 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotif-2-12.7B-Reasoning: A Practitioner's Guide to RL Training Recipes
Dec 11, 2025We introduce Motif-2-12.7B-Reasoning, a 12.7B parameter language model designed to bridge the gap between open-weight systems and proprietary frontier models in complex reasoning and long-context understanding. Addressing the common challenges of model collapse and training instability in reasoning adaptation, we propose a comprehensive, reproducible training recipe spanning system, data, and algorithmic optimizations. Our approach combines memory-efficient infrastructure for 64K-token contexts using hybrid parallelism and kernel-level optimizations with a two-stage Supervised Fine-Tuning (SFT) curriculum that mitigates distribution mismatch through verified, aligned synthetic data. Furthermore, we detail a robust Reinforcement Learning Fine-Tuning (RLFT) pipeline that stabilizes training via difficulty-aware data filtering and mixed-policy trajectory reuse. Empirical results demonstrate that Motif-2-12.7B-Reasoning achieves performance comparable to models with significantly larger parameter counts across mathematics, coding, and agentic benchmarks, offering the community a competitive open model and a practical blueprint for scaling reasoning capabilities under realistic compute constraints.
Motif 2 12.7B technical report
Nov 07, 2025We introduce Motif-2-12.7B, a new open-weight foundation model that pushes the efficiency frontier of large language models by combining architectural innovation with system-level optimization. Designed for scalable language understanding and robust instruction generalization under constrained compute budgets, Motif-2-12.7B builds upon Motif-2.6B with the integration of Grouped Differential Attention (GDA), which improves representational efficiency by disentangling signal and noise-control attention pathways. The model is pre-trained on 5.5 trillion tokens spanning diverse linguistic, mathematical, scientific, and programming domains using a curriculum-driven data scheduler that gradually changes the data composition ratio. The training system leverages the MuonClip optimizer alongside custom high-performance kernels, including fused PolyNorm activations and the Parallel Muon algorithm, yielding significant throughput and memory efficiency gains in large-scale distributed environments. Post-training employs a three-stage supervised fine-tuning pipeline that successively enhances general instruction adherence, compositional understanding, and linguistic precision. Motif-2-12.7B demonstrates competitive performance across diverse benchmarks, showing that thoughtful architectural scaling and optimized training design can rival the capabilities of much larger models.
Multi-channel convolutional neural quantum embedding
Sep 26, 2025



Classification using variational quantum circuits is a promising frontier in quantum machine learning. Quantum supervised learning (QSL) applied to classical data using variational quantum circuits involves embedding the data into a quantum Hilbert space and optimizing the circuit parameters to train the measurement process. In this context, the efficacy of QSL is inherently influenced by the selection of quantum embedding. In this study, we introduce a classical-quantum hybrid approach for optimizing quantum embedding beyond the limitations of the standard circuit model of quantum computation (i.e., completely positive and trace-preserving maps) for general multi-channel data. We benchmark the performance of various models in our framework using the CIFAR-10 and Tiny ImageNet datasets and provide theoretical analyses that guide model design and optimization.
Expanding Foundational Language Capabilities in Open-Source LLMs through a Korean Case Study
Sep 04, 2025We introduce Llama-3-Motif, a language model consisting of 102 billion parameters, specifically designed to enhance Korean capabilities while retaining strong performance in English. Developed on the Llama 3 architecture, Llama-3-Motif employs advanced training techniques, including LlamaPro and Masked Structure Growth, to effectively scale the model without altering its core Transformer architecture. Using the MoAI platform for efficient training across hyperscale GPU clusters, we optimized Llama-3-Motif using a carefully curated dataset that maintains a balanced ratio of Korean and English data. Llama-3-Motif shows decent performance on Korean-specific benchmarks, outperforming existing models and achieving results comparable to GPT-4.
MoNDE: Mixture of Near-Data Experts for Large-Scale Sparse Models
May 29, 2024



Mixture-of-Experts (MoE) large language models (LLM) have memory requirements that often exceed the GPU memory capacity, requiring costly parameter movement from secondary memories to the GPU for expert computation. In this work, we present Mixture of Near-Data Experts (MoNDE), a near-data computing solution that efficiently enables MoE LLM inference. MoNDE reduces the volume of MoE parameter movement by transferring only the $\textit{hot}$ experts to the GPU, while computing the remaining $\textit{cold}$ experts inside the host memory device. By replacing the transfers of massive expert parameters with the ones of small activations, MoNDE enables far more communication-efficient MoE inference, thereby resulting in substantial speedups over the existing parameter offloading frameworks for both encoder and decoder operations.
Embracing Limited and Imperfect Data: A Review on Plant Stress Recognition Using Deep Learning
May 19, 2023Plant stress recognition has witnessed significant improvements in recent years with the advent of deep learning. A large-scale and annotated training dataset is required to achieve decent performance; however, collecting it is frequently difficult and expensive. Therefore, deploying current deep learning-based methods in real-world applications may suffer primarily from limited and imperfect data. Embracing them is a promising strategy that has not received sufficient attention. From this perspective, a systematic survey was conducted in this study, with the ultimate objective of monitoring plant growth by implementing deep learning, which frees humans and potentially reduces the resultant losses from plant stress. We believe that our paper has highlighted the importance of embracing this limited and imperfect data and enhanced its relevant understanding.
ComMU: Dataset for Combinatorial Music Generation
Nov 17, 2022



Commercial adoption of automatic music composition requires the capability of generating diverse and high-quality music suitable for the desired context (e.g., music for romantic movies, action games, restaurants, etc.). In this paper, we introduce combinatorial music generation, a new task to create varying background music based on given conditions. Combinatorial music generation creates short samples of music with rich musical metadata, and combines them to produce a complete music. In addition, we introduce ComMU, the first symbolic music dataset consisting of short music samples and their corresponding 12 musical metadata for combinatorial music generation. Notable properties of ComMU are that (1) dataset is manually constructed by professional composers with an objective guideline that induces regularity, and (2) it has 12 musical metadata that embraces composers' intentions. Our results show that we can generate diverse high-quality music only with metadata, and that our unique metadata such as track-role and extended chord quality improves the capacity of the automatic composition. We highly recommend watching our video before reading the paper (https://pozalabs.github.io/ComMU).
UBoCo : Unsupervised Boundary Contrastive Learning for Generic Event Boundary Detection
Nov 30, 2021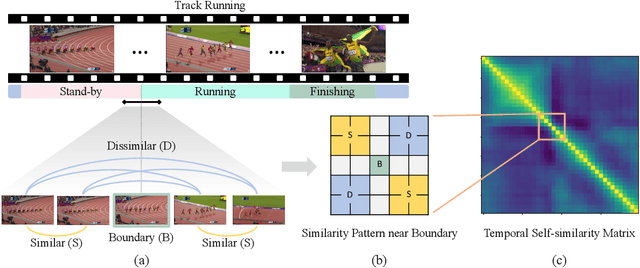
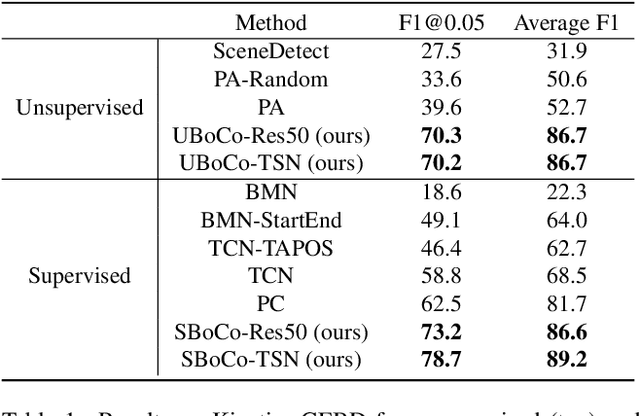
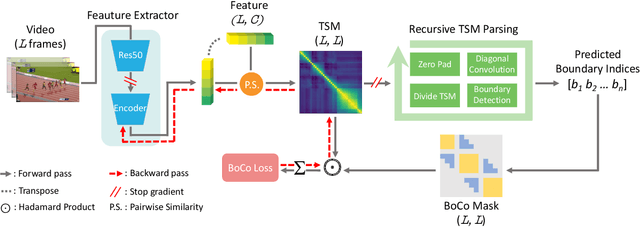
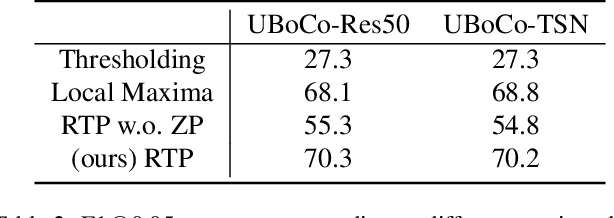
Generic Event Boundary Detection (GEBD) is a newly suggested video understanding task that aims to find one level deeper semantic boundaries of events. Bridging the gap between natural human perception and video understanding, it has various potential applications, including interpretable and semantically valid video parsing. Still at an early development stage, existing GEBD solvers are simple extensions of relevant video understanding tasks, disregarding GEBD's distinctive characteristics. In this paper, we propose a novel framework for unsupervised/supervised GEBD, by using the Temporal Self-similarity Matrix (TSM) as the video representation. The new Recursive TSM Parsing (RTP) algorithm exploits local diagonal patterns in TSM to detect boundaries, and it is combined with the Boundary Contrastive (BoCo) loss to train our encoder to generate more informative TSMs. Our framework can be applied to both unsupervised and supervised settings, with both achieving state-of-the-art performance by a huge margin in GEBD benchmark. Especially, our unsupervised method outperforms the previous state-of-the-art "supervised" model, implying its exceptional efficacy.
Winning the CVPR'2021 Kinetics-GEBD Challenge: Contrastive Learning Approach
Jun 22, 2021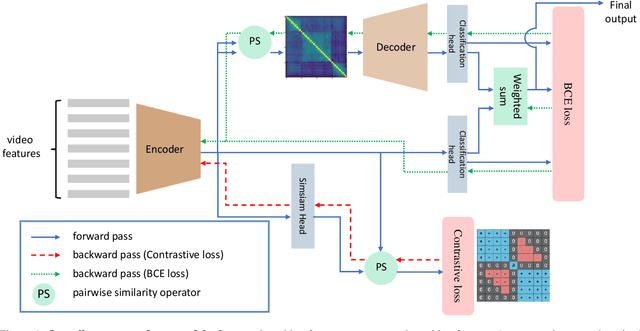
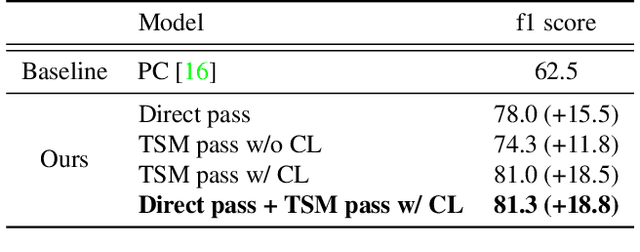
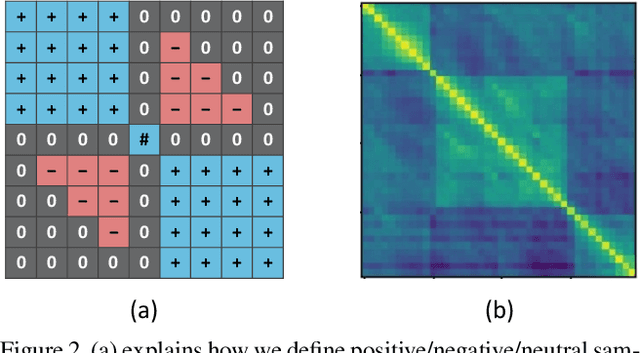
Generic Event Boundary Detection (GEBD) is a newly introduced task that aims to detect "general" event boundaries that correspond to natural human perception. In this paper, we introduce a novel contrastive learning based approach to deal with the GEBD. Our intuition is that the feature similarity of the video snippet would significantly vary near the event boundaries, while remaining relatively the same in the remaining part of the video. In our model, Temporal Self-similarity Matrix (TSM) is utilized as an intermediate representation which takes on a role as an information bottleneck. With our model, we achieved significant performance boost compared to the given baselines. Our code is available at https://github.com/hello-jinwoo/LOVEU-CVPR2021.
GradPIM: A Practical Processing-in-DRAM Architecture for Gradient Descent
Feb 15, 2021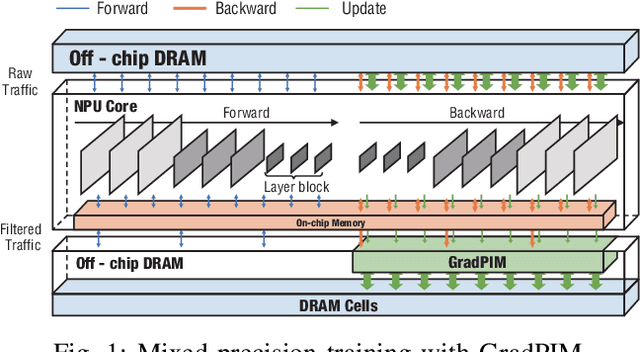
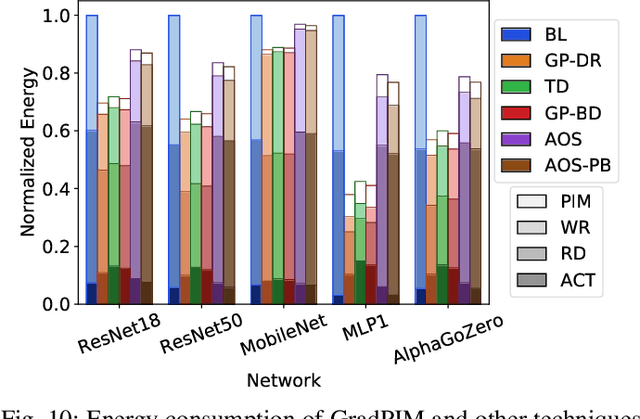
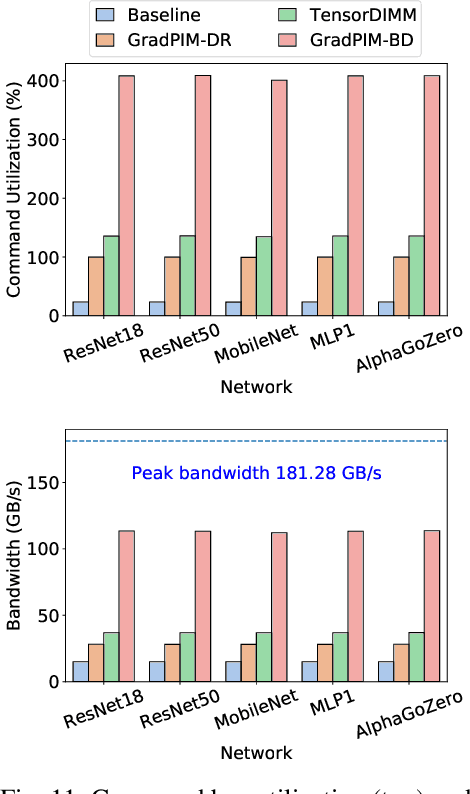
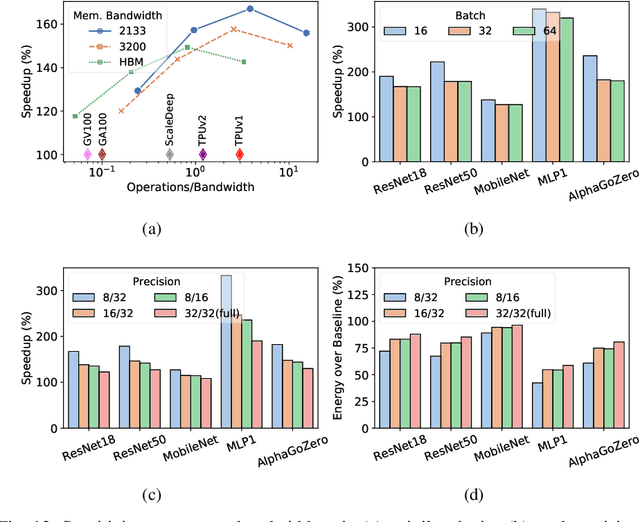
In this paper, we present GradPIM, a processing-in-memory architecture which accelerates parameter updates of deep neural networks training. As one of processing-in-memory techniques that could be realized in the near future, we propose an incremental, simple architectural design that does not invade the existing memory protocol. Extending DDR4 SDRAM to utilize bank-group parallelism makes our operation designs in processing-in-memory (PIM) module efficient in terms of hardware cost and performance. Our experimental results show that the proposed architecture can improve the performance of DNN training and greatly reduce memory bandwidth requirement while posing only a minimal amount of overhead to the protocol and DRAM area.