 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-way Encoding for Robustness
Jun 05, 2019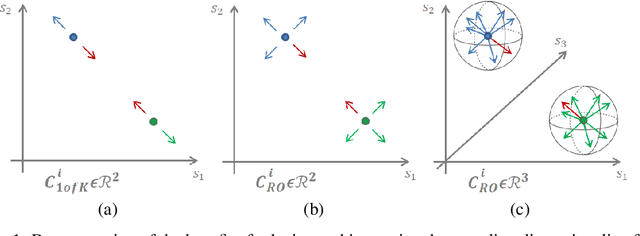

Deep models are state-of-the-art for many computer vision tasks including image classification and object detection. However, it has been shown that deep models are vulnerable to adversarial examples. We highlight how one-hot encoding directly contributes to this vulnerability and propose breaking away from this widely-used, but highly-vulnerable mapping. We demonstrate that by leveraging a different output encoding, multi-way encoding, we decorrelate source and target models, making target models more secure. Our approach makes it more difficult for adversaries to find useful gradients for generating adversarial attacks of the target model. We present robustness for black-box and white-box attacks on four benchmark datasets. The strength of our approach is also presented in the form of an attack for model watermarking by decorrelating a target model from a source model.
Guided Zoom: Questioning Network Evidence for Fine-grained Classification
Dec 06, 2018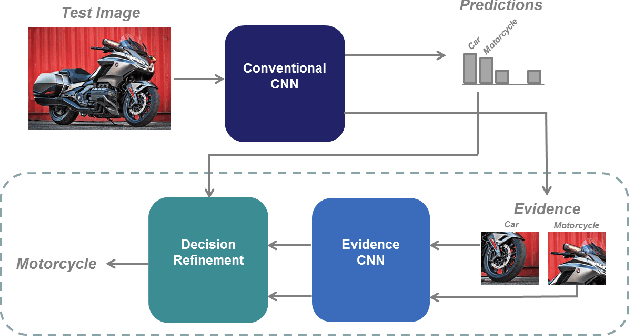

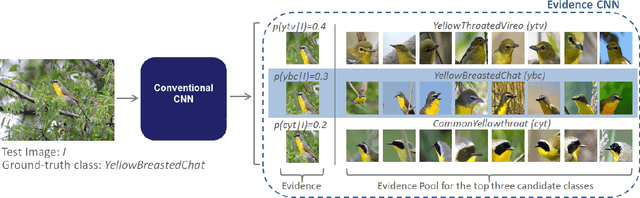
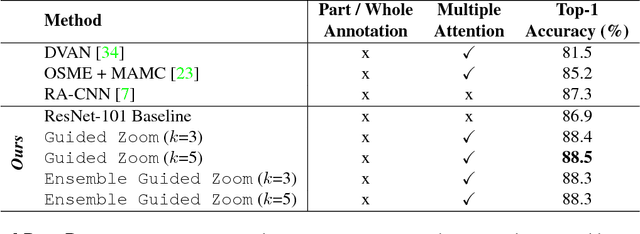
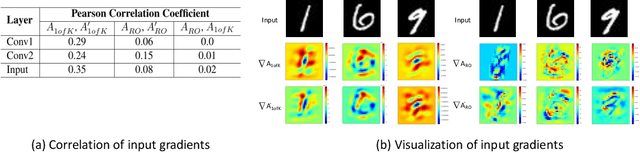
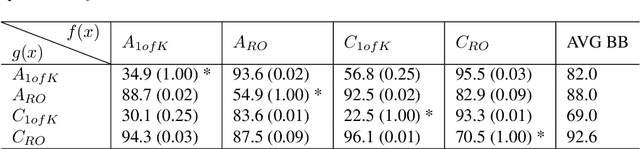
We propose Guided Zoom, an approach that utilizes spatial grounding to make more informed predictions. It does so by making sure the model has "the right reasons" for a prediction, being defined as reasons that are coherent with those used to make similar correct decisions at training time. The reason/evidence upon which a deep neural network makes a prediction is defined to be the spatial grounding, in the pixel space, for a specific class conditional probability in the model output. Guided Zoom questions how reasonable the evidence used to make a prediction is. In state-of-the-art deep single-label classification models, the top-k (k = 2, 3, 4, ...) accuracy is usually significantly higher than the top-1 accuracy. This is more evident in fine-grained datasets, where differences between classes are quite subtle. We show that Guided Zoom results in the refinement of a model's classification accuracy on three finegrained classification datasets. We also explore the complementarity of different grounding techniques, by comparing their ensemble to an adversarial erasing approach that iteratively reveals the next most discriminative evidence.
Hashing as Tie-Aware Learning to Rank
Oct 09, 2018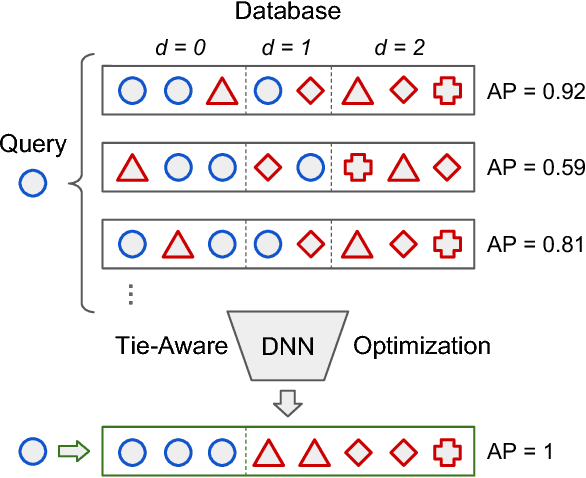
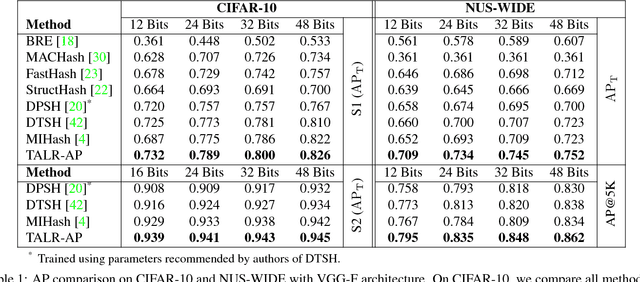
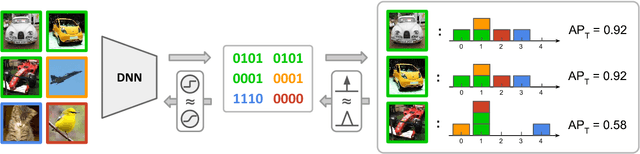
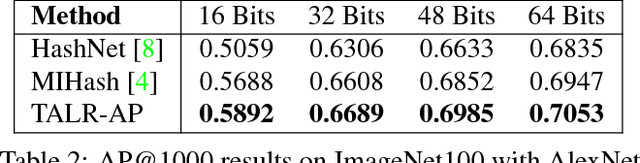
Hashing, or learning binary embeddings of data, is frequently used in nearest neighbor retrieval. In this paper, we develop learning to rank formulations for hashing, aimed at directly optimizing ranking-based evaluation metrics such as Average Precision (AP) and Normalized Discounted Cumulative Gain (NDCG). We first observe that the integer-valued Hamming distance often leads to tied rankings, and propose to use tie-aware versions of AP and NDCG to evaluate hashing for retrieval. Then, to optimize tie-aware ranking metrics, we derive their continuous relaxations, and perform gradient-based optimization with deep neural networks. Our results establish the new state-of-the-art for image retrieval by Hamming ranking in common benchmarks.
Hashing with Mutual Information
Jun 25, 2018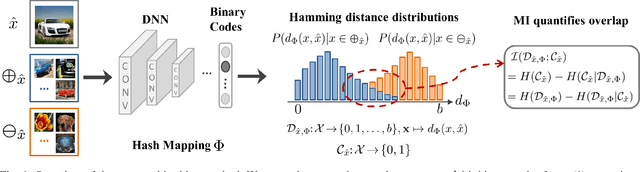
Binary vector embeddings enable fast nearest neighbor retrieval in large databases of high-dimensional objects, and play an important role in many practical applications, such as image and video retrieval. We study the problem of learning binary vector embeddings under a supervised setting, also known as hashing. We propose a novel supervised hashing method based on optimizing an information-theoretic quantity: mutual information. We show that optimizing mutual information can reduce ambiguity in the induced neighborhood structure in the learned Hamming space, which is essential in obtaining high retrieval performance. To this end, we optimize mutual information in deep neural networks with minibatch stochastic gradient descent, with a formulation that maximally and efficiently utilizes available supervision. Experiments on four image retrieval benchmarks, including ImageNet, confirm the effectiveness of our method in learning high-quality binary embeddings for nearest neighbor retrieval.
Excitation Dropout: Encouraging Plasticity in Deep Neural Networks
May 23, 2018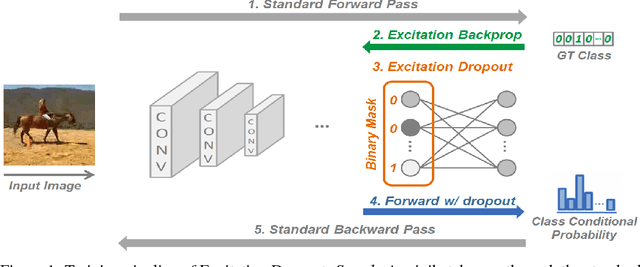

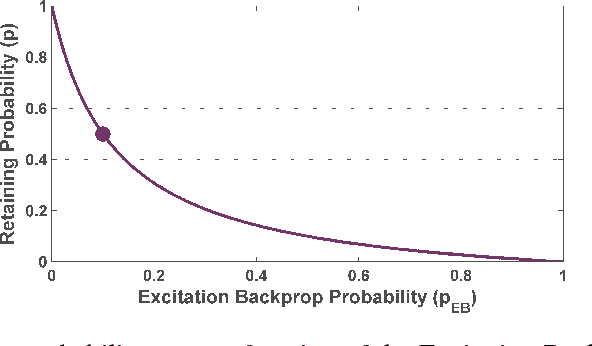
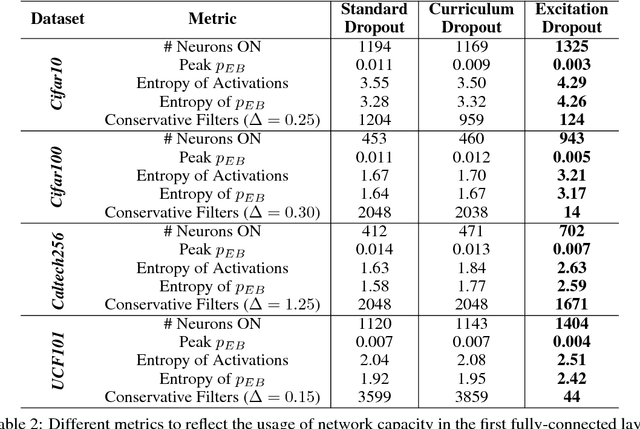
We propose a guided dropout regularizer for deep networks based on the evidence of a network prediction: the firing of neurons in specific paths. In this work, we utilize the evidence at each neuron to determine the probability of dropout, rather than dropping out neurons uniformly at random as in standard dropout. In essence, we dropout with higher probability those neurons which contribute more to decision making at training time. This approach penalizes high saliency neurons that are most relevant for model prediction, i.e. those having stronger evidence. By dropping such high-saliency neurons, the network is forced to learn alternative paths in order to maintain loss minimization, resulting in a plasticity-like behavior, a characteristic of human brains too. We demonstrate better generalization ability, an increased utilization of network neurons, and a higher resilience to network compression using several metrics over four image/video recognition benchmarks.
Excitation Backprop for RNNs
Mar 08, 2018



Deep models are state-of-the-art for many vision tasks including video action recognition and video captioning. Models are trained to caption or classify activity in videos, but little is known about the evidence used to make such decisions. Grounding decisions made by deep networks has been studied in spatial visual content, giving more insight into model predictions for images. However, such studies are relatively lacking for models of spatiotemporal visual content - videos. In this work, we devise a formulation that simultaneously grounds evidence in space and time, in a single pass, using top-down saliency. We visualize the spatiotemporal cues that contribute to a deep model's classification/captioning output using the model's internal representation. Based on these spatiotemporal cues, we are able to localize segments within a video that correspond with a specific action, or phrase from a caption, without explicitly optimizing/training for these tasks.
* CVPR 2018 Camera Ready Version
Moments in Time Dataset: one million videos for event understanding
Jan 09, 2018
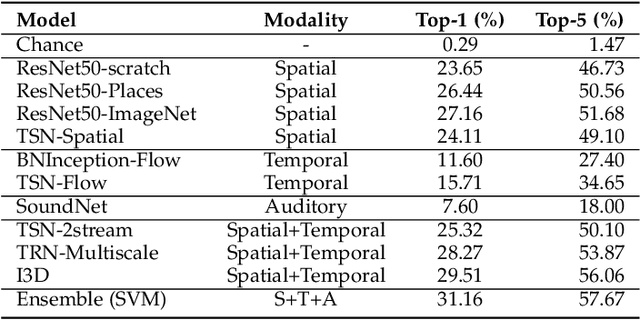

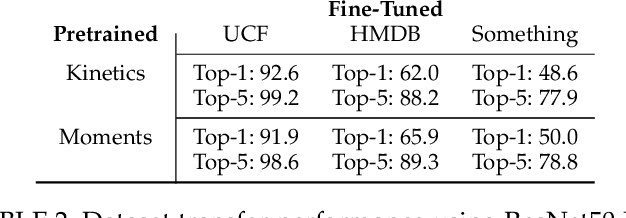
We present the Moments in Time Dataset, a large-scale human-annotated collection of one million short videos corresponding to dynamic events unfolding within three seconds. Modeling the spatial-audio-temporal dynamics even for actions occurring in 3 second videos poses many challenges: meaningful events do not include only people, but also objects, animals, and natural phenomena; visual and auditory events can be symmetrical or not in time ("opening" means "closing" in reverse order), and transient or sustained. We describe the annotation process of our dataset (each video is tagged with one action or activity label among 339 different classes), analyze its scale and diversity in comparison to other large-scale video datasets for action recognition, and report results of several baseline models addressing separately and jointly three modalities: spatial, temporal and auditory. The Moments in Time dataset designed to have a large coverage and diversity of events in both visual and auditory modalities, can serve as a new challenge to develop models that scale to the level of complexity and abstract reasoning that a human processes on a daily basis.
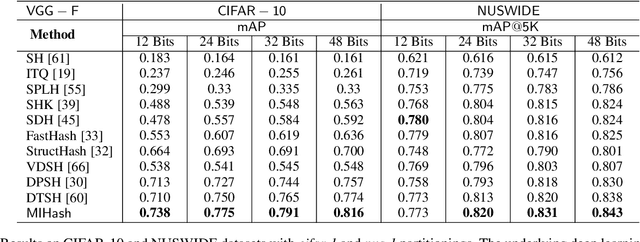
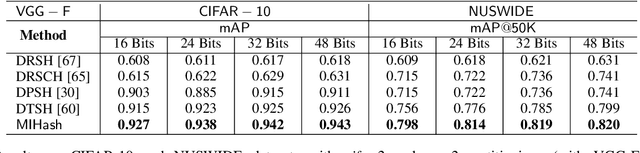
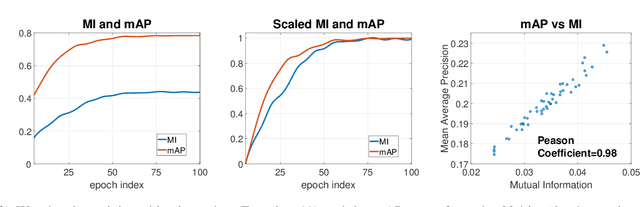
MIHash: Online Hashing with Mutual Information
Jul 29, 2017
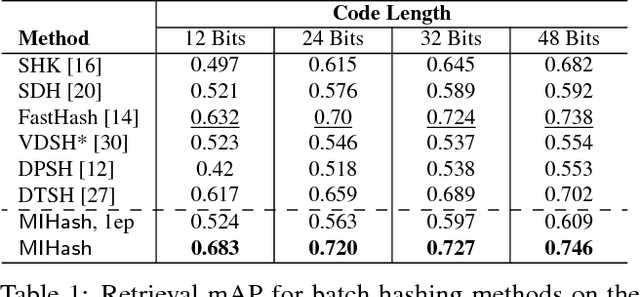
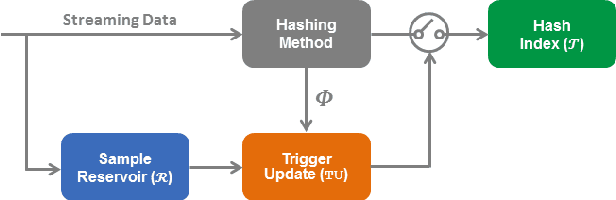
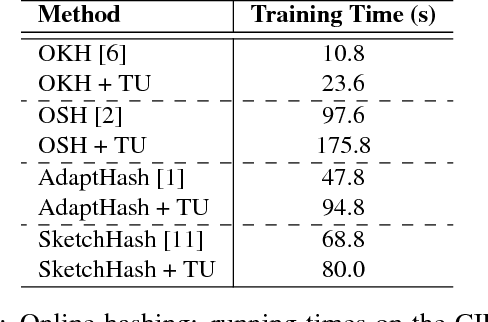
Learning-based hashing methods are widely used for nearest neighbor retrieval, and recently, online hashing methods have demonstrated good performance-complexity trade-offs by learning hash functions from streaming data. In this paper, we first address a key challenge for online hashing: the binary codes for indexed data must be recomputed to keep pace with updates to the hash functions. We propose an efficient quality measure for hash functions, based on an information-theoretic quantity, mutual information, and use it successfully as a criterion to eliminate unnecessary hash table updates. Next, we also show how to optimize the mutual information objective using stochastic gradient descent. We thus develop a novel hashing method, MIHash, that can be used in both online and batch settings. Experiments on image retrieval benchmarks (including a 2.5M image dataset) confirm the effectiveness of our formulation, both in reducing hash table recomputations and in learning high-quality hash functions.
Do Less and Achieve More: Training CNNs for Action Recognition Utilizing Action Images from the Web
Dec 22, 2015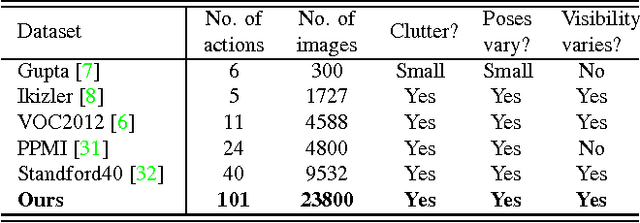

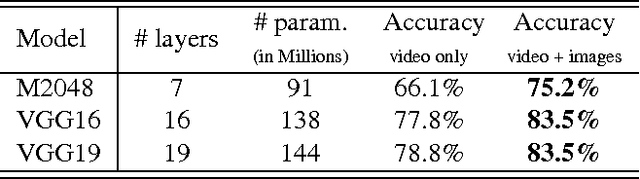
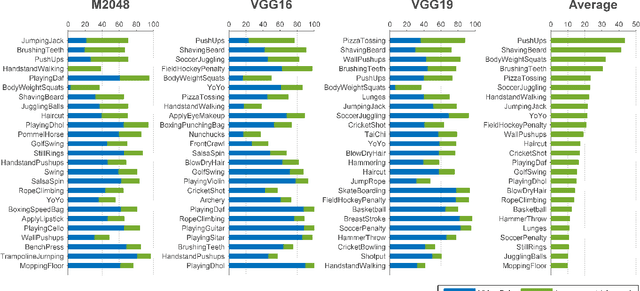
Recently, attempts have been made to collect millions of videos to train CNN models for action recognition in videos. However, curating such large-scale video datasets requires immense human labor, and training CNNs on millions of videos demands huge computational resources. In contrast, collecting action images from the Web is much easier and training on images requires much less computation. In addition, labeled web images tend to contain discriminative action poses, which highlight discriminative portions of a video's temporal progression. We explore the question of whether we can utilize web action images to train better CNN models for action recognition in videos. We collect 23.8K manually filtered images from the Web that depict the 101 actions in the UCF101 action video dataset. We show that by utilizing web action images along with videos in training, significant performance boosts of CNN models can be achieved. We then investigate the scalability of the process by leveraging crawled web images (unfiltered) for UCF101 and ActivityNet. We replace 16.2M video frames by 393K unfiltered images and get comparable performance.
Online Supervised Hashing for Ever-Growing Datasets
Nov 10, 2015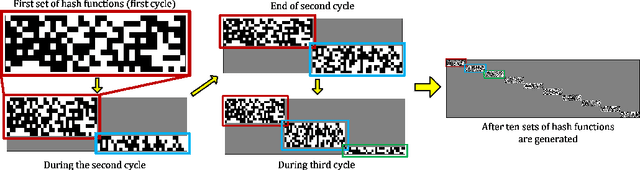
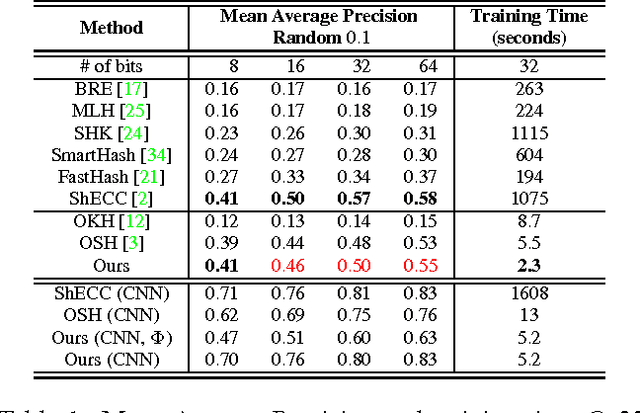
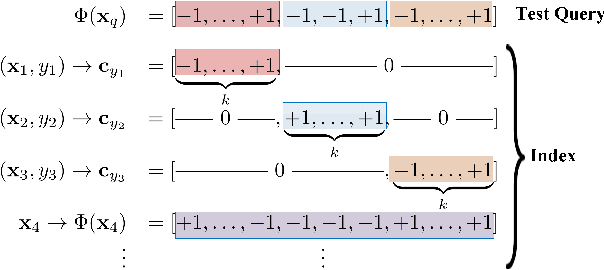
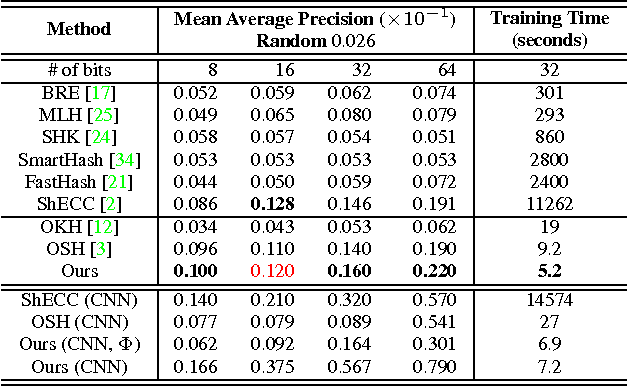
Supervised hashing methods are widely-used for nearest neighbor search in computer vision applications. Most state-of-the-art supervised hashing approaches employ batch-learners. Unfortunately, batch-learning strategies can be inefficient when confronted with large training datasets. Moreover, with batch-learners, it is unclear how to adapt the hash functions as a dataset continues to grow and diversify over time. Yet, in many practical scenarios the dataset grows and diversifies; thus, both the hash functions and the indexing must swiftly accommodate these changes. To address these issues, we propose an online hashing method that is amenable to changes and expansions of the datasets. Since it is an online algorithm, our approach offers linear complexity with the dataset size. Our solution is supervised, in that we incorporate available label information to preserve the semantic neighborhood. Such an adaptive hashing method is attractive; but it requires recomputing the hash table as the hash functions are updated. If the frequency of update is high, then recomputing the hash table entries may cause inefficiencies in the system, especially for large indexes. Thus, we also propose a framework to reduce hash table updates. We compare our method to state-of-the-art solutions on two benchmarks and demonstrate significant improvements over previous work.