 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Ranking Game for Imitation Learning
Feb 07, 2022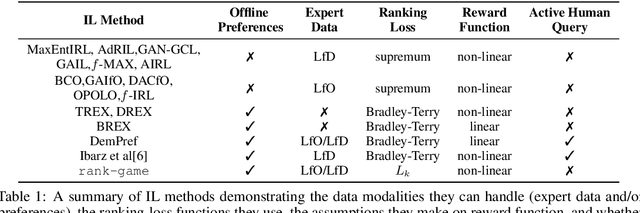
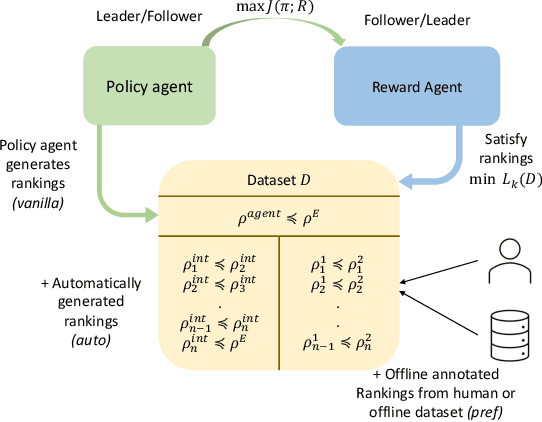
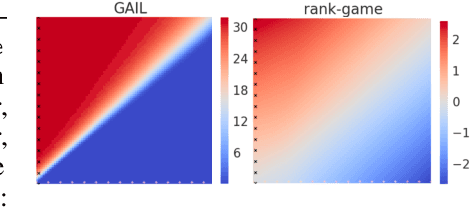
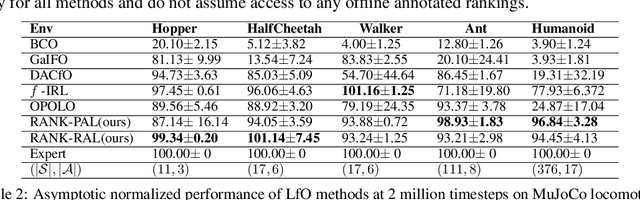
We propose a new framework for imitation learning - treating imitation as a two-player ranking-based Stackelberg game between a $\textit{policy}$ and a $\textit{reward}$ function. In this game, the reward agent learns to satisfy pairwise performance rankings within a set of policies, while the policy agent learns to maximize this reward. This game encompasses a large subset of both inverse reinforcement learning (IRL) methods and methods which learn from offline preferences. The Stackelberg game formulation allows us to use optimization methods that take the game structure into account, leading to more sample efficient and stable learning dynamics compared to existing IRL methods. We theoretically analyze the requirements of the loss function used for ranking policy performances to facilitate near-optimal imitation learning at equilibrium. We use insights from this analysis to further increase sample efficiency of the ranking game by using automatically generated rankings or with offline annotated rankings. Our experiments show that the proposed method achieves state-of-the-art sample efficiency and is able to solve previously unsolvable tasks in the Learning from Observation (LfO) setting.
SOPE: Spectrum of Off-Policy Estimators
Dec 02, 2021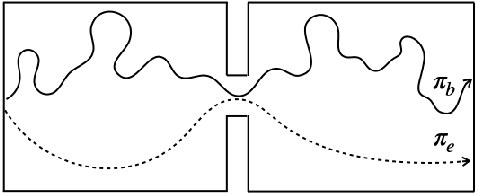

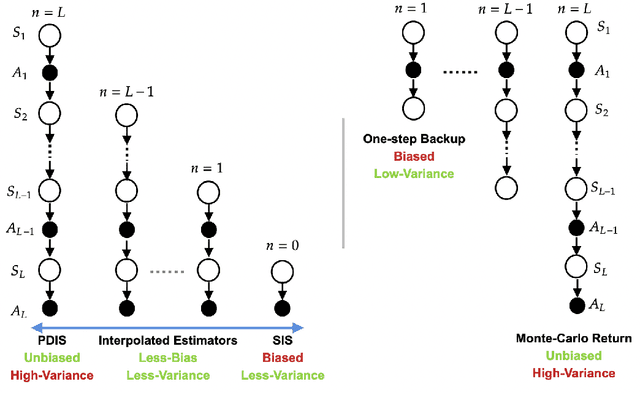
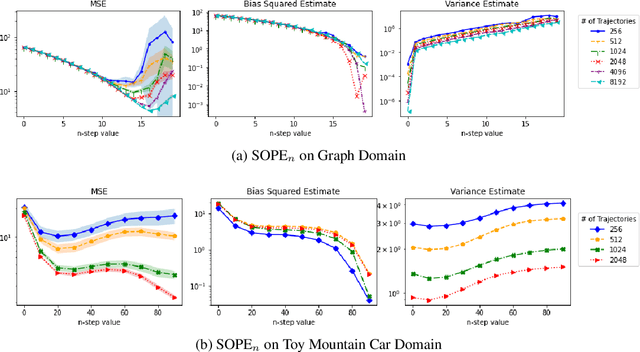
Many sequential decision making problems are high-stakes and require off-policy evaluation (OPE) of a new policy using historical data collected using some other policy. One of the most common OPE techniques that provides unbiased estimates is trajectory based importance sampling (IS). However, due to the high variance of trajectory IS estimates, importance sampling methods based on state-action visitation distributions (SIS) have recently been adopted. Unfortunately, while SIS often provides lower variance estimates for long horizons, estimating the state-action distribution ratios can be challenging and lead to biased estimates. In this paper, we present a new perspective on this bias-variance trade-off and show the existence of a spectrum of estimators whose endpoints are SIS and IS. Additionally, we also establish a spectrum for doubly-robust and weighted version of these estimators. We provide empirical evidence that estimators in this spectrum can be used to trade-off between the bias and variance of IS and SIS and can achieve lower mean-squared error than both IS and SIS.
You Only Evaluate Once: a Simple Baseline Algorithm for Offline RL
Oct 05, 2021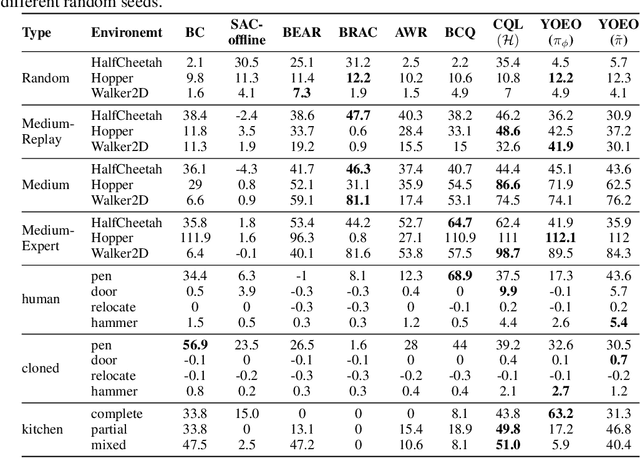

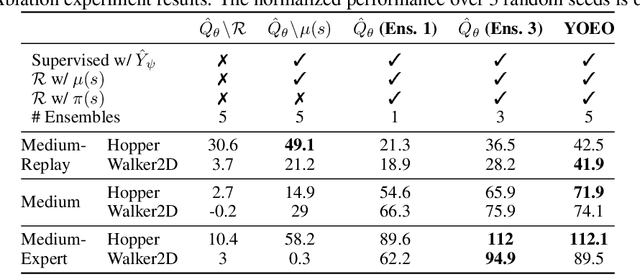
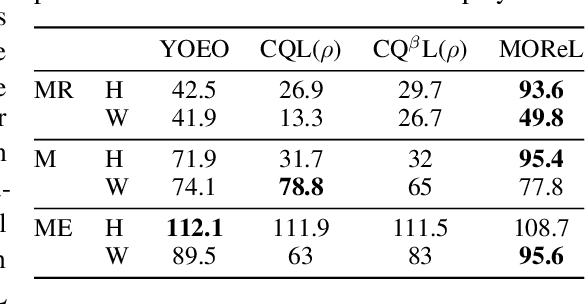
The goal of offline reinforcement learning (RL) is to find an optimal policy given prerecorded trajectories. Many current approaches customize existing off-policy RL algorithms, especially actor-critic algorithms in which policy evaluation and improvement are iterated. However, the convergence of such approaches is not guaranteed due to the use of complex non-linear function approximation and an intertwined optimization process. By contrast, we propose a simple baseline algorithm for offline RL that only performs the policy evaluation step once so that the algorithm does not require complex stabilization schemes. Since the proposed algorithm is not likely to converge to an optimal policy, it is an appropriate baseline for actor-critic algorithms that ought to be outperformed if there is indeed value in iterative optimization in the offline setting. Surprisingly, we empirically find that the proposed algorithm exhibits competitive and sometimes even state-of-the-art performance in a subset of the D4RL offline RL benchmark. This result suggests that future work is needed to fully exploit the potential advantages of iterative optimization in order to justify the reduced stability of such methods.
Distributional Depth-Based Estimation of Object Articulation Models
Aug 12, 2021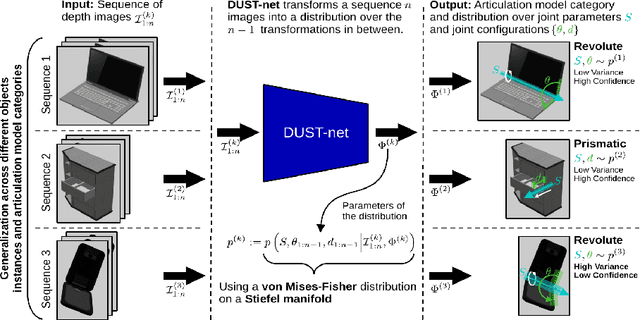

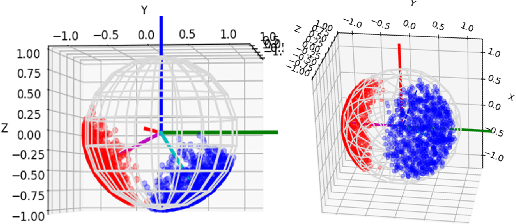
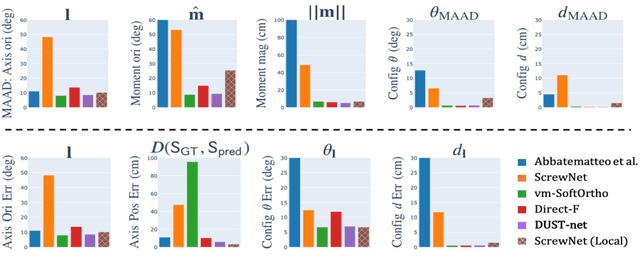
We propose a method that efficiently learns distributions over articulation model parameters directly from depth images without the need to know articulation model categories a priori. By contrast, existing methods that learn articulation models from raw observations typically only predict point estimates of the model parameters, which are insufficient to guarantee the safe manipulation of articulated objects. Our core contributions include a novel representation for distributions over rigid body transformations and articulation model parameters based on screw theory, von Mises-Fisher distributions, and Stiefel manifolds. Combining these concepts allows for an efficient, mathematically sound representation that implicitly satisfies the constraints that rigid body transformations and articulations must adhere to. Leveraging this representation, we introduce a novel deep learning based approach, DUST-net, that performs category-independent articulation model estimation while also providing model uncertainties. We evaluate our approach on several benchmarking datasets and real-world objects and compare its performance with two current state-of-the-art methods. Our results demonstrate that DUST-net can successfully learn distributions over articulation models for novel objects across articulation model categories, which generate point estimates with better accuracy than state-of-the-art methods and effectively capture the uncertainty over predicted model parameters due to noisy inputs.
Robust Generative Adversarial Imitation Learning via Local Lipschitzness
Jun 30, 2021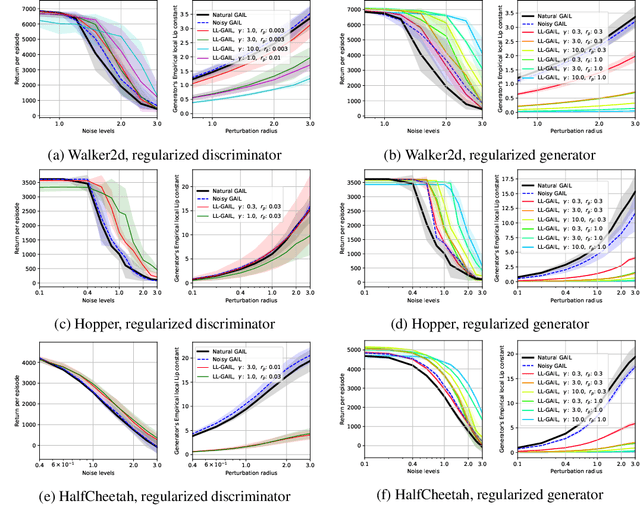
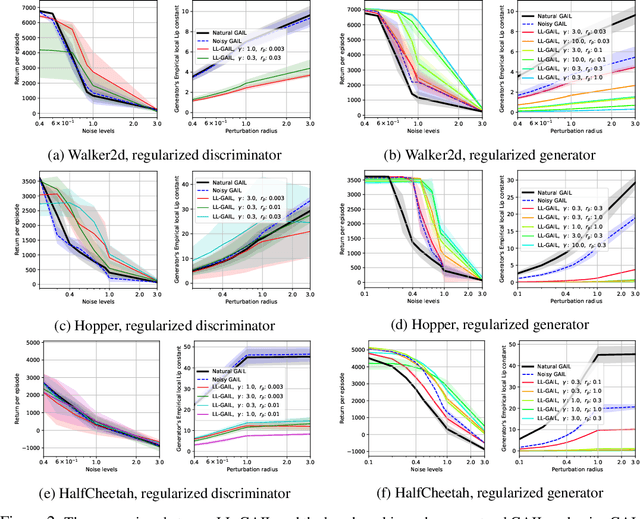
We explore methodologies to improve the robustness of generative adversarial imitation learning (GAIL) algorithms to observation noise. Towards this objective, we study the effect of local Lipschitzness of the discriminator and the generator on the robustness of policies learned by GAIL. In many robotics applications, the learned policies by GAIL typically suffer from a degraded performance at test time since the observations from the environment might be corrupted by noise. Hence, robustifying the learned policies against the observation noise is of critical importance. To this end, we propose a regularization method to induce local Lipschitzness in the generator and the discriminator of adversarial imitation learning methods. We show that the modified objective leads to learning significantly more robust policies. Moreover, we demonstrate -- both theoretically and experimentally -- that training a locally Lipschitz discriminator leads to a locally Lipschitz generator, thereby improving the robustness of the resultant policy. We perform extensive experiments on simulated robot locomotion environments from the MuJoCo suite that demonstrate the proposed method learns policies that significantly outperform the state-of-the-art generative adversarial imitation learning algorithm when applied to test scenarios with noise-corrupted observations.
Zero-shot Task Adaptation using Natural Language
Jun 05, 2021
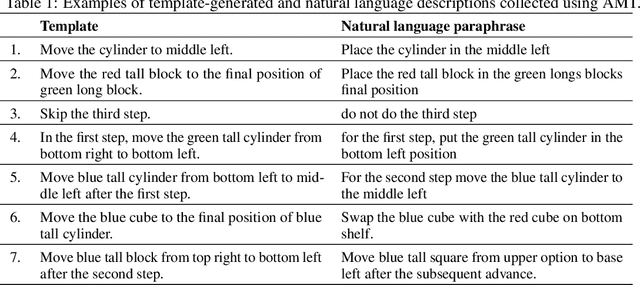
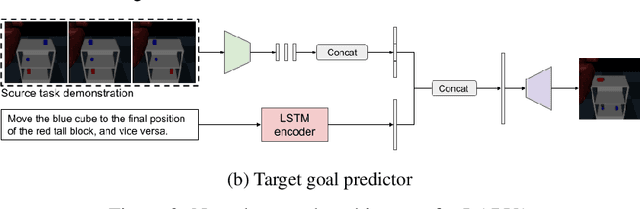
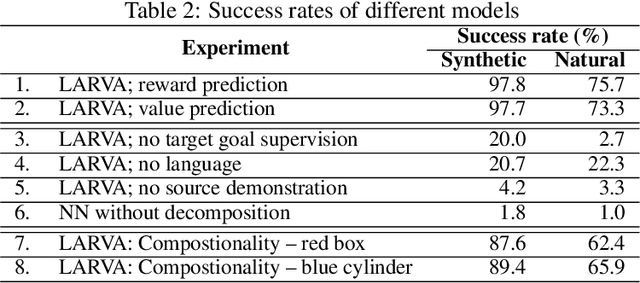
Imitation learning and instruction-following are two common approaches to communicate a user's intent to a learning agent. However, as the complexity of tasks grows, it could be beneficial to use both demonstrations and language to communicate with an agent. In this work, we propose a novel setting where an agent is given both a demonstration and a description, and must combine information from both the modalities. Specifically, given a demonstration for a task (the source task), and a natural language description of the differences between the demonstrated task and a related but different task (the target task), our goal is to train an agent to complete the target task in a zero-shot setting, that is, without any demonstrations for the target task. To this end, we introduce Language-Aided Reward and Value Adaptation (LARVA) which, given a source demonstration and a linguistic description of how the target task differs, learns to output a reward / value function that accurately describes the target task. Our experiments show that on a diverse set of adaptations, our approach is able to complete more than 95% of target tasks when using template-based descriptions, and more than 70% when using free-form natural language.
Adversarial Intrinsic Motivation for Reinforcement Learning
May 30, 2021
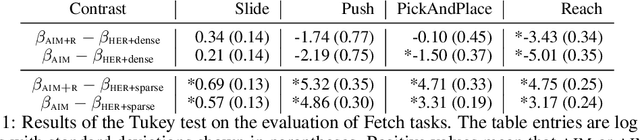
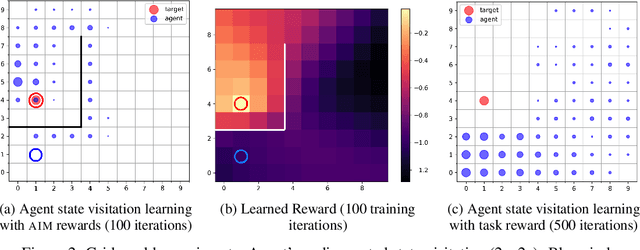
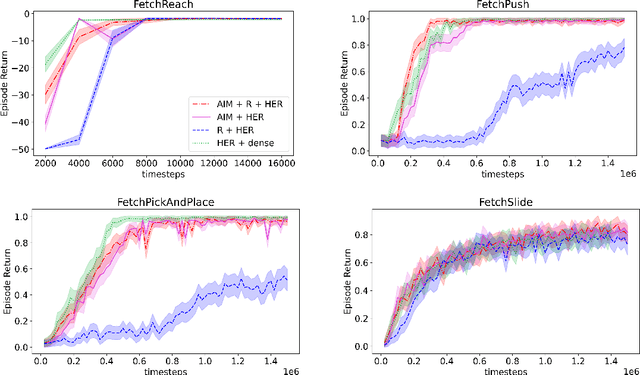
Learning with an objective to minimize the mismatch with a reference distribution has been shown to be useful for generative modeling and imitation learning. In this paper, we investigate whether one such objective, the Wasserstein-1 distance between a policy's state visitation distribution and a target distribution, can be utilized effectively for reinforcement learning (RL) tasks. Specifically, this paper focuses on goal-conditioned reinforcement learning where the idealized (unachievable) target distribution has full measure at the goal. We introduce a quasimetric specific to Markov Decision Processes (MDPs), and show that the policy that minimizes the Wasserstein-1 distance of its state visitation distribution to this target distribution under this quasimetric is the policy that reaches the goal in as few steps as possible. Our approach, termed Adversarial Intrinsic Motivation (AIM), estimates this Wasserstein-1 distance through its dual objective and uses it to compute a supplemental reward function. Our experiments show that this reward function changes smoothly with respect to transitions in the MDP and assists the agent in learning. Additionally, we combine AIM with Hindsight Experience Replay (HER) and show that the resulting algorithm accelerates learning significantly on several simulated robotics tasks when compared to HER with a sparse positive reward at the goal state.
Universal Off-Policy Evaluation
Apr 26, 2021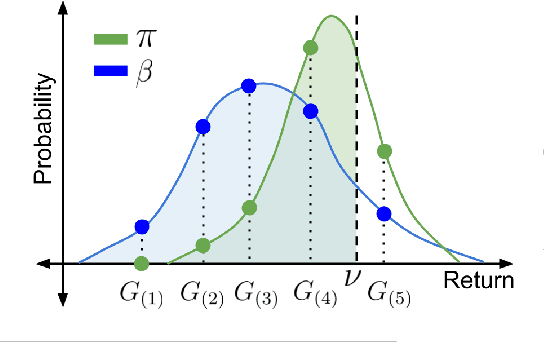

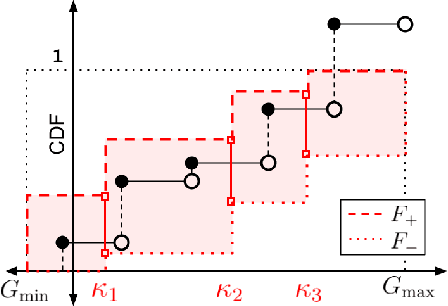
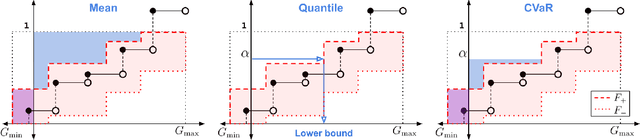
When faced with sequential decision-making problems, it is often useful to be able to predict what would happen if decisions were made using a new policy. Those predictions must often be based on data collected under some previously used decision-making rule. Many previous methods enable such off-policy (or counterfactual) estimation of the expected value of a performance measure called the return. In this paper, we take the first steps towards a universal off-policy estimator (UnO) -- one that provides off-policy estimates and high-confidence bounds for any parameter of the return distribution. We use UnO for estimating and simultaneously bounding the mean, variance, quantiles/median, inter-quantile range, CVaR, and the entire cumulative distribution of returns. Finally, we also discuss Uno's applicability in various settings, including fully observable, partially observable (i.e., with unobserved confounders), Markovian, non-Markovian, stationary, smoothly non-stationary, and discrete distribution shifts.
Self-Supervised Online Reward Shaping in Sparse-Reward Environments
Mar 08, 2021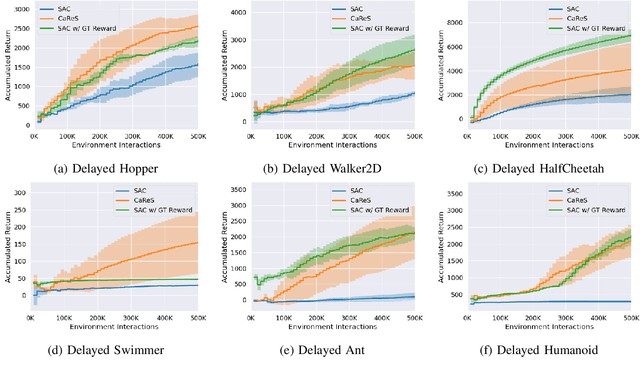
We propose a novel reinforcement learning framework that performs self-supervised online reward shaping, yielding faster, sample efficient performance in sparse reward environments. The proposed framework alternates between updating a policy and inferring a reward function. While the policy update is done with the inferred, potentially dense reward function, the original sparse reward is used to provide a self-supervisory signal for the reward update by serving as an ordering over the observed trajectories. The proposed framework is based on the theory that altering the reward function does not affect the optimal policy of the original MDP as long as we maintain certain relations between the altered and the original reward. We name the proposed framework \textit{ClAssification-based REward Shaping} (CaReS), since we learn the altered reward in a self-supervised manner using classifier based reward inference. Experimental results on several sparse-reward environments demonstrate that the proposed algorithm is not only significantly more sample efficient than the state-of-the-art baseline, but also achieves a similar sample efficiency to MDPs that use hand-designed dense reward functions.
SCAPE: Learning Stiffness Control from Augmented Position Control Experiences
Feb 16, 2021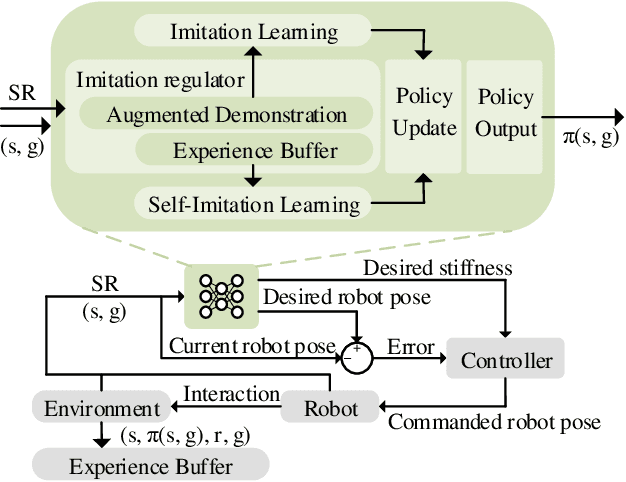
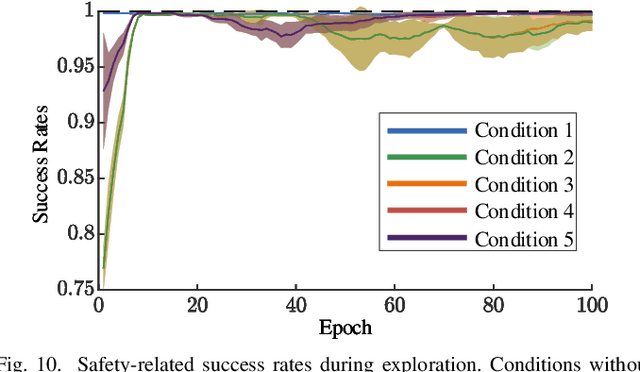
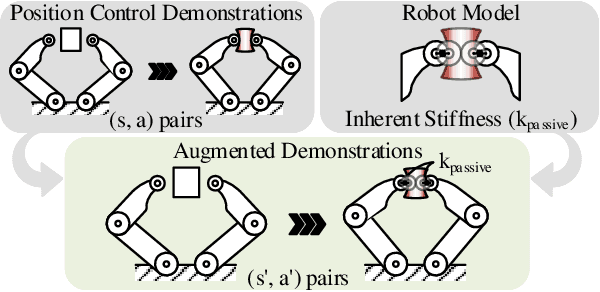
We introduce a sample-efficient method for learning state-dependent stiffness control policies for dexterous manipulation. The ability to control stiffness facilitates safe and reliable manipulation by providing compliance and robustness to uncertainties. So far, most current reinforcement learning approaches to achieve robotic manipulation have exclusively focused on position control, often due to the difficulty of learning high-dimensional stiffness control policies. This difficulty can be partially mitigated via policy guidance such as in imitation learning. However, expert stiffness control demonstrations are often expensive or infeasible to record. Therefore, we present an approach to learn Stiffness Control from Augmented Position control Experiences (SCAPE) that bypasses this difficulty by transforming position control demonstrations into approximate, suboptimal stiffness control demonstrations. Then, the suboptimality of the augmented demonstrations is addressed by using complementary techniques that help the agent safely learn from both the demonstrations and reinforcement learning. By using simulation tools and experiments on a robotic testbed, we show that the proposed approach efficiently learns safe manipulation policies and outperforms learned position control policies and several other baseline learning algorithms.