 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Memory Efficient Baseline for Open Domain Question Answering
Dec 30, 2020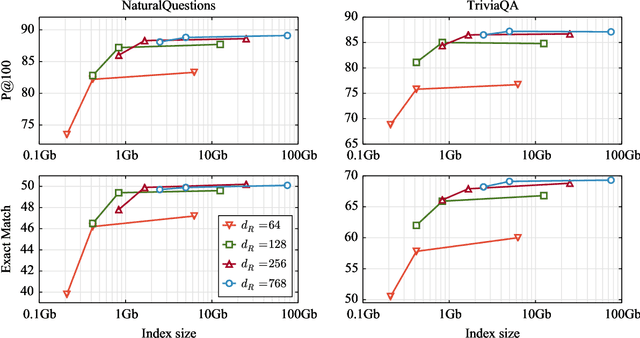
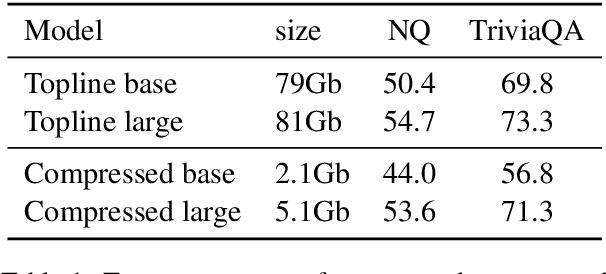
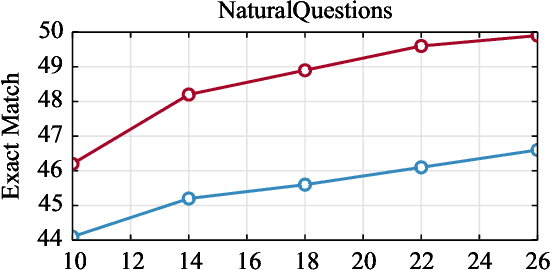
Recently, retrieval systems based on dense representations have led to important improvements in open-domain question answering, and related tasks. While very effective, this approach is also memory intensive, as the dense vectors for the whole knowledge source need to be kept in memory. In this paper, we study how the memory footprint of dense retriever-reader systems can be reduced. We consider three strategies to reduce the index size: dimension reduction, vector quantization and passage filtering. We evaluate our approach on two question answering benchmarks: TriviaQA and NaturalQuestions, showing that it is possible to get competitive systems using less than 6Gb of memory.
Joint Verification and Reranking for Open Fact Checking Over Tables
Dec 30, 2020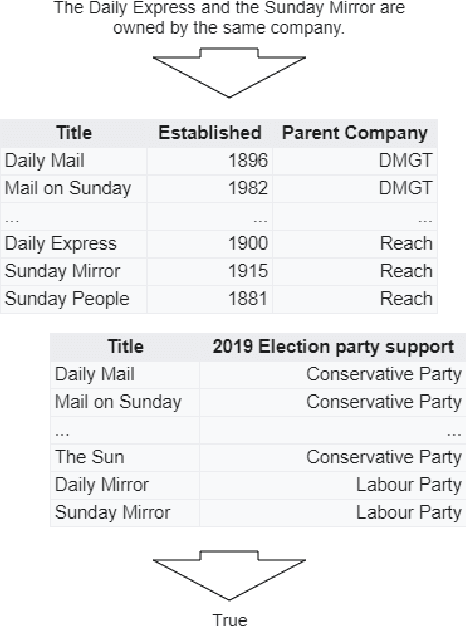
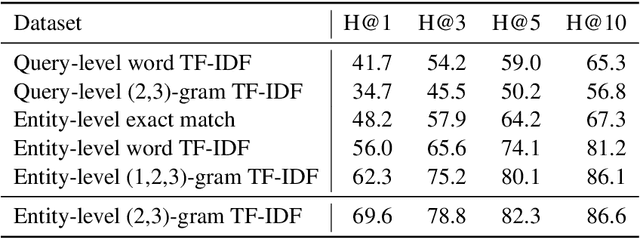
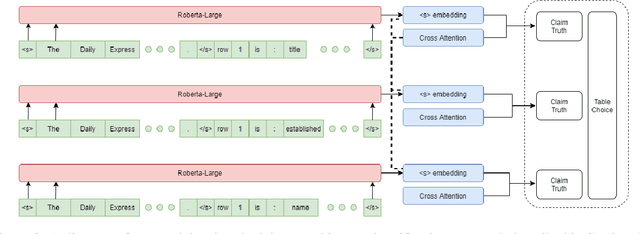
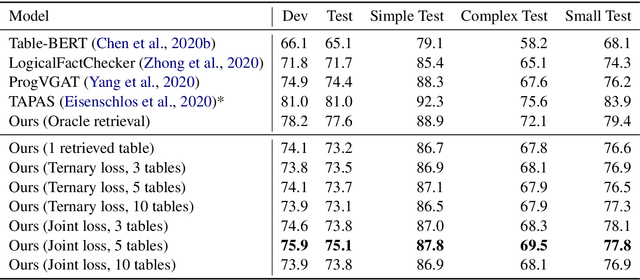
Structured information is an important knowledge source for automatic verification of factual claims. Nevertheless, the majority of existing research into this task has focused on textual data, and the few recent inquiries into structured data have been for the closed-domain setting where appropriate evidence for each claim is assumed to have already been retrieved. In this paper, we investigate verification over structured data in the open-domain setting, introducing a joint reranking-and-verification model which fuses evidence documents in the verification component. Our open-domain model achieves performance comparable to the closed-domain state-of-the-art on the TabFact dataset, and demonstrates performance gains from the inclusion of multiple tables as well as a significant improvement over a heuristic retrieval baseline.
Generating Fact Checking Briefs
Nov 10, 2020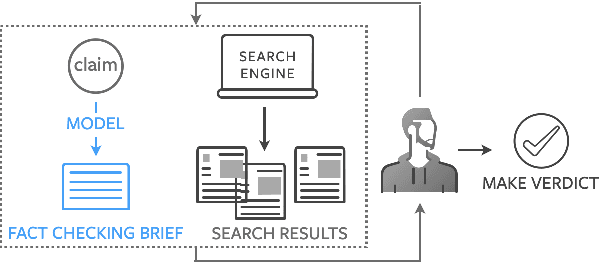
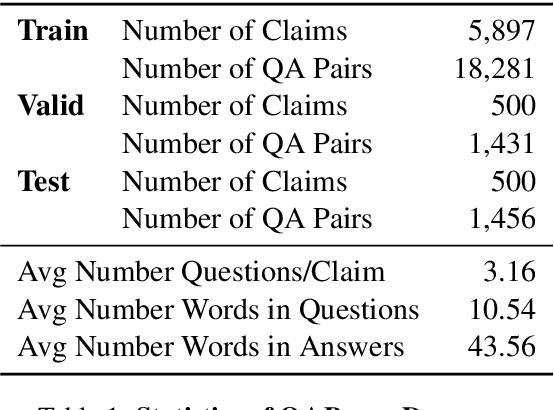

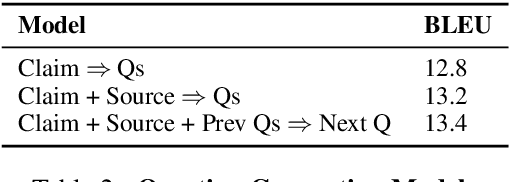
Fact checking at scale is difficult -- while the number of active fact checking websites is growing, it remains too small for the needs of the contemporary media ecosystem. However, despite good intentions, contributions from volunteers are often error-prone, and thus in practice restricted to claim detection. We investigate how to increase the accuracy and efficiency of fact checking by providing information about the claim before performing the check, in the form of natural language briefs. We investigate passage-based briefs, containing a relevant passage from Wikipedia, entity-centric ones consisting of Wikipedia pages of mentioned entities, and Question-Answering Briefs, with questions decomposing the claim, and their answers. To produce QABriefs, we develop QABriefer, a model that generates a set of questions conditioned on the claim, searches the web for evidence, and generates answers. To train its components, we introduce QABriefDataset which we collected via crowdsourcing. We show that fact checking with briefs -- in particular QABriefs -- increases the accuracy of crowdworkers by 10% while slightly decreasing the time taken. For volunteer (unpaid) fact checkers, QABriefs slightly increase accuracy and reduce the time required by around 20%.
Don't Read Too Much into It: Adaptive Computation for Open-Domain Question Answering
Nov 10, 2020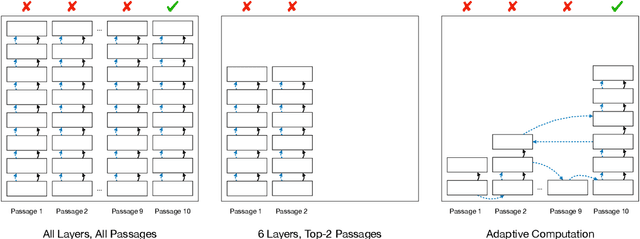
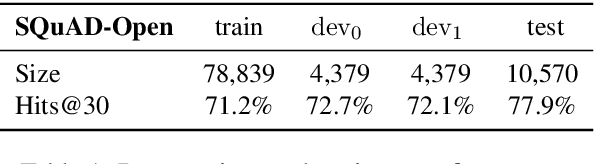
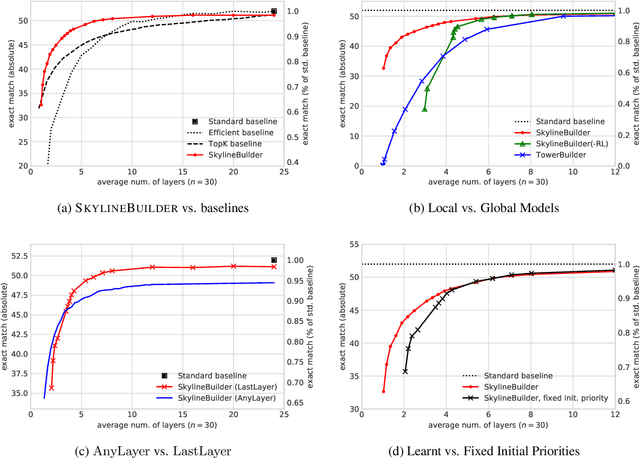
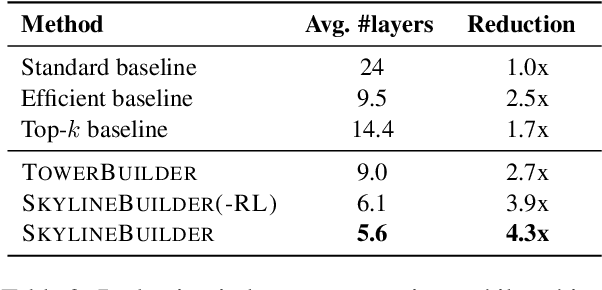
Most approaches to Open-Domain Question Answering consist of a light-weight retriever that selects a set of candidate passages, and a computationally expensive reader that examines the passages to identify the correct answer. Previous works have shown that as the number of retrieved passages increases, so does the performance of the reader. However, they assume all retrieved passages are of equal importance and allocate the same amount of computation to them, leading to a substantial increase in computational cost. To reduce this cost, we propose the use of adaptive computation to control the computational budget allocated for the passages to be read. We first introduce a technique operating on individual passages in isolation which relies on anytime prediction and a per-layer estimation of an early exit probability. We then introduce SkylineBuilder, an approach for dynamically deciding on which passage to allocate computation at each step, based on a resource allocation policy trained via reinforcement learning. Our results on SQuAD-Open show that adaptive computation with global prioritisation improves over several strong static and adaptive methods, leading to a 4.3x reduction in computation while retaining 95% performance of the full model.
Proactive Action Visual Residual Reinforcement Learning for Contact-Rich Tasks Using a Torque-Controlled Robot
Oct 25, 2020

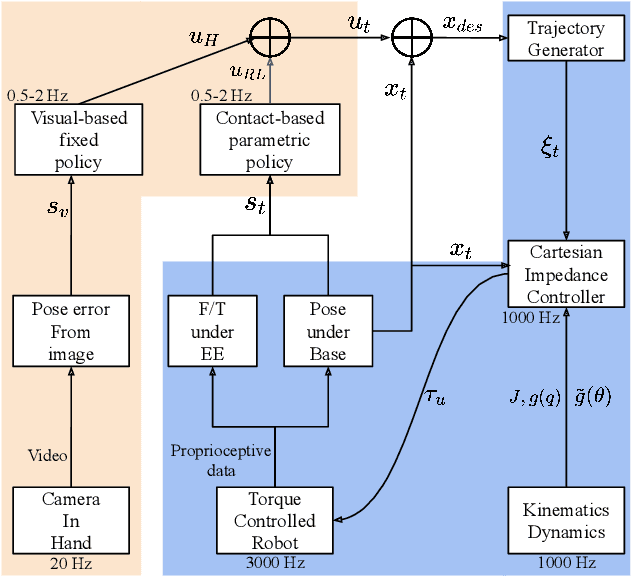
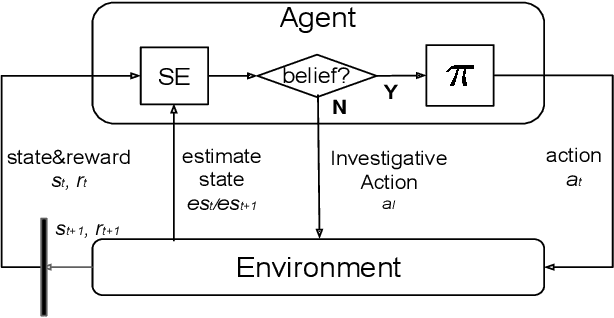
Contact-rich manipulation tasks are commonly found in modern manufacturing settings. However, manually designing a robot controller is considered hard for traditional control methods as the controller requires an effective combination of modalities and vastly different characteristics. In this paper, we firstly consider incorporating operational space visual and haptic information into reinforcement learning(RL) methods to solve the target uncertainty problem in unstructured environments. Moreover, we propose a novel idea of introducing a proactive action to solve the partially observable Markov decision process problem. Together with these two ideas, our method can either adapt to reasonable variations in unstructured environments and improve the sample efficiency of policy learning. We evaluated our method on a task that involved inserting a random-access memory using a torque-controlled robot, and we tested the success rates of the different baselines used in the traditional methods. We proved that our method is robust and can tolerate environmental variations very well.
Neural Databases
Oct 14, 2020
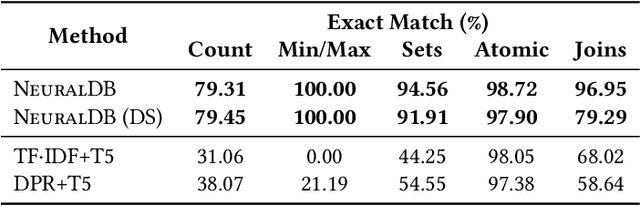
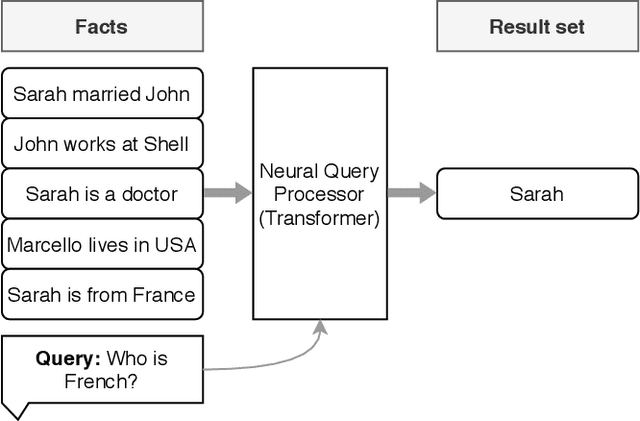

In recent years, neural networks have shown impressive performance gains on long-standing AI problems, and in particular, answering queries from natural language text. These advances raise the question of whether they can be extended to a point where we can relax the fundamental assumption of database management, namely, that our data is represented as fields of a pre-defined schema. This paper presents a first step in answering that question. We describe NeuralDB, a database system with no pre-defined schema, in which updates and queries are given in natural language. We develop query processing techniques that build on the primitives offered by the state of the art Natural Language Processing methods. We begin by demonstrating that at the core, recent NLP transformers, powered by pre-trained language models, can answer select-project-join queries if they are given the exact set of relevant facts. However, they cannot scale to non-trivial databases and cannot perform aggregation queries. Based on these findings, we describe a NeuralDB architecture that runs multiple Neural SPJ operators in parallel, each with a set of database sentences that can produce one of the answers to the query. The result of these operators is fed to an aggregation operator if needed. We describe an algorithm that learns how to create the appropriate sets of facts to be fed into each of the Neural SPJ operators. Importantly, this algorithm can be trained by the Neural SPJ operator itself. We experimentally validate the accuracy of NeuralDB and its components, showing that we can answer queries over thousands of sentences with very high accuracy.
Autoregressive Entity Retrieval
Oct 02, 2020Entities are at the center of how we represent and aggregate knowledge. For instance, Encyclopedias such as Wikipedia are structured by entities (e.g., one per article). The ability to retrieve such entities given a query is fundamental for knowledge-intensive tasks such as entity linking and open-domain question answering. One way to understand current approaches is as classifiers among atomic labels, one for each entity. Their weight vectors are dense entity representations produced by encoding entity information such as descriptions. This approach leads to several shortcomings: i) context and entity affinity is mainly captured through a vector dot product, potentially missing fine-grained interactions between the two; ii) a large memory footprint is needed to store dense representations when considering large entity sets; iii) an appropriately hard set of negative data has to be subsampled at training time. We propose GENRE, the first system that retrieves entities by generating their unique names, left to right, token-by-token in an autoregressive fashion, and conditioned on the context. This enables to mitigate the aforementioned technical issues: i) the autoregressive formulation allows us to directly capture relations between context and entity name, effectively cross encoding both; ii) the memory footprint is greatly reduced because the parameters of our encoder-decoder architecture scale with vocabulary size, not entity count; iii) the exact softmax loss can be efficiently computed without the need to subsample negative data. We show the efficacy of the approach with more than 20 datasets on entity disambiguation, end-to-end entity linking and document retrieval tasks, achieving new SOTA, or very competitive results while using a tiny fraction of the memory of competing systems. Finally, we demonstrate that new entities can be added by simply specifying their unambiguous name.
Answering Complex Open-Domain Questions with Multi-Hop Dense Retrieval
Sep 27, 2020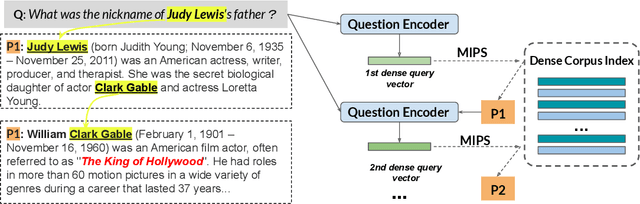
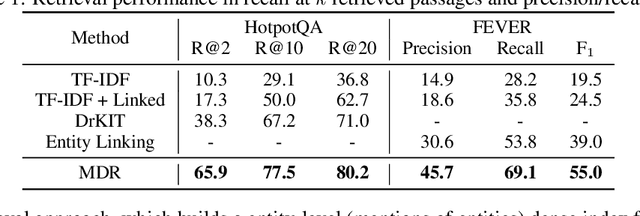
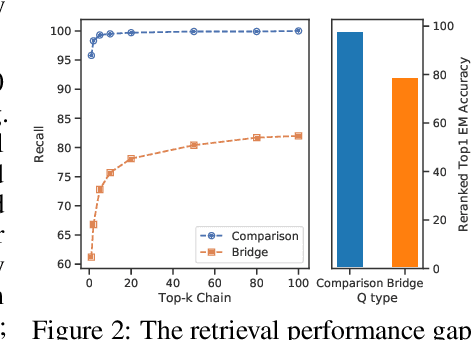

We propose a simple and efficient multi-hop dense retrieval approach for answering complex open-domain questions, which achieves state-of-the-art performance on two multi-hop datasets, HotpotQA and multi-evidence FEVER. Contrary to previous work, our method does not require access to any corpus-specific information, such as inter-document hyperlinks or human-annotated entity markers, and can be applied to any unstructured text corpus. Our system also yields a much better efficiency-accuracy trade-off, matching the best published accuracy on HotpotQA while being 10 times faster at inference time.
KILT: a Benchmark for Knowledge Intensive Language Tasks
Sep 04, 2020
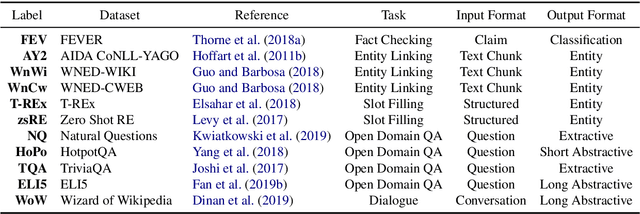
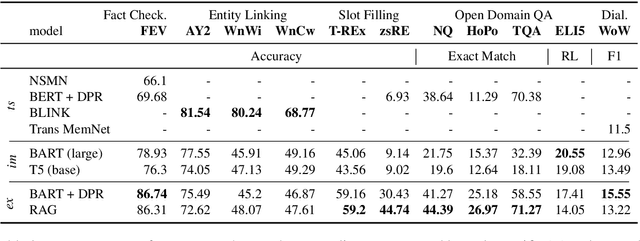
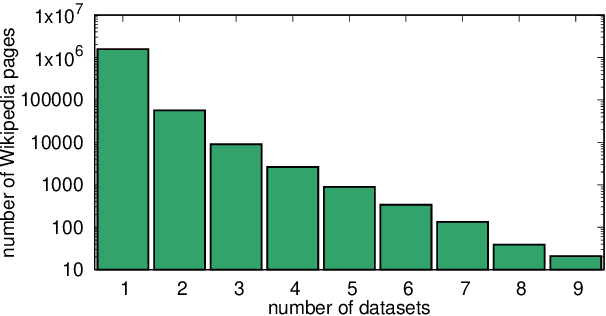
Challenging problems such as open-domain question answering, fact checking, slot filling and entity linking require access to large, external knowledge sources. While some models do well on individual tasks, developing general models is difficult as each task might require computationally expensive indexing of custom knowledge sources, in addition to dedicated infrastructure. To catalyze research on models that condition on specific information in large textual resources, we present a benchmark for knowledge-intensive language tasks (KILT). All tasks in KILT are grounded in the same snapshot of Wikipedia, reducing engineering turnaround through the re-use of components, as well as accelerating research into task-agnostic memory architectures. We test both task-specific and general baselines, evaluating downstream performance in addition to the ability of the models to provide provenance. We find that a shared dense vector index coupled with a seq2seq model is a strong baseline, outperforming more tailor-made approaches for fact checking, open-domain question answering and dialogue, and yielding competitive results on entity linking and slot filling, by generating disambiguated text. KILT data and code are available at https://github.com/facebookresearch/KILT.
Question and Answer Test-Train Overlap in Open-Domain Question Answering Datasets
Aug 06, 2020


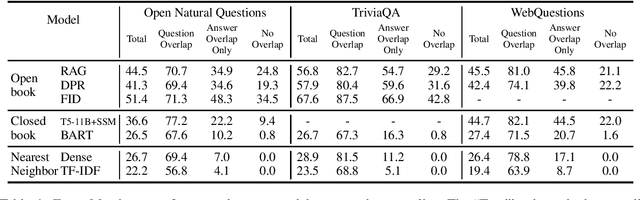
Ideally Open-Domain Question Answering models should exhibit a number of competencies, ranging from simply memorizing questions seen at training time, to answering novel question formulations with answers seen during training, to generalizing to completely novel questions with novel answers. However, single aggregated test set scores do not show the full picture of what capabilities models truly have. In this work, we perform a detailed study of the test sets of three popular open-domain benchmark datasets with respect to these competencies. We find that 60-70% of test-time answers are also present somewhere in the training sets. We also find that 30% of test-set questions have a near-duplicate paraphrase in their corresponding training sets. Using these findings, we evaluate a variety of popular open-domain models to obtain greater insight into what extent they can actually generalize, and what drives their overall performance. We find that all models perform dramatically worse on questions that cannot be memorized from training sets, with a mean absolute performance difference of 63% between repeated and non-repeated data. Finally we show that simple nearest-neighbor models out-perform a BART closed-book QA model, further highlighting the role that training set memorization plays in these benchmarks