 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-H-Embodiment: A Large-Scale Dataset for Enabling Foundation Models in Medical Robotics
Apr 22, 2026Autonomous medical robots hold promise to improve patient outcomes, reduce provider workload, democratize access to care, and enable superhuman precision. However, autonomous medical robotics has been limited by a fundamental data problem: existing medical robotic datasets are small, single-embodiment, and rarely shared openly, restricting the development of foundation models that the field needs to advance. We introduce Open-H-Embodiment, the largest open dataset of medical robotic video with synchronized kinematics to date, spanning more than 49 institutions and multiple robotic platforms including the CMR Versius, Intuitive Surgical's da Vinci, da Vinci Research Kit (dVRK), Rob Surgical BiTrack, Virtual Incision's MIRA, Moon Surgical Maestro, and a variety of custom systems, spanning surgical manipulation, robotic ultrasound, and endoscopy procedures. We demonstrate the research enabled by this dataset through two foundation models. GR00T-H is the first open foundation vision-language-action model for medical robotics, which is the only evaluated model to achieve full end-to-end task completion on a structured suturing benchmark (25% of trials vs. 0% for all others) and achieves 64% average success across a 29-step ex vivo suturing sequence. We also train Cosmos-H-Surgical-Simulator, the first action-conditioned world model to enable multi-embodiment surgical simulation from a single checkpoint, spanning nine robotic platforms and supporting in silico policy evaluation and synthetic data generation for the medical domain. These results suggest that open, large-scale medical robot data collection can serve as critical infrastructure for the research community, enabling advances in robot learning, world modeling, and beyond.
AutoCam: Hierarchical Path Planning for an Autonomous Auxiliary Camera in Surgical Robotics
May 15, 2025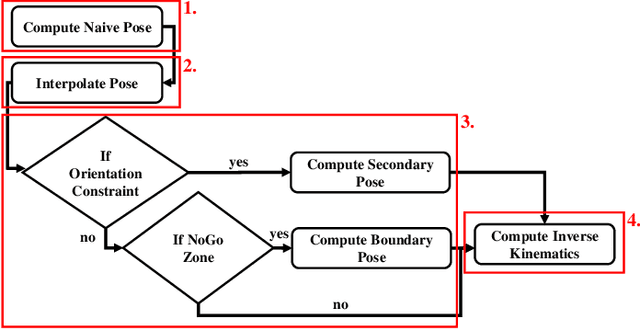

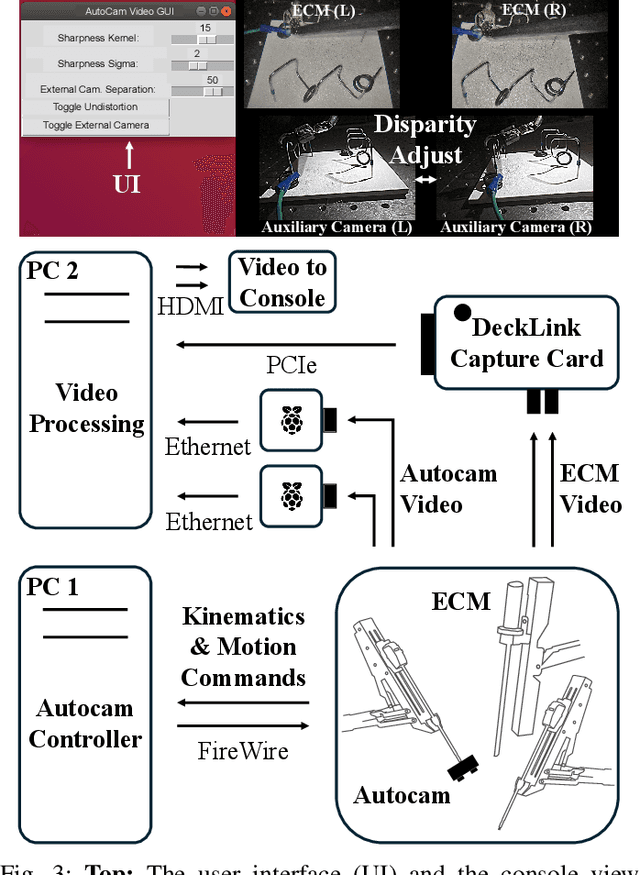
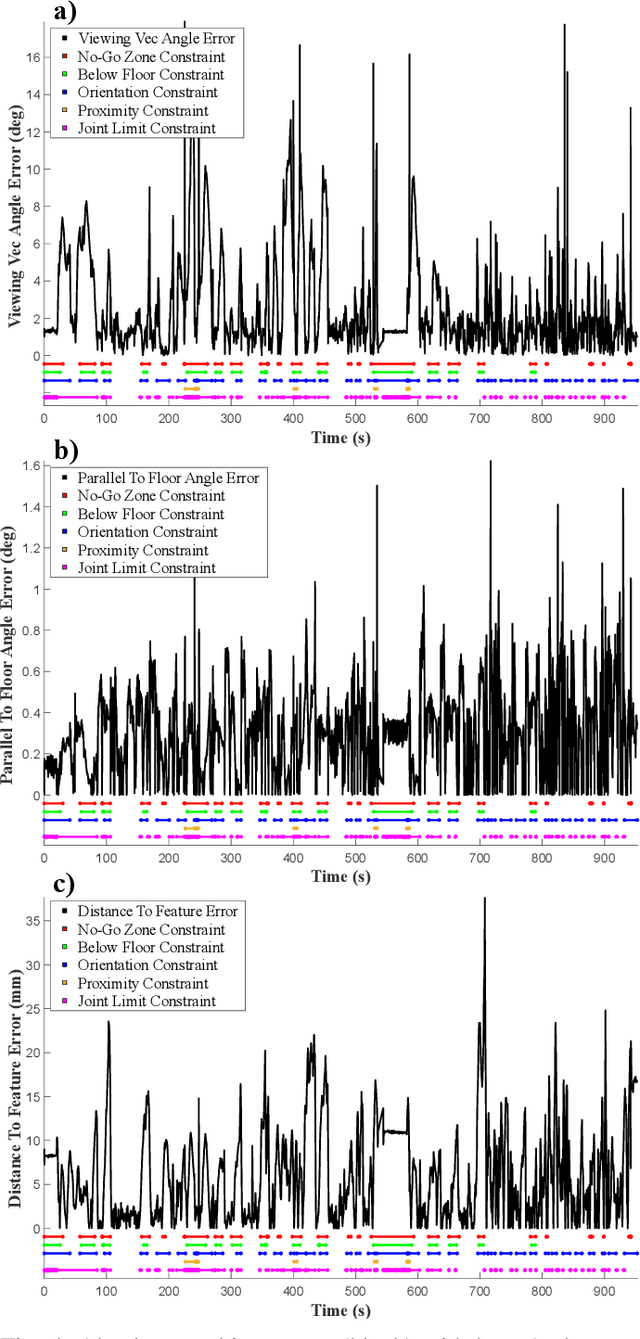
Incorporating an autonomous auxiliary camera into robot-assisted minimally invasive surgery (RAMIS) enhances spatial awareness and eliminates manual viewpoint control. Existing path planning methods for auxiliary cameras track two-dimensional surgical features but do not simultaneously account for camera orientation, workspace constraints, and robot joint limits. This study presents AutoCam: an automatic auxiliary camera placement method to improve visualization in RAMIS. Implemented on the da Vinci Research Kit, the system uses a priority-based, workspace-constrained control algorithm that combines heuristic geometric placement with nonlinear optimization to ensure robust camera tracking. A user study (N=6) demonstrated that the system maintained 99.84% visibility of a salient feature and achieved a pose error of 4.36 $\pm$ 2.11 degrees and 1.95 $\pm$ 5.66 mm. The controller was computationally efficient, with a loop time of 6.8 $\pm$ 12.8 ms. An additional pilot study (N=6), where novices completed a Fundamentals of Laparoscopic Surgery training task, suggests that users can teleoperate just as effectively from AutoCam's viewpoint as from the endoscope's while still benefiting from AutoCam's improved visual coverage of the scene. These results indicate that an auxiliary camera can be autonomously controlled using the da Vinci patient-side manipulators to track a salient feature, laying the groundwork for new multi-camera visualization methods in RAMIS.
The Quiet Eye Phenomenon in Minimally Invasive Surgery
Sep 06, 2023In this paper, we report our discovery of a gaze behavior called Quiet Eye (QE) in minimally invasive surgery. The QE behavior has been extensively studied in sports training and has been associated with higher level of expertise in multiple sports. We investigated the QE behavior in two independently collected data sets of surgeons performing tasks in a sinus surgery setting and a robotic surgery setting, respectively. Our results show that the QE behavior is more likely to occur in successful task executions and in performances of surgeons of high level of expertise. These results open the door to use the QE behavior in both training and skill assessment in minimally invasive surgery.