 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCannot See the Forest for the Trees: Aggregating Multiple Viewpoints to Better Classify Objects in Videos
Jun 05, 2022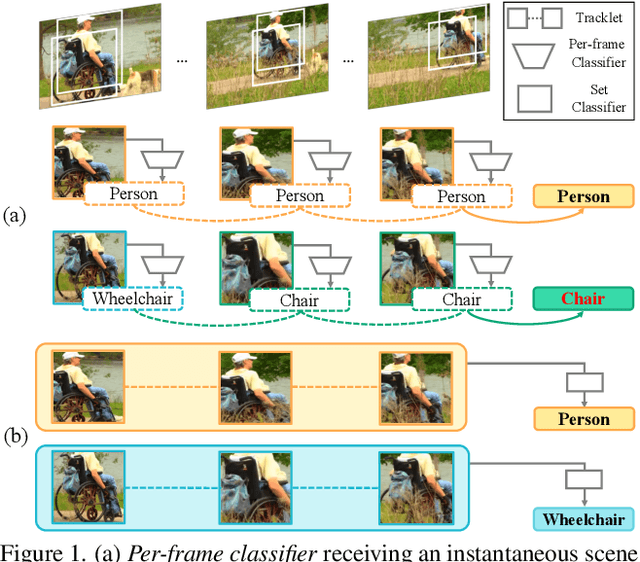

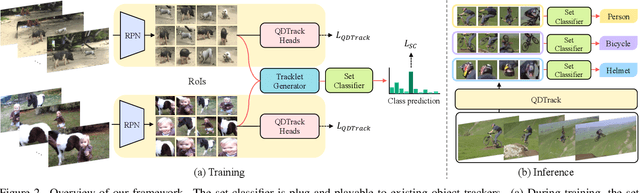
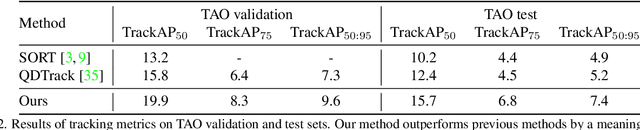
Recently, both long-tailed recognition and object tracking have made great advances individually. TAO benchmark presented a mixture of the two, long-tailed object tracking, in order to further reflect the aspect of the real-world. To date, existing solutions have adopted detectors showing robustness in long-tailed distributions, which derive per-frame results. Then, they used tracking algorithms that combine the temporally independent detections to finalize tracklets. However, as the approaches did not take temporal changes in scenes into account, inconsistent classification results in videos led to low overall performance. In this paper, we present a set classifier that improves accuracy of classifying tracklets by aggregating information from multiple viewpoints contained in a tracklet. To cope with sparse annotations in videos, we further propose augmentation of tracklets that can maximize data efficiency. The set classifier is plug-and-playable to existing object trackers, and highly improves the performance of long-tailed object tracking. By simply attaching our method to QDTrack on top of ResNet-101, we achieve the new state-of-the-art, 19.9% and 15.7% TrackAP_50 on TAO validation and test sets, respectively.
VISOLO: Grid-Based Space-Time Aggregation for Efficient Online Video Instance Segmentation
Dec 08, 2021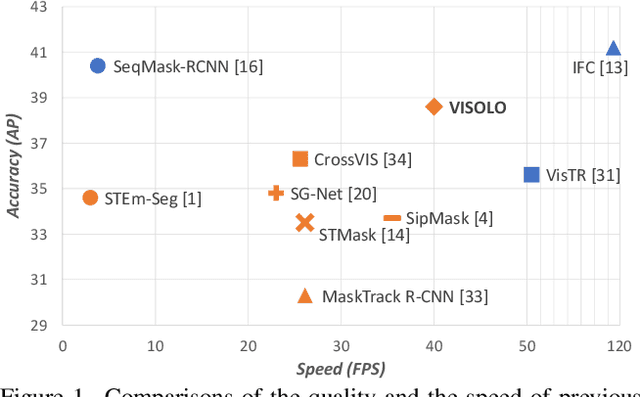
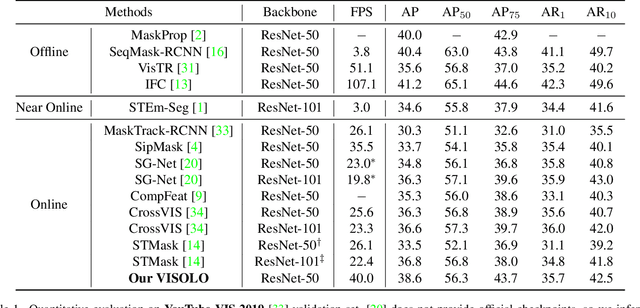
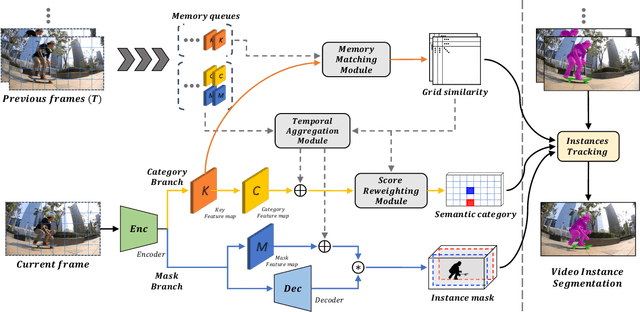
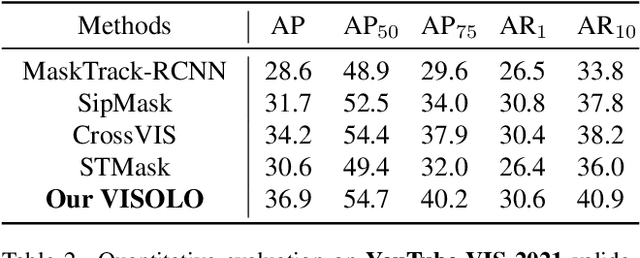
For online video instance segmentation (VIS), fully utilizing the information from previous frames in an efficient manner is essential for real-time applications. Most previous methods follow a two-stage approach requiring additional computations such as RPN and RoIAlign, and do not fully exploit the available information in the video for all subtasks in VIS. In this paper, we propose a novel single-stage framework for online VIS built based on the grid structured feature representation. The grid-based features allow us to employ fully convolutional networks for real-time processing, and also to easily reuse and share features within different components. We also introduce cooperatively operating modules that aggregate information from available frames, in order to enrich the features for all subtasks in VIS. Our design fully takes advantage of previous information in a grid form for all tasks in VIS in an efficient way, and we achieved the new state-of-the-art accuracy (38.6 AP and 36.9 AP) and speed (40.0 FPS) on YouTube-VIS 2019 and 2021 datasets among online VIS methods.
UBoCo : Unsupervised Boundary Contrastive Learning for Generic Event Boundary Detection
Nov 30, 2021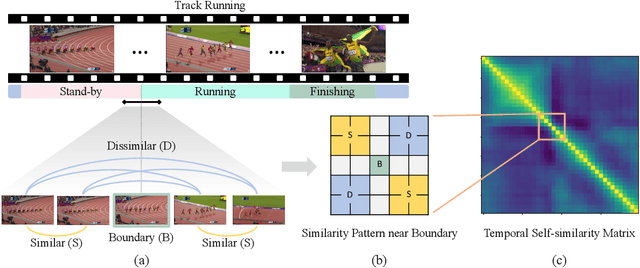
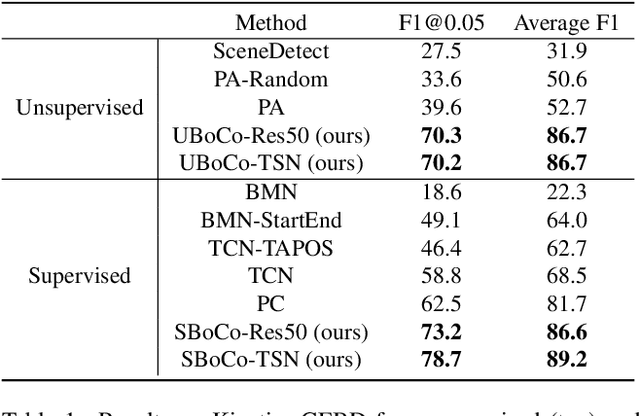
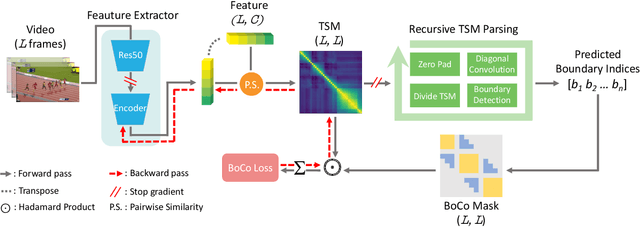
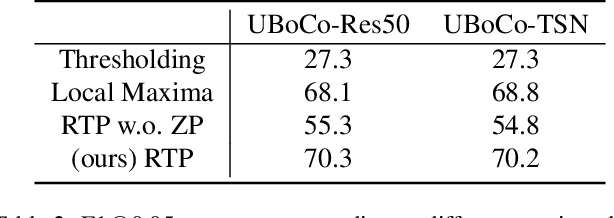
Generic Event Boundary Detection (GEBD) is a newly suggested video understanding task that aims to find one level deeper semantic boundaries of events. Bridging the gap between natural human perception and video understanding, it has various potential applications, including interpretable and semantically valid video parsing. Still at an early development stage, existing GEBD solvers are simple extensions of relevant video understanding tasks, disregarding GEBD's distinctive characteristics. In this paper, we propose a novel framework for unsupervised/supervised GEBD, by using the Temporal Self-similarity Matrix (TSM) as the video representation. The new Recursive TSM Parsing (RTP) algorithm exploits local diagonal patterns in TSM to detect boundaries, and it is combined with the Boundary Contrastive (BoCo) loss to train our encoder to generate more informative TSMs. Our framework can be applied to both unsupervised and supervised settings, with both achieving state-of-the-art performance by a huge margin in GEBD benchmark. Especially, our unsupervised method outperforms the previous state-of-the-art "supervised" model, implying its exceptional efficacy.
Winning the CVPR'2021 Kinetics-GEBD Challenge: Contrastive Learning Approach
Jun 22, 2021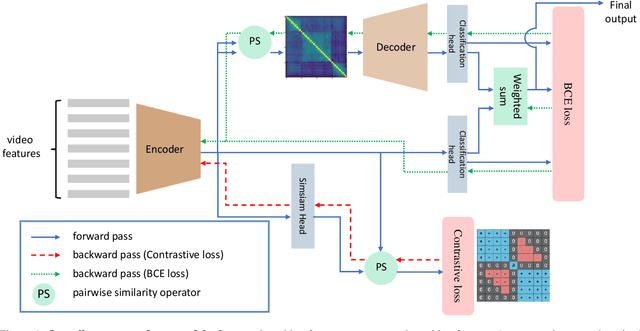
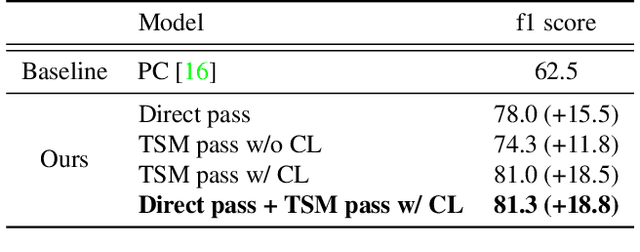
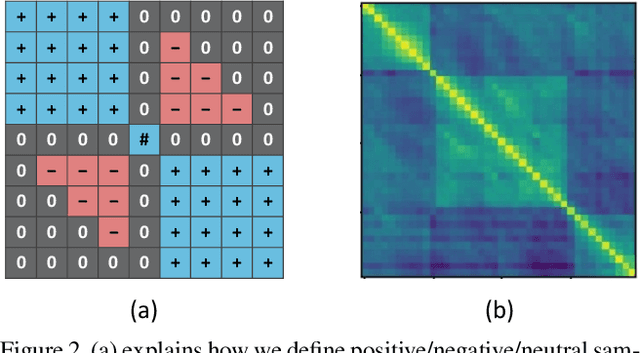
Generic Event Boundary Detection (GEBD) is a newly introduced task that aims to detect "general" event boundaries that correspond to natural human perception. In this paper, we introduce a novel contrastive learning based approach to deal with the GEBD. Our intuition is that the feature similarity of the video snippet would significantly vary near the event boundaries, while remaining relatively the same in the remaining part of the video. In our model, Temporal Self-similarity Matrix (TSM) is utilized as an intermediate representation which takes on a role as an information bottleneck. With our model, we achieved significant performance boost compared to the given baselines. Our code is available at https://github.com/hello-jinwoo/LOVEU-CVPR2021.
Video Instance Segmentation using Inter-Frame Communication Transformers
Jun 07, 2021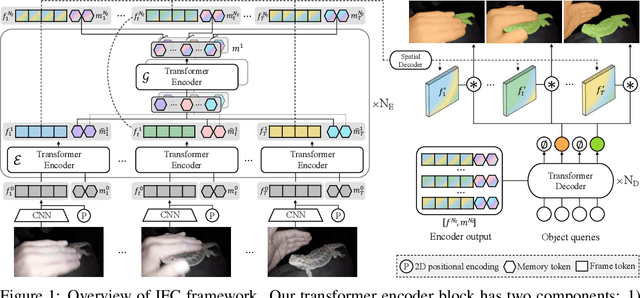

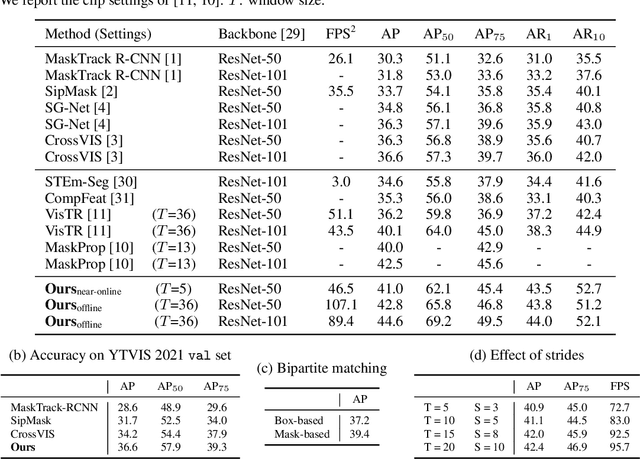

We propose a novel end-to-end solution for video instance segmentation (VIS) based on transformers. Recently, the per-clip pipeline shows superior performance over per-frame methods leveraging richer information from multiple frames. However, previous per-clip models require heavy computation and memory usage to achieve frame-to-frame communications, limiting practicality. In this work, we propose Inter-frame Communication Transformers (IFC), which significantly reduces the overhead for information-passing between frames by efficiently encoding the context within the input clip. Specifically, we propose to utilize concise memory tokens as a mean of conveying information as well as summarizing each frame scene. The features of each frame are enriched and correlated with other frames through exchange of information between the precisely encoded memory tokens. We validate our method on the latest benchmark sets and achieved the state-of-the-art performance (AP 44.6 on YouTube-VIS 2019 val set using the offline inference) while having a considerably fast runtime (89.4 FPS). Our method can also be applied to near-online inference for processing a video in real-time with only a small delay. The code will be made available.
Polygonal Point Set Tracking
May 30, 2021
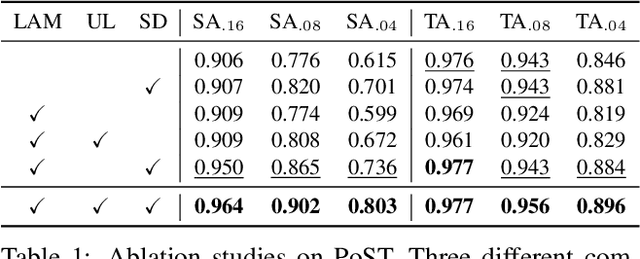
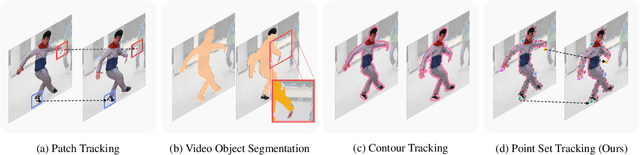

In this paper, we propose a novel learning-based polygonal point set tracking method. Compared to existing video object segmentation~(VOS) methods that propagate pixel-wise object mask information, we propagate a polygonal point set over frames. Specifically, the set is defined as a subset of points in the target contour, and our goal is to track corresponding points on the target contour. Those outputs enable us to apply various visual effects such as motion tracking, part deformation, and texture mapping. To this end, we propose a new method to track the corresponding points between frames by the global-local alignment with delicately designed losses and regularization terms. We also introduce a novel learning strategy using synthetic and VOS datasets that makes it possible to tackle the problem without developing the point correspondence dataset. Since the existing datasets are not suitable to validate our method, we build a new polygonal point set tracking dataset and demonstrate the superior performance of our method over the baselines and existing contour-based VOS methods. In addition, we present visual-effects applications of our method on part distortion and text mapping.
Temporally smooth online action detection using cycle-consistent future anticipation
Apr 16, 2021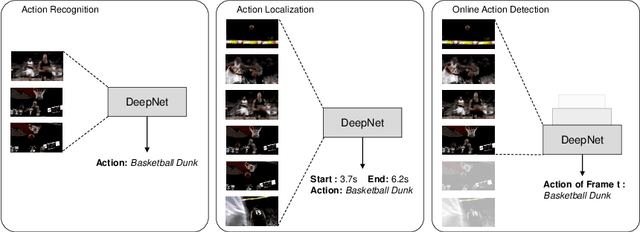
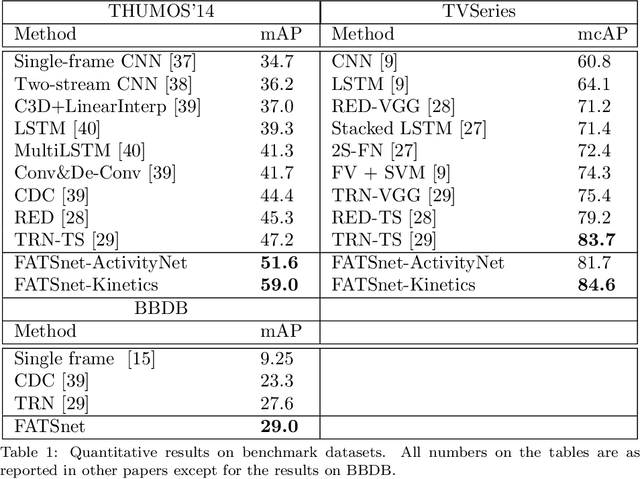
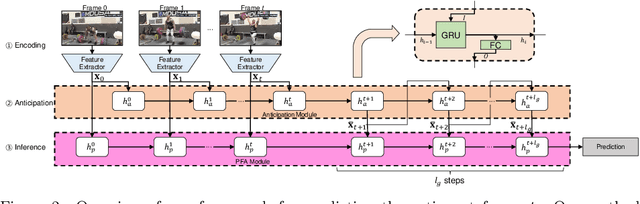
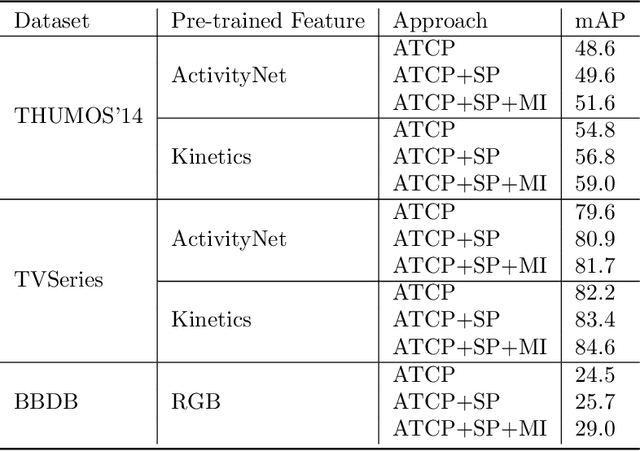
Many video understanding tasks work in the offline setting by assuming that the input video is given from the start to the end. However, many real-world problems require the online setting, making a decision immediately using only the current and the past frames of videos such as in autonomous driving and surveillance systems. In this paper, we present a novel solution for online action detection by using a simple yet effective RNN-based networks called the Future Anticipation and Temporally Smoothing network (FATSnet). The proposed network consists of a module for anticipating the future that can be trained in an unsupervised manner with the cycle-consistency loss, and another component for aggregating the past and the future for temporally smooth frame-by-frame predictions. We also propose a solution to relieve the performance loss when running RNN-based models on very long sequences. Evaluations on TVSeries, THUMOS14, and BBDB show that our method achieve the state-of-the-art performances compared to the previous works on online action detection.
* Accepted by Pattern Recognition
Single-shot Path Integrated Panoptic Segmentation
Dec 04, 2020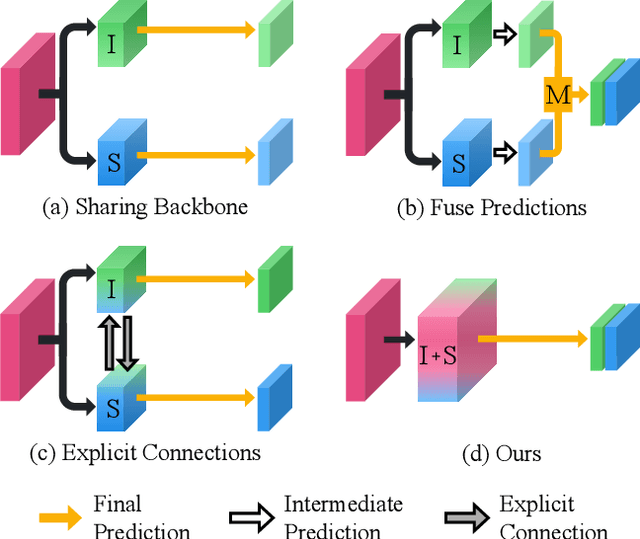
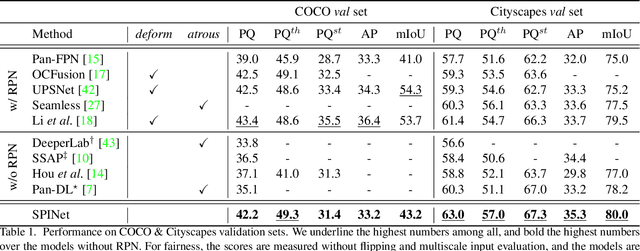
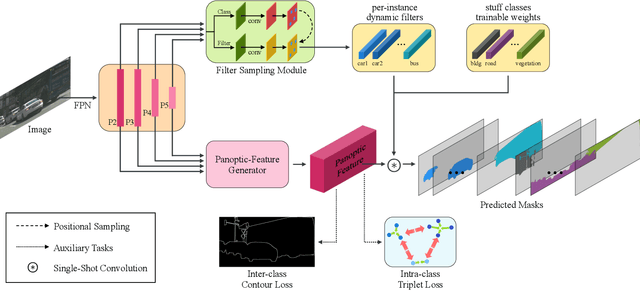
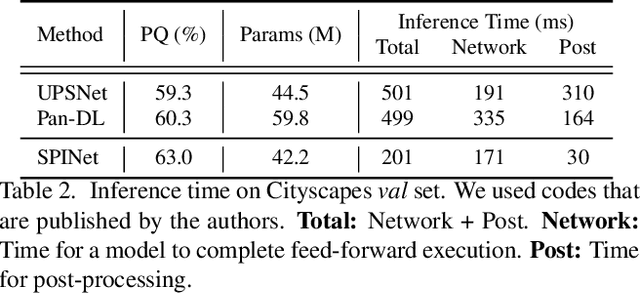
Panoptic segmentation, which is a novel task of unifying instance segmentation and semantic segmentation, has attracted a lot of attention lately. However, most of the previous methods are composed of multiple pathways with each pathway specialized to a designated segmentation task. In this paper, we propose to resolve panoptic segmentation in single-shot by integrating the execution flows. With the integrated pathway, a unified feature map called Panoptic-Feature is generated, which includes the information of both things and stuffs. Panoptic-Feature becomes more sophisticated by auxiliary problems that guide to cluster pixels that belong to the same instance and differentiate between objects of different classes. A collection of convolutional filters, where each filter represents either a thing or stuff, is applied to Panoptic-Feature at once, materializing the single-shot panoptic segmentation. Taking the advantages of both top-down and bottom-up approaches, our method, named SPINet, enjoys high efficiency and accuracy on major panoptic segmentation benchmarks: COCO and Cityscapes.
Cross-Identity Motion Transfer for Arbitrary Objects through Pose-Attentive Video Reassembling
Jul 17, 2020
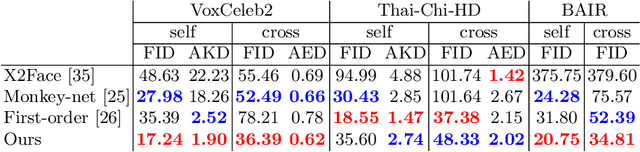
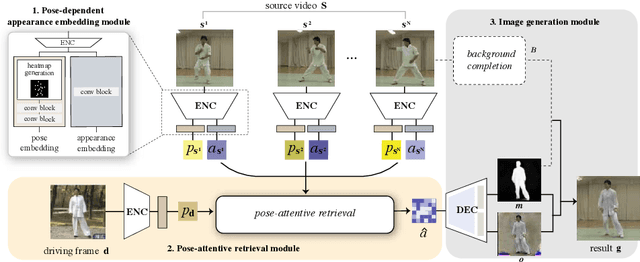
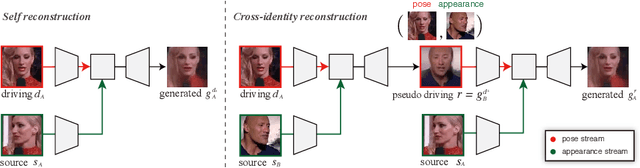
We propose an attention-based networks for transferring motions between arbitrary objects. Given a source image(s) and a driving video, our networks animate the subject in the source images according to the motion in the driving video. In our attention mechanism, dense similarities between the learned keypoints in the source and the driving images are computed in order to retrieve the appearance information from the source images. Taking a different approach from the well-studied warping based models, our attention-based model has several advantages. By reassembling non-locally searched pieces from the source contents, our approach can produce more realistic outputs. Furthermore, our system can make use of multiple observations of the source appearance (e.g. front and sides of faces) to make the results more accurate. To reduce the training-testing discrepancy of the self-supervised learning, a novel cross-identity training scheme is additionally introduced. With the training scheme, our networks is trained to transfer motions between different subjects, as in the real testing scenario. Experimental results validate that our method produces visually pleasing results in various object domains, showing better performances compared to previous works.
NTIRE 2020 Challenge on Perceptual Extreme Super-Resolution: Methods and Results
May 03, 2020
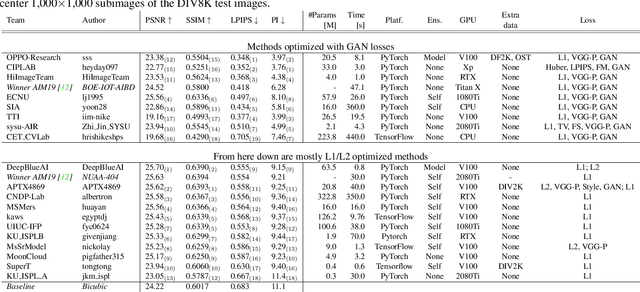

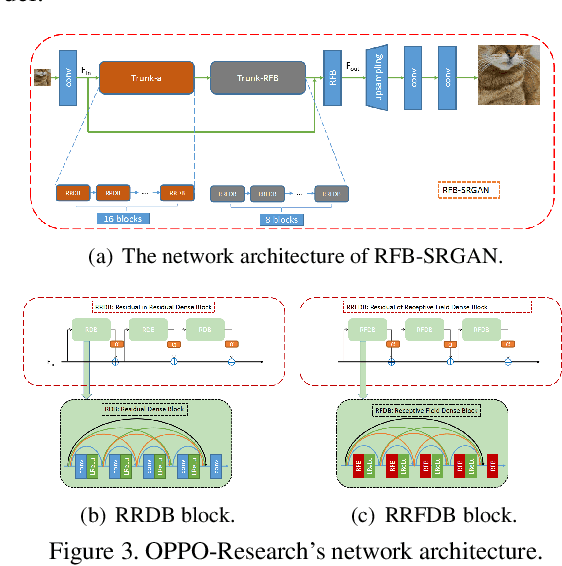
This paper reviews the NTIRE 2020 challenge on perceptual extreme super-resolution with focus on proposed solutions and results. The challenge task was to super-resolve an input image with a magnification factor 16 based on a set of prior examples of low and corresponding high resolution images. The goal is to obtain a network design capable to produce high resolution results with the best perceptual quality and similar to the ground truth. The track had 280 registered participants, and 19 teams submitted the final results. They gauge the state-of-the-art in single image super-resolution.