 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniSkill: Imitating Human Videos via Cross-Embodiment Skill Representations
May 15, 2025Mimicry is a fundamental learning mechanism in humans, enabling individuals to learn new tasks by observing and imitating experts. However, applying this ability to robots presents significant challenges due to the inherent differences between human and robot embodiments in both their visual appearance and physical capabilities. While previous methods bridge this gap using cross-embodiment datasets with shared scenes and tasks, collecting such aligned data between humans and robots at scale is not trivial. In this paper, we propose UniSkill, a novel framework that learns embodiment-agnostic skill representations from large-scale cross-embodiment video data without any labels, enabling skills extracted from human video prompts to effectively transfer to robot policies trained only on robot data. Our experiments in both simulation and real-world environments show that our cross-embodiment skills successfully guide robots in selecting appropriate actions, even with unseen video prompts. The project website can be found at: https://kimhanjung.github.io/UniSkill.
ActionSwitch: Class-agnostic Detection of Simultaneous Actions in Streaming Videos
Jul 17, 2024



Online Temporal Action Localization (On-TAL) is a critical task that aims to instantaneously identify action instances in untrimmed streaming videos as soon as an action concludes -- a major leap from frame-based Online Action Detection (OAD). Yet, the challenge of detecting overlapping actions is often overlooked even though it is a common scenario in streaming videos. Current methods that can address concurrent actions depend heavily on class information, limiting their flexibility. This paper introduces ActionSwitch, the first class-agnostic On-TAL framework capable of detecting overlapping actions. By obviating the reliance on class information, ActionSwitch provides wider applicability to various situations, including overlapping actions of the same class or scenarios where class information is unavailable. This approach is complemented by the proposed "conservativeness loss", which directly embeds a conservative decision-making principle into the loss function for On-TAL. Our ActionSwitch achieves state-of-the-art performance in complex datasets, including Epic-Kitchens 100 targeting the challenging egocentric view and FineAction consisting of fine-grained actions.
Exploring Scalability of Self-Training for Open-Vocabulary Temporal Action Localization
Jul 09, 2024The vocabulary size in temporal action localization (TAL) is constrained by the scarcity of large-scale annotated datasets. To address this, recent works incorporate powerful pre-trained vision-language models (VLMs), such as CLIP, to perform open-vocabulary TAL (OV-TAL). However, unlike VLMs trained on extensive image/video-text pairs, existing OV-TAL methods still rely on small, fully labeled TAL datasets for training an action localizer. In this paper, we explore the scalability of self-training with unlabeled YouTube videos for OV-TAL. Our self-training approach consists of two stages. First, a class-agnostic action localizer is trained on a human-labeled TAL dataset and used to generate pseudo-labels for unlabeled videos. Second, the large-scale pseudo-labeled dataset is combined with the human-labeled dataset to train the localizer. Extensive experiments demonstrate that leveraging web-scale videos in self-training significantly enhances the generalizability of an action localizer. Additionally, we highlighted issues with existing OV-TAL evaluation schemes and proposed a new evaluation protocol. Code is released at https://github.com/HYUNJS/STOV-TAL
Object Aware Egocentric Online Action Detection
Jun 03, 2024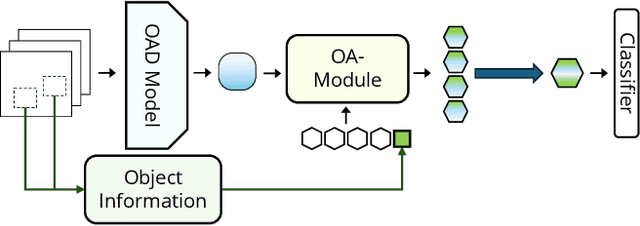
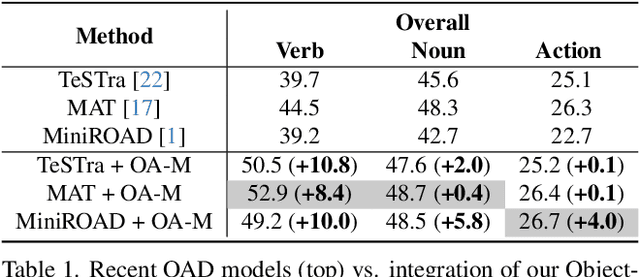
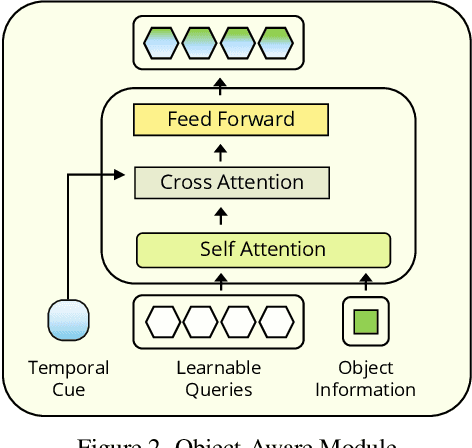
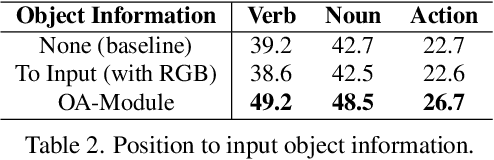
Advancements in egocentric video datasets like Ego4D, EPIC-Kitchens, and Ego-Exo4D have enriched the study of first-person human interactions, which is crucial for applications in augmented reality and assisted living. Despite these advancements, current Online Action Detection methods, which efficiently detect actions in streaming videos, are predominantly designed for exocentric views and thus fail to capitalize on the unique perspectives inherent to egocentric videos. To address this gap, we introduce an Object-Aware Module that integrates egocentric-specific priors into existing OAD frameworks, enhancing first-person footage interpretation. Utilizing object-specific details and temporal dynamics, our module improves scene understanding in detecting actions. Validated extensively on the Epic-Kitchens 100 dataset, our work can be seamlessly integrated into existing models with minimal overhead and bring consistent performance enhancements, marking an important step forward in adapting action detection systems to egocentric video analysis.
ComMU: Dataset for Combinatorial Music Generation
Nov 17, 2022



Commercial adoption of automatic music composition requires the capability of generating diverse and high-quality music suitable for the desired context (e.g., music for romantic movies, action games, restaurants, etc.). In this paper, we introduce combinatorial music generation, a new task to create varying background music based on given conditions. Combinatorial music generation creates short samples of music with rich musical metadata, and combines them to produce a complete music. In addition, we introduce ComMU, the first symbolic music dataset consisting of short music samples and their corresponding 12 musical metadata for combinatorial music generation. Notable properties of ComMU are that (1) dataset is manually constructed by professional composers with an objective guideline that induces regularity, and (2) it has 12 musical metadata that embraces composers' intentions. Our results show that we can generate diverse high-quality music only with metadata, and that our unique metadata such as track-role and extended chord quality improves the capacity of the automatic composition. We highly recommend watching our video before reading the paper (https://pozalabs.github.io/ComMU).
Soft-Landing Strategy for Alleviating the Task Discrepancy Problem in Temporal Action Localization Tasks
Nov 11, 2022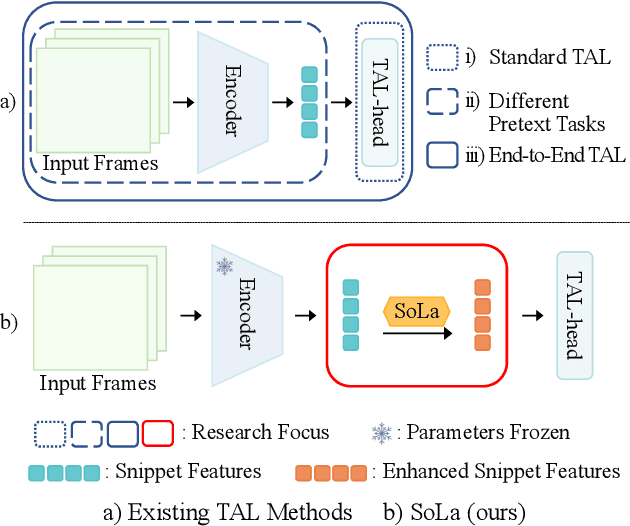
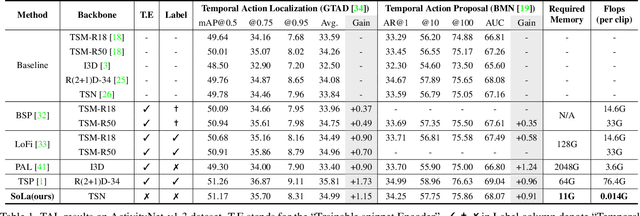
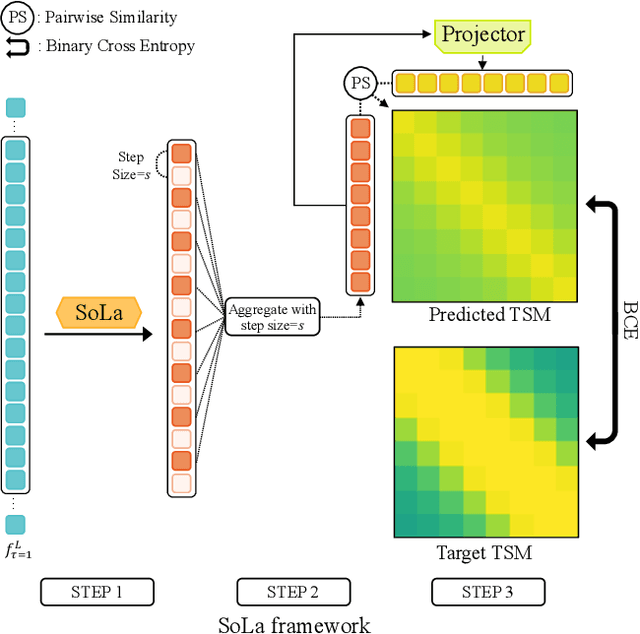
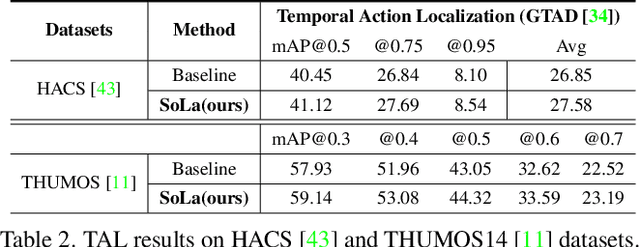
Temporal Action Localization (TAL) methods typically operate on top of feature sequences from a frozen snippet encoder that is pretrained with the Trimmed Action Classification (TAC) tasks, resulting in a task discrepancy problem. While existing TAL methods mitigate this issue either by retraining the encoder with a pretext task or by end-to-end fine-tuning, they commonly require an overload of high memory and computation. In this work, we introduce Soft-Landing (SoLa) strategy, an efficient yet effective framework to bridge the transferability gap between the pretrained encoder and the downstream tasks by incorporating a light-weight neural network, i.e., a SoLa module, on top of the frozen encoder. We also propose an unsupervised training scheme for the SoLa module; it learns with inter-frame Similarity Matching that uses the frame interval as its supervisory signal, eliminating the need for temporal annotations. Experimental evaluation on various benchmarks for downstream TAL tasks shows that our method effectively alleviates the task discrepancy problem with remarkable computational efficiency.
UBoCo : Unsupervised Boundary Contrastive Learning for Generic Event Boundary Detection
Nov 30, 2021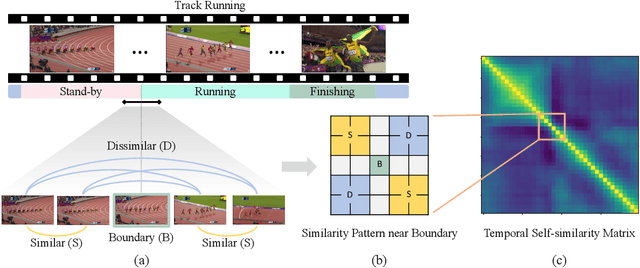
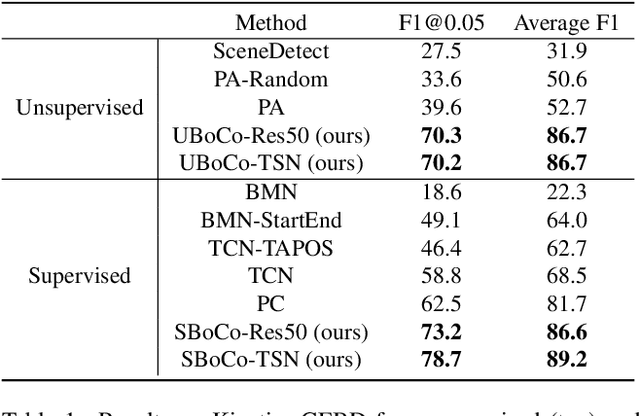
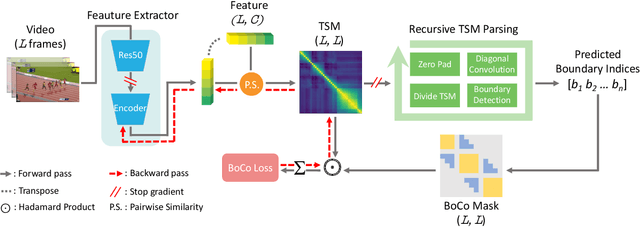
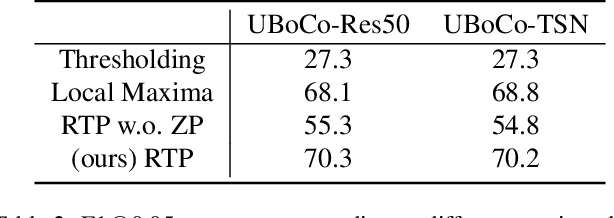
Generic Event Boundary Detection (GEBD) is a newly suggested video understanding task that aims to find one level deeper semantic boundaries of events. Bridging the gap between natural human perception and video understanding, it has various potential applications, including interpretable and semantically valid video parsing. Still at an early development stage, existing GEBD solvers are simple extensions of relevant video understanding tasks, disregarding GEBD's distinctive characteristics. In this paper, we propose a novel framework for unsupervised/supervised GEBD, by using the Temporal Self-similarity Matrix (TSM) as the video representation. The new Recursive TSM Parsing (RTP) algorithm exploits local diagonal patterns in TSM to detect boundaries, and it is combined with the Boundary Contrastive (BoCo) loss to train our encoder to generate more informative TSMs. Our framework can be applied to both unsupervised and supervised settings, with both achieving state-of-the-art performance by a huge margin in GEBD benchmark. Especially, our unsupervised method outperforms the previous state-of-the-art "supervised" model, implying its exceptional efficacy.
Winning the CVPR'2021 Kinetics-GEBD Challenge: Contrastive Learning Approach
Jun 22, 2021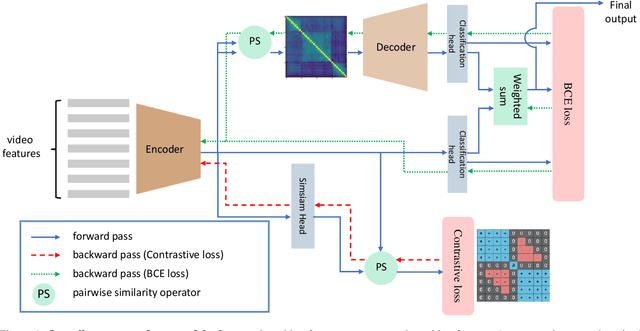
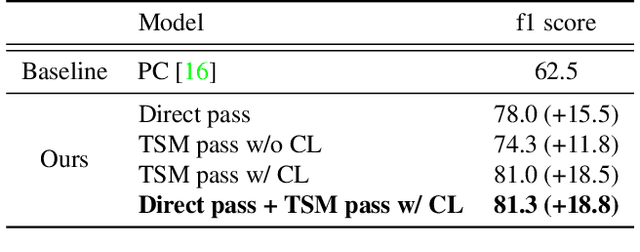
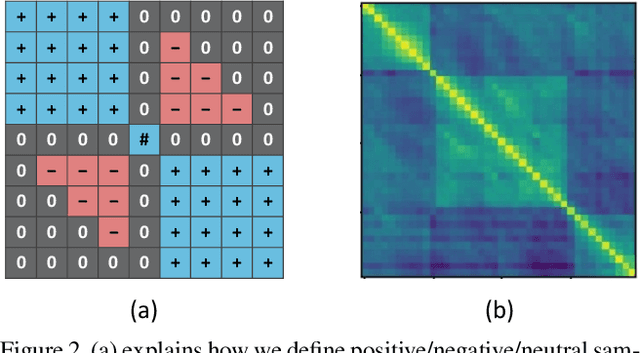
Generic Event Boundary Detection (GEBD) is a newly introduced task that aims to detect "general" event boundaries that correspond to natural human perception. In this paper, we introduce a novel contrastive learning based approach to deal with the GEBD. Our intuition is that the feature similarity of the video snippet would significantly vary near the event boundaries, while remaining relatively the same in the remaining part of the video. In our model, Temporal Self-similarity Matrix (TSM) is utilized as an intermediate representation which takes on a role as an information bottleneck. With our model, we achieved significant performance boost compared to the given baselines. Our code is available at https://github.com/hello-jinwoo/LOVEU-CVPR2021.
Mature GAIL: Imitation Learning for Low-level and High-dimensional Input using Global Encoder and Cost Transformation
Sep 07, 2019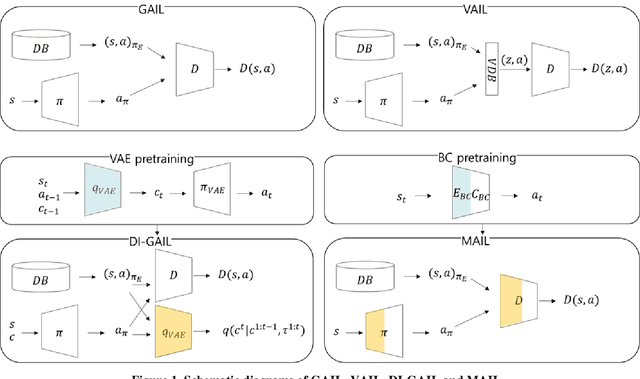
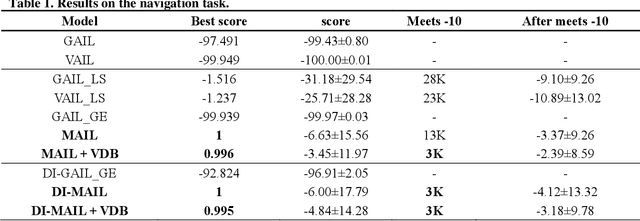
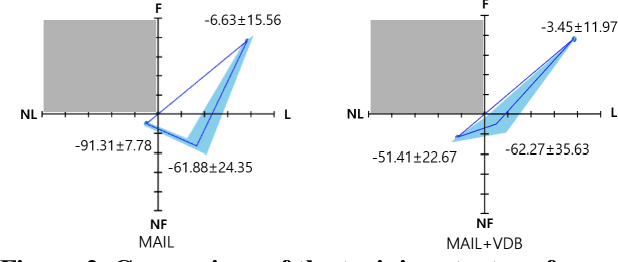
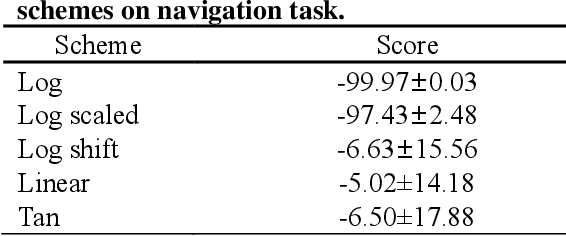
Recently, GAIL framework and various variants have shown remarkable possibilities for solving practical MDP problems. However, detailed researches of low-level, and high-dimensional state input in this framework, such as image sequences, has not been conducted. Furthermore, the cost function learned in the traditional GAIL frame-work only lies on a negative range, acting as a non-penalized reward and making the agent difficult to learn the optimal policy. In this paper, we propose a new algorithm based on the GAIL framework that includes a global encoder and the reward penalization mechanism. The global encoder solves two issues that arise when applying GAIL framework to high-dimensional image state. Also, it is shown that the penalization mechanism provides more adequate reward to the agent, resulting in stable performance improvement. Our approach's potential can be backed up by the fact that it is generally applicable to variants of GAIL framework. We conducted in-depth experiments by applying our methods to various variants of the GAIL framework. And, the results proved that our method significantly improves the performances when it comes to low-level and high-dimensional tasks.