 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat do you learn from context? Probing for sentence structure in contextualized word representations
May 15, 2019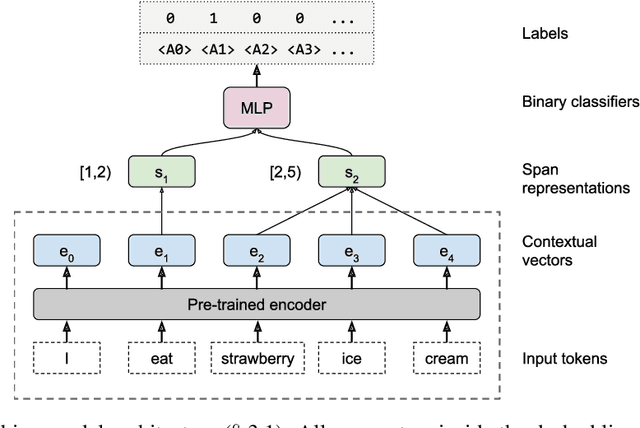

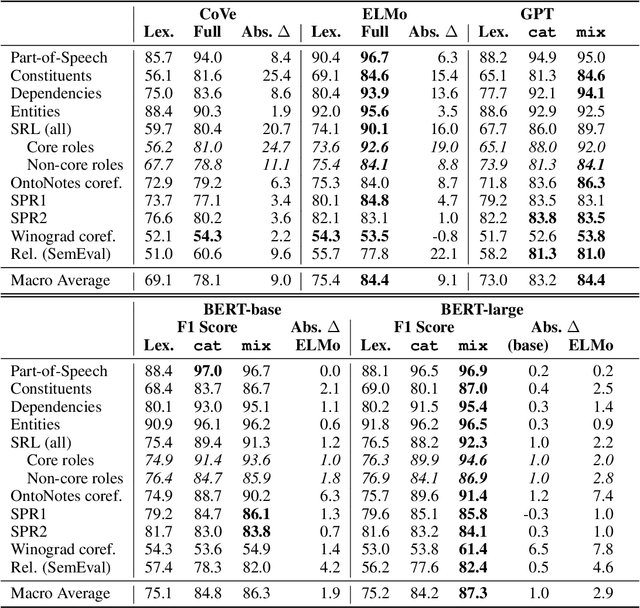
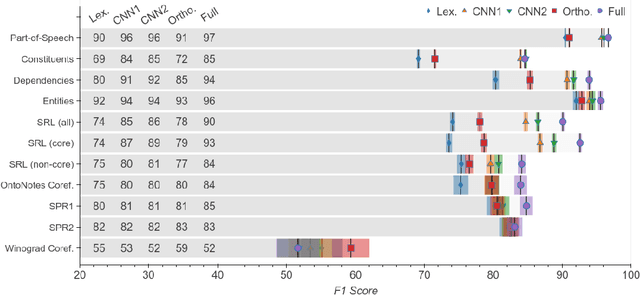
Contextualized representation models such as ELMo (Peters et al., 2018a) and BERT (Devlin et al., 2018) have recently achieved state-of-the-art results on a diverse array of downstream NLP tasks. Building on recent token-level probing work, we introduce a novel edge probing task design and construct a broad suite of sub-sentence tasks derived from the traditional structured NLP pipeline. We probe word-level contextual representations from four recent models and investigate how they encode sentence structure across a range of syntactic, semantic, local, and long-range phenomena. We find that existing models trained on language modeling and translation produce strong representations for syntactic phenomena, but only offer comparably small improvements on semantic tasks over a non-contextual baseline.
SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems
May 02, 2019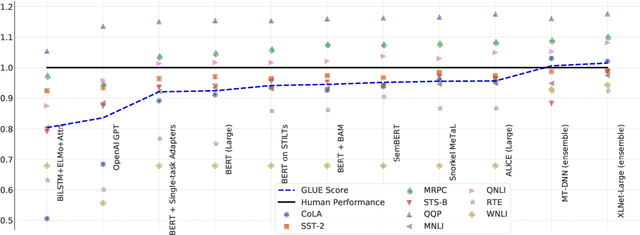
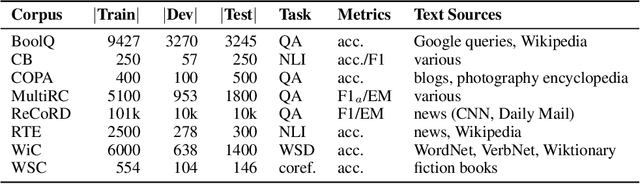

In the last year, new models and methods for pretraining and transfer learning have driven striking performance improvements across a range of language understanding tasks. The GLUE benchmark, introduced one year ago, offers a single-number metric that summarizes progress on a diverse set of such tasks, but performance on the benchmark has recently come close to the level of non-expert humans, suggesting limited headroom for further research. This paper recaps lessons learned from the GLUE benchmark and presents SuperGLUE, a new benchmark styled after GLUE with a new set of more difficult language understanding tasks, improved resources, and a new public leaderboard. SuperGLUE will be available soon at super.gluebenchmark.com.
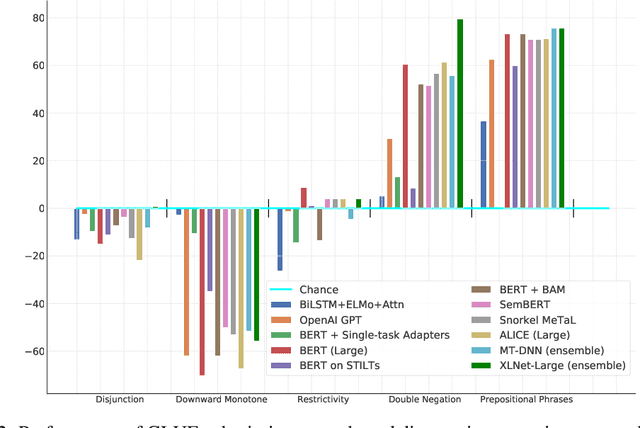
Probing What Different NLP Tasks Teach Machines about Function Word Comprehension
Apr 25, 2019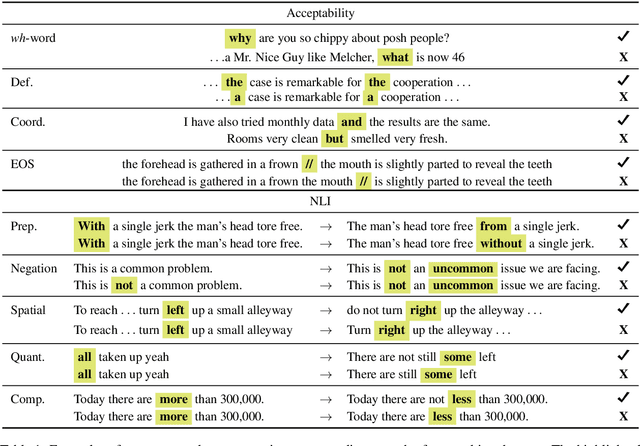
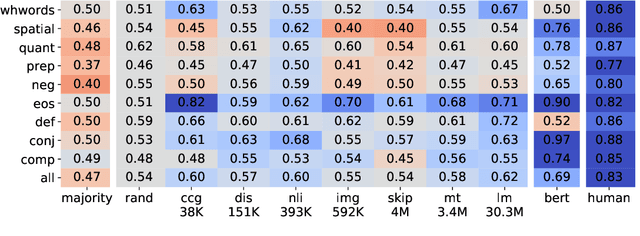

We introduce a set of nine challenge tasks that test for the understanding of function words. These tasks are created by structurally mutating sentences from existing datasets to target the comprehension of specific types of function words (e.g., prepositions, wh-words). Using these probing tasks, we explore the effects of various pretraining objectives for sentence encoders (e.g., language modeling, CCG supertagging and natural language inference (NLI)) on the learned representations. Our results show that pretraining on CCG---our most syntactic objective---performs the best on average across our probing tasks, suggesting that syntactic knowledge helps function word comprehension. Language modeling also shows strong performance, supporting its widespread use for pretraining state-of-the-art NLP models. Overall, no pretraining objective dominates across the board, and our function word probing tasks highlight several intuitive differences between pretraining objectives, e.g., that NLI helps the comprehension of negation.
Identifying and Reducing Gender Bias in Word-Level Language Models
Apr 05, 2019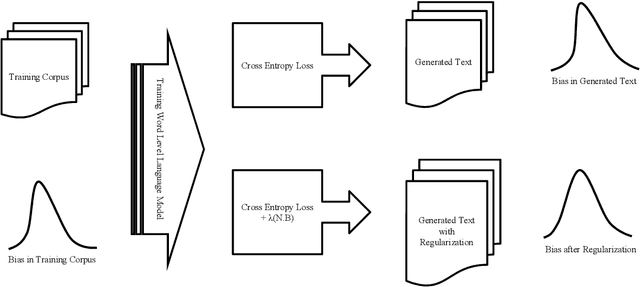
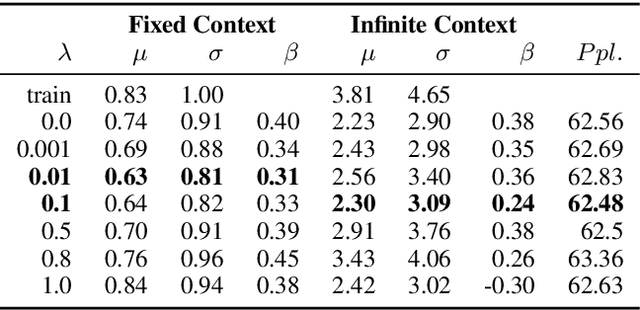
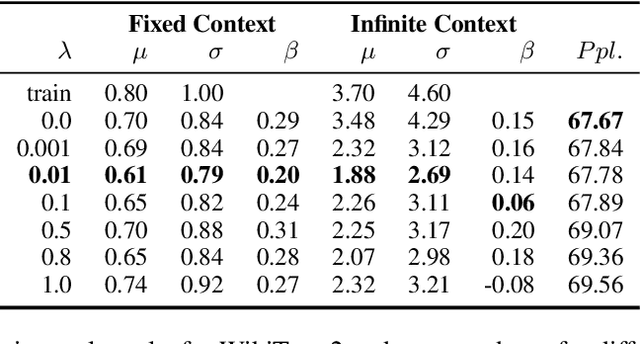
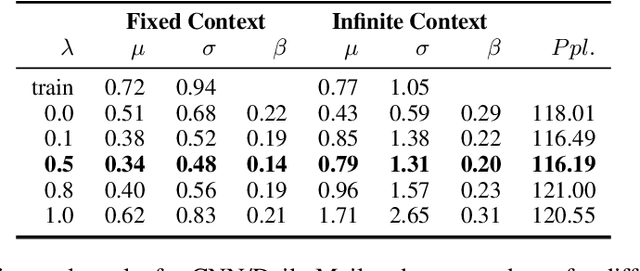
Many text corpora exhibit socially problematic biases, which can be propagated or amplified in the models trained on such data. For example, doctor cooccurs more frequently with male pronouns than female pronouns. In this study we (i) propose a metric to measure gender bias; (ii) measure bias in a text corpus and the text generated from a recurrent neural network language model trained on the text corpus; (iii) propose a regularization loss term for the language model that minimizes the projection of encoder-trained embeddings onto an embedding subspace that encodes gender; (iv) finally, evaluate efficacy of our proposed method on reducing gender bias. We find this regularization method to be effective in reducing gender bias up to an optimal weight assigned to the loss term, beyond which the model becomes unstable as the perplexity increases. We replicate this study on three training corpora---Penn Treebank, WikiText-2, and CNN/Daily Mail---resulting in similar conclusions.
On Measuring Social Biases in Sentence Encoders
Mar 25, 2019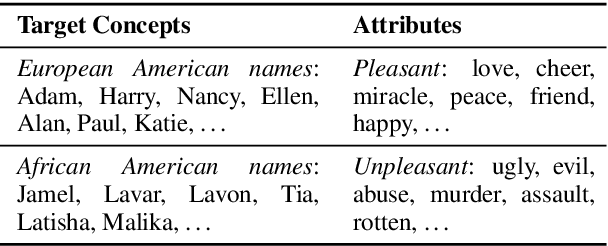
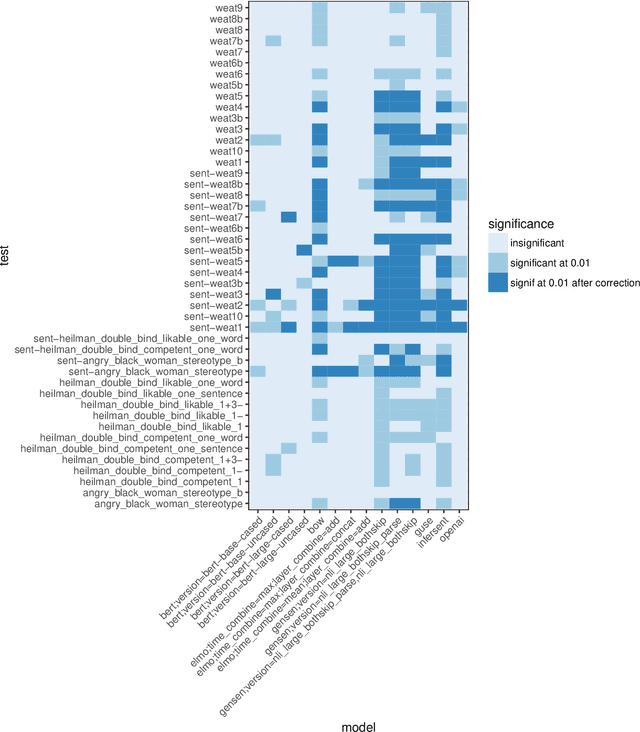

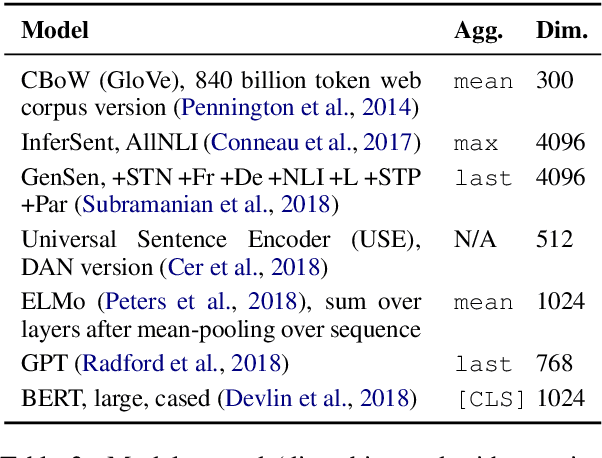
The Word Embedding Association Test shows that GloVe and word2vec word embeddings exhibit human-like implicit biases based on gender, race, and other social constructs (Caliskan et al., 2017). Meanwhile, research on learning reusable text representations has begun to explore sentence-level texts, with some sentence encoders seeing enthusiastic adoption. Accordingly, we extend the Word Embedding Association Test to measure bias in sentence encoders. We then test several sentence encoders, including state-of-the-art methods such as ELMo and BERT, for the social biases studied in prior work and two important biases that are difficult or impossible to test at the word level. We observe mixed results including suspicious patterns of sensitivity that suggest the test's assumptions may not hold in general. We conclude by proposing directions for future work on measuring bias in sentence encoders.
Grammatical Analysis of Pretrained Sentence Encoders with Acceptability Judgments
Jan 11, 2019
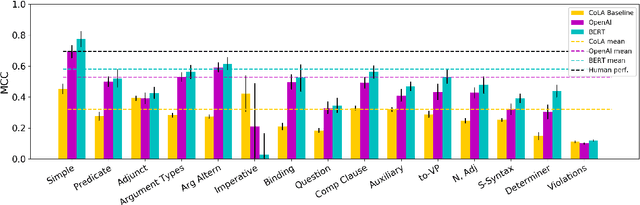
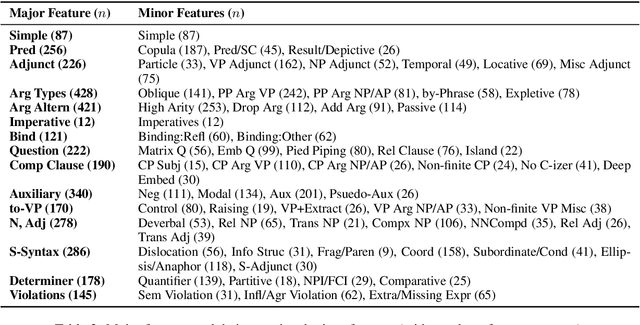
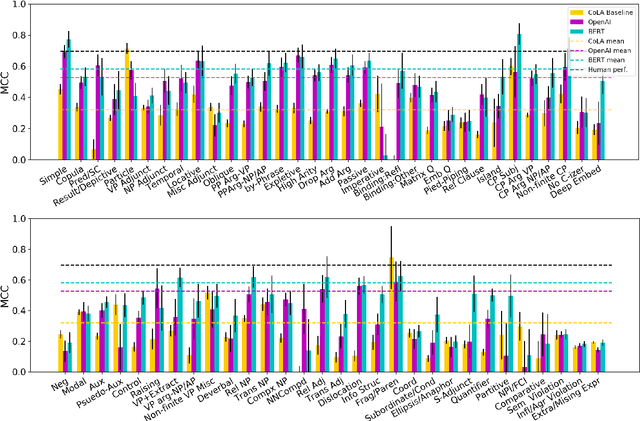
Recent pretrained sentence encoders achieve state of the art results on language understanding tasks, but does this mean they have implicit knowledge of syntactic structures? We introduce a grammatically annotated development set for the Corpus of Linguistic Acceptability (CoLA; Warstadt et al., 2018), which we use to investigate the grammatical knowledge of three pretrained encoders, including the popular OpenAI Transformer (Radford et al., 2018) and BERT (Devlin et al., 2018). We fine-tune these encoders to do acceptability classification over CoLA and compare the models' performance on the annotated analysis set. Some phenomena, e.g. modification by adjuncts, are easy to learn for all models, while others, e.g. long-distance movement, are learned effectively only by models with strong overall performance, and others still, e.g. morphological agreement, are hardly learned by any model.
Looking for ELMo's friends: Sentence-Level Pretraining Beyond Language Modeling
Dec 28, 2018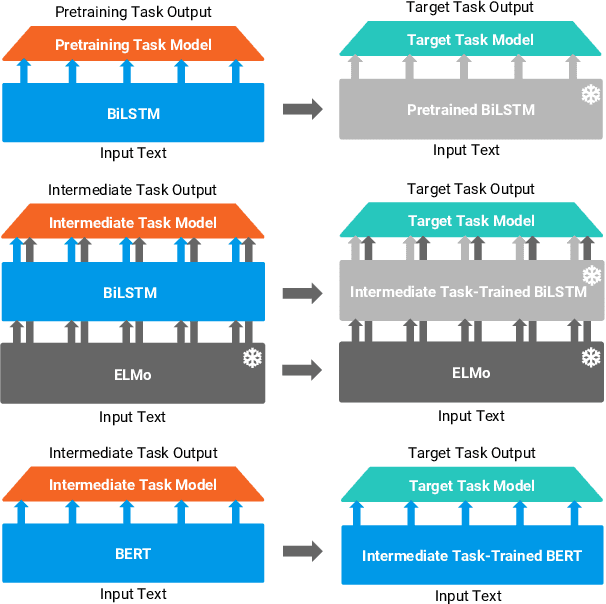
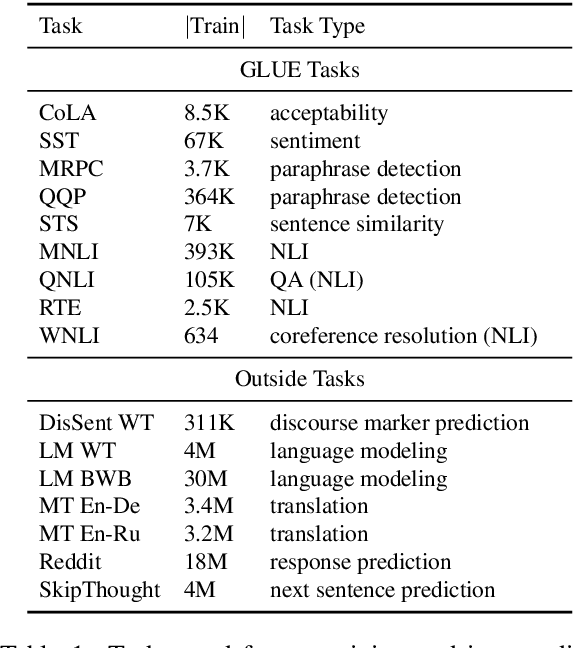
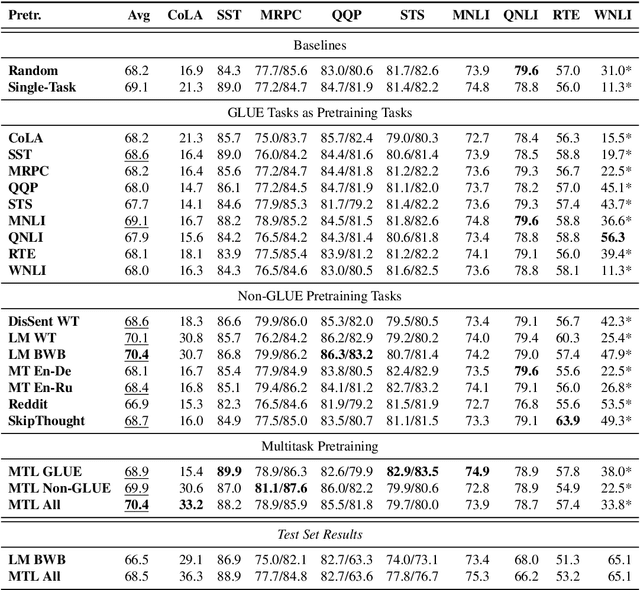
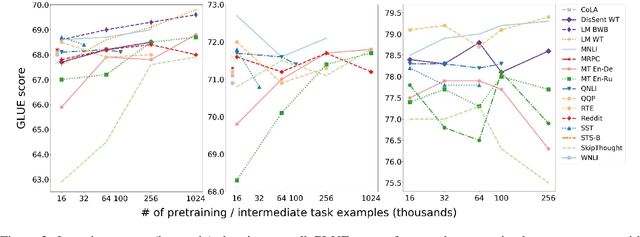
Work on the problem of contextualized word representation -- the development of reusable neural network components for sentence understanding -- has recently seen a surge of progress centered on the unsupervised pretraining task of language modeling with methods like ELMo. This paper contributes the first large-scale systematic study comparing different pretraining tasks in this context, both as complements to language modeling and as potential alternatives. The primary results of the study support the use of language modeling as a pretraining task and set a new state of the art among comparable models using multitask learning with language models. However, a closer look at these results reveals worryingly strong baselines and strikingly varied results across target tasks, suggesting that the widely-used paradigm of pretraining and freezing sentence encoders may not be an ideal platform for further work.
Verb Argument Structure Alternations in Word and Sentence Embeddings
Nov 27, 2018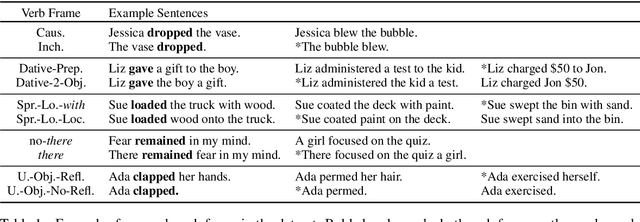
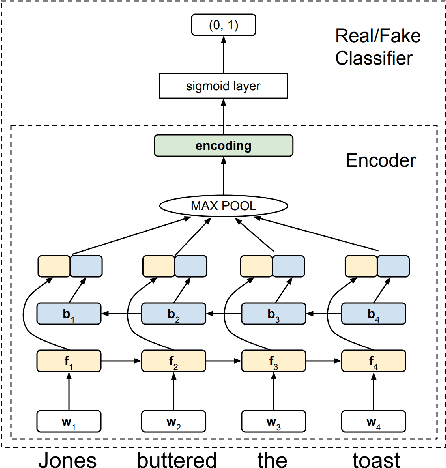

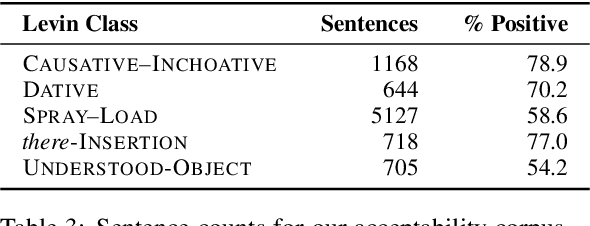
Verbs occur in different syntactic environments, or frames. We investigate whether artificial neural networks encode grammatical distinctions necessary for inferring the idiosyncratic frame-selectional properties of verbs. We introduce five datasets, collectively called FAVA, containing in aggregate nearly 10k sentences labeled for grammatical acceptability, illustrating different verbal argument structure alternations. We then test whether models can distinguish acceptable English verb-frame combinations from unacceptable ones using a sentence embedding alone. For converging evidence, we further construct LaVA, a corresponding word-level dataset, and investigate whether the same syntactic features can be extracted from word embeddings. Our models perform reliable classifications for some verbal alternations but not others, suggesting that while these representations do encode fine-grained lexical information, it is incomplete or can be hard to extract. Further, differences between the word- and sentence-level models show that some information present in word embeddings is not passed on to the down-stream sentence embeddings.
Sentence Encoders on STILTs: Supplementary Training on Intermediate Labeled-data Tasks
Nov 02, 2018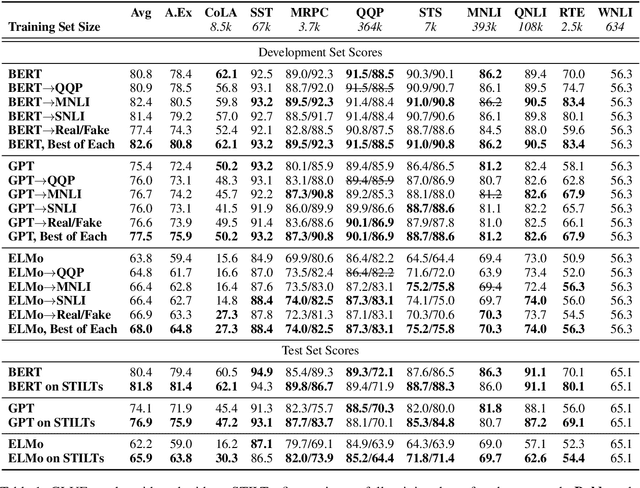
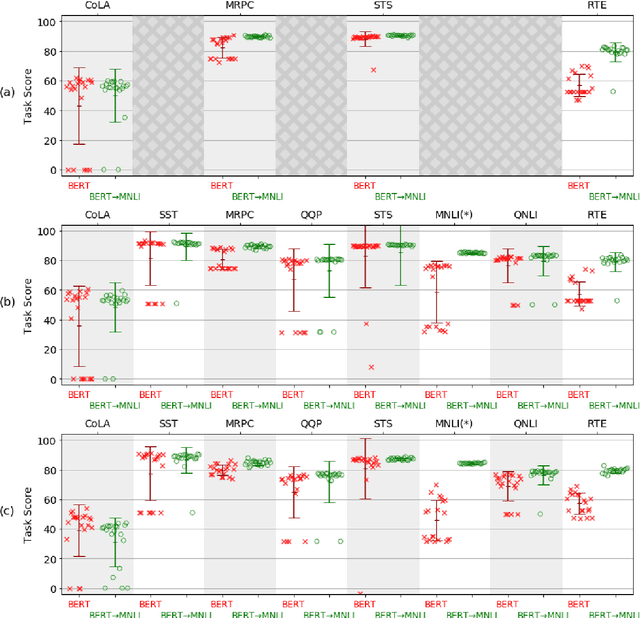
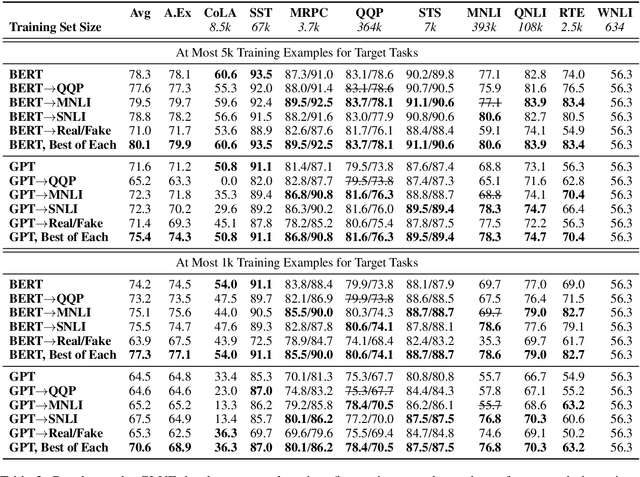
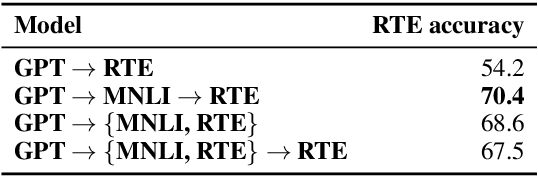
Pretraining with language modeling and related unsupervised tasks has recently been shown to be a very effective enabling technology for the development of neural network models for language understanding tasks. In this work, we show that although language model-style pretraining is extremely effective at teaching models about language, it does not yield an ideal starting point for efficient transfer learning. By supplementing language model-style pretraining with further training on data-rich supervised tasks, we are able to achieve substantial additional performance improvements across the nine target tasks in the GLUE benchmark. We obtain an overall score of 76.9 on GLUE--a 2.3 point improvement over our baseline system adapted from Radford et al. (2018) and a 4.1 point improvement over Radford et al.'s reported score. We further use training data downsampling to show that the benefits of this supplementary training are even more pronounced in data-constrained regimes.
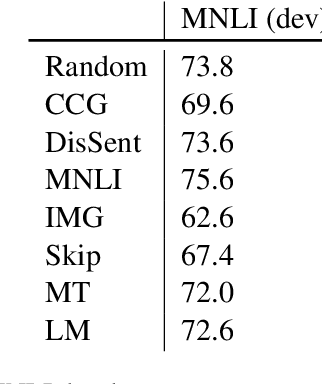
Language Modeling Teaches You More Syntax than Translation Does: Lessons Learned Through Auxiliary Task Analysis
Sep 26, 2018

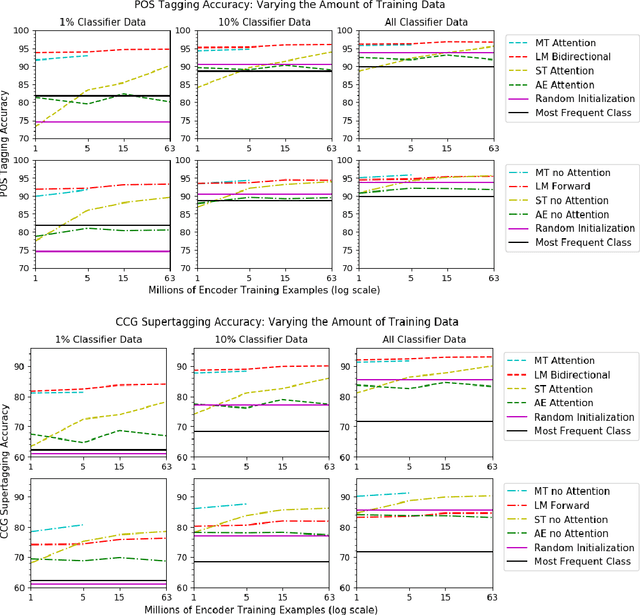
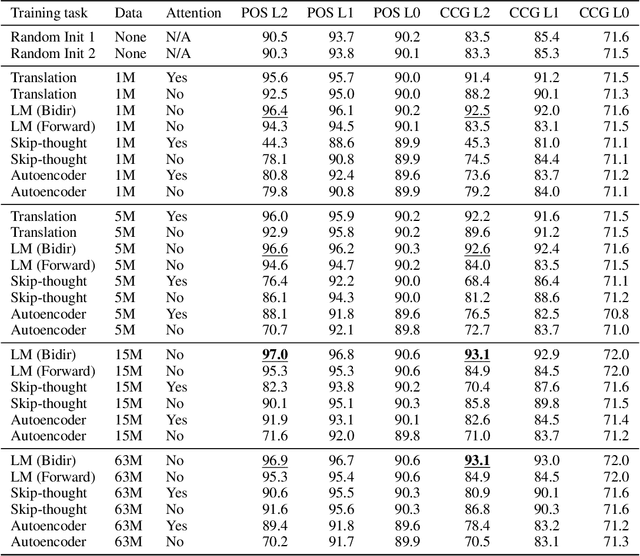
Recent work using auxiliary prediction task classifiers to investigate the properties of LSTM representations has begun to shed light on why pretrained representations, like ELMo (Peters et al., 2018) and CoVe (McCann et al., 2017), are so beneficial for neural language understanding models. We still, though, do not yet have a clear understanding of how the choice of pretraining objective affects the type of linguistic information that models learn. With this in mind, we compare four objectives---language modeling, translation, skip-thought, and autoencoding---on their ability to induce syntactic and part-of-speech information. We make a fair comparison between the tasks by holding constant the quantity and genre of the training data, as well as the LSTM architecture. We find that representations from language models consistently perform best on our syntactic auxiliary prediction tasks, even when trained on relatively small amounts of data. These results suggest that language modeling may be the best data-rich pretraining task for transfer learning applications requiring syntactic information. We also find that the representations from randomly-initialized, frozen LSTMs perform strikingly well on our syntactic auxiliary tasks, but this effect disappears when the amount of training data for the auxiliary tasks is reduced.