 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Optimal Advantage from Preferences and Mistaking it for Reward
Oct 03, 2023



We consider algorithms for learning reward functions from human preferences over pairs of trajectory segments, as used in reinforcement learning from human feedback (RLHF). Most recent work assumes that human preferences are generated based only upon the reward accrued within those segments, or their partial return. Recent work casts doubt on the validity of this assumption, proposing an alternative preference model based upon regret. We investigate the consequences of assuming preferences are based upon partial return when they actually arise from regret. We argue that the learned function is an approximation of the optimal advantage function, $\hat{A^*_r}$, not a reward function. We find that if a specific pitfall is addressed, this incorrect assumption is not particularly harmful, resulting in a highly shaped reward function. Nonetheless, this incorrect usage of $\hat{A^*_r}$ is less desirable than the appropriate and simpler approach of greedy maximization of $\hat{A^*_r}$. From the perspective of the regret preference model, we also provide a clearer interpretation of fine tuning contemporary large language models with RLHF. This paper overall provides insight regarding why learning under the partial return preference model tends to work so well in practice, despite it conforming poorly to how humans give preferences.
Hierarchical Empowerment: Towards Tractable Empowerment-Based Skill-Learning
Jul 06, 2023



General purpose agents will require large repertoires of skills. Empowerment -- the maximum mutual information between skills and the states -- provides a pathway for learning large collections of distinct skills, but mutual information is difficult to optimize. We introduce a new framework, Hierarchical Empowerment, that makes computing empowerment more tractable by integrating concepts from Goal-Conditioned Hierarchical Reinforcement Learning. Our framework makes two specific contributions. First, we introduce a new variational lower bound on mutual information that can be used to compute empowerment over short horizons. Second, we introduce a hierarchical architecture for computing empowerment over exponentially longer time scales. We verify the contributions of the framework in a series of simulated robotics tasks. In a popular ant navigation domain, our four level agents are able to learn skills that cover a surface area over two orders of magnitude larger than prior work.
Granger-Causal Hierarchical Skill Discovery
Jun 15, 2023



Reinforcement Learning (RL) has shown promising results learning policies for complex tasks, but can often suffer from low sample efficiency and limited transfer. We introduce the Hierarchy of Interaction Skills (HIntS) algorithm, which uses learned interaction detectors to discover and train a hierarchy of skills that manipulate factors in factored environments. Inspired by Granger causality, these unsupervised detectors capture key events between factors to sample efficiently learn useful skills and transfer those skills to other related tasks -- tasks where many reinforcement learning techniques struggle. We evaluate HIntS on a robotic pushing task with obstacles -- a challenging domain where other RL and HRL methods fall short. The learned skills not only demonstrate transfer using variants of Breakout, a common RL benchmark, but also show 2-3x improvement in both sample efficiency and final performance compared to comparable RL baselines. Together, HIntS demonstrates a proof of concept for using Granger-causal relationships for skill discovery.
Imitation from Arbitrary Experience: A Dual Unification of Reinforcement and Imitation Learning Methods
Feb 16, 2023



It is well known that Reinforcement Learning (RL) can be formulated as a convex program with linear constraints. The dual form of this formulation is unconstrained, which we refer to as dual RL, and can leverage preexisting tools from convex optimization to improve the learning performance of RL agents. We show that several state-of-the-art deep RL algorithms (in online, offline, and imitation settings) can be viewed as dual RL approaches in a unified framework. This unification calls for the methods to be studied on common ground, so as to identify the components that actually contribute to the success of these methods. Our unification also reveals that prior off-policy imitation learning methods in the dual space are based on an unrealistic coverage assumption and are restricted to matching a particular f-divergence. We propose a new method using a simple modification to the dual framework that allows for imitation learning with arbitrary off-policy data to obtain near-expert performance.
Language-guided Task Adaptation for Imitation Learning
Jan 24, 2023



We introduce a novel setting, wherein an agent needs to learn a task from a demonstration of a related task with the difference between the tasks communicated in natural language. The proposed setting allows reusing demonstrations from other tasks, by providing low effort language descriptions, and can also be used to provide feedback to correct agent errors, which are both important desiderata for building intelligent agents that assist humans in daily tasks. To enable progress in this proposed setting, we create two benchmarks -- Room Rearrangement and Room Navigation -- that cover a diverse set of task adaptations. Further, we propose a framework that uses a transformer-based model to reason about the entities in the tasks and their relationships, to learn a policy for the target task
Understanding Acoustic Patterns of Human Teachers Demonstrating Manipulation Tasks to Robots
Nov 01, 2022



Humans use audio signals in the form of spoken language or verbal reactions effectively when teaching new skills or tasks to other humans. While demonstrations allow humans to teach robots in a natural way, learning from trajectories alone does not leverage other available modalities including audio from human teachers. To effectively utilize audio cues accompanying human demonstrations, first it is important to understand what kind of information is present and conveyed by such cues. This work characterizes audio from human teachers demonstrating multi-step manipulation tasks to a situated Sawyer robot using three feature types: (1) duration of speech used, (2) expressiveness in speech or prosody, and (3) semantic content of speech. We analyze these features along four dimensions and find that teachers convey similar semantic concepts via spoken words for different conditions of (1) demonstration types, (2) audio usage instructions, (3) subtasks, and (4) errors during demonstrations. However, differentiating properties of speech in terms of duration and expressiveness are present along the four dimensions, highlighting that human audio carries rich information, potentially beneficial for technological advancement of robot learning from demonstration methods.
Models of human preference for learning reward functions
Jun 05, 2022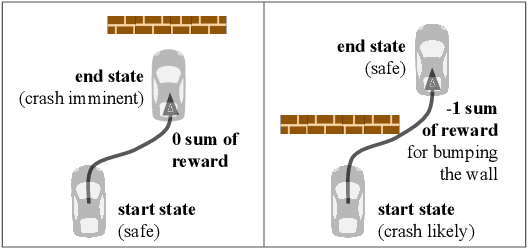
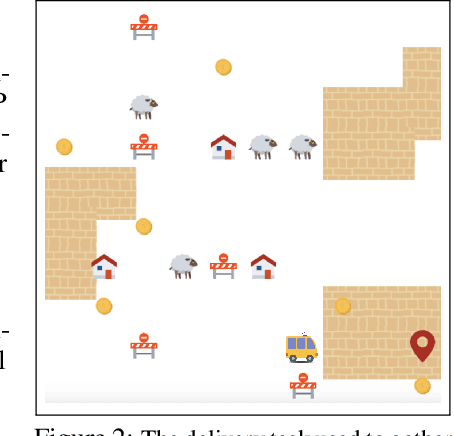
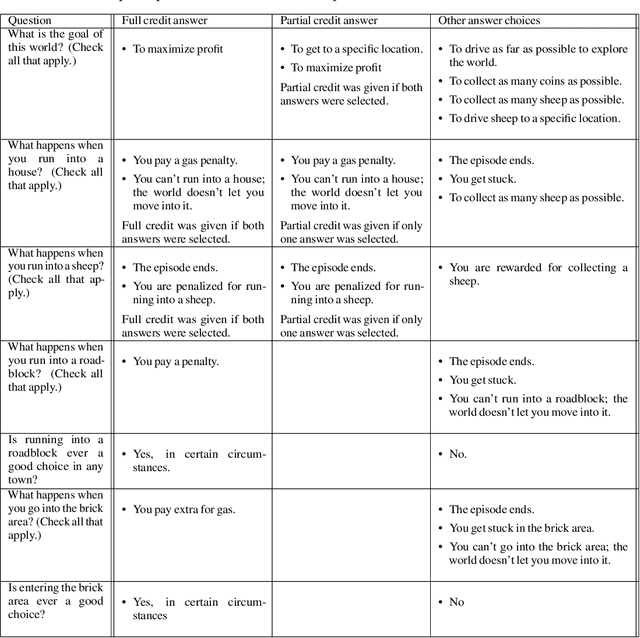
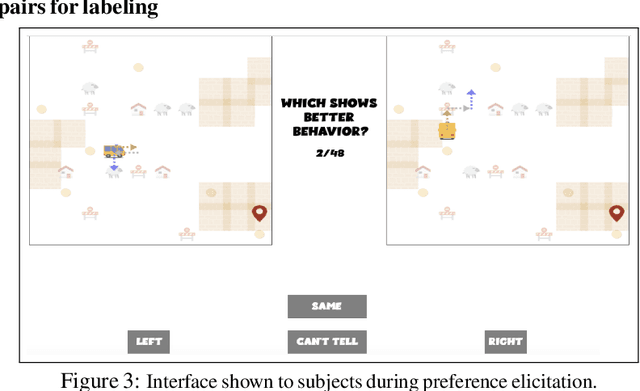
The utility of reinforcement learning is limited by the alignment of reward functions with the interests of human stakeholders. One promising method for alignment is to learn the reward function from human-generated preferences between pairs of trajectory segments. These human preferences are typically assumed to be informed solely by partial return, the sum of rewards along each segment. We find this assumption to be flawed and propose modeling preferences instead as arising from a different statistic: each segment's regret, a measure of a segment's deviation from optimal decision-making. Given infinitely many preferences generated according to regret, we prove that we can identify a reward function equivalent to the reward function that generated those preferences. We also prove that the previous partial return model lacks this identifiability property without preference noise that reveals rewards' relative proportions, and we empirically show that our proposed regret preference model outperforms it with finite training data in otherwise the same setting. Additionally, our proposed regret preference model better predicts real human preferences and also learns reward functions from these preferences that lead to policies that are better human-aligned. Overall, this work establishes that the choice of preference model is impactful, and our proposed regret preference model provides an improvement upon a core assumption of recent research.
Know Your Boundaries: The Necessity of Explicit Behavioral Cloning in Offline RL
Jun 01, 2022
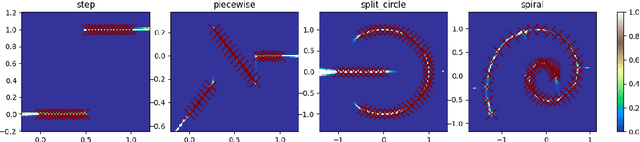
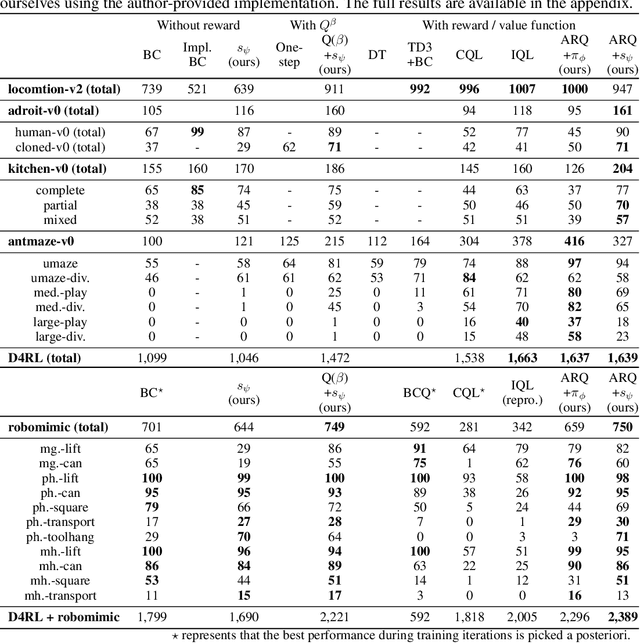

We introduce an offline reinforcement learning (RL) algorithm that explicitly clones a behavior policy to constrain value learning. In offline RL, it is often important to prevent a policy from selecting unobserved actions, since the consequence of these actions cannot be presumed without additional information about the environment. One straightforward way to implement such a constraint is to explicitly model a given data distribution via behavior cloning and directly force a policy not to select uncertain actions. However, many offline RL methods instantiate the constraint indirectly -- for example, pessimistic value estimation -- due to a concern about errors when modeling a potentially complex behavior policy. In this work, we argue that it is not only viable but beneficial to explicitly model the behavior policy for offline RL because the constraint can be realized in a stable way with the trained model. We first suggest a theoretical framework that allows us to incorporate behavior-cloned models into value-based offline RL methods, enjoying the strength of both explicit behavior cloning and value learning. Then, we propose a practical method utilizing a score-based generative model for behavior cloning. With the proposed method, we show state-of-the-art performance on several datasets within the D4RL and Robomimic benchmarks and achieve competitive performance across all datasets tested.
Can Foundation Models Perform Zero-Shot Task Specification For Robot Manipulation?
Apr 23, 2022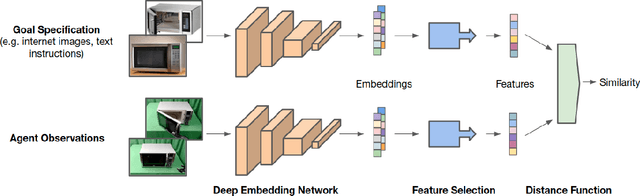
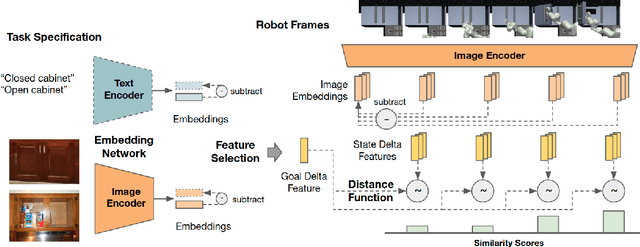
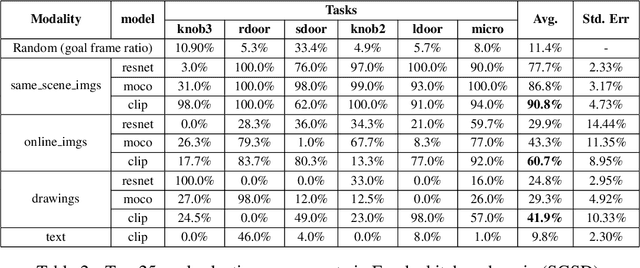

Task specification is at the core of programming autonomous robots. A low-effort modality for task specification is critical for engagement of non-expert end-users and ultimate adoption of personalized robot agents. A widely studied approach to task specification is through goals, using either compact state vectors or goal images from the same robot scene. The former is hard to interpret for non-experts and necessitates detailed state estimation and scene understanding. The latter requires the generation of desired goal image, which often requires a human to complete the task, defeating the purpose of having autonomous robots. In this work, we explore alternate and more general forms of goal specification that are expected to be easier for humans to specify and use such as images obtained from the internet, hand sketches that provide a visual description of the desired task, or simple language descriptions. As a preliminary step towards this, we investigate the capabilities of large scale pre-trained models (foundation models) for zero-shot goal specification, and find promising results in a collection of simulated robot manipulation tasks and real-world datasets.
A Ranking Game for Imitation Learning
Feb 07, 2022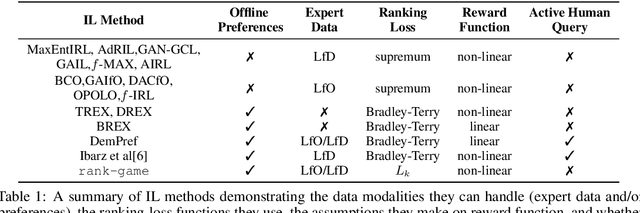
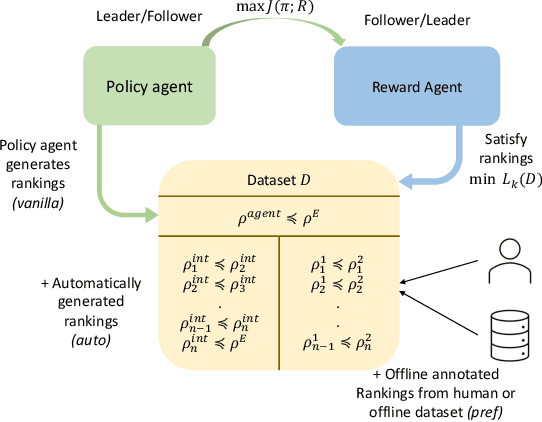
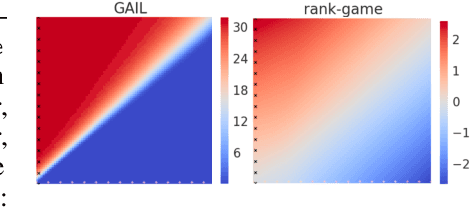
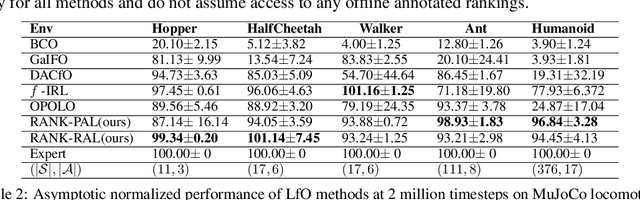
We propose a new framework for imitation learning - treating imitation as a two-player ranking-based Stackelberg game between a $\textit{policy}$ and a $\textit{reward}$ function. In this game, the reward agent learns to satisfy pairwise performance rankings within a set of policies, while the policy agent learns to maximize this reward. This game encompasses a large subset of both inverse reinforcement learning (IRL) methods and methods which learn from offline preferences. The Stackelberg game formulation allows us to use optimization methods that take the game structure into account, leading to more sample efficient and stable learning dynamics compared to existing IRL methods. We theoretically analyze the requirements of the loss function used for ranking policy performances to facilitate near-optimal imitation learning at equilibrium. We use insights from this analysis to further increase sample efficiency of the ranking game by using automatically generated rankings or with offline annotated rankings. Our experiments show that the proposed method achieves state-of-the-art sample efficiency and is able to solve previously unsolvable tasks in the Learning from Observation (LfO) setting.