 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFindings of the Fifth Shared Task on Multilingual Coreference Resolution: Expanding Datasets for Long-Range Entities
May 20, 2026This paper describes the fifth edition of the Shared Task on Multilingual Coreference Resolution, held in conjunction with the CODI-CRAC 2026 workshop. Building on previous iterations, the task required participants to develop systems capable of mention identification and identity-based coreference clustering. The 2026 edition specifically emphasizes long-range entities, defined as coreferential chains spanning significant distances, across many words and sentences. The task expanded its linguistic scope by incorporating five new datasets and two additional languages. These additions leverage version 1.4 of CorefUD, a harmonized multilingual collection comprising 27 datasets in 19 languages. In total, ten systems participated, including four LLM-based approaches (three fine-tuned models and one few-shot approach). While traditional systems still maintained their lead, LLMs demonstrated significant potential, suggesting they may soon challenge established approaches in future editions.
Word Alignment-Based Evaluation of Uniform Meaning Representations
Mar 27, 2026Comparison and evaluation of graph-based representations of sentence meaning is a challenge because competing representations of the same sentence may have different number of nodes, and it is not obvious which nodes should be compared to each other. Existing approaches favor node mapping that maximizes $F_1$ score over node relations and attributes, regardless whether the similarity is intentional or accidental; consequently, the identified mismatches in values of node attributes are not useful for any detailed error analysis. We propose a node-matching algorithm that allows comparison of multiple Uniform Meaning Representations (UMR) of one sentence and that takes advantage of node-word alignments, inherently available in UMR. We compare it with previously used approaches, in particular smatch (the de-facto standard in AMR evaluation), and argue that sensitivity to word alignment makes the comparison of meaning representations more intuitive and interpretable, while avoiding the NP-hard search problem inherent in smatch. A script implementing the method is freely available.
Towards Generating Automatic Anaphora Annotations
Mar 12, 2025

Training models that can perform well on various NLP tasks require large amounts of data, and this becomes more apparent with nuanced tasks such as anaphora and conference resolution. To combat the prohibitive costs of creating manual gold annotated data, this paper explores two methods to automatically create datasets with coreferential annotations; direct conversion from existing datasets, and parsing using multilingual models capable of handling new and unseen languages. The paper details the current progress on those two fronts, as well as the challenges the efforts currently face, and our approach to overcoming these challenges.
Findings of the Third Shared Task on Multilingual Coreference Resolution
Oct 21, 2024



The paper presents an overview of the third edition of the shared task on multilingual coreference resolution, held as part of the CRAC 2024 workshop. Similarly to the previous two editions, the participants were challenged to develop systems capable of identifying mentions and clustering them based on identity coreference. This year's edition took another step towards real-world application by not providing participants with gold slots for zero anaphora, increasing the task's complexity and realism. In addition, the shared task was expanded to include a more diverse set of languages, with a particular focus on historical languages. The training and evaluation data were drawn from version 1.2 of the multilingual collection of harmonized coreference resources CorefUD, encompassing 21 datasets across 15 languages. 6 systems competed in this shared task.
A Unified Taxonomy of Deep Syntactic Relations
Mar 21, 2023



This paper analyzes multiple deep-syntactic frameworks with the goal of creating a proposal for a set of universal semantic role labels. The proposal examines various theoretic linguistic perspectives and focuses on Meaning-Text Theory and Functional Generative Description frameworks. For the purpose of this research, data from four languages is used -- Spanish and Catalan (Taule et al., 2011), Czech (Hajic et al., 2017), and English (Hajic et al., 2012). This proposal is oriented towards Universal Dependencies (de Marneffe et al., 2021) with a further intention of applying the universal semantic role labels to the UD data.
Findings of the Shared Task on Multilingual Coreference Resolution
Sep 16, 2022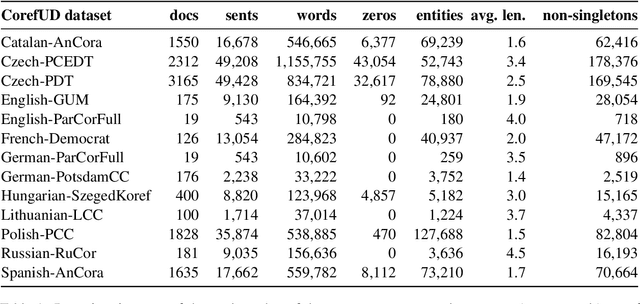
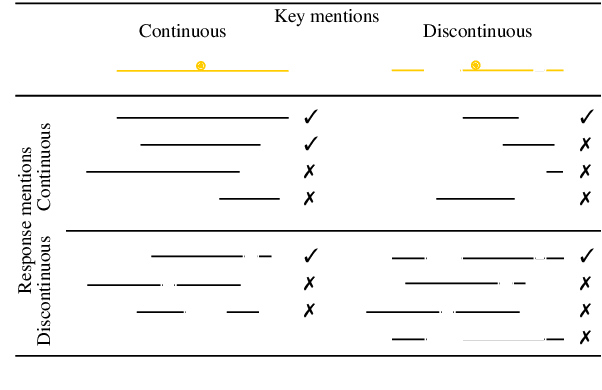

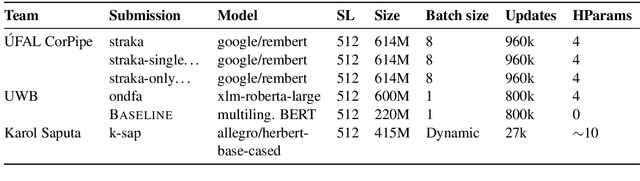
This paper presents an overview of the shared task on multilingual coreference resolution associated with the CRAC 2022 workshop. Shared task participants were supposed to develop trainable systems capable of identifying mentions and clustering them according to identity coreference. The public edition of CorefUD 1.0, which contains 13 datasets for 10 languages, was used as the source of training and evaluation data. The CoNLL score used in previous coreference-oriented shared tasks was used as the main evaluation metric. There were 8 coreference prediction systems submitted by 5 participating teams; in addition, there was a competitive Transformer-based baseline system provided by the organizers at the beginning of the shared task. The winner system outperformed the baseline by 12 percentage points (in terms of the CoNLL scores averaged across all datasets for individual languages).
Predicting Typological Features in WALS using Language Embeddings and Conditional Probabilities: ÚFAL Submission to the SIGTYP 2020 Shared Task
Oct 08, 2020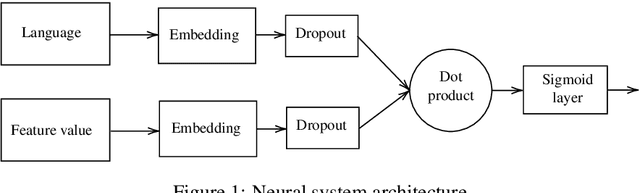
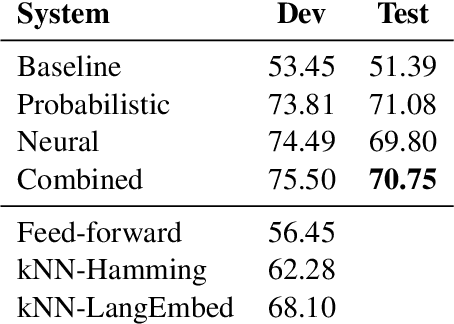
We present our submission to the SIGTYP 2020 Shared Task on the prediction of typological features. We submit a constrained system, predicting typological features only based on the WALS database. We investigate two approaches. The simpler of the two is a system based on estimating correlation of feature values within languages by computing conditional probabilities and mutual information. The second approach is to train a neural predictor operating on precomputed language embeddings based on WALS features. Our submitted system combines the two approaches based on their self-estimated confidence scores. We reach the accuracy of 70.7% on the test data and rank first in the shared task.
Universal Dependencies v2: An Evergrowing Multilingual Treebank Collection
Apr 22, 2020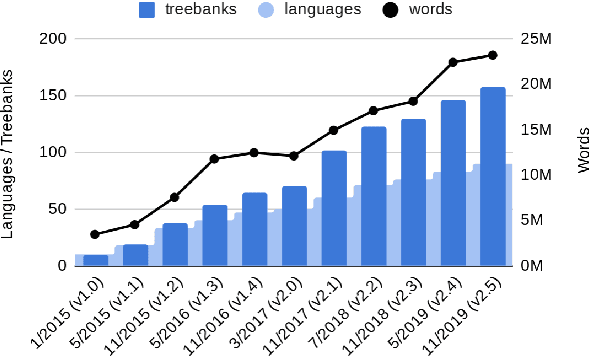
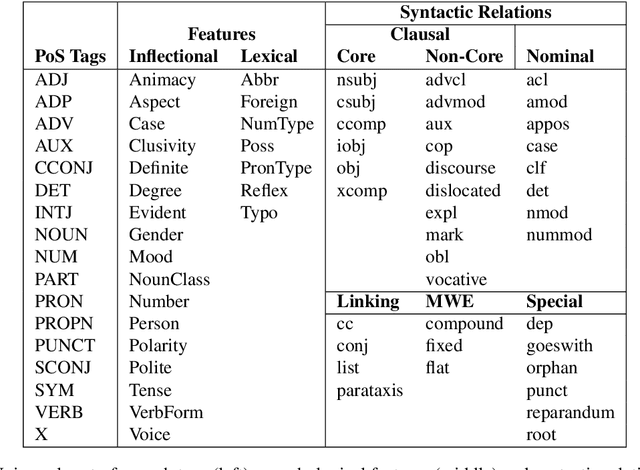
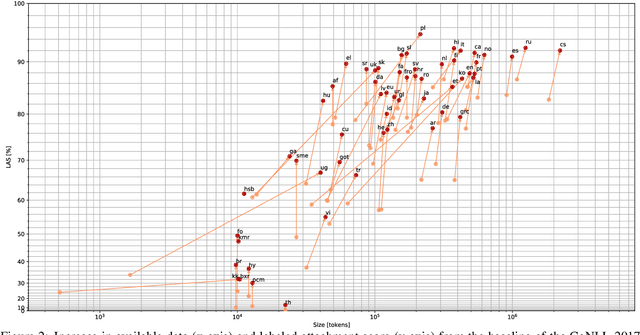
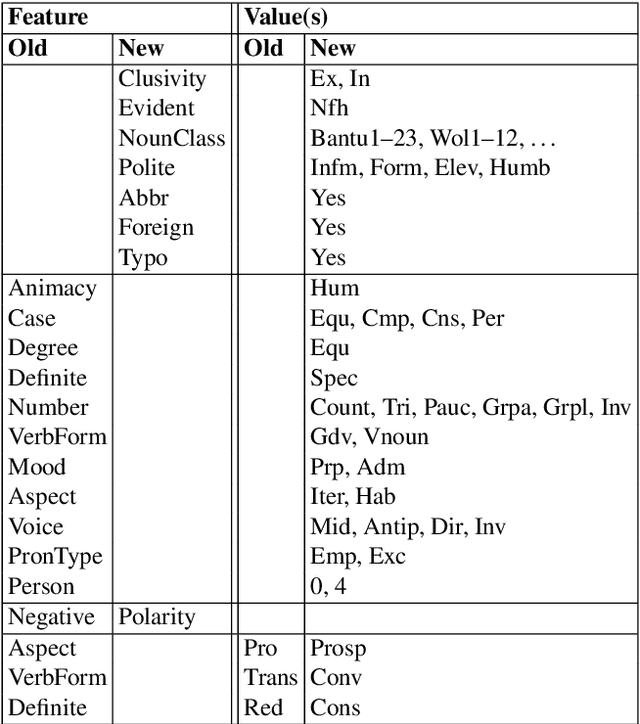
Universal Dependencies is an open community effort to create cross-linguistically consistent treebank annotation for many languages within a dependency-based lexicalist framework. The annotation consists in a linguistically motivated word segmentation; a morphological layer comprising lemmas, universal part-of-speech tags, and standardized morphological features; and a syntactic layer focusing on syntactic relations between predicates, arguments and modifiers. In this paper, we describe version 2 of the guidelines (UD v2), discuss the major changes from UD v1 to UD v2, and give an overview of the currently available treebanks for 90 languages.
Automatic Extraction of Subcategorization Frames for Czech
Sep 08, 2000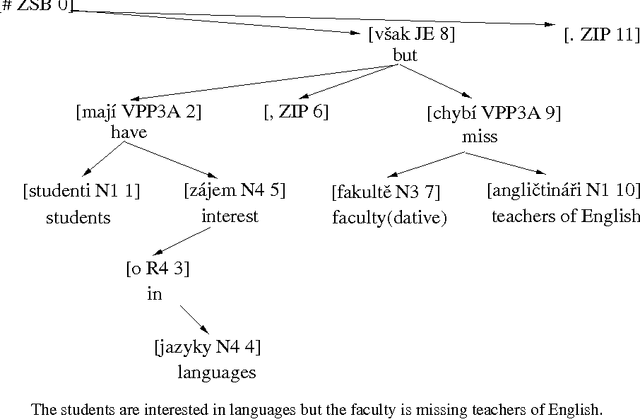
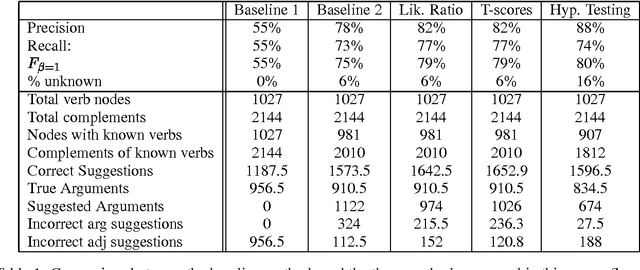
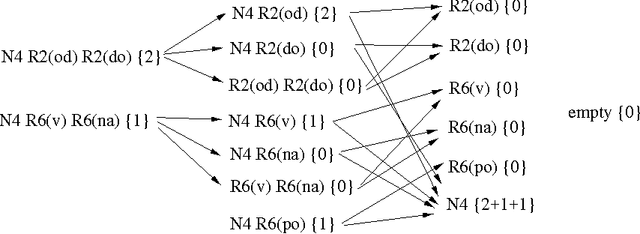
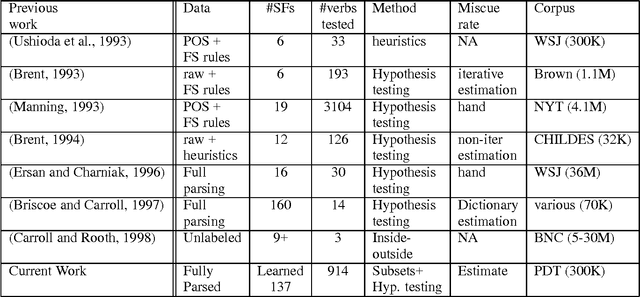
We present some novel machine learning techniques for the identification of subcategorization information for verbs in Czech. We compare three different statistical techniques applied to this problem. We show how the learning algorithm can be used to discover previously unknown subcategorization frames from the Czech Prague Dependency Treebank. The algorithm can then be used to label dependents of a verb in the Czech treebank as either arguments or adjuncts. Using our techniques, we ar able to achieve 88% precision on unseen parsed text.
* 7 pages. Another version under the name "Learning Verb Subcategorization from Corpora: Counting Frame Subsets", authors: Zeman, Sarkar, in proceedings of LREC 2000, Athens, Greece