 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCluster-GCN: An Efficient Algorithm for Training Deep and Large Graph Convolutional Networks
May 20, 2019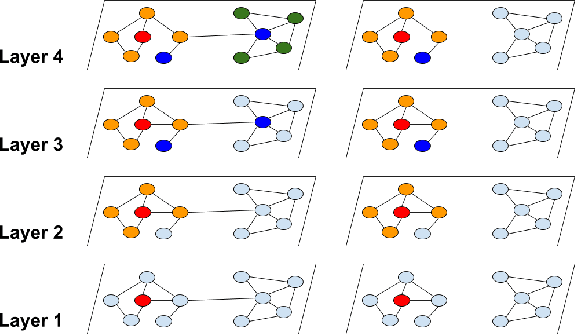
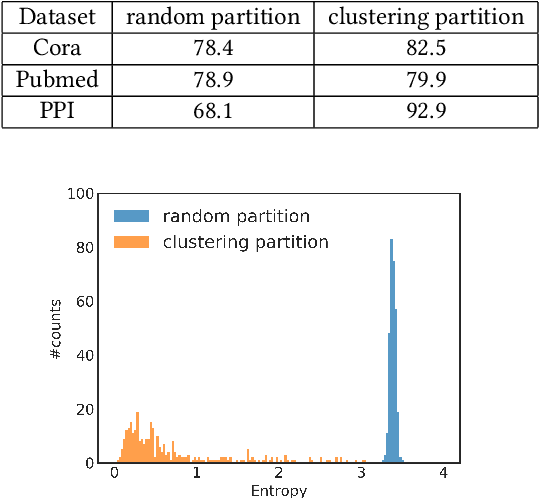
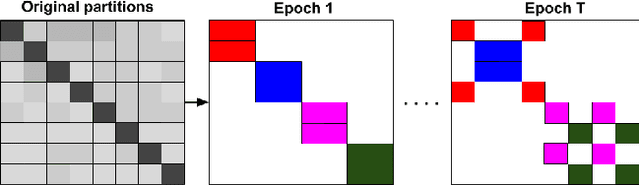
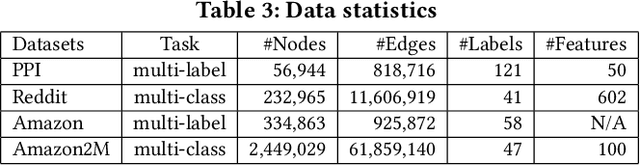
Graph convolutional network (GCN) has been successfully applied to many graph-based applications; however, training a large-scale GCN remains challenging. Current SGD-based algorithms suffer from either a high computational cost that exponentially grows with number of GCN layers, or a large space requirement for keeping the entire graph and the embedding of each node in memory. In this paper, we propose Cluster-GCN, a novel GCN algorithm that is suitable for SGD-based training by exploiting the graph clustering structure. Cluster-GCN works as the following: at each step, it samples a block of nodes that associate with a dense subgraph identified by a graph clustering algorithm, and restricts the neighborhood search within this subgraph. This simple but effective strategy leads to significantly improved memory and computational efficiency while being able to achieve comparable test accuracy with previous algorithms. To test the scalability of our algorithm, we create a new Amazon2M data with 2 million nodes and 61 million edges which is more than 5 times larger than the previous largest publicly available dataset (Reddit). For training a 3-layer GCN on this data, Cluster-GCN is faster than the previous state-of-the-art VR-GCN (1523 seconds vs 1961 seconds) and using much less memory (2.2GB vs 11.2GB). Furthermore, for training 4 layer GCN on this data, our algorithm can finish in around 36 minutes while all the existing GCN training algorithms fail to train due to the out-of-memory issue. Furthermore, Cluster-GCN allows us to train much deeper GCN without much time and memory overhead, which leads to improved prediction accuracy---using a 5-layer Cluster-GCN, we achieve state-of-the-art test F1 score 99.36 on the PPI dataset, while the previous best result was 98.71 by [16].
Do Neural Networks Show Gestalt Phenomena? An Exploration of the Law of Closure
Mar 21, 2019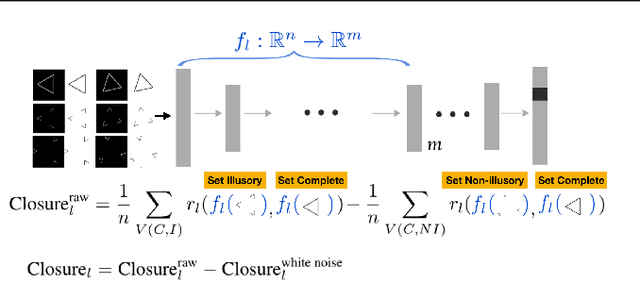
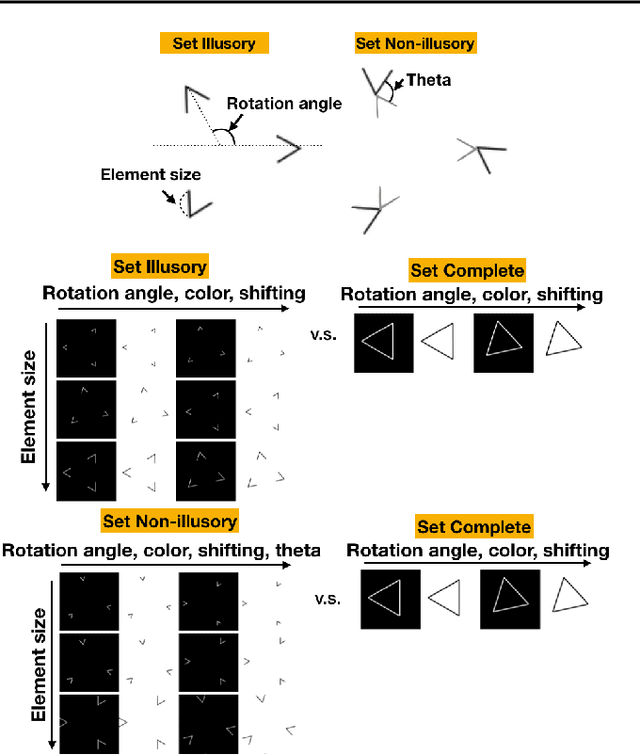
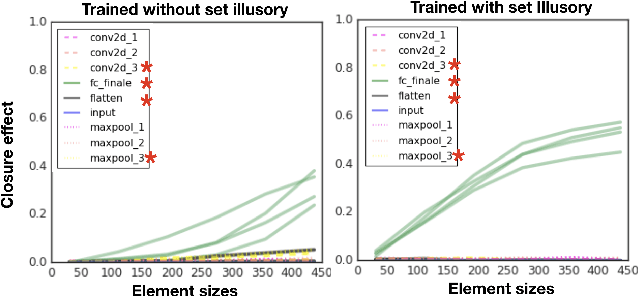
One characteristic of human visual perception is the presence of `Gestalt phenomena,' that is, that the whole is something other than the sum of its parts. A natural question is whether image-recognition networks show similar effects. Our paper investigates one particular type of Gestalt phenomenon, the law of closure, in the context of a feedforward image classification neural network (NN). This is a robust effect in human perception, but experiments typically rely on measurements (e.g., reaction time) that are not available for artificial neural nets. We describe a protocol for identifying closure effect in NNs, and report on the results of experiments with simple visual stimuli. Our findings suggest that NNs trained with natural images do exhibit closure, in contrast to networks with randomized weights or networks that have been trained on visually random data. Furthermore, the closure effect reflects something beyond good feature extraction; it is correlated with the network's higher layer features and ability to generalize.
Identity Crisis: Memorization and Generalization under Extreme Overparameterization
Feb 15, 2019

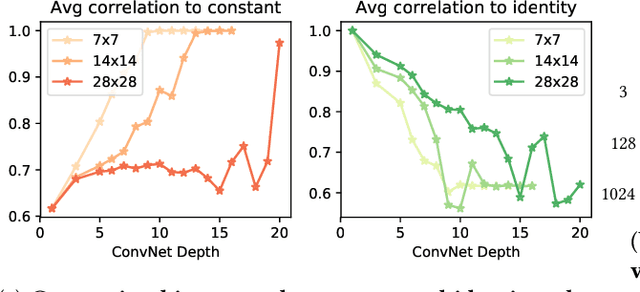

We study the interplay between memorization and generalization of overparametrized networks in the extreme case of a single training example. The learning task is to predict an output which is as similar as possible to the input. We examine both fully-connected and convolutional networks that are initialized randomly and then trained to minimize the reconstruction error. The trained networks take one of the two forms: the constant function ("memorization") and the identity function ("generalization"). We show that different architectures exhibit vastly different inductive bias towards memorization and generalization. An important consequence of our study is that even in extreme cases of overparameterization, deep learning can result in proper generalization.
Transfusion: Understanding Transfer Learning with Applications to Medical Imaging
Feb 14, 2019
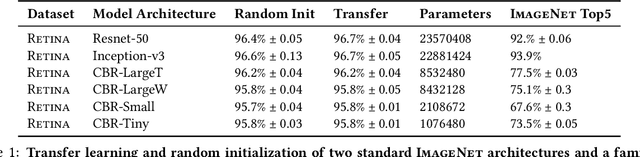
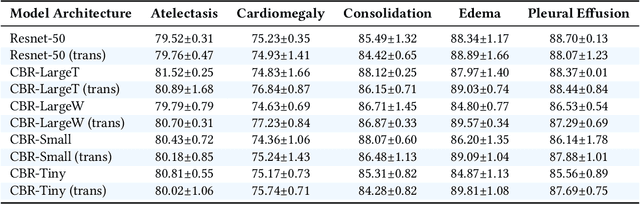
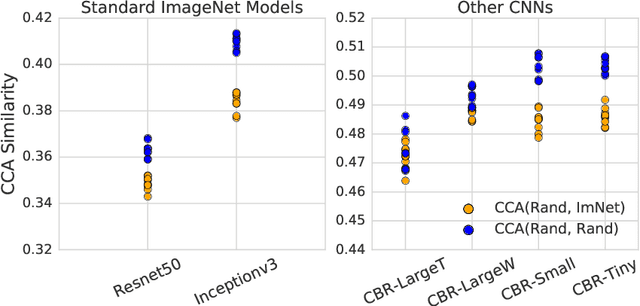
With the increasingly varied applications of deep learning, transfer learning has emerged as a critically important technique. However, the central question of how much feature reuse in transfer is the source of benefit remains unanswered. In this paper, we present an in-depth analysis of the effects of transfer, focusing on medical imaging, which is a particularly intriguing setting. Here, transfer learning is extremely popular, but data differences between pretraining and finetuing are considerable, reiterating the question of what is transferred. With experiments on two large scale medical imaging datasets, and CIFAR-10, we find transfer has almost negligible effects on performance, but significantly helps convergence speed. However, in all of these settings, convergence without transfer can be sped up dramatically by using only mean and variance statistics of the pretrained weights. Visualizing the lower layer filters shows that models trained from random initialization do not learn Gabor filters on medical images. We use CCA (canonical correlation analysis) to study the learned representations of the different models, finding that pretrained models are surprisingly similar to random initialization at higher layers. This similarity is evidenced both through model learning dynamics and a transfusion experiment, which explores the convergence speed using a subset of pretrained weights.
Are All Layers Created Equal?
Feb 12, 2019
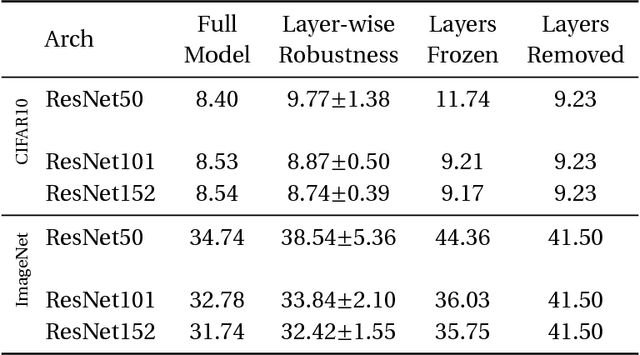
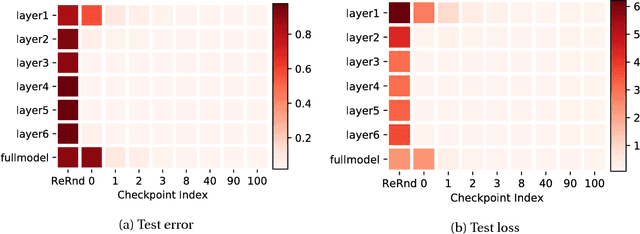
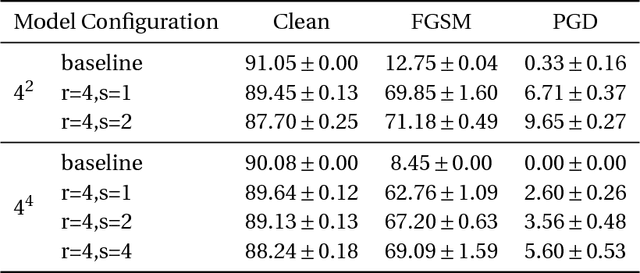
Understanding learning and generalization of deep architectures has been a major research objective in the recent years with notable theoretical progress. A main focal point of generalization studies stems from the success of excessively large networks which defy the classical wisdom of uniform convergence and learnability. We study empirically the layer-wise functional structure of overparameterized deep models. We provide evidence for the heterogeneous characteristic of layers. To do so, we introduce the notion of (post training) re-initialization and re-randomization robustness. We show that layers can be categorized into either `robust' or `critical'. In contrast to critical layers, resetting the robust layers to their initial value has no negative consequence, and in many cases they barely change throughout training. Our study provides further evidence that mere parameter counting or norm accounting is too coarse in studying generalization of deep models, and flatness or robustness analysis of the model parameters needs to respect the network architectures.
Semantic Redundancies in Image-Classification Datasets: The 10% You Don't Need
Jan 29, 2019
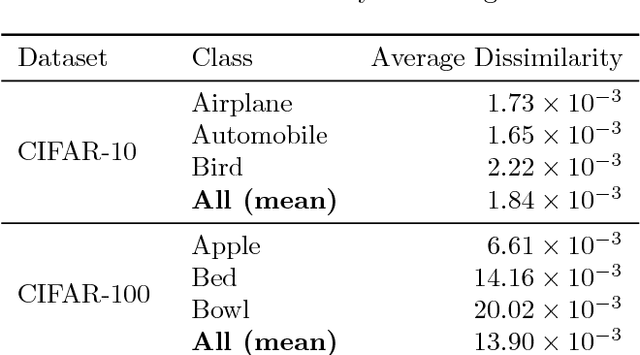
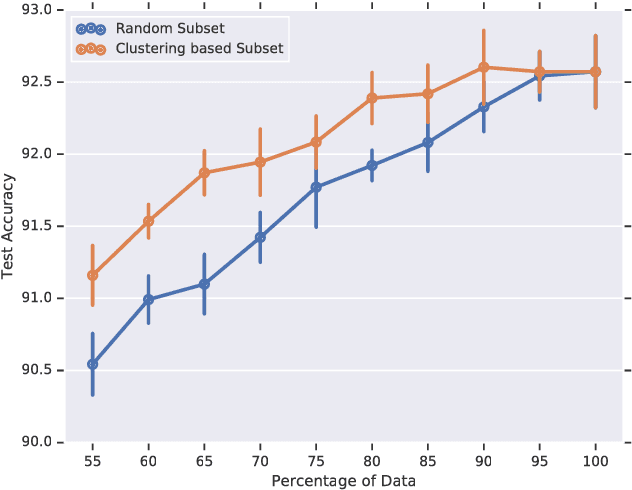

Large datasets have been crucial to the success of deep learning models in the recent years, which keep performing better as they are trained with more labelled data. While there have been sustained efforts to make these models more data-efficient, the potential benefit of understanding the data itself, is largely untapped. Specifically, focusing on object recognition tasks, we wonder if for common benchmark datasets we can do better than random subsets of the data and find a subset that can generalize on par with the full dataset when trained on. To our knowledge, this is the first result that can find notable redundancies in CIFAR-10 and ImageNet datasets (at least 10%). Interestingly, we observe semantic correlations between required and redundant images. We hope that our findings can motivate further research into identifying additional redundancies and exploiting them for more efficient training or data-collection.
Unsupervised speech representation learning using WaveNet autoencoders
Jan 25, 2019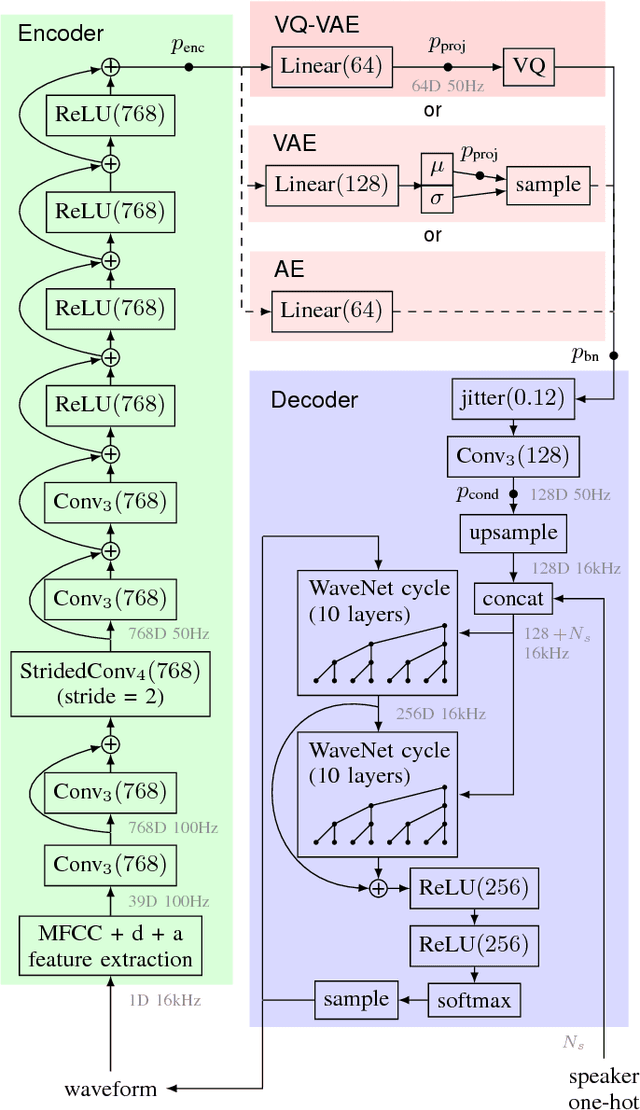
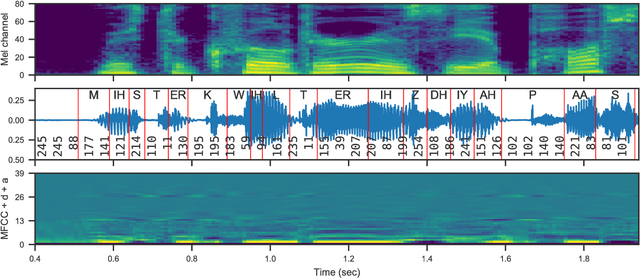
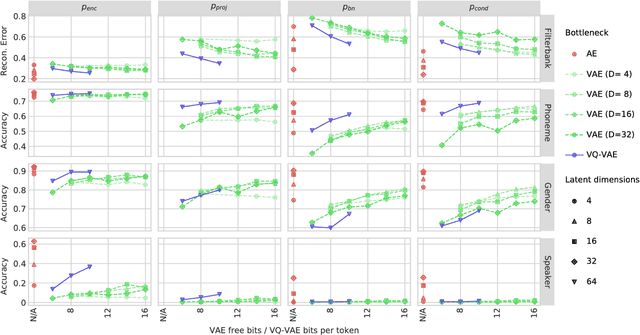
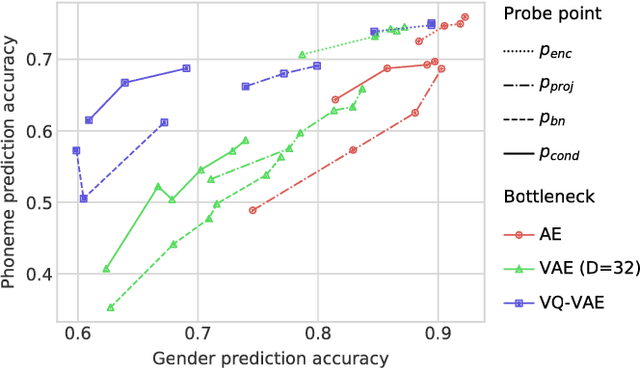
We consider the task of unsupervised extraction of meaningful latent representations of speech by applying autoencoding neural networks to speech waveforms. The goal is to learn a representation able to capture high level semantic content from the signal, e.g. phoneme identities, while being invariant to confounding low level details in the signal such as the underlying pitch contour or background noise. The behavior of autoencoder models depends on the kind of constraint that is applied to the latent representation. We compare three variants: a simple dimensionality reduction bottleneck, a Gaussian Variational Autoencoder (VAE), and a discrete Vector Quantized VAE (VQ-VAE). We analyze the quality of learned representations in terms of speaker independence, the ability to predict phonetic content, and the ability to accurately reconstruct individual spectrogram frames. Moreover, for discrete encodings extracted using the VQ-VAE, we measure the ease of mapping them to phonemes. We introduce a regularization scheme that forces the representations to focus on the phonetic content of the utterance and report performance comparable with the top entries in the ZeroSpeech 2017 unsupervised acoustic unit discovery task.
GaterNet: Dynamic Filter Selection in Convolutional Neural Network via a Dedicated Global Gating Network
Nov 27, 2018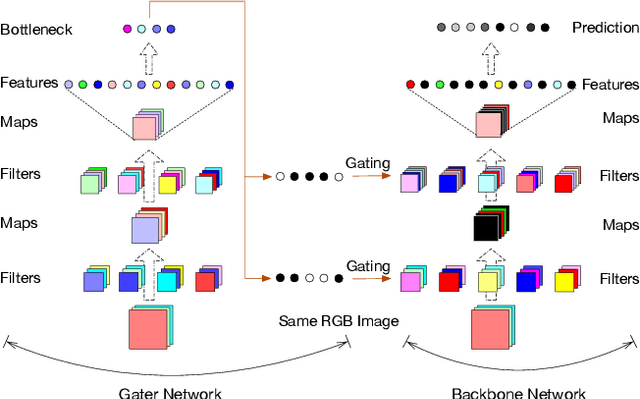
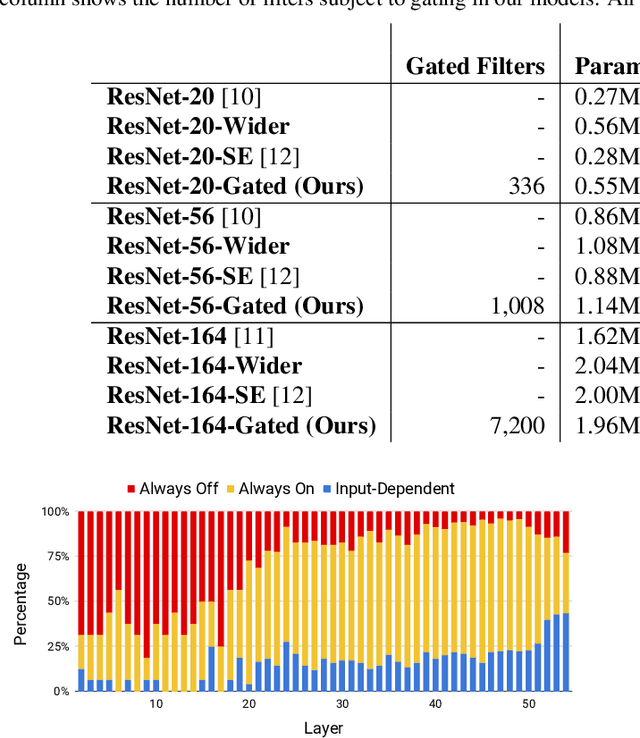
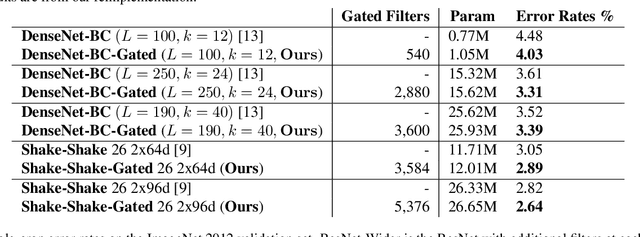

The concept of conditional computation for deep nets has been proposed previously to improve model performance by selectively using only parts of the model conditioned on the sample it is processing. In this paper, we investigate input-dependent dynamic filter selection in deep convolutional neural networks (CNNs). The problem is interesting because the idea of forcing different parts of the model to learn from different types of samples may help us acquire better filters in CNNs, improve the model generalization performance and potentially increase the interpretability of model behavior. We propose a novel yet simple framework called GaterNet, which involves a backbone and a gater network. The backbone network is a regular CNN that performs the major computation needed for making a prediction, while a global gater network is introduced to generate binary gates for selectively activating filters in the backbone network based on each input. Extensive experiments on CIFAR and ImageNet datasets show that our models consistently outperform the original models with a large margin. On CIFAR-10, our model also improves upon state-of-the-art results.
Content preserving text generation with attribute controls
Nov 03, 2018
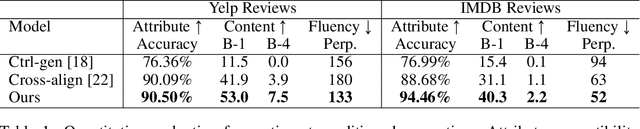
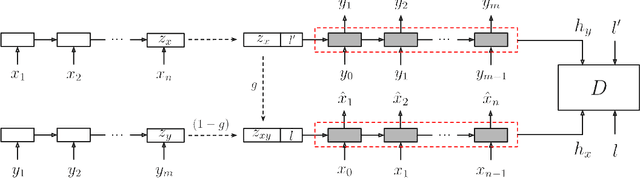
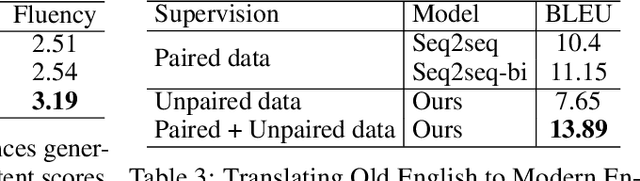
In this work, we address the problem of modifying textual attributes of sentences. Given an input sentence and a set of attribute labels, we attempt to generate sentences that are compatible with the conditioning information. To ensure that the model generates content compatible sentences, we introduce a reconstruction loss which interpolates between auto-encoding and back-translation loss components. We propose an adversarial loss to enforce generated samples to be attribute compatible and realistic. Through quantitative, qualitative and human evaluations we demonstrate that our model is capable of generating fluent sentences that better reflect the conditioning information compared to prior methods. We further demonstrate that the model is capable of simultaneously controlling multiple attributes.
Area Attention
Oct 30, 2018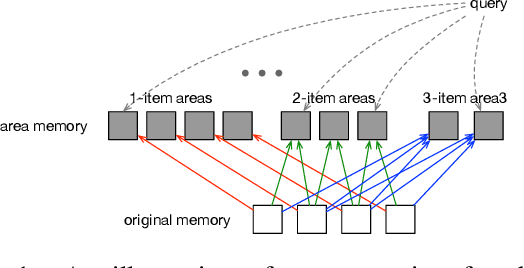
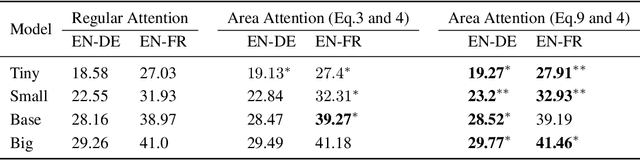
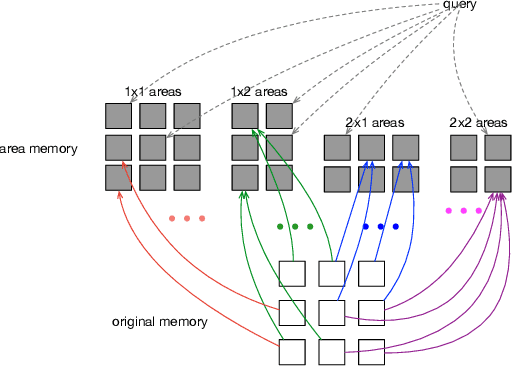
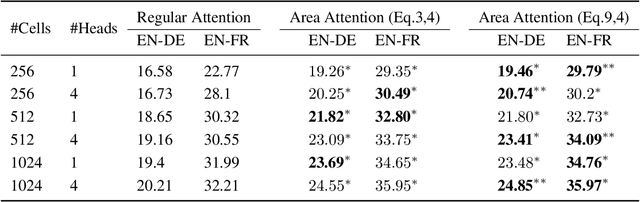
Existing attention mechanisms, are mostly item-based in that a model is designed to attend to a single item in a collection of items (the memory). Intuitively, an area in the memory that may contain multiple items can be worth attending to as a whole. We propose area attention: a way to attend to an area of the memory, where each area contains a group of items that are either spatially adjacent when the memory has a 2-dimensional structure, such as images, or temporally adjacent for 1-dimensional memory, such as natural language sentences. Importantly, the size of an area, i.e., the number of items in an area, can vary depending on the learned coherence of the adjacent items. By giving the model the option to attend to an area of items, instead of only a single item, we hope attention mechanisms can better capture the nature of the task. Area attention can work along multi-head attention for attending to multiple areas in the memory. We evaluate area attention on two tasks: neural machine translation and image captioning, and improve upon strong (state-of-the-art) baselines in both cases. These improvements are obtainable with a basic form of area attention that is parameter free. In addition to proposing the novel concept of area attention, we contribute an efficient way for computing it by leveraging the technique of summed area tables.