 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Sampling of Dependency Structures
Sep 14, 2021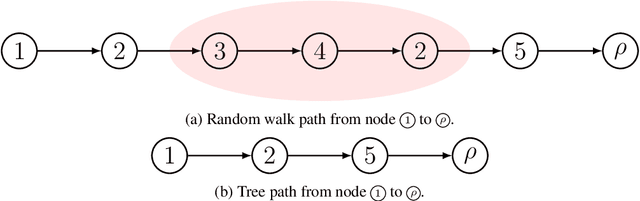



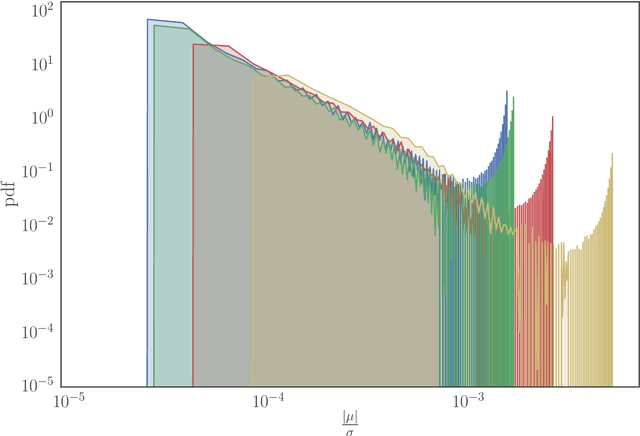
Probabilistic distributions over spanning trees in directed graphs are a fundamental model of dependency structure in natural language processing, syntactic dependency trees. In NLP, dependency trees often have an additional root constraint: only one edge may emanate from the root. However, no sampling algorithm has been presented in the literature to account for this additional constraint. In this paper, we adapt two spanning tree sampling algorithms to faithfully sample dependency trees from a graph subject to the root constraint. Wilson (1996)'s sampling algorithm has a running time of $\mathcal{O}(H)$ where $H$ is the mean hitting time of the graph. Colbourn (1996)'s sampling algorithm has a running time of $\mathcal{O}(N^3)$, which is often greater than the mean hitting time of a directed graph. Additionally, we build upon Colbourn's algorithm and present a novel extension that can sample $K$ trees without replacement in $\mathcal{O}(K N^3 + K^2 N)$ time. To the best of our knowledge, no algorithm has been given for sampling spanning trees without replacement from a directed graph.
A Bayesian Framework for Information-Theoretic Probing
Sep 08, 2021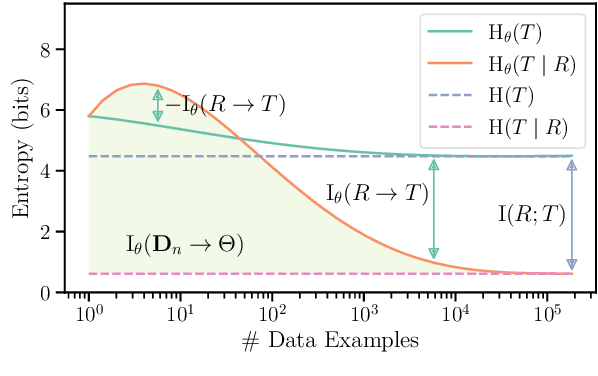
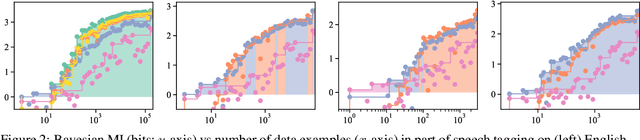
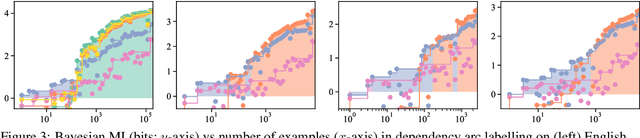
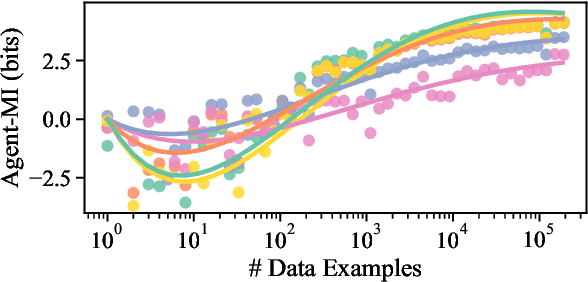
Pimentel et al. (2020) recently analysed probing from an information-theoretic perspective. They argue that probing should be seen as approximating a mutual information. This led to the rather unintuitive conclusion that representations encode exactly the same information about a target task as the original sentences. The mutual information, however, assumes the true probability distribution of a pair of random variables is known, leading to unintuitive results in settings where it is not. This paper proposes a new framework to measure what we term Bayesian mutual information, which analyses information from the perspective of Bayesian agents -- allowing for more intuitive findings in scenarios with finite data. For instance, under Bayesian MI we have that data can add information, processing can help, and information can hurt, which makes it more intuitive for machine learning applications. Finally, we apply our framework to probing where we believe Bayesian mutual information naturally operationalises ease of extraction by explicitly limiting the available background knowledge to solve a task.
Differentiable Subset Pruning of Transformer Heads
Aug 22, 2021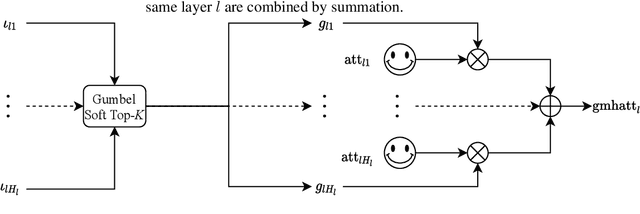
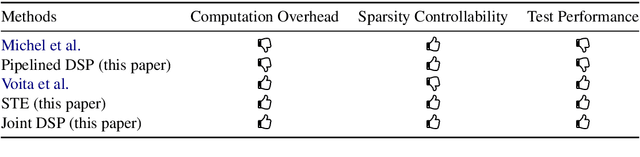
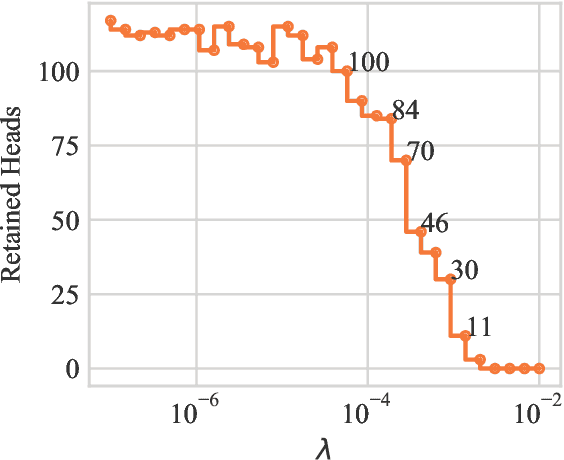
Multi-head attention, a collection of several attention mechanisms that independently attend to different parts of the input, is the key ingredient in the Transformer. Recent work has shown, however, that a large proportion of the heads in a Transformer's multi-head attention mechanism can be safely pruned away without significantly harming the performance of the model; such pruning leads to models that are noticeably smaller and faster in practice. Our work introduces a new head pruning technique that we term differentiable subset pruning. Intuitively, our method learns per-head importance variables and then enforces a user-specified hard constraint on the number of unpruned heads. The importance variables are learned via stochastic gradient descent. We conduct experiments on natural language inference and machine translation; we show that differentiable subset pruning performs comparably or better than previous works while offering precise control of the sparsity level.
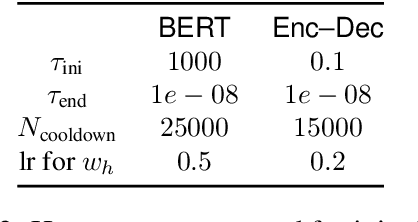
Towards Zero-shot Language Modeling
Aug 06, 2021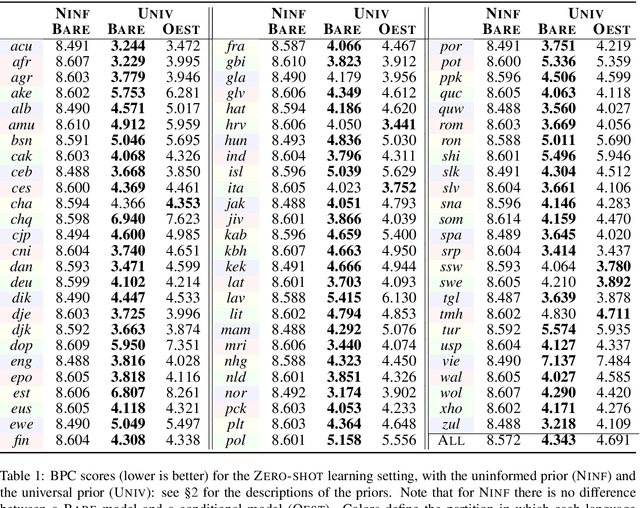
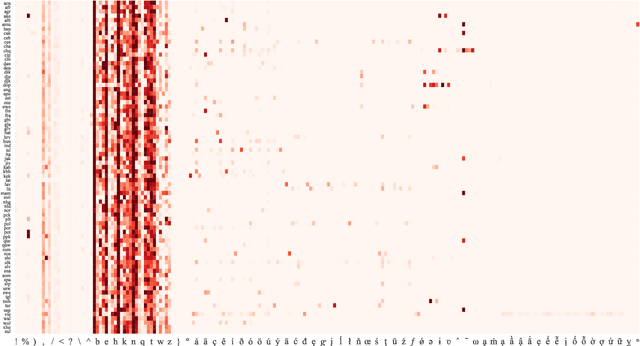
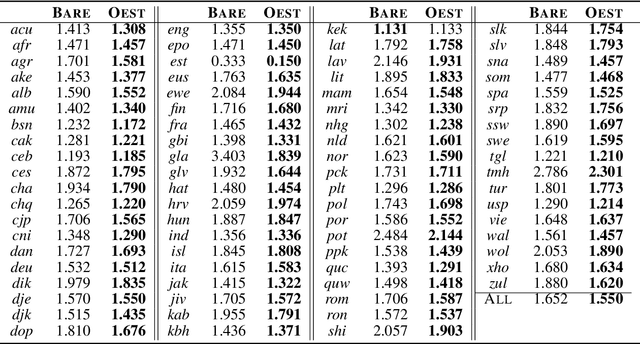
Can we construct a neural model that is inductively biased towards learning human languages? Motivated by this question, we aim at constructing an informative prior over neural weights, in order to adapt quickly to held-out languages in the task of character-level language modeling. We infer this distribution from a sample of typologically diverse training languages via Laplace approximation. The use of such a prior outperforms baseline models with an uninformative prior (so-called "fine-tuning") in both zero-shot and few-shot settings. This shows that the prior is imbued with universal phonological knowledge. Moreover, we harness additional language-specific side information as distant supervision for held-out languages. Specifically, we condition language models on features from typological databases, by concatenating them to hidden states or generating weights with hyper-networks. These features appear beneficial in the few-shot setting, but not in the zero-shot setting. Since the paucity of digital texts affects the majority of the world's languages, we hope that these findings will help broaden the scope of applications for language technology.
Determinantal Beam Search
Jun 21, 2021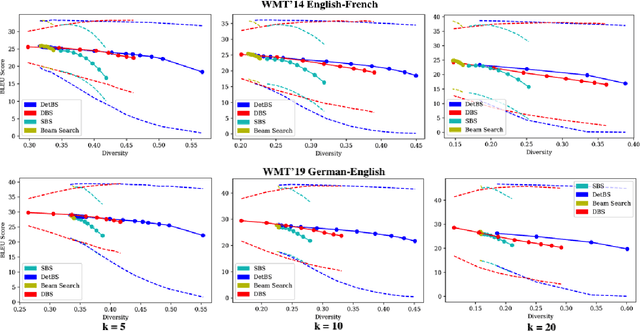


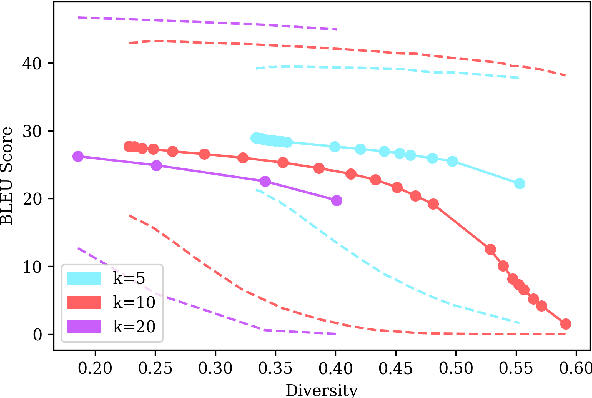
Beam search is a go-to strategy for decoding neural sequence models. The algorithm can naturally be viewed as a subset optimization problem, albeit one where the corresponding set function does not reflect interactions between candidates. Empirically, this leads to sets often exhibiting high overlap, e.g., strings may differ by only a single word. Yet in use-cases that call for multiple solutions, a diverse or representative set is often desired. To address this issue, we propose a reformulation of beam search, which we call determinantal beam search. Determinantal beam search has a natural relationship to determinantal point processes (DPPs), models over sets that inherently encode intra-set interactions. By posing iterations in beam search as a series of subdeterminant maximization problems, we can turn the algorithm into a diverse subset selection process. In a case study, we use the string subsequence kernel to explicitly encourage n-gram coverage in text generated from a sequence model. We observe that our algorithm offers competitive performance against other diverse set generation strategies in the context of language generation, while providing a more general approach to optimizing for diversity.
A Cognitive Regularizer for Language Modeling
Jun 10, 2021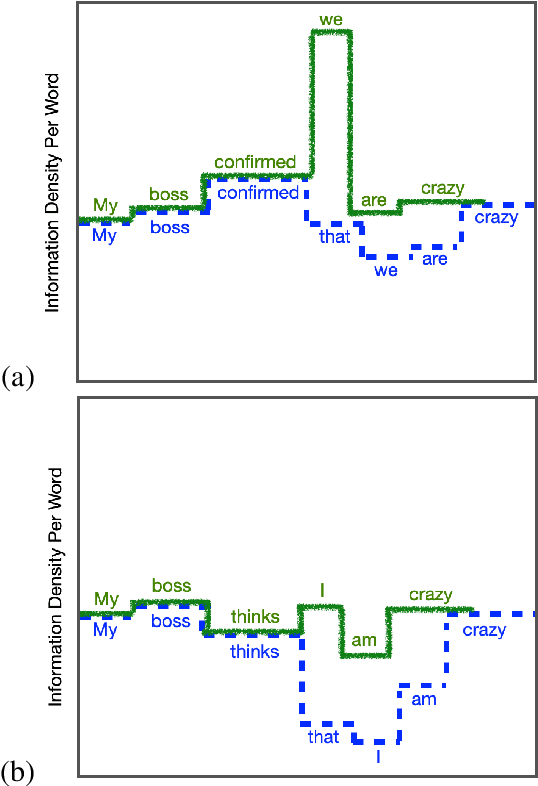
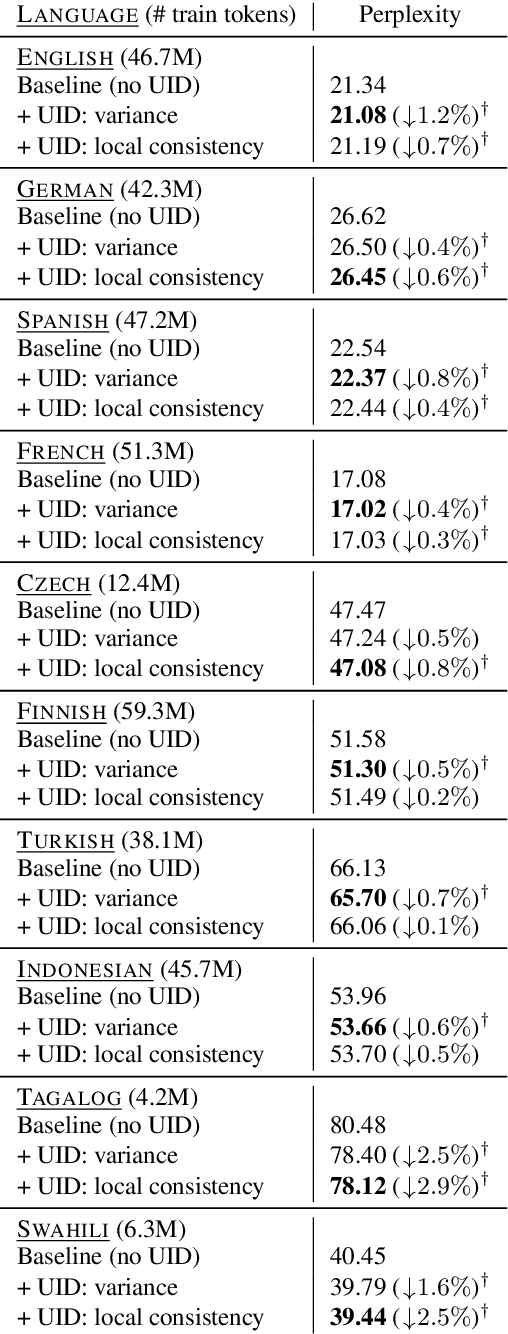
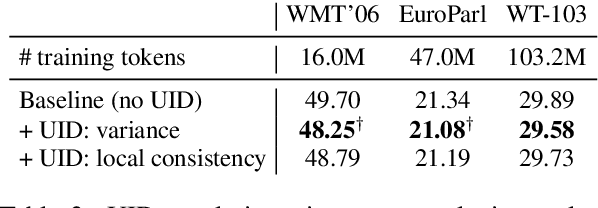
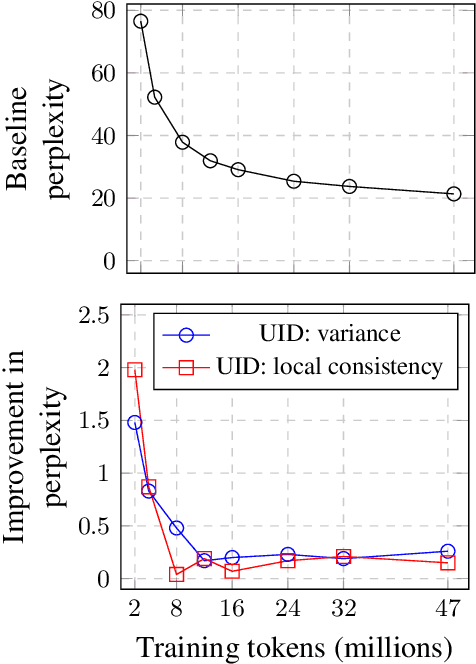
The uniform information density (UID) hypothesis, which posits that speakers behaving optimally tend to distribute information uniformly across a linguistic signal, has gained traction in psycholinguistics as an explanation for certain syntactic, morphological, and prosodic choices. In this work, we explore whether the UID hypothesis can be operationalized as an inductive bias for statistical language modeling. Specifically, we augment the canonical MLE objective for training language models with a regularizer that encodes UID. In experiments on ten languages spanning five language families, we find that using UID regularization consistently improves perplexity in language models, having a larger effect when training data is limited. Moreover, via an analysis of generated sequences, we find that UID-regularized language models have other desirable properties, e.g., they generate text that is more lexically diverse. Our results not only suggest that UID is a reasonable inductive bias for language modeling, but also provide an alternative validation of the UID hypothesis using modern-day NLP tools.
Is Sparse Attention more Interpretable?
Jun 08, 2021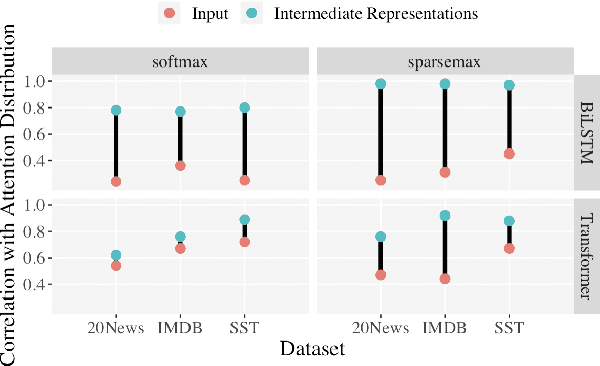
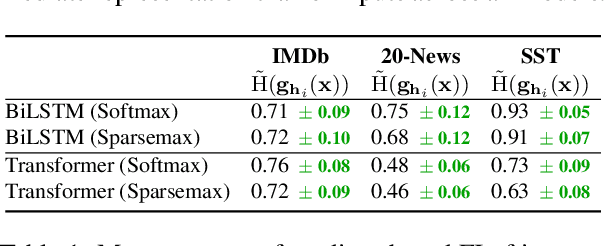
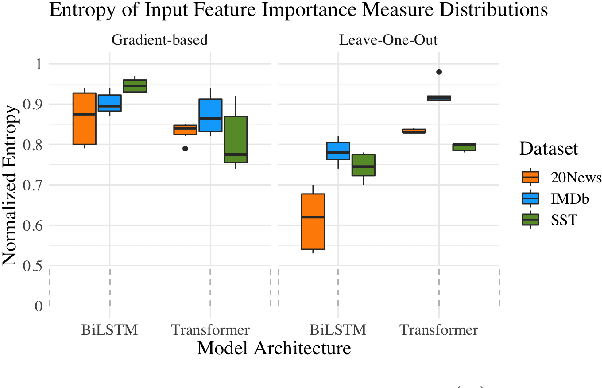
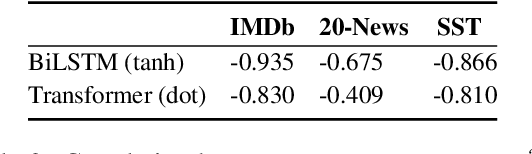
Sparse attention has been claimed to increase model interpretability under the assumption that it highlights influential inputs. Yet the attention distribution is typically over representations internal to the model rather than the inputs themselves, suggesting this assumption may not have merit. We build on the recent work exploring the interpretability of attention; we design a set of experiments to help us understand how sparsity affects our ability to use attention as an explainability tool. On three text classification tasks, we verify that only a weak relationship between inputs and co-indexed intermediate representations exists -- under sparse attention and otherwise. Further, we do not find any plausible mappings from sparse attention distributions to a sparse set of influential inputs through other avenues. Rather, we observe in this setting that inducing sparsity may make it less plausible that attention can be used as a tool for understanding model behavior.
* ACL 2021
SIGTYP 2021 Shared Task: Robust Spoken Language Identification
Jun 07, 2021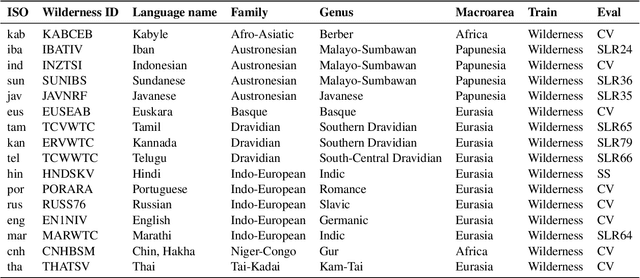
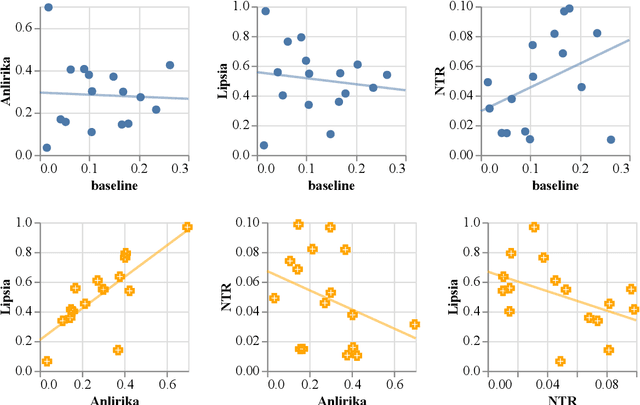
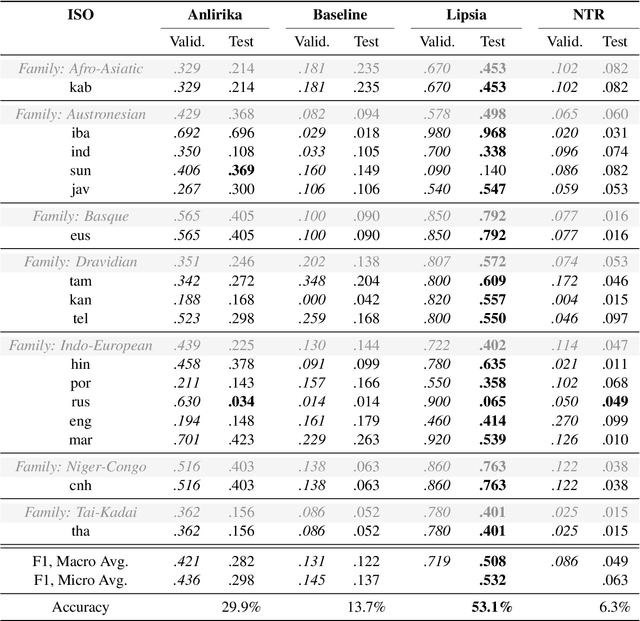
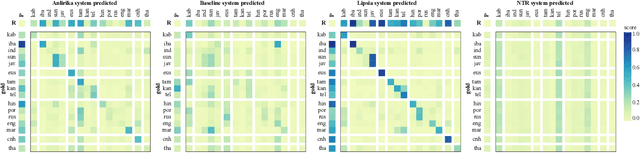
While language identification is a fundamental speech and language processing task, for many languages and language families it remains a challenging task. For many low-resource and endangered languages this is in part due to resource availability: where larger datasets exist, they may be single-speaker or have different domains than desired application scenarios, demanding a need for domain and speaker-invariant language identification systems. This year's shared task on robust spoken language identification sought to investigate just this scenario: systems were to be trained on largely single-speaker speech from one domain, but evaluated on data in other domains recorded from speakers under different recording circumstances, mimicking realistic low-resource scenarios. We see that domain and speaker mismatch proves very challenging for current methods which can perform above 95% accuracy in-domain, which domain adaptation can address to some degree, but that these conditions merit further investigation to make spoken language identification accessible in many scenarios.
Do Syntactic Probes Probe Syntax? Experiments with Jabberwocky Probing
Jun 04, 2021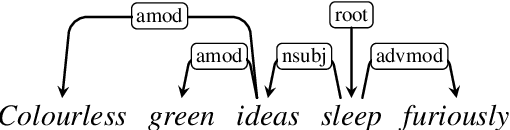

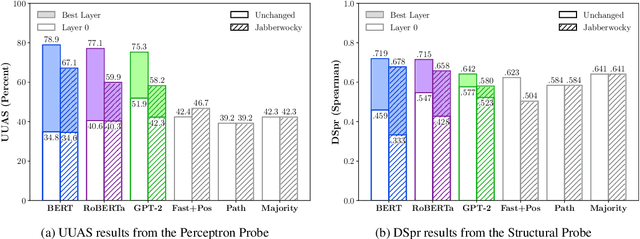
Analysing whether neural language models encode linguistic information has become popular in NLP. One method of doing so, which is frequently cited to support the claim that models like BERT encode syntax, is called probing; probes are small supervised models trained to extract linguistic information from another model's output. If a probe is able to predict a particular structure, it is argued that the model whose output it is trained on must have implicitly learnt to encode it. However, drawing a generalisation about a model's linguistic knowledge about a specific phenomena based on what a probe is able to learn may be problematic: in this work, we show that semantic cues in training data means that syntactic probes do not properly isolate syntax. We generate a new corpus of semantically nonsensical but syntactically well-formed Jabberwocky sentences, which we use to evaluate two probes trained on normal data. We train the probes on several popular language models (BERT, GPT, and RoBERTa), and find that in all settings they perform worse when evaluated on these data, for one probe by an average of 15.4 UUAS points absolute. Although in most cases they still outperform the baselines, their lead is reduced substantially, e.g. by 53% in the case of BERT for one probe. This begs the question: what empirical scores constitute knowing syntax?
Modeling the Unigram Distribution
Jun 04, 2021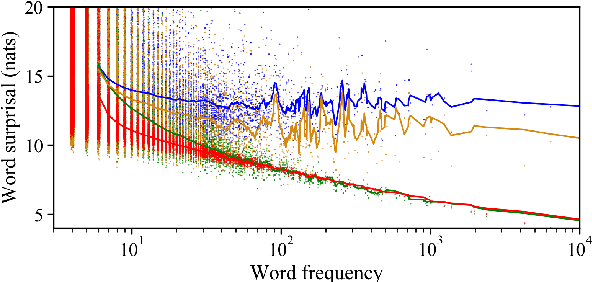
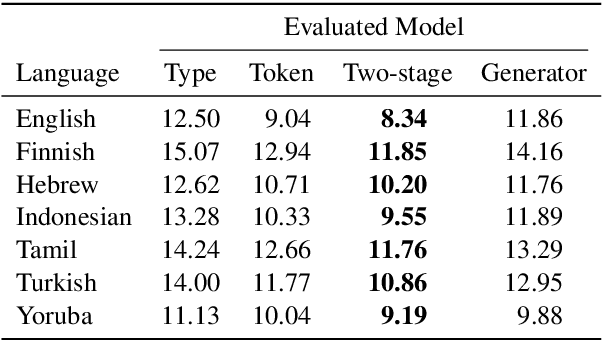

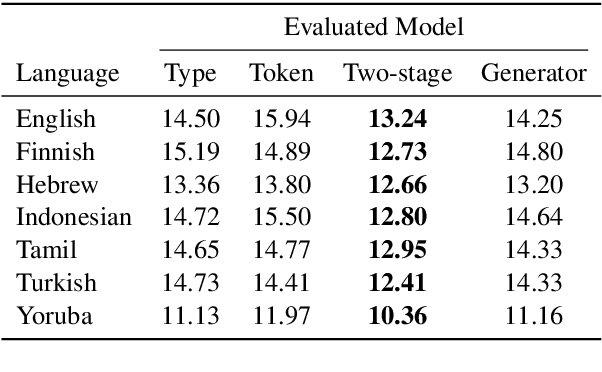
The unigram distribution is the non-contextual probability of finding a specific word form in a corpus. While of central importance to the study of language, it is commonly approximated by each word's sample frequency in the corpus. This approach, being highly dependent on sample size, assigns zero probability to any out-of-vocabulary (oov) word form. As a result, it produces negatively biased probabilities for any oov word form, while positively biased probabilities to in-corpus words. In this work, we argue in favor of properly modeling the unigram distribution -- claiming it should be a central task in natural language processing. With this in mind, we present a novel model for estimating it in a language (a neuralization of Goldwater et al.'s (2011) model) and show it produces much better estimates across a diverse set of 7 languages than the na\"ive use of neural character-level language models.