 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthesizing Stable Reduced-Order Visuomotor Policies for Nonlinear Systems via Sums-of-Squares Optimization
Apr 24, 2023



We present a method for synthesizing dynamic, reduced-order output-feedback polynomial control policies for control-affine nonlinear systems which guarantees runtime stability to a goal state, when using visual observations and a learned perception module in the feedback control loop. We leverage Lyapunov analysis to formulate the problem of synthesizing such policies. This problem is nonconvex in the policy parameters and the Lyapunov function that is used to prove the stability of the policy. To solve this problem approximately, we propose two approaches: the first solves a sequence of sum-of-squares optimization problems to iteratively improve a policy which is provably-stable by construction, while the second directly performs gradient-based optimization on the parameters of the polynomial policy, and its closed-loop stability is verified a posteriori. We extend our approach to provide stability guarantees in the presence of observation noise, which realistically arises due to errors in the learned perception module. We evaluate our approach on several underactuated nonlinear systems, including pendula and quadrotors, showing that our guarantees translate to empirical stability when controlling these systems from images, while baseline approaches can fail to reliably stabilize the system.
Growing Convex Collision-Free Regions in Configuration Space using Nonlinear Programming
Mar 26, 2023One of the most difficult parts of motion planning in configuration space is ensuring a trajectory does not collide with task-space obstacles in the environment. Generating regions that are convex and collision free in configuration space can separate the computational burden of collision checking from motion planning. To that end, we propose an extension to IRIS (Iterative Regional Inflation by Semidefinite programming) [5] that allows it to operate in configuration space. Our algorithm, IRIS-NP (Iterative Regional Inflation by Semidefinite & Nonlinear Programming), uses nonlinear optimization to add the separating hyperplanes, enabling support for more general nonlinear constraints. Developed in parallel to Amice et al. [1], IRIS-NP trades rigorous certification that regions are collision free for probabilistic certification and the benefit of faster region generation in the configuration-space coordinates. IRIS-NP also provides a solid initialization to C-IRIS to reduce the number of iterations required for certification. We demonstrate that IRIS-NP can scale to a dual-arm manipulator and can handle additional nonlinear constraints using the same machinery. Finally, we show ablations of elements of our implementation to demonstrate their importance.
Certified Polyhedral Decompositions of Collision-Free Configuration Space
Feb 23, 2023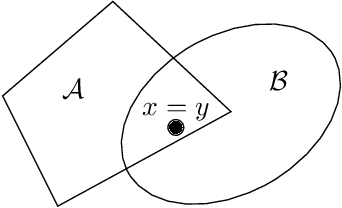

Understanding the geometry of collision-free configuration space (C-free) in the presence of task-space obstacles is an essential ingredient for collision-free motion planning. While it is possible to check for collisions at a point using standard algorithms, to date no practical method exists for computing C-free regions with rigorous certificates due to the complexity of mapping task-space obstacles through the kinematics. In this work, we present the first to our knowledge rigorous method for approximately decomposing a rational parametrization of C-free into certified polyhedral regions. Our method, called C-IRIS (C-space Iterative Regional Inflation by Semidefinite programming), generates large, convex polytopes in a rational parameterization of the configuration space which are rigorously certified to be collision-free. Such regions have been shown to be useful for both optimization-based and randomized motion planning. Based on convex optimization, our method works in arbitrary dimensions, only makes assumptions about the convexity of the obstacles in the task space, and is fast enough to scale to realistic problems in manipulation. We demonstrate our algorithm's ability to fill a non-trivial amount of collision-free C-space in several 2-DOF examples where the C-space can be visualized, as well as the scalability of our algorithm on a 7-DOF KUKA iiwa, a 6-DOF UR3e and 12-DOF bimanual manipulators. An implementation of our algorithm is open-sourced in Drake. We furthermore provide examples of our algorithm in interactive Python notebooks.
Smoothed Online Learning for Prediction in Piecewise Affine Systems
Jan 26, 2023The problem of piecewise affine (PWA) regression and planning is of foundational importance to the study of online learning, control, and robotics, where it provides a theoretically and empirically tractable setting to study systems undergoing sharp changes in the dynamics. Unfortunately, due to the discontinuities that arise when crossing into different ``pieces,'' learning in general sequential settings is impossible and practical algorithms are forced to resort to heuristic approaches. This paper builds on the recently developed smoothed online learning framework and provides the first algorithms for prediction and simulation in PWA systems whose regret is polynomial in all relevant problem parameters under a weak smoothness assumption; moreover, our algorithms are efficient in the number of calls to an optimization oracle. We further apply our results to the problems of one-step prediction and multi-step simulation regret in piecewise affine dynamical systems, where the learner is tasked with simulating trajectories and regret is measured in terms of the Wasserstein distance between simulated and true data. Along the way, we develop several technical tools of more general interest.
Can Direct Latent Model Learning Solve Linear Quadratic Gaussian Control?
Dec 30, 2022We study the task of learning state representations from potentially high-dimensional observations, with the goal of controlling an unknown partially observable system. We pursue a direct latent model learning approach, where a dynamic model in some latent state space is learned by predicting quantities directly related to planning (e.g., costs) without reconstructing the observations. In particular, we focus on an intuitive cost-driven state representation learning method for solving Linear Quadratic Gaussian (LQG) control, one of the most fundamental partially observable control problems. As our main results, we establish finite-sample guarantees of finding a near-optimal state representation function and a near-optimal controller using the directly learned latent model. To the best of our knowledge, despite various empirical successes, prior to this work it was unclear if such a cost-driven latent model learner enjoys finite-sample guarantees. Our work underscores the value of predicting multi-step costs, an idea that is key to our theory, and notably also an idea that is known to be empirically valuable for learning state representations.
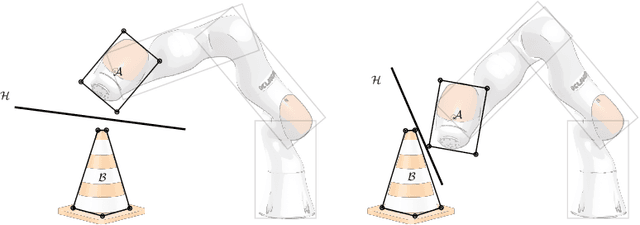
Global Planning for Contact-Rich Manipulation via Local Smoothing of Quasi-dynamic Contact Models
Jun 22, 2022

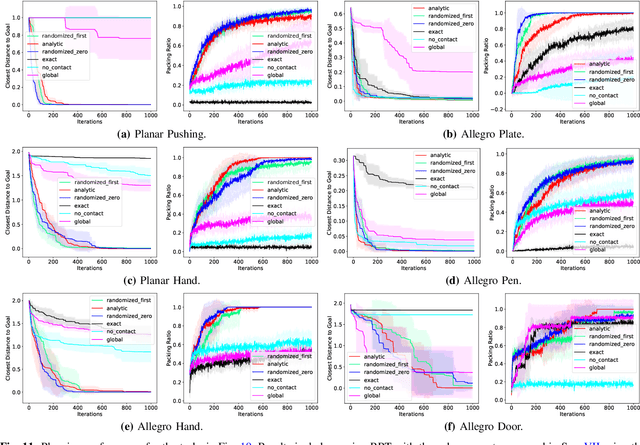
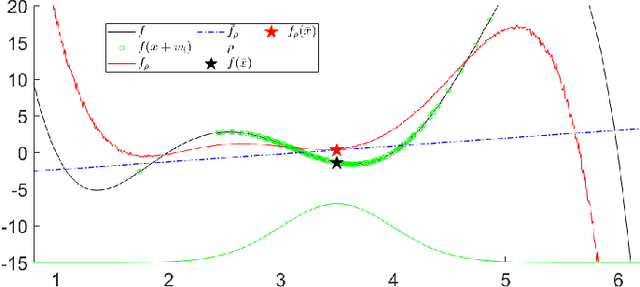
The empirical success of Reinforcement Learning (RL) in the setting of contact-rich manipulation leaves much to be understood from a model-based perspective, where the key difficulties are often attributed to (i) the explosion of contact modes, (ii) stiff, non-smooth contact dynamics and the resulting exploding / discontinuous gradients, and (iii) the non-convexity of the planning problem. The stochastic nature of RL addresses (i) and (ii) by effectively sampling and averaging the contact modes. On the other hand, model-based methods have tackled the same challenges by smoothing contact dynamics analytically. Our first contribution is to establish the theoretical equivalence of the two methods for simple systems, and provide qualitative and empirical equivalence on a number of complex examples. In order to further alleviate (ii), our second contribution is a convex, differentiable and quasi-dynamic formulation of contact dynamics, which is amenable to both smoothing schemes, and has proven through experiments to be highly effective for contact-rich planning. Our final contribution resolves (iii), where we show that classical sampling-based motion planning algorithms can be effective in global planning when contact modes are abstracted via smoothing. Applying our method on a collection of challenging contact-rich manipulation tasks, we demonstrate that efficient model-based motion planning can achieve results comparable to RL with dramatically less computation. Video: https://youtu.be/12Ew4xC-VwA
Motion Planning around Obstacles with Convex Optimization
May 09, 2022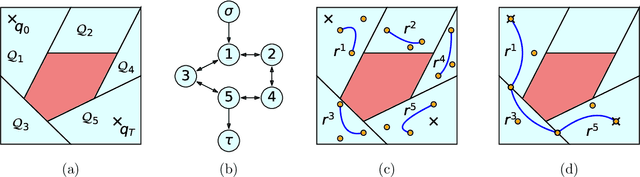
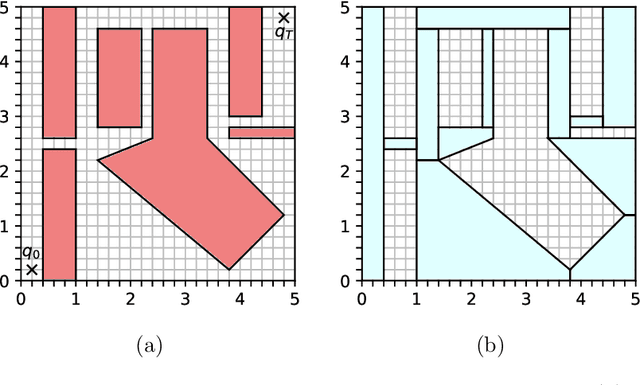
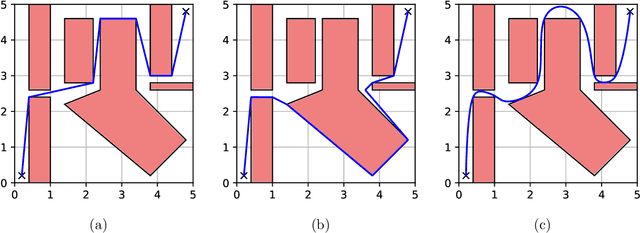
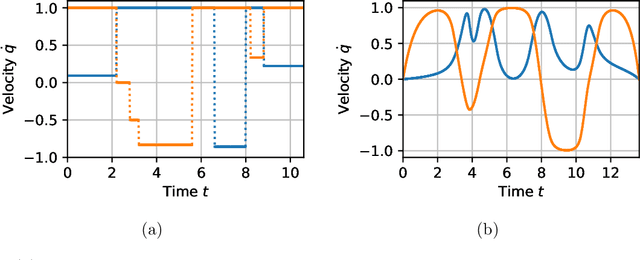
Trajectory optimization offers mature tools for motion planning in high-dimensional spaces under dynamic constraints. However, when facing complex configuration spaces, cluttered with obstacles, roboticists typically fall back to sampling-based planners that struggle in very high dimensions and with continuous differential constraints. Indeed, obstacles are the source of many textbook examples of problematic nonconvexities in the trajectory-optimization problem. Here we show that convex optimization can, in fact, be used to reliably plan trajectories around obstacles. Specifically, we consider planning problems with collision-avoidance constraints, as well as cost penalties and hard constraints on the shape, the duration, and the velocity of the trajectory. Combining the properties of B\'ezier curves with a recently-proposed framework for finding shortest paths in Graphs of Convex Sets (GCS), we formulate the planning problem as a compact mixed-integer optimization. In stark contrast with existing mixed-integer planners, the convex relaxation of our programs is very tight, and a cheap rounding of its solution is typically sufficient to design globally-optimal trajectories. This reduces the mixed-integer program back to a simple convex optimization, and automatically provides optimality bounds for the planned trajectories. We name the proposed planner GCS, after its underlying optimization framework. We demonstrate GCS in simulation on a variety of robotic platforms, including a quadrotor flying through buildings and a dual-arm manipulator (with fourteen degrees of freedom) moving in a confined space. Using numerical experiments on a seven-degree-of-freedom manipulator, we show that GCS can outperform widely-used sampling-based planners by finding higher-quality trajectories in less time.
Finding and Optimizing Certified, Collision-Free Regions in Configuration Space for Robot Manipulators
May 07, 2022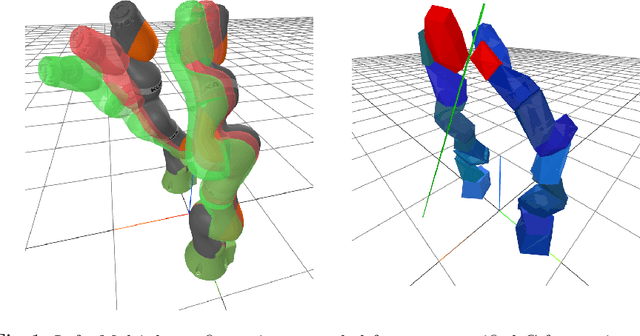

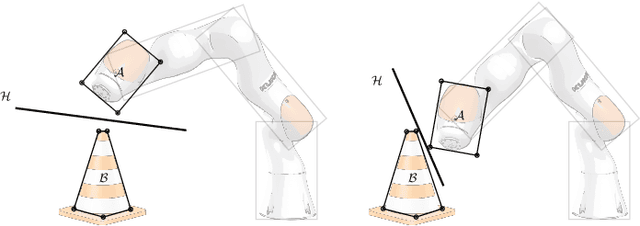
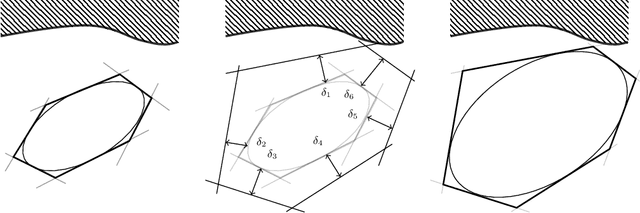
Configuration space (C-space) has played a central role in collision-free motion planning, particularly for robot manipulators. While it is possible to check for collisions at a point using standard algorithms, to date no practical method exists for computing collision-free C-space regions with rigorous certificates due to the complexities of mapping task-space obstacles through the kinematics. In this work, we present the first to our knowledge method for generating such regions and certificates through convex optimization. Our method, called C-Iris (C-space Iterative Regional Inflation by Semidefinite programming), generates large, convex polytopes in a rational parametrization of the configuration space which are guaranteed to be collision-free. Such regions have been shown to be useful for both optimization-based and randomized motion planning. Our regions are generated by alternating between two convex optimization problems: (1) a simultaneous search for a maximal-volume ellipse inscribed in a given polytope and a certificate that the polytope is collision-free and (2) a maximal expansion of the polytope away from the ellipse which does not violate the certificate. The volume of the ellipse and size of the polytope are allowed to grow over several iterations while being collision-free by construction. Our method works in arbitrary dimensions, only makes assumptions about the convexity of the obstacles in the task space, and scales to realistic problems in manipulation. We demonstrate our algorithm's ability to fill a non-trivial amount of collision-free C-space in a 3-DOF example where the C-space can be visualized, as well as the scalability of our algorithm on a 7-DOF KUKA iiwa and a 12-DOF bimanual manipulator.
Learning Multi-Object Dynamics with Compositional Neural Radiance Fields
Mar 04, 2022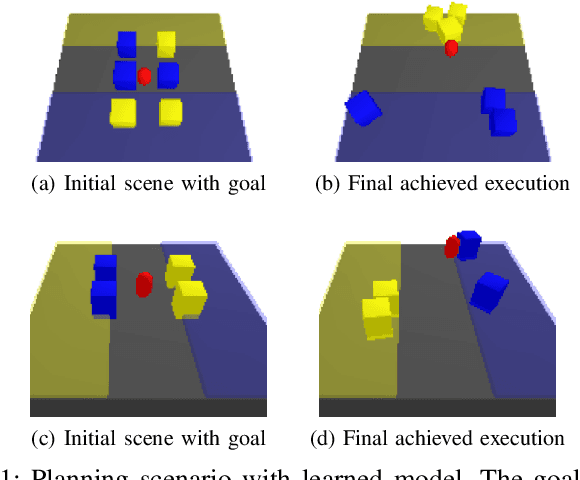
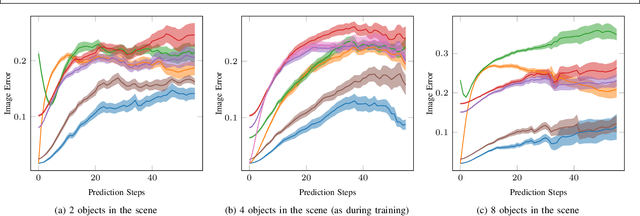
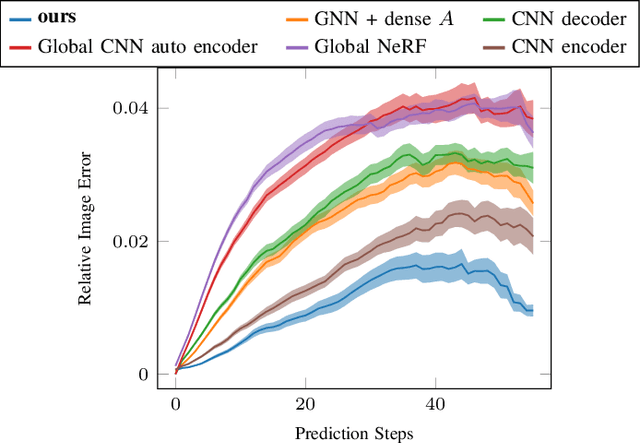
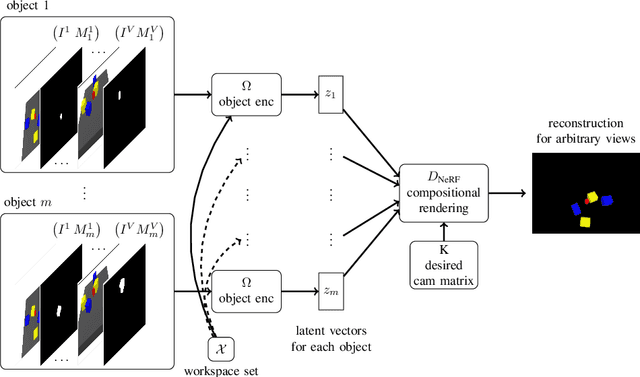
We present a method to learn compositional predictive models from image observations based on implicit object encoders, Neural Radiance Fields (NeRFs), and graph neural networks. A central question in learning dynamic models from sensor observations is on which representations predictions should be performed. NeRFs have become a popular choice for representing scenes due to their strong 3D prior. However, most NeRF approaches are trained on a single scene, representing the whole scene with a global model, making generalization to novel scenes, containing different numbers of objects, challenging. Instead, we present a compositional, object-centric auto-encoder framework that maps multiple views of the scene to a \emph{set} of latent vectors representing each object separately. The latent vectors parameterize individual NeRF models from which the scene can be reconstructed and rendered from novel viewpoints. We train a graph neural network dynamics model in the latent space to achieve compositionality for dynamics prediction. A key feature of our approach is that the learned 3D information of the scene through the NeRF model enables us to incorporate structural priors in learning the dynamics models, making long-term predictions more stable. The model can further be used to synthesize new scenes from individual object observations. For planning, we utilize RRTs in the learned latent space, where we can exploit our model and the implicit object encoder to make sampling the latent space informative and more efficient. In the experiments, we show that the model outperforms several baselines on a pushing task containing many objects. Video: https://dannydriess.github.io/compnerfdyn/
Elliptical Slice Sampling for Probabilistic Verification of Stochastic Systems with Signal Temporal Logic Specifications
Feb 28, 2022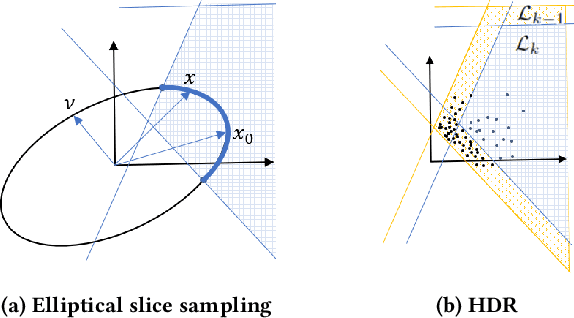
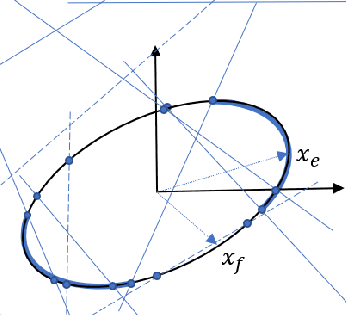
Autonomous robots typically incorporate complex sensors in their decision-making and control loops. These sensors, such as cameras and Lidars, have imperfections in their sensing and are influenced by environmental conditions. In this paper, we present a method for probabilistic verification of linearizable systems with Gaussian and Gaussian mixture noise models (e.g. from perception modules, machine learning components). We compute the probabilities of task satisfaction under Signal Temporal Logic (STL) specifications, using its robustness semantics, with a Markov Chain Monte-Carlo slice sampler. As opposed to other techniques, our method avoids over-approximations and double-counting of failure events. Central to our approach is a method for efficient and rejection-free sampling of signals from a Gaussian distribution such that satisfy or violate a given STL formula. We show illustrative examples from applications in robot motion planning.