 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaverick-Aware Shapley Valuation for Client Selection in Federated Learning
May 21, 2024



Federated Learning (FL) allows clients to train a model collaboratively without sharing their private data. One key challenge in practical FL systems is data heterogeneity, particularly in handling clients with rare data, also referred to as Mavericks. These clients own one or more data classes exclusively, and the model performance becomes poor without their participation. Thus, utilizing Mavericks throughout training is crucial. In this paper, we first design a Maverick-aware Shapley valuation that fairly evaluates the contribution of Mavericks. The main idea is to compute the clients' Shapley values (SV) class-wise, i.e., per label. Next, we propose FedMS, a Maverick-Shapley client selection mechanism for FL that intelligently selects the clients that contribute the most in each round, by employing our Maverick-aware SV-based contribution score. We show that, compared to an extensive list of baselines, FedMS achieves better model performance and fairer Shapley Rewards distribution.
Revisiting OPRO: The Limitations of Small-Scale LLMs as Optimizers
May 16, 2024Numerous recent works aim to enhance the efficacy of Large Language Models (LLMs) through strategic prompting. In particular, the Optimization by PROmpting (OPRO) approach provides state-of-the-art performance by leveraging LLMs as optimizers where the optimization task is to find instructions that maximize the task accuracy. In this paper, we revisit OPRO for automated prompting with relatively small-scale LLMs, such as LLaMa-2 family and Mistral 7B. Our investigation reveals that OPRO shows limited effectiveness in small-scale LLMs, with limited inference capabilities constraining optimization ability. We suggest future automatic prompting engineering to consider both model capabilities and computational costs. Additionally, for small-scale LLMs, we recommend direct instructions that clearly outline objectives and methodologies as robust prompt baselines, ensuring efficient and effective prompt engineering in ongoing research.
Federated Learning Privacy: Attacks, Defenses, Applications, and Policy Landscape - A Survey
May 06, 2024Deep learning has shown incredible potential across a vast array of tasks and accompanying this growth has been an insatiable appetite for data. However, a large amount of data needed for enabling deep learning is stored on personal devices and recent concerns on privacy have further highlighted challenges for accessing such data. As a result, federated learning (FL) has emerged as an important privacy-preserving technology enabling collaborative training of machine learning models without the need to send the raw, potentially sensitive, data to a central server. However, the fundamental premise that sending model updates to a server is privacy-preserving only holds if the updates cannot be "reverse engineered" to infer information about the private training data. It has been shown under a wide variety of settings that this premise for privacy does {\em not} hold. In this survey paper, we provide a comprehensive literature review of the different privacy attacks and defense methods in FL. We identify the current limitations of these attacks and highlight the settings in which FL client privacy can be broken. We dissect some of the successful industry applications of FL and draw lessons for future successful adoption. We survey the emerging landscape of privacy regulation for FL. We conclude with future directions for taking FL toward the cherished goal of generating accurate models while preserving the privacy of the data from its participants.
Ethos: Rectifying Language Models in Orthogonal Parameter Space
Apr 01, 2024



Language models (LMs) have greatly propelled the research on natural language processing. However, LMs also raise concerns regarding the generation of biased or toxic content and the potential disclosure of private information from the training dataset. In this work, we present a new efficient approach, Ethos, that rectifies LMs to mitigate toxicity and bias in outputs and avoid privacy leakage. Ethos is built on task arithmetic. However, unlike current task arithmetic algorithms, Ethos distinguishes general beneficial and undesired knowledge when reconstructing task vectors. Specifically, Ethos first obtains a set of principal components from the pre-trained models using singular value decomposition. Then, by projecting the task vector onto principal components, Ethos identifies the principal components that encode general or undesired knowledge. Ethos performs negating using the task vector with undesired knowledge only, thereby minimizing collateral damage on general model utility. We demonstrate the efficacy of our approach on three different tasks: debiasing, detoxification, and memorization unlearning. Evaluations show Ethos is more effective in removing undesired knowledge and maintaining the overall model performance compared to current task arithmetic methods.
Hawk: Accurate and Fast Privacy-Preserving Machine Learning Using Secure Lookup Table Computation
Mar 26, 2024



Training machine learning models on data from multiple entities without direct data sharing can unlock applications otherwise hindered by business, legal, or ethical constraints. In this work, we design and implement new privacy-preserving machine learning protocols for logistic regression and neural network models. We adopt a two-server model where data owners secret-share their data between two servers that train and evaluate the model on the joint data. A significant source of inefficiency and inaccuracy in existing methods arises from using Yao's garbled circuits to compute non-linear activation functions. We propose new methods for computing non-linear functions based on secret-shared lookup tables, offering both computational efficiency and improved accuracy. Beyond introducing leakage-free techniques, we initiate the exploration of relaxed security measures for privacy-preserving machine learning. Instead of claiming that the servers gain no knowledge during the computation, we contend that while some information is revealed about access patterns to lookup tables, it maintains epsilon-dX-privacy. Leveraging this relaxation significantly reduces the computational resources needed for training. We present new cryptographic protocols tailored to this relaxed security paradigm and define and analyze the leakage. Our evaluations show that our logistic regression protocol is up to 9x faster, and the neural network training is up to 688x faster than SecureML. Notably, our neural network achieves an accuracy of 96.6% on MNIST in 15 epochs, outperforming prior benchmarks that capped at 93.4% using the same architecture.
Edge Private Graph Neural Networks with Singular Value Perturbation
Mar 16, 2024



Graph neural networks (GNNs) play a key role in learning representations from graph-structured data and are demonstrated to be useful in many applications. However, the GNN training pipeline has been shown to be vulnerable to node feature leakage and edge extraction attacks. This paper investigates a scenario where an attacker aims to recover private edge information from a trained GNN model. Previous studies have employed differential privacy (DP) to add noise directly to the adjacency matrix or a compact graph representation. The added perturbations cause the graph structure to be substantially morphed, reducing the model utility. We propose a new privacy-preserving GNN training algorithm, Eclipse, that maintains good model utility while providing strong privacy protection on edges. Eclipse is based on two key observations. First, adjacency matrices in graph structures exhibit low-rank behavior. Thus, Eclipse trains GNNs with a low-rank format of the graph via singular values decomposition (SVD), rather than the original graph. Using the low-rank format, Eclipse preserves the primary graph topology and removes the remaining residual edges. Eclipse adds noise to the low-rank singular values instead of the entire graph, thereby preserving the graph privacy while still maintaining enough of the graph structure to maintain model utility. We theoretically show Eclipse provide formal DP guarantee on edges. Experiments on benchmark graph datasets show that Eclipse achieves significantly better privacy-utility tradeoff compared to existing privacy-preserving GNN training methods. In particular, under strong privacy constraints ($\epsilon$ < 4), Eclipse shows significant gains in the model utility by up to 46%. We further demonstrate that Eclipse also has better resilience against common edge attacks (e.g., LPA), lowering the attack AUC by up to 5% compared to other state-of-the-art baselines.
ATP: Enabling Fast LLM Serving via Attention on Top Principal Keys
Mar 01, 2024



We propose a new attention mechanism with linear complexity, ATP, that fixates \textbf{A}ttention on \textbf{T}op \textbf{P}rincipal keys, rather than on each individual token. Particularly, ATP is driven by an important observation that input sequences are typically low-rank, i.e., input sequences can be represented by a few principal bases. Therefore, instead of directly iterating over all the input tokens, ATP transforms inputs into an orthogonal space and computes attention only on the top principal bases (keys). Owing to the observed low-rank structure in input sequences, ATP is able to capture semantic relationships in input sequences with a few principal keys. Furthermore, the attention complexity is reduced from \emph{quadratic} to \emph{linear} without incurring a noticeable performance drop. ATP further reduces complexity for other linear layers with low-rank inputs, leading to more speedup compared to prior works that solely target the attention module. Our evaluations on various models (e.g., BERT and Llama) demonstrate that ATP achieves comparable accuracy with much lower computation and memory complexity than the standard attention mechanism. In particular, ATP barely loses accuracy with only $1/2$ principal keys, and only incurs around $2\%$ accuracy drops with $1/4$ principal keys.
MARS: Meaning-Aware Response Scoring for Uncertainty Estimation in Generative LLMs
Feb 20, 2024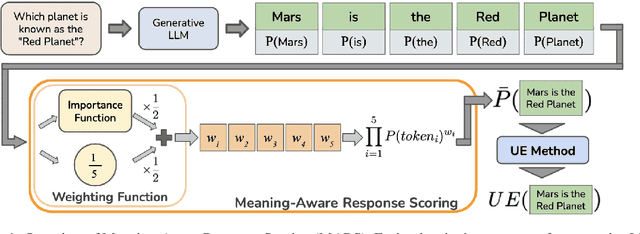
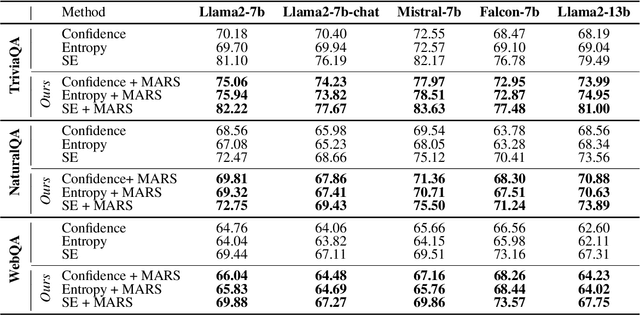
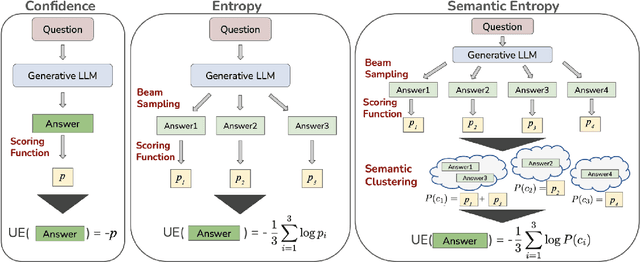
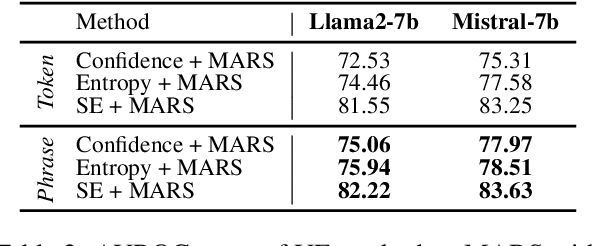
Generative Large Language Models (LLMs) are widely utilized for their excellence in various tasks. However, their tendency to produce inaccurate or misleading outputs poses a potential risk, particularly in high-stakes environments. Therefore, estimating the correctness of generative LLM outputs is an important task for enhanced reliability. Uncertainty Estimation (UE) in generative LLMs is an evolving domain, where SOTA probability-based methods commonly employ length-normalized scoring. In this work, we propose Meaning-Aware Response Scoring (MARS) as an alternative to length-normalized scoring for UE methods. MARS is a novel scoring function that considers the semantic contribution of each token in the generated sequence in the context of the question. We demonstrate that integrating MARS into UE methods results in a universal and significant improvement in UE performance. We conduct experiments using three distinct closed-book question-answering datasets across five popular pre-trained LLMs. Lastly, we validate the efficacy of MARS on a Medical QA dataset. Code can be found https://github.com/Ybakman/LLM_Uncertainity.
All Rivers Run to the Sea: Private Learning with Asymmetric Flows
Dec 05, 2023



Data privacy is of great concern in cloud machine-learning service platforms, when sensitive data are exposed to service providers. While private computing environments (e.g., secure enclaves), and cryptographic approaches (e.g., homomorphic encryption) provide strong privacy protection, their computing performance still falls short compared to cloud GPUs. To achieve privacy protection with high computing performance, we propose Delta, a new private training and inference framework, with comparable model performance as non-private centralized training. Delta features two asymmetric data flows: the main information-sensitive flow and the residual flow. The main part flows into a small model while the residuals are offloaded to a large model. Specifically, Delta embeds the information-sensitive representations into a low-dimensional space while pushing the information-insensitive part into high-dimension residuals. To ensure privacy protection, the low-dimensional information-sensitive part is secured and fed to a small model in a private environment. On the other hand, the residual part is sent to fast cloud GPUs, and processed by a large model. To further enhance privacy and reduce the communication cost, Delta applies a random binary quantization technique along with a DP-based technique to the residuals before sharing them with the public platform. We theoretically show that Delta guarantees differential privacy in the public environment and greatly reduces the complexity in the private environment. We conduct empirical analyses on CIFAR-10, CIFAR-100 and ImageNet datasets and ResNet-18 and ResNet-34, showing that Delta achieves strong privacy protection, fast training, and inference without significantly compromising the model utility.
A Data-Free Approach to Mitigate Catastrophic Forgetting in Federated Class Incremental Learning for Vision Tasks
Nov 21, 2023



Deep learning models often suffer from forgetting previously learned information when trained on new data. This problem is exacerbated in federated learning (FL), where the data is distributed and can change independently for each user. Many solutions are proposed to resolve this catastrophic forgetting in a centralized setting. However, they do not apply directly to FL because of its unique complexities, such as privacy concerns and resource limitations. To overcome these challenges, this paper presents a framework for $\textbf{federated class incremental learning}$ that utilizes a generative model to synthesize samples from past distributions. This data can be later exploited alongside the training data to mitigate catastrophic forgetting. To preserve privacy, the generative model is trained on the server using data-free methods at the end of each task without requesting data from clients. Moreover, our solution does not demand the users to store old data or models, which gives them the freedom to join/leave the training at any time. Additionally, we introduce SuperImageNet, a new regrouping of the ImageNet dataset specifically tailored for federated continual learning. We demonstrate significant improvements compared to existing baselines through extensive experiments on multiple datasets.