 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuestion and Answer Test-Train Overlap in Open-Domain Question Answering Datasets
Paper and Code



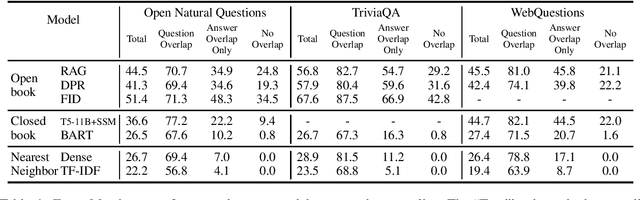
Ideally Open-Domain Question Answering models should exhibit a number of competencies, ranging from simply memorizing questions seen at training time, to answering novel question formulations with answers seen during training, to generalizing to completely novel questions with novel answers. However, single aggregated test set scores do not show the full picture of what capabilities models truly have. In this work, we perform a detailed study of the test sets of three popular open-domain benchmark datasets with respect to these competencies. We find that 60-70% of test-time answers are also present somewhere in the training sets. We also find that 30% of test-set questions have a near-duplicate paraphrase in their corresponding training sets. Using these findings, we evaluate a variety of popular open-domain models to obtain greater insight into what extent they can actually generalize, and what drives their overall performance. We find that all models perform dramatically worse on questions that cannot be memorized from training sets, with a mean absolute performance difference of 63% between repeated and non-repeated data. Finally we show that simple nearest-neighbor models out-perform a BART closed-book QA model, further highlighting the role that training set memorization plays in these benchmarks