common pair after merging the first token, and so on. Given a tokenizer's merge list along with data samples for each category of interest, we formulate a linear program that solves for the proportion of each category in the tokenizer's training set. Importantly, to the extent to which tokenizer training data is representative of the pretraining data, we indirectly learn about pretraining data. In controlled experiments, we show that our attack recovers mixture ratios with high precision for tokenizers trained on known mixtures of natural languages, programming languages, and data sources. We then apply our approach to off-the-shelf tokenizers released with recent LMs. We confirm much publicly disclosed information about these models, and also make several new inferences: GPT-4o's tokenizer is much more multilingual than its predecessors, training on 39% non-English data; Llama3 extends GPT-3.5's tokenizer primarily for multilingual (48%) use; GPT-3.5's and Claude's tokenizers are trained on predominantly code (~60%). We hope our work sheds light on current design practices for pretraining data, and inspires continued research into data mixture inference for LMs.
Understanding the Gains from Repeated Self-Distillation
Jul 05, 2024



Self-Distillation is a special type of knowledge distillation where the student model has the same architecture as the teacher model. Despite using the same architecture and the same training data, self-distillation has been empirically observed to improve performance, especially when applied repeatedly. For such a process, there is a fundamental question of interest: How much gain is possible by applying multiple steps of self-distillation? To investigate this relative gain, we propose studying the simple but canonical task of linear regression. Our analysis shows that the excess risk achieved by multi-step self-distillation can significantly improve upon a single step of self-distillation, reducing the excess risk by a factor as large as $d$, where $d$ is the input dimension. Empirical results on regression tasks from the UCI repository show a reduction in the learnt model's risk (MSE) by up to 47%.
PLeaS -- Merging Models with Permutations and Least Squares
Jul 02, 2024The democratization of machine learning systems has made the process of fine-tuning accessible to a large number of practitioners, leading to a wide range of open-source models fine-tuned on specialized tasks and datasets. Recent work has proposed to merge such models to combine their functionalities. However, prior approaches are restricted to models that are fine-tuned from the same base model. Furthermore, the final merged model is typically restricted to be of the same size as the original models. In this work, we propose a new two-step algorithm to merge models-termed PLeaS-which relaxes these constraints. First, leveraging the Permutation symmetries inherent in the two models, PLeaS partially matches nodes in each layer by maximizing alignment. Next, PLeaS computes the weights of the merged model as a layer-wise Least Squares solution to minimize the approximation error between the features of the merged model and the permuted features of the original models. into a single model of a desired size, even when the two original models are fine-tuned from different base models. We also present a variant of our method which can merge models without using data from the fine-tuning domains. We demonstrate our method to merge ResNet models trained with shared and different label spaces, and show that we can perform better than the state-of-the-art merging methods by 8 to 15 percentage points for the same target compute while merging models trained on DomainNet and on fine-grained classification tasks.
DataComp-LM: In search of the next generation of training sets for language models
Jun 18, 2024



We introduce DataComp for Language Models (DCLM), a testbed for controlled dataset experiments with the goal of improving language models. As part of DCLM, we provide a standardized corpus of 240T tokens extracted from Common Crawl, effective pretraining recipes based on the OpenLM framework, and a broad suite of 53 downstream evaluations. Participants in the DCLM benchmark can experiment with data curation strategies such as deduplication, filtering, and data mixing at model scales ranging from 412M to 7B parameters. As a baseline for DCLM, we conduct extensive experiments and find that model-based filtering is key to assembling a high-quality training set. The resulting dataset, DCLM-Baseline enables training a 7B parameter language model from scratch to 64% 5-shot accuracy on MMLU with 2.6T training tokens. Compared to MAP-Neo, the previous state-of-the-art in open-data language models, DCLM-Baseline represents a 6.6 percentage point improvement on MMLU while being trained with 40% less compute. Our baseline model is also comparable to Mistral-7B-v0.3 and Llama 3 8B on MMLU (63% & 66%), and performs similarly on an average of 53 natural language understanding tasks while being trained with 6.6x less compute than Llama 3 8B. Our results highlight the importance of dataset design for training language models and offer a starting point for further research on data curation.
Multilingual Diversity Improves Vision-Language Representations
May 27, 2024



Massive web-crawled image-text datasets lay the foundation for recent progress in multimodal learning. These datasets are designed with the goal of training a model to do well on standard computer vision benchmarks, many of which, however, have been shown to be English-centric (e.g., ImageNet). Consequently, existing data curation techniques gravitate towards using predominantly English image-text pairs and discard many potentially useful non-English samples. Our work questions this practice. Multilingual data is inherently enriching not only because it provides a gateway to learn about culturally salient concepts, but also because it depicts common concepts differently from monolingual data. We thus conduct a systematic study to explore the performance benefits of using more samples of non-English origins with respect to English vision tasks. By translating all multilingual image-text pairs from a raw web crawl to English and re-filtering them, we increase the prevalence of (translated) multilingual data in the resulting training set. Pre-training on this dataset outperforms using English-only or English-dominated datasets on ImageNet, ImageNet distribution shifts, image-English-text retrieval and on average across 38 tasks from the DataComp benchmark. On a geographically diverse task like GeoDE, we also observe improvements across all regions, with the biggest gain coming from Africa. In addition, we quantitatively show that English and non-English data are significantly different in both image and (translated) text space. We hope that our findings motivate future work to be more intentional about including multicultural and multilingual data, not just when non-English or geographically diverse tasks are involved, but to enhance model capabilities at large.
Air Gap: Protecting Privacy-Conscious Conversational Agents
May 08, 2024


The growing use of large language model (LLM)-based conversational agents to manage sensitive user data raises significant privacy concerns. While these agents excel at understanding and acting on context, this capability can be exploited by malicious actors. We introduce a novel threat model where adversarial third-party apps manipulate the context of interaction to trick LLM-based agents into revealing private information not relevant to the task at hand. Grounded in the framework of contextual integrity, we introduce AirGapAgent, a privacy-conscious agent designed to prevent unintended data leakage by restricting the agent's access to only the data necessary for a specific task. Extensive experiments using Gemini, GPT, and Mistral models as agents validate our approach's effectiveness in mitigating this form of context hijacking while maintaining core agent functionality. For example, we show that a single-query context hijacking attack on a Gemini Ultra agent reduces its ability to protect user data from 94% to 45%, while an AirGapAgent achieves 97% protection, rendering the same attack ineffective.
Improved Communication-Privacy Trade-offs in $L_2$ Mean Estimation under Streaming Differential Privacy
May 02, 2024



We study $L_2$ mean estimation under central differential privacy and communication constraints, and address two key challenges: firstly, existing mean estimation schemes that simultaneously handle both constraints are usually optimized for $L_\infty$ geometry and rely on random rotation or Kashin's representation to adapt to $L_2$ geometry, resulting in suboptimal leading constants in mean square errors (MSEs); secondly, schemes achieving order-optimal communication-privacy trade-offs do not extend seamlessly to streaming differential privacy (DP) settings (e.g., tree aggregation or matrix factorization), rendering them incompatible with DP-FTRL type optimizers. In this work, we tackle these issues by introducing a novel privacy accounting method for the sparsified Gaussian mechanism that incorporates the randomness inherent in sparsification into the DP noise. Unlike previous approaches, our accounting algorithm directly operates in $L_2$ geometry, yielding MSEs that fast converge to those of the uncompressed Gaussian mechanism. Additionally, we extend the sparsification scheme to the matrix factorization framework under streaming DP and provide a precise accountant tailored for DP-FTRL type optimizers. Empirically, our method demonstrates at least a 100x improvement of compression for DP-SGD across various FL tasks.
Insufficient Statistics Perturbation: Stable Estimators for Private Least Squares
Apr 23, 2024


We present a sample- and time-efficient differentially private algorithm for ordinary least squares, with error that depends linearly on the dimension and is independent of the condition number of $X^\top X$, where $X$ is the design matrix. All prior private algorithms for this task require either $d^{3/2}$ examples, error growing polynomially with the condition number, or exponential time. Our near-optimal accuracy guarantee holds for any dataset with bounded statistical leverage and bounded residuals. Technically, we build on the approach of Brown et al. (2023) for private mean estimation, adding scaled noise to a carefully designed stable nonprivate estimator of the empirical regression vector.
On the Convergence of Differentially-Private Fine-tuning: To Linearly Probe or to Fully Fine-tune?
Feb 29, 2024


Differentially private (DP) machine learning pipelines typically involve a two-phase process: non-private pre-training on a public dataset, followed by fine-tuning on private data using DP optimization techniques. In the DP setting, it has been observed that full fine-tuning may not always yield the best test accuracy, even for in-distribution data. This paper (1) analyzes the training dynamics of DP linear probing (LP) and full fine-tuning (FT), and (2) explores the phenomenon of sequential fine-tuning, starting with linear probing and transitioning to full fine-tuning (LP-FT), and its impact on test loss. We provide theoretical insights into the convergence of DP fine-tuning within an overparameterized neural network and establish a utility curve that determines the allocation of privacy budget between linear probing and full fine-tuning. The theoretical results are supported by empirical evaluations on various benchmarks and models. The findings reveal the complex nature of DP fine-tuning methods. These results contribute to a deeper understanding of DP machine learning and highlight the importance of considering the allocation of privacy budget in the fine-tuning process.
Privacy-Preserving Instructions for Aligning Large Language Models
Feb 21, 2024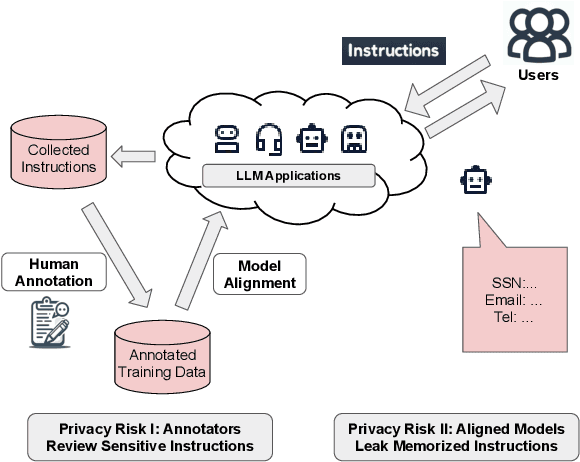
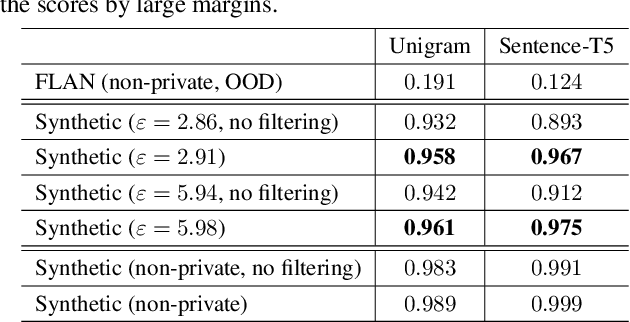
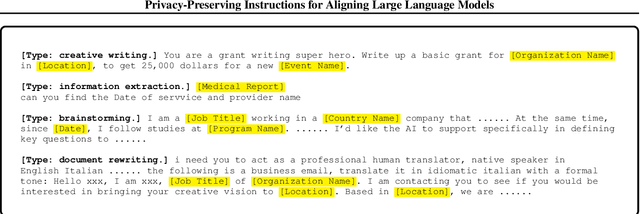
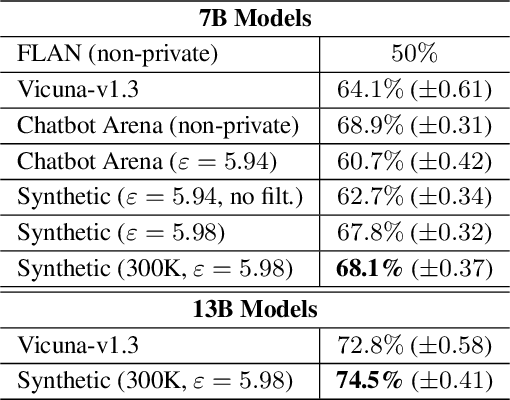
Service providers of large language model (LLM) applications collect user instructions in the wild and use them in further aligning LLMs with users' intentions. These instructions, which potentially contain sensitive information, are annotated by human workers in the process. This poses a new privacy risk not addressed by the typical private optimization. To this end, we propose using synthetic instructions to replace real instructions in data annotation and model fine-tuning. Formal differential privacy is guaranteed by generating those synthetic instructions using privately fine-tuned generators. Crucial in achieving the desired utility is our novel filtering algorithm that matches the distribution of the synthetic instructions to that of the real ones. In both supervised fine-tuning and reinforcement learning from human feedback, our extensive experiments demonstrate the high utility of the final set of synthetic instructions by showing comparable results to real instructions. In supervised fine-tuning, models trained with private synthetic instructions outperform leading open-source models such as Vicuna.