 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRome was built in 1776: A Case Study on Factual Correctness in Knowledge-Grounded Response Generation
Oct 11, 2021
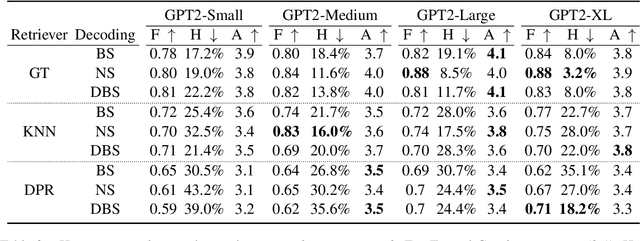


Recently neural response generation models have leveraged large pre-trained transformer models and knowledge snippets to generate relevant and informative responses. However, this does not guarantee that generated responses are factually correct. In this paper, we examine factual correctness in knowledge-grounded neural response generation models. We present a human annotation setup to identify three different response types: responses that are factually consistent with respect to the input knowledge, responses that contain hallucinated knowledge, and non-verifiable chitchat style responses. We use this setup to annotate responses generated using different stateof-the-art models, knowledge snippets, and decoding strategies. In addition, to facilitate the development of a factual consistency detector, we automatically create a new corpus called Conv-FEVER that is adapted from the Wizard of Wikipedia dataset and includes factually consistent and inconsistent responses. We demonstrate the benefit of our Conv-FEVER dataset by showing that the models trained on this data perform reasonably well to detect factually inconsistent responses with respect to the provided knowledge through evaluation on our human annotated data. We will release the Conv-FEVER dataset and the human annotated responses.
"How Robust r u?": Evaluating Task-Oriented Dialogue Systems on Spoken Conversations
Sep 28, 2021
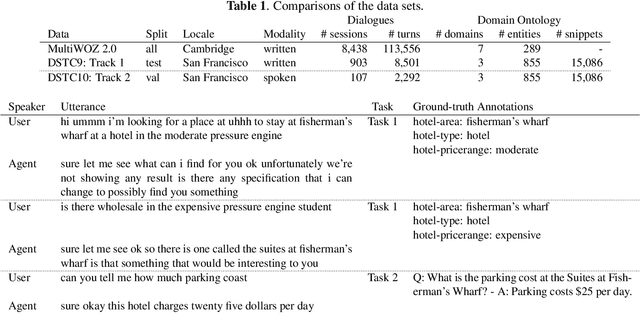
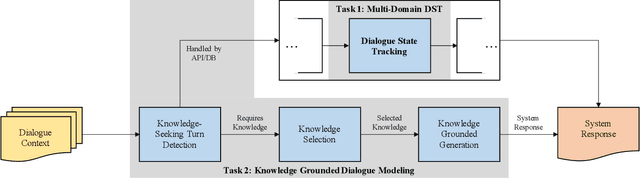

Most prior work in dialogue modeling has been on written conversations mostly because of existing data sets. However, written dialogues are not sufficient to fully capture the nature of spoken conversations as well as the potential speech recognition errors in practical spoken dialogue systems. This work presents a new benchmark on spoken task-oriented conversations, which is intended to study multi-domain dialogue state tracking and knowledge-grounded dialogue modeling. We report that the existing state-of-the-art models trained on written conversations are not performing well on our spoken data, as expected. Furthermore, we observe improvements in task performances when leveraging n-best speech recognition hypotheses such as by combining predictions based on individual hypotheses. Our data set enables speech-based benchmarking of task-oriented dialogue systems.
Commonsense-Focused Dialogues for Response Generation: An Empirical Study
Sep 21, 2021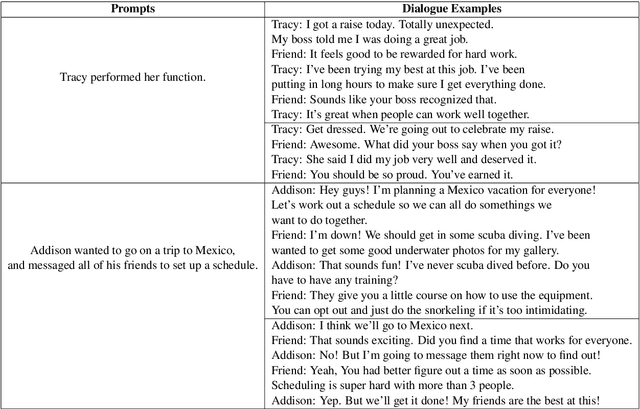
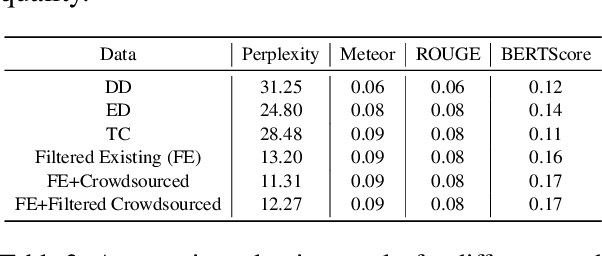
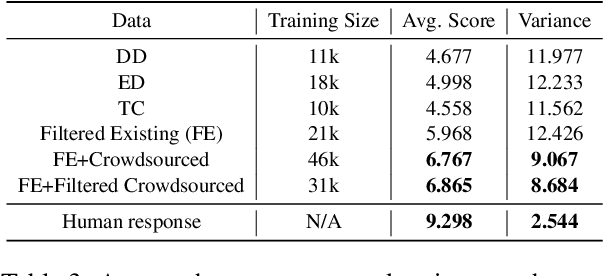
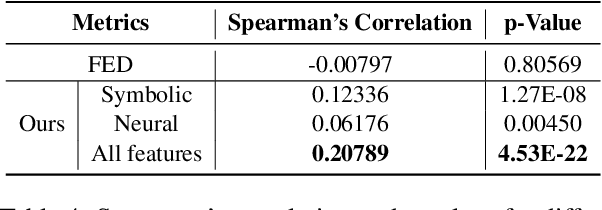
Smooth and effective communication requires the ability to perform latent or explicit commonsense inference. Prior commonsense reasoning benchmarks (such as SocialIQA and CommonsenseQA) mainly focus on the discriminative task of choosing the right answer from a set of candidates, and do not involve interactive language generation as in dialogue. Moreover, existing dialogue datasets do not explicitly focus on exhibiting commonsense as a facet. In this paper, we present an empirical study of commonsense in dialogue response generation. We first auto-extract commonsensical dialogues from existing dialogue datasets by leveraging ConceptNet, a commonsense knowledge graph. Furthermore, building on social contexts/situations in SocialIQA, we collect a new dialogue dataset with 25K dialogues aimed at exhibiting social commonsense in an interactive setting. We evaluate response generation models trained using these datasets and find that models trained on both extracted and our collected data produce responses that consistently exhibit more commonsense than baselines. Finally we propose an approach for automatic evaluation of commonsense that relies on features derived from ConceptNet and pre-trained language and dialog models, and show reasonable correlation with human evaluation of responses' commonsense quality. We are releasing a subset of our collected data, Commonsense-Dialogues, containing about 11K dialogs.
Towards Zero and Few-shot Knowledge-seeking Turn Detection in Task-orientated Dialogue Systems
Sep 18, 2021
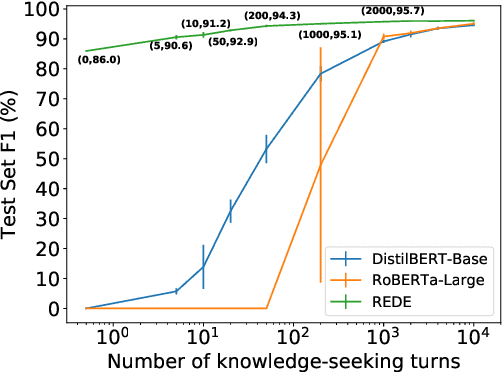
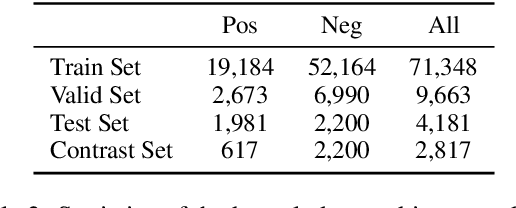
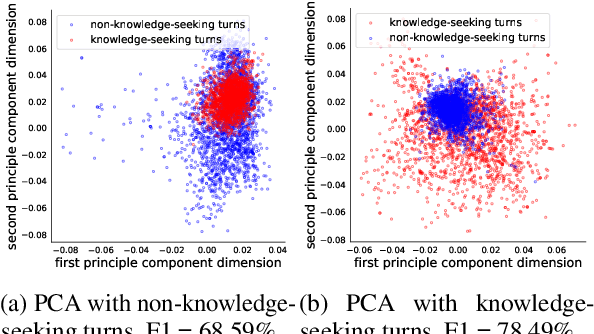
Most prior work on task-oriented dialogue systems is restricted to supporting domain APIs. However, users may have requests that are out of the scope of these APIs. This work focuses on identifying such user requests. Existing methods for this task mainly rely on fine-tuning pre-trained models on large annotated data. We propose a novel method, REDE, based on adaptive representation learning and density estimation. REDE can be applied to zero-shot cases, and quickly learns a high-performing detector with only a few shots by updating less than 3K parameters. We demonstrate REDE's competitive performance on DSTC9 data and our newly collected test set.
Can I Be of Further Assistance? Using Unstructured Knowledge Access to Improve Task-oriented Conversational Modeling
Jun 16, 2021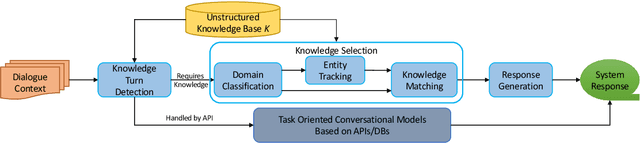

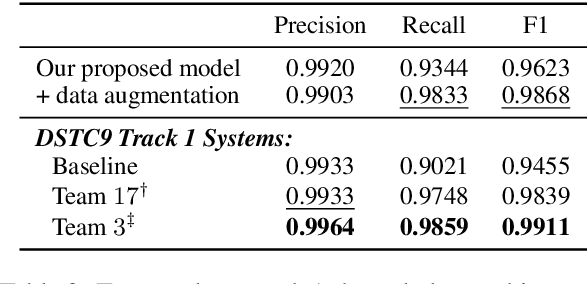
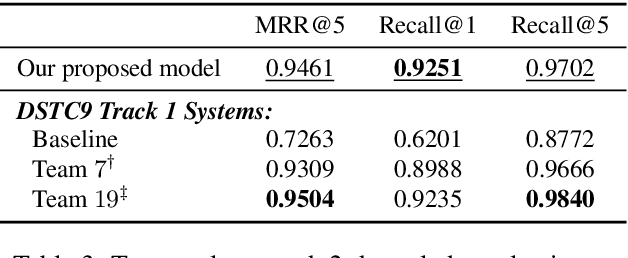
Most prior work on task-oriented dialogue systems are restricted to limited coverage of domain APIs. However, users oftentimes have requests that are out of the scope of these APIs. This work focuses on responding to these beyond-API-coverage user turns by incorporating external, unstructured knowledge sources. Our approach works in a pipelined manner with knowledge-seeking turn detection, knowledge selection, and response generation in sequence. We introduce novel data augmentation methods for the first two steps and demonstrate that the use of information extracted from dialogue context improves the knowledge selection and end-to-end performances. Through experiments, we achieve state-of-the-art performance for both automatic and human evaluation metrics on the DSTC9 Track 1 benchmark dataset, validating the effectiveness of our contributions.
Generative Conversational Networks
Jun 15, 2021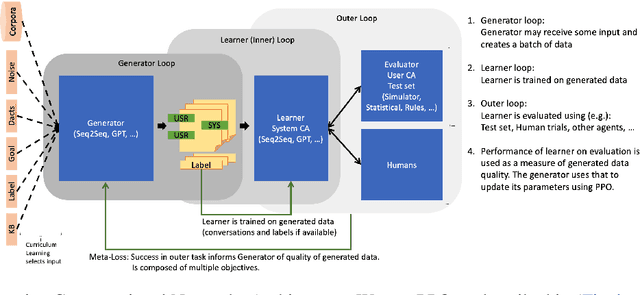
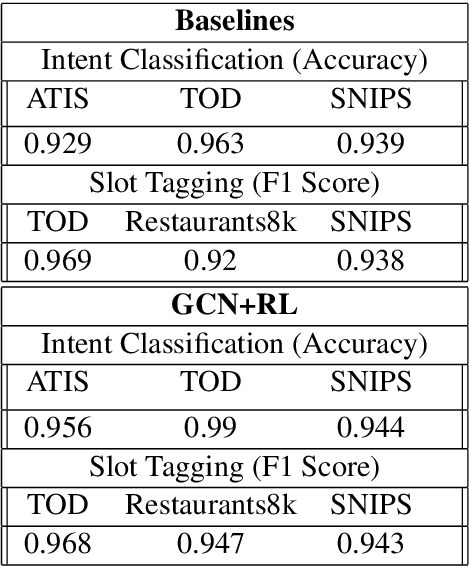
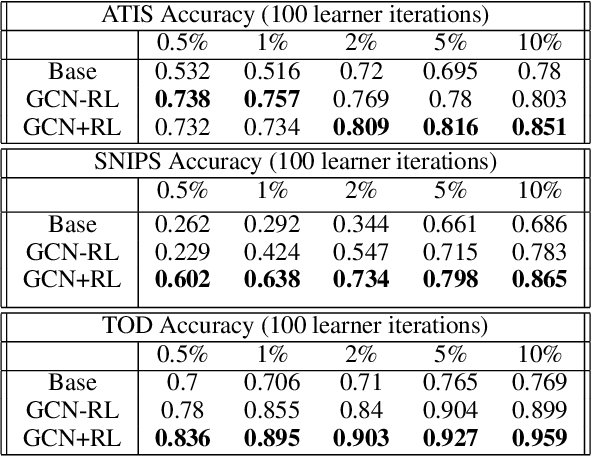
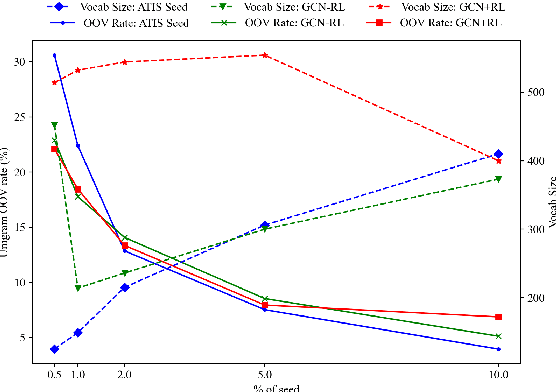
Inspired by recent work in meta-learning and generative teaching networks, we propose a framework called Generative Conversational Networks, in which conversational agents learn to generate their own labelled training data (given some seed data) and then train themselves from that data to perform a given task. We use reinforcement learning to optimize the data generation process where the reward signal is the agent's performance on the task. The task can be any language-related task, from intent detection to full task-oriented conversations. In this work, we show that our approach is able to generalise from seed data and performs well in limited data and limited computation settings, with significant gains for intent detection and slot tagging across multiple datasets: ATIS, TOD, SNIPS, and Restaurants8k. We show an average improvement of 35% in intent detection and 21% in slot tagging over a baseline model trained from the seed data. We also conduct an analysis of the novelty of the generated data and provide generated examples for intent detection, slot tagging, and non-goal oriented conversations.
Beyond Domain APIs: Task-oriented Conversational Modeling with Unstructured Knowledge Access Track in DSTC9
Feb 04, 2021
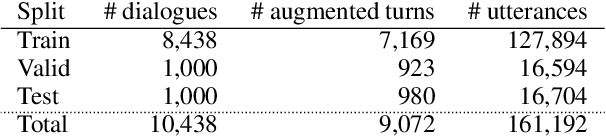
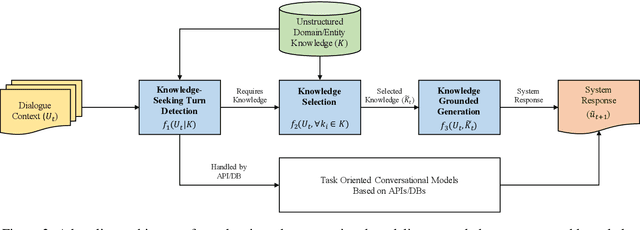

Most prior work on task-oriented dialogue systems are restricted to a limited coverage of domain APIs, while users oftentimes have domain related requests that are not covered by the APIs. This challenge track aims to expand the coverage of task-oriented dialogue systems by incorporating external unstructured knowledge sources. We define three tasks: knowledge-seeking turn detection, knowledge selection, and knowledge-grounded response generation. We introduce the data sets and the neural baseline models for three tasks. The challenge track received a total of 105 entries from 24 participating teams. In the evaluation results, the ensemble methods with different large-scale pretrained language models achieved high performances with improved knowledge selection capability and better generalization into unseen data.
Overview of the Ninth Dialog System Technology Challenge: DSTC9
Nov 12, 2020
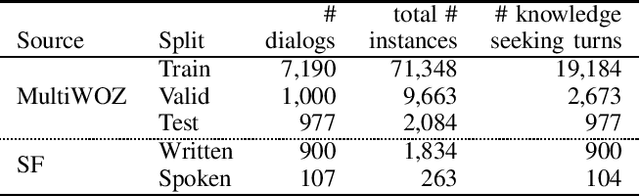

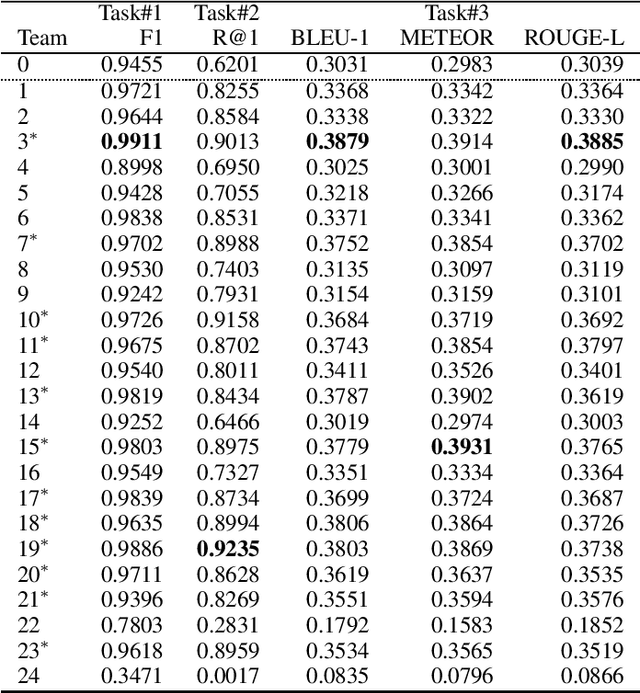
This paper introduces the Ninth Dialog System Technology Challenge (DSTC-9). This edition of the DSTC focuses on applying end-to-end dialog technologies for four distinct tasks in dialog systems, namely, 1. Task-oriented dialog Modeling with unstructured knowledge access, 2. Multi-domain task-oriented dialog, 3. Interactive evaluation of dialog, and 4. Situated interactive multi-modal dialog. This paper describes the task definition, provided datasets, baselines and evaluation set-up for each track. We also summarize the results of the submitted systems to highlight the overall trends of the state-of-the-art technologies for the tasks.
Video Question Answering on Screencast Tutorials
Aug 02, 2020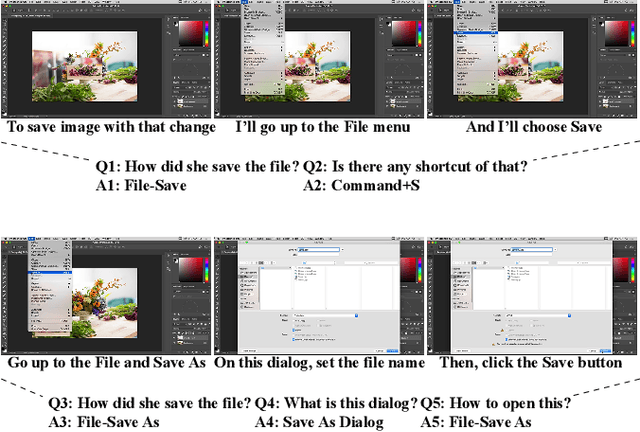
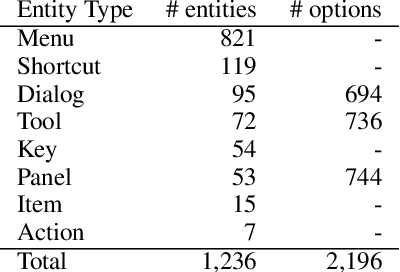
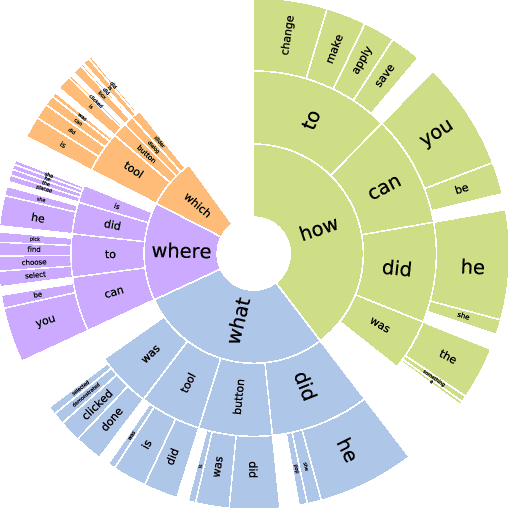
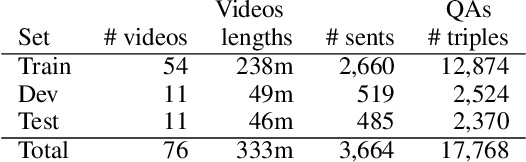
This paper presents a new video question answering task on screencast tutorials. We introduce a dataset including question, answer and context triples from the tutorial videos for a software. Unlike other video question answering works, all the answers in our dataset are grounded to the domain knowledge base. An one-shot recognition algorithm is designed to extract the visual cues, which helps enhance the performance of video question answering. We also propose several baseline neural network architectures based on various aspects of video contexts from the dataset. The experimental results demonstrate that our proposed models significantly improve the question answering performances by incorporating multi-modal contexts and domain knowledge.
Policy-Driven Neural Response Generation for Knowledge-Grounded Dialogue Systems
Jun 09, 2020
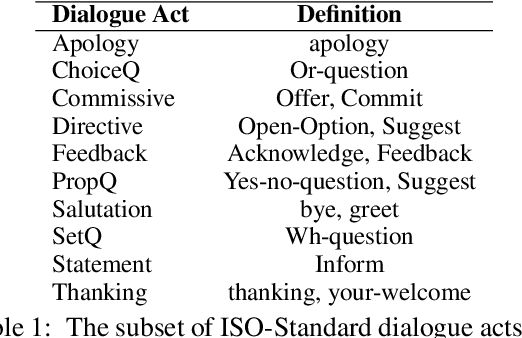
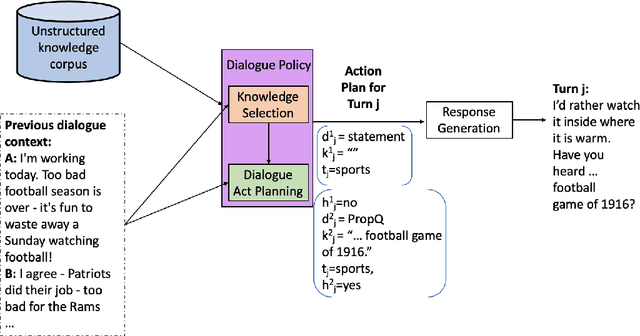
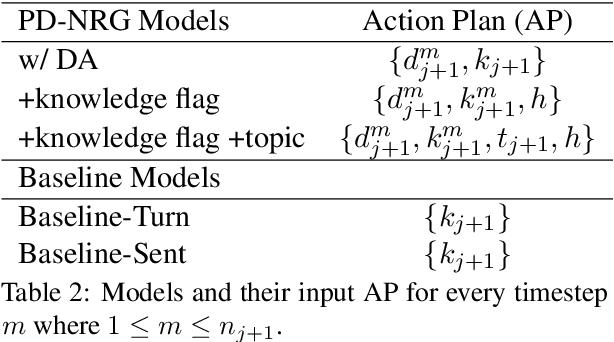
Open-domain dialogue systems aim to generate relevant, informative and engaging responses. Seq2seq neural response generation approaches do not have explicit mechanisms to control the content or style of the generated response, and frequently result in uninformative utterances. In this paper, we propose using a dialogue policy to plan the content and style of target responses in the form of an action plan, which includes knowledge sentences related to the dialogue context, targeted dialogue acts, topic information, etc. The attributes within the action plan are obtained by automatically annotating the publicly released Topical-Chat dataset. We condition neural response generators on the action plan which is then realized as target utterances at the turn and sentence levels. We also investigate different dialogue policy models to predict an action plan given the dialogue context. Through automated and human evaluation, we measure the appropriateness of the generated responses and check if the generation models indeed learn to realize the given action plans. We demonstrate that a basic dialogue policy that operates at the sentence level generates better responses in comparison to turn level generation as well as baseline models with no action plan. Additionally the basic dialogue policy has the added effect of controllability.